decay专题

tf.train.exponential_decay(学习率衰减)
#!/usr/bin/env python3# -*- coding: utf-8 -*-'''学习率较大容易搜索震荡(在最优值附近徘徊),学习率较小则收敛速度较慢,那么可以通过初始定义一个较大的学习率,通过设置decay_rate来缩小学习率,减少迭代次数。tf.train.exponential_decay就是用来实现这个功能。'''__author__ = 'Zhang Shuai'i

【PyTorch 新手基础】一分钟快速部署 learning rate decay
【方法一:ReduceLROnPlateau】当设定指标在最近几个epoch中都没有变化时,调整学习率。 optimizer = torch.optim.SGD(net.parameters(), lr=learning_rate, weight_decay=0.01)scheduler = torch.optim.lr_sheduler.ReduceLROnPlateau(optimizer

【深度学习笔记3.1 正则化】权重衰减(weight decay)
权重衰减是什么?参考有关文献 这里参考文献[1]整理成如下代码:(详见文献[5]regularization/WeightDecay.py) import numpy as npimport tensorflow as tffrom matplotlib import pyplot as pltn_train = 20n_test = 100num_inputs = 200true_w
C++备忘录007:烦人的数组decay到指针
void bar(int a[2]) {static_assert(std::is_same_v<decltype(a), int *>);}void foo(int (&a)[2]) {static_assert(std::is_same_v<decltype(a), int (&)[2]>);} 这是从C继承来的老问题,心累

【论文笔记】Layer-Wise Weight Decay for Deep Neural Networks
Abstract 本文为了提高深度神经网络的训练效率,提出了逐层权重衰减(layer-wise weight decay)。 本文方法通过逐层设置权重衰减稀疏的不同值,使反向传播梯度的尺度与权重衰减的尺度之比在整个网络中保持恒定。这种设置可以避免过拟合或欠拟合,适当地训练所有层,无需逐层调整系数。 该方法可在不改变网络模型的情况下提升现有DNN的性能。 1 Introduction 很多机器
Caffe中learning rate 和 weight decay 的理解
Caffe中learning rate 和 weight decay 的理解 在caffe.proto中 对caffe网络中出现的各项参数做了详细的解释。 1.关于learning rate optional float base_lr = 5; // The base learning rate // The learning rate decay policy. The curr

C++11之std::is_same和std::decay
使用C++,大家会经常用到模板编程。 模板(Templates)使得我们可以生成通用的函数,这些函数能够接受任意数据类型的参数,可返回任意类型的值,而不需要对所有可能的数据类型进行函数重载。这在一定程度上实现了宏(macro)的作用。 模板在一定程度上使得程序能够更灵活,但也带来了困扰。由于类型的不确定性,导致对不同类型的数据操作存在不确定性。 C++11提供了type_traits头文件,
Tensorflow学习率的learning rate decay
x = tf.Variable(1.0)y = x.assign_add(1)with tf.Session() as sess:sess.run(tf.global_variables_initializer())print sess.run(x)print sess.run(y)print sess.run(x) 输出 1,2,2注意其x会变的 import tensorflow as

