datastream专题

说说Flink DataStream的八种物理分区逻辑
By 大数据技术与架构 场景描述:Spark的RDD有分区的概念,Flink的DataStream同样也有,只不过没有RDD那么显式而已。Flink通过流分区器StreamPartitioner来控制DataStream中的元素往下游的流向。 Spark的RDD有分区的概念,Flink的DataStream同样也有,只不过没有RDD那么显式而已。Flink通过流分区器StreamPartitio

大数据-117 - Flink DataStream Sink 案例:写出到MySQL、写出到Kafka
点一下关注吧!!!非常感谢!!持续更新!!! 目前已经更新到了: Hadoop(已更完)HDFS(已更完)MapReduce(已更完)Hive(已更完)Flume(已更完)Sqoop(已更完)Zookeeper(已更完)HBase(已更完)Redis (已更完)Kafka(已更完)Spark(已更完)Flink(正在更新!) 章节内容 上节我们完成了如下的内容: Sink 的基本概念等内

大数据-116 - Flink DataStream Sink 原理、概念、常见Sink类型 配置与使用 附带案例1:消费Kafka写到Redis
点一下关注吧!!!非常感谢!!持续更新!!! 目前已经更新到了: Hadoop(已更完)HDFS(已更完)MapReduce(已更完)Hive(已更完)Flume(已更完)Sqoop(已更完)Zookeeper(已更完)HBase(已更完)Redis (已更完)Kafka(已更完)Spark(已更完)Flink(正在更新!) 章节内容 上节我们完成了如下的内容: Flink DataSt

Lesson_for_java_day18--java中的IO流(序列化、ByteArrayStream、DataStream、RandowAccessFile)
一、序列化: package sonyi;import java.io.FileInputStream;import java.io.FileNotFoundException;import java.io.FileOutputStream;import java.io.IOException;import java.io.ObjectInputStream;import java

Flink常用转换(transformation)算子使用教程(DataSTream API)
前言 一个 Flink 程序,其实就是对 DataStream 的各种转换。具体来说,代码基本上都由以下几部分构成,如下图所示: 获取执行环境(execution environment)读取数据源(source)定义基于数据的转换操作(transformations)定义计算结果的输出位置(sink)触发程序执行(execute) 数据源读入数据之后,我们就可以使用各种转换算子,将一

(九)基于 Flink DataStream API 应用案例
在 11.11 购物节大促活动中,天猫、京东等商家会对外发布购物节对应的交易金额、单量等信息,下面我们以 2023.11.11 购物节大促为背景,完成如下任务的计算: 问题1:每隔 1 秒统计购物节当日从零点开始,截止到当前时间总交易额。 问题2:基于销售的商品,按照品牌分类,每小时统计对应品牌下的总订单量。 基于上面的应用场景,结合 DataStream API,完

Flink常见数据源开发(DataStream API)
前言 一个 Flink 程序,其实就是对 DataStream 的各种转换。具体来说,代码基本上都由以下几部分构成,如下图所示: 获取执行环境(execution environment)读取数据源(source)定义基于数据的转换操作(transformations)定义计算结果的输出位置(sink)触发程序执行(execute) 本篇博客主要用DataStream API开发Flink
详解 Flink Table API 和 Flink SQL 之表和 DataStream 的转换
一、表转换为 DataStream /**Table API 中表到 DataStream 有两种模式:1.追加模式(Append Mode):用于表只会被插入(Insert)操作更改的场景。2.撤回模式(Retract Mode):用于任何场景。有些类似于更新模式中 Retract 模式,它只有 Insert 和 Delete 两类操作。得到的数据会增加一个 Boolean 类型的标识位(返回
![流批一体计算引擎-10-[Flink]中的常用算子和DataStream转换](https://img-blog.csdnimg.cn/direct/d05f4a2969834c3d826feb57eb0a90b9.png)
流批一体计算引擎-10-[Flink]中的常用算子和DataStream转换
pyflink 处理 kafka数据 1 DataStream API 示例代码 从非空集合中读取数据,并将结果写入本地文件系统。 from pyflink.common.serialization import Encoderfrom pyflink.common.typeinfo import Typesfrom pyflink.datastream import StreamEx

