流批专题

flink流批一体概念与配置
flink流批一体概念与配置 什么时候可以/应该使用批处理执行模式?配置批处理执行模式流批执行模式的区别任务调度和网络Shuffle流执行模式批量执行模式 状态后端/状态处理顺序事件时间/水印处理时间故障恢复 需要注意的点检查点编写自定义操作符 什么时候可以/应该使用批处理执行模式? BATCH执行模式只能用于有界的数据源。有界性是数据源的一个属性,它告诉我们来自该数据源的所有
![流批一体计算引擎-10-[Flink]中的常用算子和DataStream转换](https://img-blog.csdnimg.cn/direct/d05f4a2969834c3d826feb57eb0a90b9.png)
流批一体计算引擎-10-[Flink]中的常用算子和DataStream转换
pyflink 处理 kafka数据 1 DataStream API 示例代码 从非空集合中读取数据,并将结果写入本地文件系统。 from pyflink.common.serialization import Encoderfrom pyflink.common.typeinfo import Typesfrom pyflink.datastream import StreamEx

Flink 流批一体在模型特征场景的使用
摘要:本文整理自B站资深开发工程师张杨老师在 Flink Forward Asia 2023 中 AI 特征工程专场的分享。内容主要为以下四部分: 模型特征场景流批一体性能优化未来展望 一、 模型特征场景 以下是一个非常简化并且典型的线上实时特征和样本的生产过程。 前面是一个 Show 和 Click ,也就是点击展现实时流,数据上报到 kafka 后在 Flink 里面进行 Jo
再见,Spark!流批一体神器 Flink 已成气候!!!
身为大数据工程师,你还在苦学Spark、Hadoop、Storm,却还没搞过Flink?醒醒吧!刚过去的2020双11,阿里在Flink实时计算技术的驱动下全程保持了“如丝般顺滑”,基于Flink的阿里巴巴实时计算平台简直强·无敌。 最恐怖的是,阿里当时的实时计算峰值达到了破纪录的每秒40亿条记录,数据量也达到了惊人的7TB每秒,相当于一秒钟需要读完500万本《新华字典》!Flink的强悍之处,

2021年最新最全Flink系列教程_Flink原理初探和流批一体API(二.五)
引言 大家好,我是ChinaManor,直译过来就是中国码农的意思,我希望自己能成为国家复兴道路的铺路人,大数据领域的耕耘者,平凡但不甘于平庸的人。 下面为大家带来阿里巴巴极度热推的Flink,实时数仓是未来的方向,学好Flink,月薪过万不是梦!! 相关教程直通车: 2021年最新最全Flink系列教程_Flink快速入门(概述,安装部署)(一) 2021年最新最全Flink系

