本文主要是介绍权重衰减weight_decay,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
查了好几次了,一直忘,记录一下
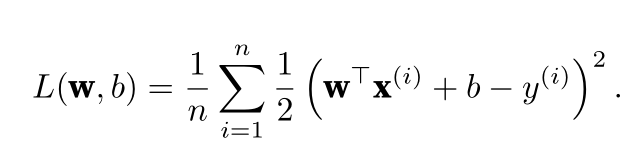
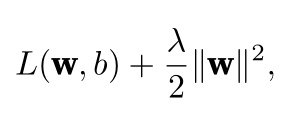
使用L 2 范数的一个原因是它对权重向量的大分量施加了巨大的惩罚。这使得我们的学习算法偏向于在大量特征上均匀分布权重的模型。在实践中,这可能使它们对单个变量中的观测误差更为稳定。
相比之下,L 1 惩罚会导致模型将权重集中在一小部分特征上,而将其他权重清除为零。这称为特征选择(feature selection),这可能是其他场景下需要的
总之就是施加一个惩罚项,防止模型过拟合,并具有鲁棒性。
这篇关于权重衰减weight_decay的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!









