本文主要是介绍流批一体计算引擎-10-[Flink]中的常用算子和DataStream转换,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
pyflink 处理 kafka数据

1 DataStream API 示例代码
从非空集合中读取数据,并将结果写入本地文件系统。
from pyflink.common.serialization import Encoder
from pyflink.common.typeinfo import Types
from pyflink.datastream import StreamExecutionEnvironment
from pyflink.datastream.connectors import StreamingFileSinkdef tutorial():env = StreamExecutionEnvironment.get_execution_environment()env.set_parallelism(1)ds = env.from_collection(collection=[(1, 'aaa'), (2, 'bbb')],type_info=Types.ROW([Types.INT(), Types.STRING()]))ds.add_sink(StreamingFileSink.for_row_format('output', Encoder.simple_string_encoder()).build())env.execute("tutorial_job")if __name__ == '__main__':tutorial()
(1)DataStream API应用程序首先需要声明一个执行环境
StreamExecutionEnvironment,这是流式程序执行的上下文。
后续将通过它来设置作业的属性(例如默认并发度、重启策略等)、创建源、并最终触发作业的执行。
env = StreamExecutionEnvironment.get_execution_environment()
env.set_parallelism(1)
(2)声明数据源
一旦创建了 StreamExecutionEnvironment 之后,可以使用它来声明数据源。
数据源从外部系统(如Apache Kafka、Rabbit MQ 或 Apache Pulsar)拉取数据到Flink作业里。
为了简单起见,本次使用元素集合作为数据源。
这里从相同类型数据集合中创建数据流(一个带有 INT 和 STRING 类型字段的ROW类型)。
ds = env.from_collection(collection=[(1, 'aaa'), (2, 'bbb')],type_info=Types.ROW([Types.INT(), Types.STRING()]))
(3)转换操作或写入外部系统
现在可以在这个数据流上执行转换操作,或者使用 sink 将数据写入外部系统。
本次使用StreamingFileSink将数据写入output文件目录中。
ds.add_sink(StreamingFileSink.for_row_format('output', Encoder.simple_string_encoder()).build())
(4)执行作业
最后一步是执行真实的 PyFlink DataStream API作业。
PyFlink applications是懒加载的,并且只有在完全构建之后才会提交给集群上执行。
要执行一个应用程序,只需简单地调用env.execute(job_name)。
env.execute("tutorial_job")

2 自定义转换函数的三种方式
三种方式支持用户自定义函数。
2.1 Lambda函数[简便]
from pyflink.common.typeinfo import Types
from pyflink.datastream import StreamExecutionEnvironmentenv = StreamExecutionEnvironment.get_execution_environment()
env.set_parallelism(1)data_stream = env.from_collection([1, 2, 3, 4, 5], type_info=Types.INT())
mapped_stream = data_stream.map(lambda x: x + 1, output_type=Types.INT())mapped_stream.print()
env.execute("tutorial_job")
2.2 python函数[简便]
from pyflink.common.typeinfo import Types
from pyflink.datastream import StreamExecutionEnvironmentdef my_map_func(value):return value + 1def main():env = StreamExecutionEnvironment.get_execution_environment()env.set_parallelism(1)data_stream = env.from_collection([1, 2, 3, 4, 5], type_info=Types.INT())mapped_stream = data_stream.map(my_map_func, output_type=Types.INT())mapped_stream.print()env.execute("tutorial_job")if __name__ == '__main__':main()
2.3 接口函数[复杂]
from pyflink.common.typeinfo import Types
from pyflink.datastream import StreamExecutionEnvironment, MapFunctionclass MyMapFunction(MapFunction):def map(self, value):return value + 1def main():env = StreamExecutionEnvironment.get_execution_environment()env.set_parallelism(1)data_stream = env.from_collection([1, 2, 3, 41, 5], type_info=Types.INT())mapped_stream = data_stream.map(MyMapFunction(), output_type=Types.INT())mapped_stream.print()env.execute("tutorial_job")if __name__ == '__main__':main()3 常用算子
参考官网算子
3.1 map【DataStream->DataStream】
from pyflink.common.typeinfo import Types
from pyflink.datastream import StreamExecutionEnvironmentenv = StreamExecutionEnvironment.get_execution_environment()