flinksql流批一体计算平台为什么选型是Streamx
flink实时计算平台为什么选型是Streamx 一、概述 1.1 背景 Apache Flink被普遍认为是下一代大数据流计算引擎, 我们在使用 Flink 时发现从编程模型, 启动配置到运维管理都有很多可以抽象共用的地方, 我们将一些好的经验固化下来并结合业内的最佳实践, 通过不断努力终于诞生了今天的框架 —— StreamX, 项目的初衷是 —— 让 Flink 开发更简单, 使用

Doris——纵腾集团流批一体数仓架构
目录 前言 一、早期架构 二、架构选型 三、新数据架构 3.1 数据中台 3.2 数仓建模 3.3 数据导入 四、实践经验 4.1 准备阶段 4.2 验证阶段 4.3 压测阶段 4.4 上线阶段 4.5 宣导阶段 4.6 运行阶段 4.6.1 Tablet规范问题 4.6.2 集群读写优化 五、总结收益 六、未来规划 原文大佬的这篇Doris数仓建
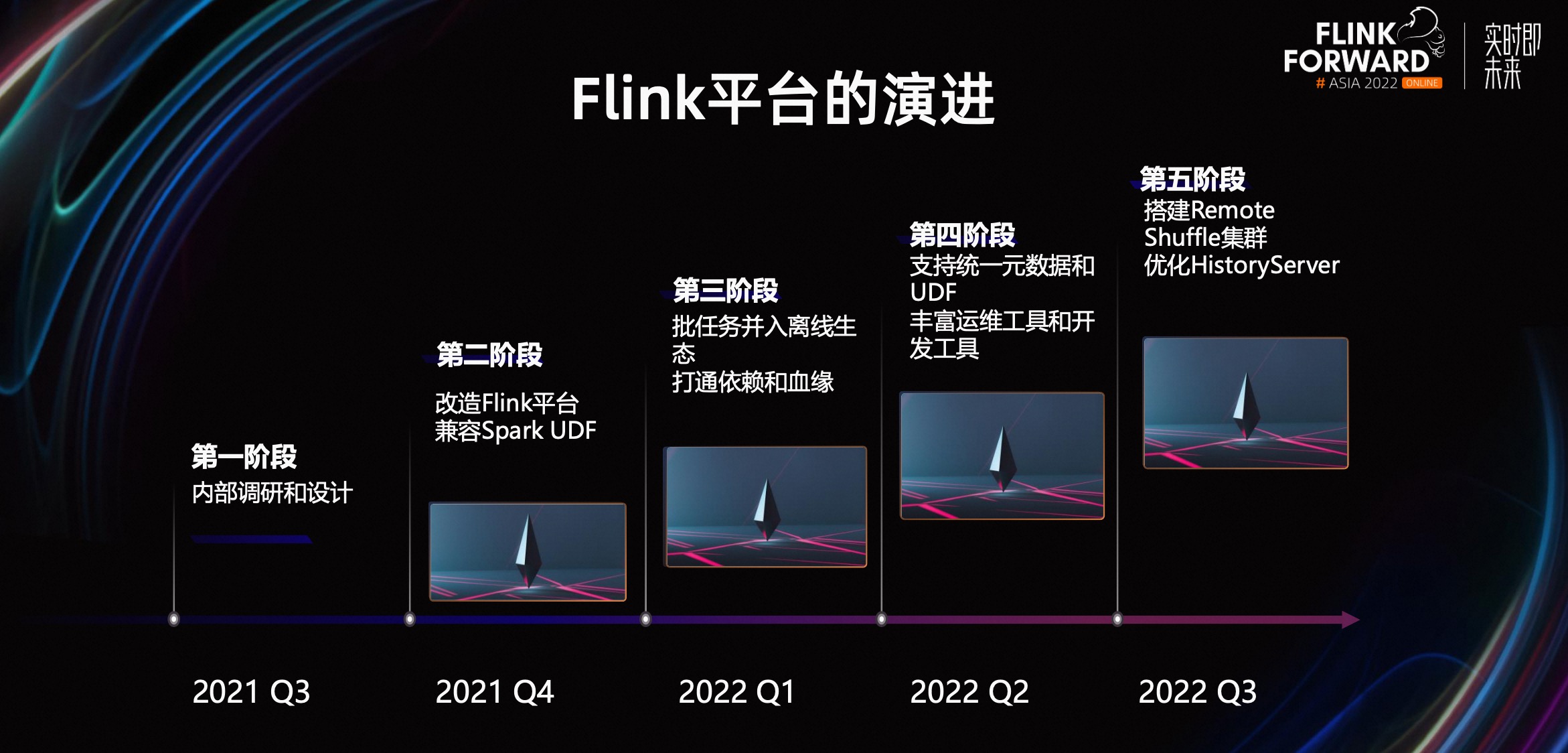
Flink 流批一体在 Shopee 的大规模实践
摘要:本文整理自 Shopee 研发专家李明昆,在 Flink Forward Asia 2022 流批一体专场的分享。本篇内容主要分为四个部分: 流批一体在 Shopee 的应用场景 批处理能力的生产优化 与离线生态的完全集成 平台在流批一体上的建设和演进 点击查看原文视频 & 演讲PPT 一、流批一体在 Shopee 的应用场景 首先,先来了解一下 Flink 在 Sho

数据平台:湖仓一体、流批一体、存算分离的核心问题
一、为什么出现湖仓一体的技术架构 目前数据仓库存储的数据结构单一,只能存储结构化的数据,对于非结构化数据的存储需求,以及存储成本是数据仓库的主要问题,而非结构化数据存储在业务库,也造成数据不能相融和利用,为了解决非结构化数据的低成本的存储诞生了湖仓一体的技术架构。 湖仓一体的技术架构是指将数据湖(Data Lake)和数据仓库(Data Warehouse)结合在一起,实现对各

FeatHub:流批一体的实时特征工程平台
摘要:本文整理自阿里巴巴高级技术专家、Apache Flink/Kafka PMC 林东,在 FFA 2022 AI 特征工程专场的分享。本篇内容主要分为三个部分: 为什么需要 FeatHubFeatHub 架构和概念FeatHub API 展示 点击查看直播回放和演讲 PPT 一、为什么需要 FeatHub 1.1 目标场景 上图中展示的是 Feathub 需要支持的目标场景。
StreamX流批一体一站式大数据平台:大数据Flink可视化工具的革命性突破,让你的数据更高效、更直观!