Flink DataStream ProcessFunction
专栏原创出处:github-源笔记文件 ,github-源码 ,欢迎 Star,转载请附上原文出处链接和本声明。 本节内容对应官方文档 1 ProcessFunction 是什么 ProcessFunction 是一个低阶的流处理操作,它可以访问流处理程序的基础构建模块: 事件 (event)(流元素)。状态 (state)(容错性,一致性,仅在keyed stream中)。定时器
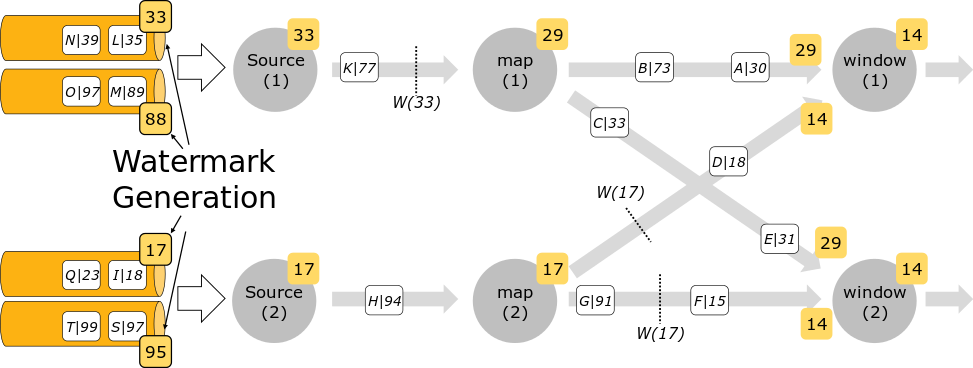
Flink DataStream时间水印机制
专栏原创出处:github-源笔记文件 ,github-源码 ,欢迎 Star,转载请附上原文出处链接和本声明。 本节内容对应官方文档 ,本节内容对应示例源码 1 Time(时间) 所有由 Flink 事件-时间流应用生成的条目都必须伴随着一个时间戳。时间戳将一个条目与一个特定的时间点关联起来,一般这个时间点表示的是这条 record 发生的时间。不过 application 可以随
Flink DataStream概览
专栏原创出处:github-源笔记文件 ,github-源码 ,欢迎 Star,转载请附上原文出处链接和本声明。 本节内容对应官方文档 1 简单示例程序 示例源码 object StreamingSimple extends StreamExecutionEnvironmentApp {val rolePayDataStream: DataStream[RolePay] = Ga
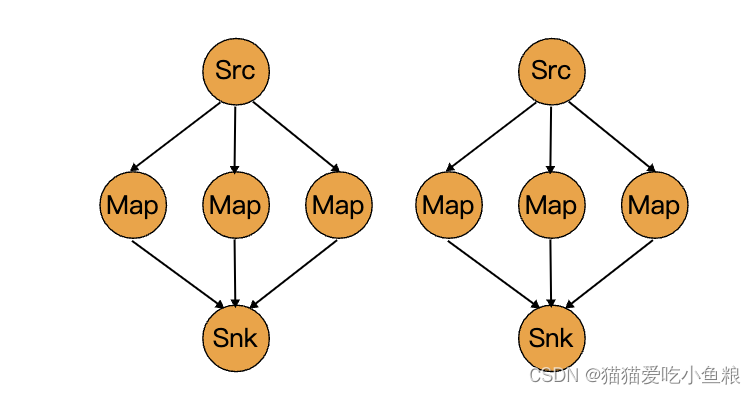
32、Flink 的 DataStream API 物理分区算子详解