深度学习记录--学习率衰减(learning rate decay)
学习率衰减 mini-batch梯度下降最终会在最小值附近的区间摆动(噪声很大),不会精确收敛 为了更加近似最小值,采用学习率衰减的方法 随着学习率的衰减,步长会逐渐变小,因此最终摆动的区间会很小,更加近似最小值 如下图,蓝色曲线表示mini-batch梯度下降,绿色曲线表示采用学习率衰减的梯度下降 学习率衰减的实现 1 epoch = 遍历数据1次 是学习率衰减的超
指数衰减-Exponential Decay
Exponential decay is the decrease in a quantity N according to the law N ( t ) = N 0 e − λ t , ( 1 ) N(t)=N_{0}e^{-\lambda t} , (1) N(t)=N0e−λt,(1) for a parameter t and constant lambda (known as th
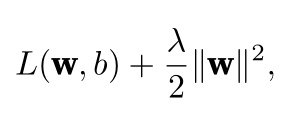
权重衰减weight_decay
查了好几次了,一直忘,记录一下 使用L 2 范数的一个原因是它对权重向量的大分量施加了巨大的惩罚。这使得我们的学习算法偏向于在大量特征上均匀分布权重的模型。在实践中,这可能使它们对单个变量中的观测误差更为稳定。 相比之下,L 1 惩罚会导致模型将权重集中在一小部分特征上,而将其他权重清除为零。这称为特征选择(feature selection),这可能是其他场景下需要的 总之
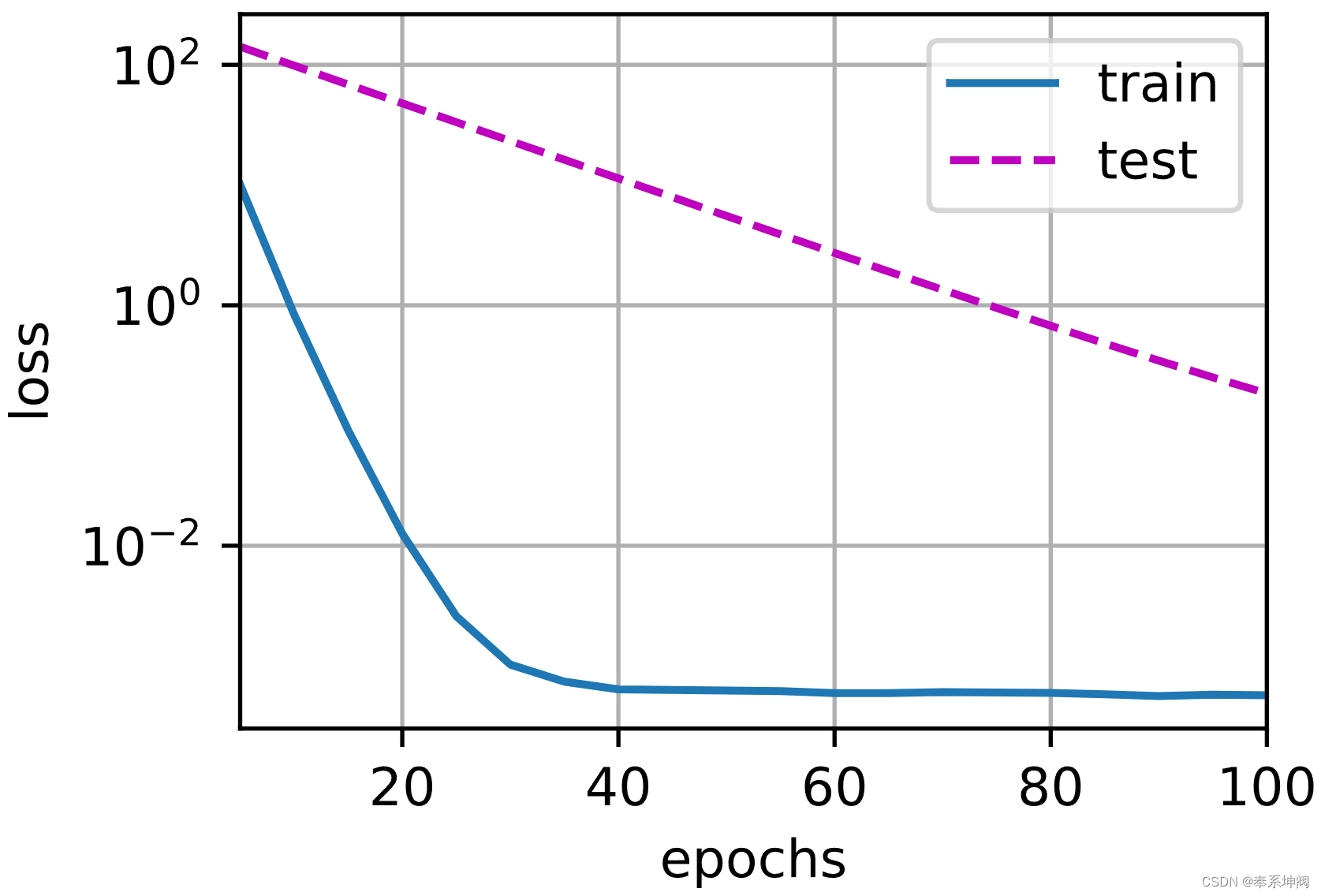
权重衰减(Weight Decay)
在深度学习中,权重衰减(Weight Decay)是一种常用的正则化技术,旨在减少模型的过拟合现象。权重衰减通过向损失函数添加一个正则化项,以惩罚模型中较大的权重值。 一、权重衰减 在深度学习中,模型的训练过程通常使用梯度下降法(或其变种)来最小化损失函数。梯度下降法的目标是找到损失函数的局部最小值,使得模型的预测能力最好。然而,当模型的参数(即权重)过多或过大时,
MSE,ks,mAP,weight decay等名词解释
参考链接:http://blog.sina.com.cn/s/blog_57a1cae80101bh65.html 均方误差 (Mean Squared Error)均方误差 MSE是网络的性能函数,网络的均方误差,叫"Mean Square Error"。比如有n对输入输出数据,每对为[Pi,Ti],i=1,2,...,n.网络通过训练后有网络输出,记为Yi。 在相同测量条件下进行的
self.named_parameters()和weight_decay解释
params_decay = (p for name, p in self.named_parameters() if 'bias' not in name)params_no_decay = (p for name, p in self.named_parameters() if 'bias' in name) 这段代码是在PyTorch中对模型的参数进行筛选,以便在优化器中为不同的参数组
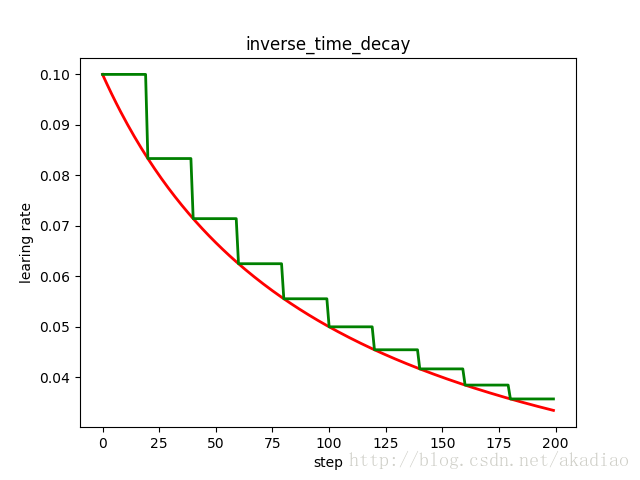
TensorFlow学习--学习率衰减/learning rate decay
学习率衰减 学习率衰减(learning rate decay) 在训练神经网络时,使用学习率控制参数的更新速度.学习率较小时,会大大降低参数的更新速度;学习率较大时,会使搜索过程中发生震荡,导致参数在极优值附近徘徊. 为此,在训练过程中引入学习率衰减,使学习率随着训练的进行逐渐衰减. TensorFlow中实现的学习率衰减方法: tf.train.piecewise_constant