介绍:StreamX,开源的流批一体一站式大数据平台,致力于让Flink开发更简单。它极大地降低了学习成本和开发门槛,使开发者可以专注于最核心的业务。StreamX支持Flink多版本, 与Flink SQL WebIDE兼容,并可以进行Flink SQL校验。此外,StreamX还提供了一套标准化的配置、开发、测试、部署、监控、运维的解决方案,包括一系列开箱即用的Connectors。 一个独特
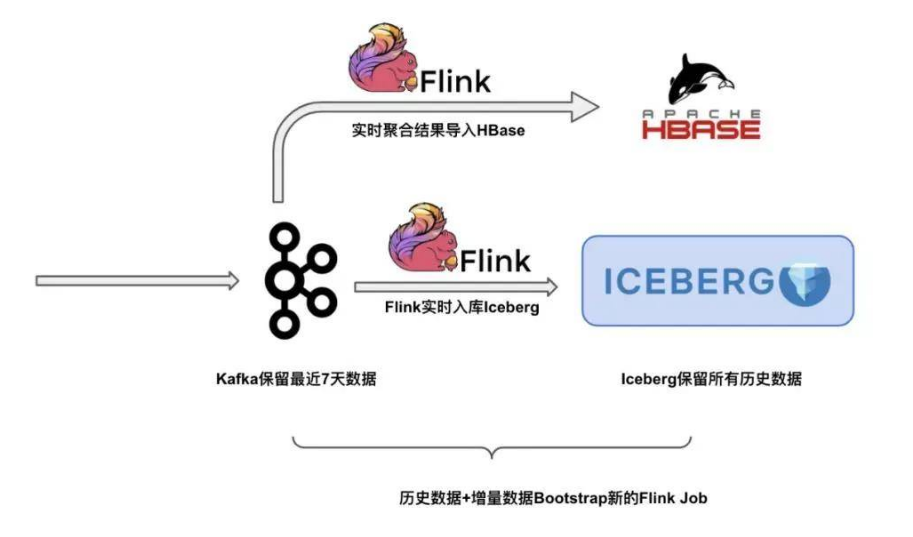
Flink + Iceberg打造流批一体的数据湖架构
一、背景 1、数据仓库架构 从Hive表出仓到外部系统(ClickHouse、Presto、ES等)带来的复杂性和存储开发等额外代价,尽量减少这种场景出仓的必要性。 痛点:传统 T+1 任务 海量的TB级 T+ 1 任务延迟导致下游数据产出时间不稳定。 任务遇到故障重试恢复代价昂贵 数据架构在处理去重和 exactly-once语义能力方面比较吃力 架构复杂,
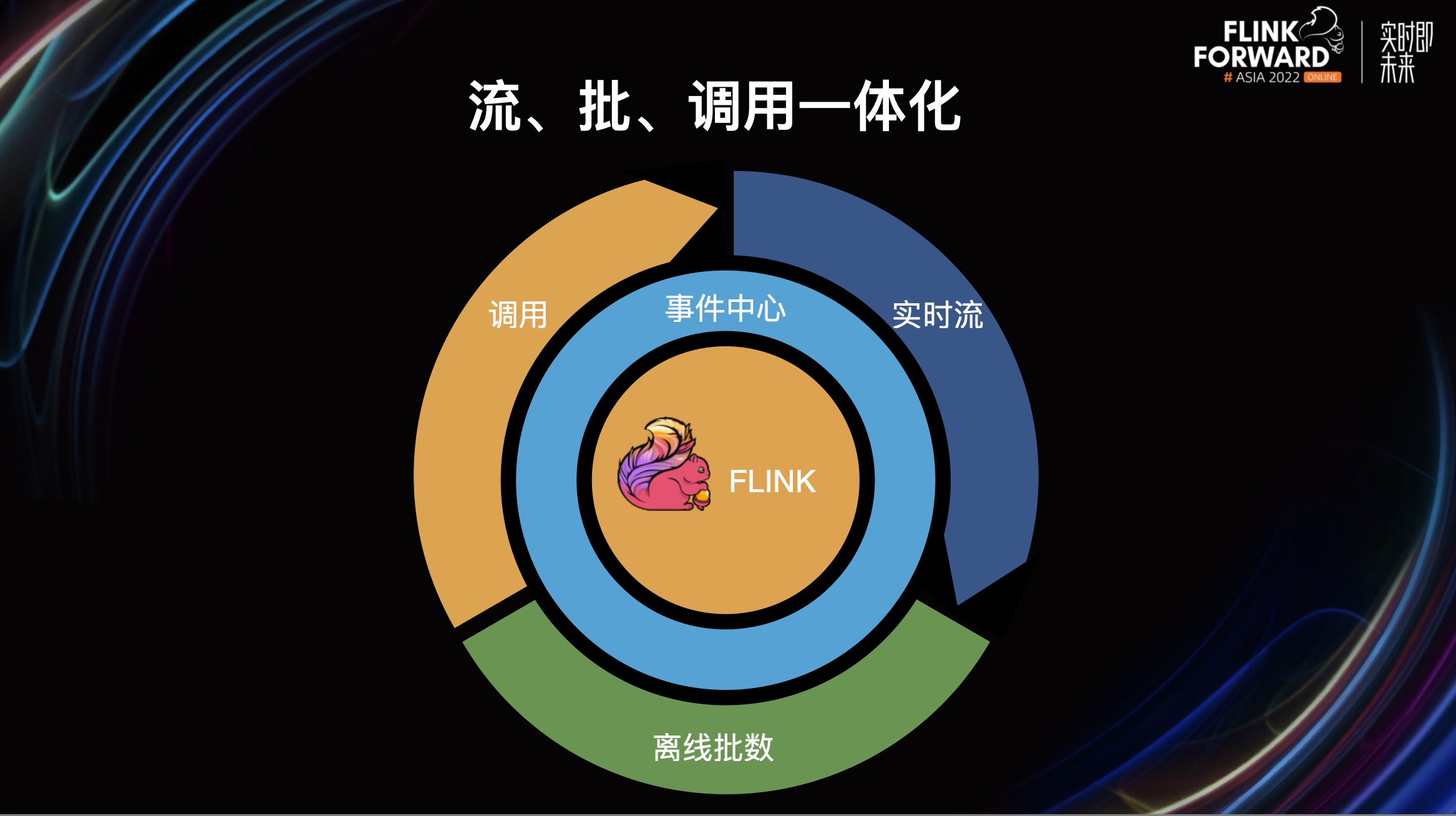
Flink 流批一体方案在数禾的实践
摘要:本文整理自上海数⽲信息科技有限公司⼤数据架构师杨涵冰,在 Flink Forward Asia 2022 流批一体专场的分享。本篇内容主要分为六个部分: 序传统方案与流批⼀体数据的流批一体方案逻辑的流批一体方案数据一致性方案流、批、调用一体方案 点击查看直播回放和演讲 PPT 一、序 1.1. 一些问题 我们在整个实时流模型开发的过程中,经常会遇到一些问题: 在对现有模型策略精