3.物理分区 Flink 提供以下方法让用户根据需要在数据转换完成后对数据分区进行更细粒度的配置。 a)自定义分区 DataStream → DataStream 使用自定义的 Partitioner 为每个元素选择目标任务。 dataStream.partitionCustom(partitioner, "someKey");dataStream.partitionCustom(pa
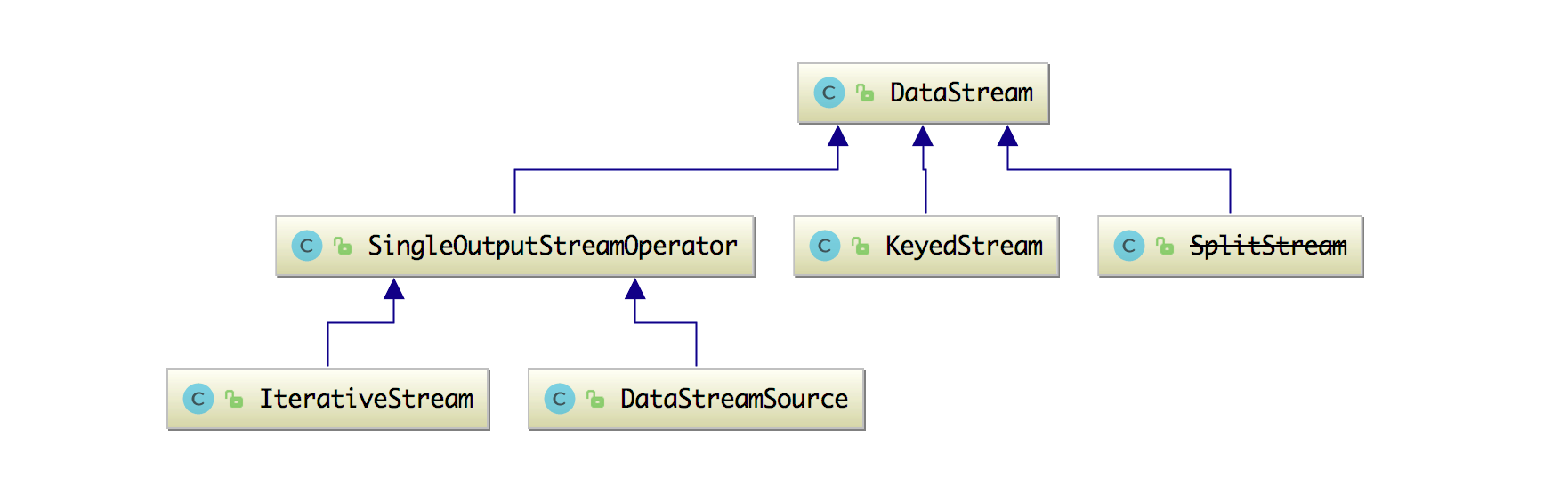
如何使用 DataStream API 来处理数据?
在 3.3 节中讲了数据转换常用的 Operators(算子),然后在 3.2 节中也讲了 Flink 中窗口的概念和原理,那么我们这篇文章再来细讲一下 Flink 中的各种 DataStream API。 我们先来看下源码里面的 DataStream 大概有哪些类呢? 可以发现其实还是有很多的类,只有熟练掌握了这些 API,我们才能在做数据转换和计算的时候足够灵活的运用开来(知道何时该选
1.18.2.8与DataStream和DataSet API结合,Scala隐式转换,通过DataSet或DataStream创建视图,将DataStream或DataSet转换成表 等
1.18.2.8.与DataStream和DataSet API结合 1.18.2.8.1.Scala隐式转换 1.18.2.8.2.通过DataSet或DataStream创建视图 1.18.2.8.3.将DataStream或DataSet转换成表 1.18.2.8.4.将表转换成DataStream或DataSet 1.18.2.8.5.将表转换成DataStream 1.18.2.8.5.