env.set_parallelism(1) # 将输出写入一个文件data_stream = env.from_collection([1, 2, 3, 4, 5], type_info=Types.INT())
mapped_stream = data_stream.map(lambda x: x + 1, output_type=Types.INT())mapped_stream.print()
env.execute("tutorial_job")
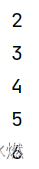
3.2 flat_map【DataStream->DataStream】
from pyflink.common.typeinfo import Types
from pyflink.datastream import StreamExecutionEnvironmentenv = StreamExecutionEnvironment.get_execution_environment()
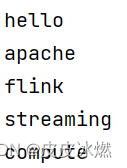
env.set_parallelism(1) # 将输出写入一个文件data_stream = env.from_collection(collection=['hello apache flink', 'streaming compute'])
out = data_stream.flat_map(lambda x: x.split(' '), output_type=Types.STRING())out.print()
env.execute("tutorial_job")
3.3 filter【DataStream->DataStream】
from pyflink.common.typeinfo import Types
from pyflink.datastream import StreamExecutionEnvironmentenv = StreamExecutionEnvironment.get_execution_environment()
env.set_parallelism(1) # 将输出写入一个文件def my_func(value):if value % 2 == 0:return valuedata_stream = env.from_collection([1, 2, 3, 4, 5], type_info=Types.INT())
filtered_stream = data_stream.filter(my_func)filtered_stream.print()
env.execute("tutorial_job")
3.4 window_all【DataStream->AllWindowedStream】
根据某些特征(例如,最近 100毫秒秒内到达的数据)对所有流事件进行分组。
所有的元素。
data_stream = env.from_collection(collection=[(1, 'm'), (3, 'n'), (2, 'm'), (4,'m')])
all_window_stream = data_stream.window_all(TumblingProcessingTimeWindows.of(Time.milliseconds(100)))
3.4.1 apply【AllWindowedStream->DataStream】
将通用 function 应用于整个窗口。
from typing import Iterablefrom pyflink.common import Time
from pyflink.datastream import StreamExecutionEnvironment
from pyflink.datastream.functions import AllWindowFunction
from pyflink.datastream.window import TumblingProcessingTimeWindows, TimeWindowenv = StreamExecutionEnvironment.get_execution_environment()
env.set_parallelism(1) # 将输出写入一个文件class MyAllWindowFunction(AllWindowFunction[tuple, int, TimeWindow]):def apply(self, window: TimeWindow, inputs: Iterable[tuple]) -> Iterable[int]:sum = 0for input in inputs:sum += input[0]yield sumdata_stream = env.from_collection(collection=[(1, 'm'), (3, 'n'), (2, 'm'), (4,'m')])
all_window_stream = data_stream.window_all(TumblingProcessingTimeWindows.of(Time.milliseconds(100)))
out = all_window_stream.apply(MyAllWindowFunction())out.print()
env.execute("tutorial_job")
3.5 key_by【DataStream->KeyedStream】
需要结合reduce或window算子使用。
data_stream = env.from_collection(collection=[(1, 'm'), (3, 'n'), (2, 'm'), (4,'m')])
key_stream = data_stream.key_by(lambda x: x[1], key_type=Types.STRING())
3.6 reduce【KeyedStream->DataStream】增量
from pyflink.common.typeinfo import Types
from pyflink.datastream import StreamExecutionEnvironmentenv = StreamExecutionEnvironment.get_execution_environment()
env.set_parallelism(1) # 将输出写入一个文件data_stream = env.from_collection(collection=[(1, 'm'), (3, 'n'), (2, 'm'), (4,'m')])
key_stream = data_stream.key_by(lambda x: x[1], key_type=Types.STRING())
out = key_stream.reduce(lambda a, b: (a[0]+b[0], a[1]))out.print()
env.execute("tutorial_job")
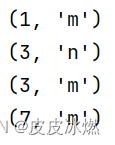
在相同 key 的数据流上“滚动”执行 reduce。
将当前元素与最后一次 reduce 得到的值组合然后输出新值。
3.7 window【KeyedStream->WindowedStream】
在已经分区的 KeyedStreams 上定义 Window。
data_stream = env.from_collection(collection=[(1, 'm'), (3, 'n'), (2, 'm'), (4,'m')])