Flink流批一体计算(24):Flink SQL之mysql维表实时关联
目录 1.维表 2.数据准备 创建源数据 创建维度表 创建Sink表 3.配置任务 Flink SQL创建kafka源表 Flink SQL创建MySQL维表 Flink SQL创建MySQL结果表 编写计算任务 核验数据 1.维表 目前在实时计算的场景中,大多数都使用过MySQL、Hbase、redis作为维表引擎存储一些维度数据,然后在DataSt
Flink流批一体计算(23):Flink SQL之多流kafka写入多个mysql sink
目录 1. 准备工作 生成数据 创建数据表 2. 创建数据表 创建数据源表 创建数据目标表 3. 计算 WITH子句 1. 准备工作 生成数据 source kafka json 数据格式 : topic case_kafka_mysql: {"ts": "20201011","id": 8,"price_amt":211} topic flink_t
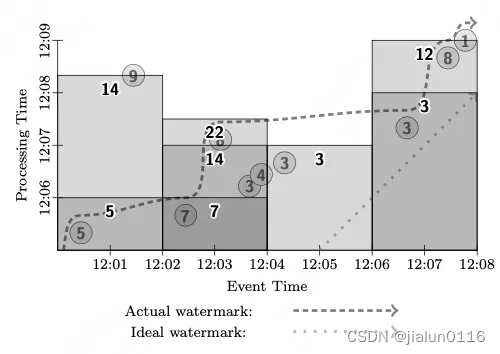
流批一体历史背景及基础介绍
目录 一、历史背景1.BI系统2.传统大数据架构3.流式架构4.Lambda架构5.Kappa架构 二、流批一体与数据架构的关系数据分析型应用数据管道型应用 三、流与批的桥梁Dataflow模型四、Dataflow模型的本质一个基本点两个时间域三个子模型1.窗口模型2.触发器模型3. 增量计算模型 四个分析维度 五、举例固定窗口,批处理固定窗口,流处理,多种触发方式 一、历史背景