flink-java使用介绍,flink,java,DataStream API,DataSet API,ETL,设置 jobname
1、环境准备 文档:https://nightlies.apache.org/flink/flink-docs-release-1.17/zh/ 仓库:https://github.com/apache/flink 下载:https://flink.apache.org/zh/downloads/ 下载指定版本:https://archive.apache.org/dist/flink/flin

大数据学习之Flink算子、了解DataStream API(基础篇一)
DataStream API (基础篇) 注: 本文只涉及DataStream 原因:随着大数据和流式计算需求的增长,处理实时数据流变得越来越重要。因此,DataStream由于其处理实时数据流的特性和能力,逐渐替代了DataSet成为了主流的数据处理方式。 目录 DataStream API (基础篇) 前摘: 一、执行环境 1. 创建执行环境 2. 执行模式 3. 触
【Flink-1.17-教程】-【四】Flink DataStream API(3)转换算子(Transformation)【用户自定义函数(UDF)】
【Flink-1.17-教程】-【四】Flink DataStream API(3)转换算子(Transformation)【用户自定义函数(UDF)】 1)函数类(Function Classes)2)富函数类(Rich Function Classes) 用户自定义函数(user-defined function,UDF),即用户可以根据自身需求,重新实现算子的逻辑。 用户自
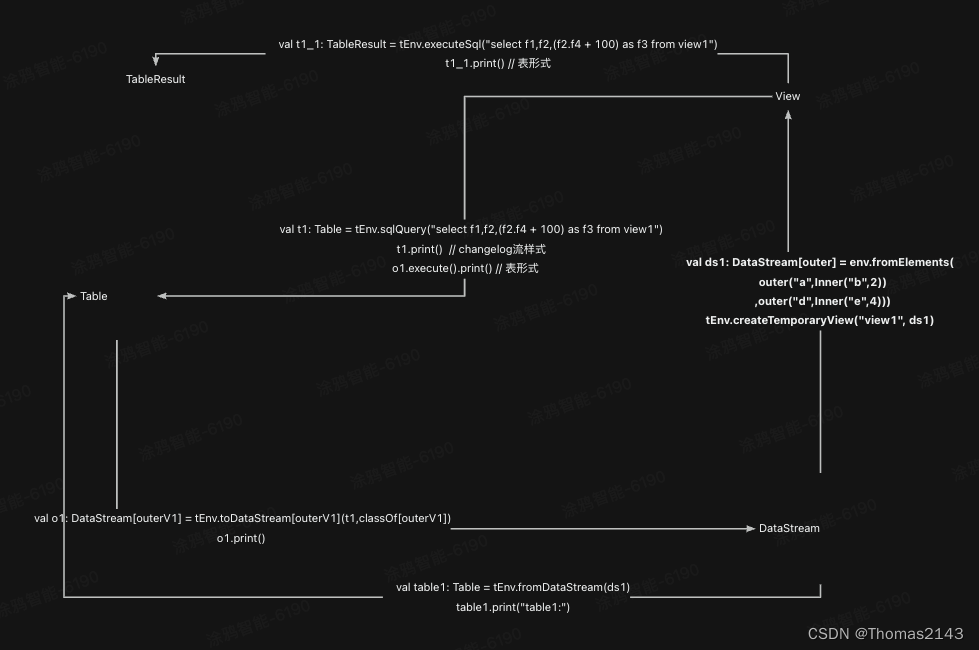
flink table view datastream互转
case class outer(f1:String,f2:Inner) case class outerV1(f1:String,f2:Inner,f3:Int) case class Inner(f3:String,f4:Int) 测试代码 package com.yy.table.convertimport org.apache.flink.streaming.api.scala.S

【Flink】FLINK-CDC之DataStream方式的应用(mysql篇)
1、mysql中创建表,注意,mysql要开启binlog,否则报错 CREATE TABLE `cdc_user` ( `id` BIGINT(11) NOT NULL, `name` VARCHAR(50) NULL DEFAULT NULL COLLATE 'utf8mb4_bin', `type` VARCHAR(50) NULL DEFAULT NULL CO

Flink-1.12 - 之 DataStream Join 类型
Flink-1.12 - 之 DataStream Join 本文主要以flink-1.12来讲述Flink DataStream Api中支持的Join。 DataStream Api提供2种类型的join方式。 Window Join Tumbling Window JoinSliding Window JoinSession Window Join Interval Join
Flink基础之DataStream API
流的合并 union联合:被unioin的流中的数据类型必须一致connect连接:合并的两条流的数据类型可以不一致 connec后,得到的是ConnectedStreams合并后需要根据数据流是否经过keyby分区 coConnect: 将两条数据流合并为同一数据类型keyedConnect public class Flink09_UnionConnectStream {public

Apache Flink(七):Apache Flink快速入门 - DataStream BATCH模式
🏡 个人主页:IT贫道_大数据OLAP体系技术栈,Apache Doris,Clickhouse 技术-CSDN博客 🚩 私聊博主:加入大数据技术讨论群聊,获取更多大数据资料。 🔔 博主个人B栈地址:豹哥教你大数据的个人空间-豹哥教你大数据个人主页-哔哩哔哩视频 下面使用Java代码使用DataStream API 的Batch 模式来处理批WordCount代码,方式如
Flink之DataStream API的转换算子
简单转换算子 函数的实现方式 自定义类,实现函数接口:编码麻烦,使用灵活匿名内部类:编码简单Lambda:编码简洁 public class Flink02_FunctionImplement {public static void main(String[] args) {//1.创建运行环境StreamExecutionEnvironment env = StreamExecutionE
Flink入门之DataStream API及kafka消费者
DataStream API 主要流程: 获取执行环境读取数据源转换操作输出数据Execute触发执行 获取执行环境 根据实际情况获取StreamExceptionEnvironment.getExecutionEnvironment(conf)创建本地环境StreamExecutionEnvironment.createLocalEnvironment()创建远程环境createRemoteE

Flink DataStream API之Operators
Flink DataStream API之Operators 官网位置:https://ci.apache.org/projects/flink/flink-docs-release-1.9/zh/dev/stream/operators/ Operators transform one or more DataStreams into a new DataStream. Programs c