key_stream = data_stream.key_by(lambda x: x[1], key_type=Types.STRING())
window_stream = key_stream.window(TumblingProcessingTimeWindows.of(Time.milliseconds(100)))
3.7.1 apply【WindowedStream->DataStream】
将通用 function 应用于整个窗口。
from typing import Iterablefrom pyflink.common import Time, Types
from pyflink.datastream import StreamExecutionEnvironment
from pyflink.datastream.functions import WindowFunction
from pyflink.datastream.window import TumblingProcessingTimeWindows, TimeWindowenv = StreamExecutionEnvironment.get_execution_environment()
env.set_parallelism(1) # 将输出写入一个文件class MyWindowFunction(WindowFunction[tuple, int, int, TimeWindow]):def apply(self, key: int, window: TimeWindow, inputs: Iterable[tuple]) -> Iterable[int]:sum = 0for input in inputs:sum += input[0]yield key, sumdata_stream = env.from_collection(collection=[(1, 'm'), (3, 'n'), (2, 'm'), (4,'m')])
key_stream = data_stream.key_by(lambda x: x[1], key_type=Types.STRING())
window_stream = key_stream.window(TumblingProcessingTimeWindows.of(Time.milliseconds(10)))
out = window_stream.apply(MyWindowFunction())out.print()
env.execute("tutorial_job")
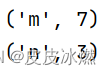
3.7.2 reduce【WindowedStream->DataStream】
from pyflink.common import Time
from pyflink.common.typeinfo import Types
from pyflink.datastream import StreamExecutionEnvironment
from pyflink.datastream.window import TumblingEventTimeWindows,TumblingProcessingTimeWindowsenv = StreamExecutionEnvironment.get_execution_environment()
env.set_parallelism(1) # 将输出写入一个文件data_stream = env.from_collection(collection=[(1, 'm'), (3, 'n'), (2, 'm'), (4,'m')])
key_stream = data_stream.key_by(lambda x: x[1], key_type=Types.STRING())
window_stream = key_stream.window(TumblingProcessingTimeWindows.of(Time.milliseconds(10)))
out = window_stream.reduce(lambda a, b: (a[0]+b[0], a[1]))out.print()
env.execute("tutorial_job")

方式二
from pyflink.common import Time
from pyflink.common.typeinfo import Types
from pyflink.datastream import StreamExecutionEnvironment, ReduceFunction
from pyflink.datastream.window import TumblingProcessingTimeWindowsenv = StreamExecutionEnvironment.get_execution_environment()
env.set_parallelism(1) # 将输出写入一个文件class MyReduceFunction(ReduceFunction):def reduce(self, value1, value2):return value1[0] + value2[0], value1[1]data_stream = env.from_collection(collection=[(1, 'm'), (3, 'n'), (2, 'm'), (4,'m')])
key_stream = data_stream.key_by(lambda x: x[1], key_type=Types.STRING())
window_stream = key_stream.window(TumblingProcessingTimeWindows.of(Time.milliseconds(10)))
out = window_stream.reduce(MyReduceFunction())out.print()
env.execute("tutorial_job")
3.8 union【DataStream*->DataStream】
将两个或多个数据流联合来创建一个包含所有流中数据的新流。
注意:如果一个数据流和自身进行联合,这个流中的每个数据将在合并后的流中出现两次。
from pyflink.datastream import StreamExecutionEnvironment
env = StreamExecutionEnvironment.get_execution_environment()
env.set_parallelism(1) # 将输出写入一个文件data_stream1 = env.from_collection(collection=[(1, 'm'), (3, 'n'), (2, 'm'), (4,'m')])
data_stream2 = env.from_collection(collection=[(1, 'a'), (3, 'b'), (2, 'a'), (4,'a')])
out = data_stream2.union(data_stream1)out.print()
env.execute("tutorial_job")
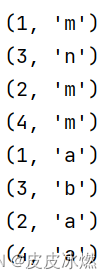
3.9 connect【DataStream,DataStream->ConnectedStream】
stream_1 = ...
stream_2 = ...
connected_streams = stream_1.connect(stream_2)
3.9.1 CoMap【ConnectedStream->DataStream】
from pyflink.datastream import StreamExecutionEnvironment, CoMapFunctionenv = StreamExecutionEnvironment.get_execution_environment()
env.set_parallelism(1) # 将输出写入一个文件data_stream1 = env.from_collection(collection=[(1, 'm'), (3, 'n'), (2, 'm'), (4,'m')])
data_stream2 = env.from_collection(collection=[(1, 'a'), (3, 'b'), (2, 'a'), (4,'a')])
connected_stream = data_stream1.connect(data_stream2)class MyCoMapFunction(CoMapFunction):def map1(self, value):return value[0] *100, value[1]def map2(self, value):return value[0], value[1] + 'flink'out = connected_stream.map(MyCoMapFunction())out.print()
env.execute("tutorial_job")

3.9.2 CoFlatMap【ConnectedStream->DataStream】
from pyflink.datastream import StreamExecutionEnvironment, CoFlatMapFunctionenv = StreamExecutionEnvironment.get_execution_environment()
env.set_parallelism(1) # 将输出写入一个文件data_stream1 = env.from_collection(collection=[(1, 'm'), (3, 'n'), (2, 'm'), (4,'m')])
data_stream2 = env.from_collection(collection=[(1, 'a'), (3, 'b'), (2, 'a'), (4,'a')])
connected_stream = data_stream1.connect(data_stream2)class MyCoFlatMapFunction(CoFlatMapFunction):def flat_map1(self, value):for i in range(value[0]):yield value[0]*100def flat_map2(self, value):yield value[0] + 10out = connected_stream.flat_map(MyCoFlatMapFunction())out.print()
env.execute("tutorial_job")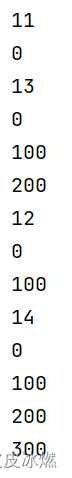
4 对接kafka输入json输出json
输入{“name”:“中文”}
输出{“name”:“中文结果”}
from pyflink.common import SimpleStringSchema, WatermarkStrategy, Types
from pyflink.datastream import StreamExecutionEnvironment, RuntimeExecutionMode
from pyflink.datastream.connectors.kafka import KafkaSource, KafkaOffsetsInitializer, KafkaSink, \KafkaRecordSerializationSchema
import jsonenv = StreamExecutionEnvironment.get_execution_environment()
env.set_runtime_mode(RuntimeExecutionMode.STREAMING)
env.set_parallelism(1)brokers = "IP:9092"# 读取kafka
source = KafkaSource.builder() \.set_bootstrap_servers(brokers) \.set_topics("flink_source") \.set_group_id("my-group") \.set_starting_offsets(KafkaOffsetsInitializer.latest()) \.set_value_only_deserializer(SimpleStringSchema()) \.build()ds1 = env.from_source(source, WatermarkStrategy.no_watermarks(), "Kafka Source")
ds1.print()# 处理流程
def process_fun(line):data_dict = json.loads(line)result_dict = {"result": data_dict.get("name", "无")+"结果"}return json.dumps(result_dict, ensure_ascii=False)ds2 = ds1.map(process_fun, Types.STRING())
ds2.print()
这篇关于流批一体计算引擎-10-[Flink]中的常用算子和DataStream转换的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!