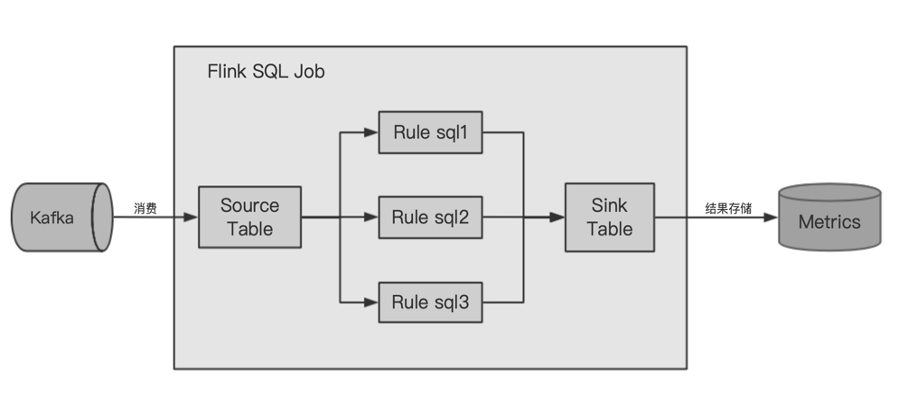
构建满足流批数据质量监控用火山引擎DataLeap
更多技术交流、求职机会,欢迎关注字节跳动数据平台微信公众号,回复【1】进入官方交流群 面对今日头条、抖音等不同产品线的复杂数据质量场景,火山引擎 DataLeap 数据质量平台如何满足多样的需求?本文将介绍我们在弥合大数据场景下数据质量校验与计算消耗资源大、校验计算时间长的冲突等方面的经验,同时介绍火山引擎 DataLeap 数据质量平台是如何用一套架构框架来满足流批方面的数据质量监控
构建满足流批数据质量监控用火山引擎DataLeap
更多技术交流、求职机会,欢迎关注字节跳动数据平台微信公众号,回复【1】进入官方交流群 面对今日头条、抖音等不同产品线的复杂数据质量场景,火山引擎 DataLeap 数据质量平台如何满足多样的需求?本文将介绍我们在弥合大数据场景下数据质量校验与计算消耗资源大、校验计算时间长的冲突等方面的经验,同时介绍火山引擎 DataLeap 数据质量平台是如何用一套架构框架来满足流批方面的数据质量监控
Flink流批一体计算(22):Flink SQL之单流kafka写入mysql
1. 准备工作 什么是Kafka源表 Kafka是分布式、高吞吐、可扩展的消息队列服务,广泛用于日志收集、监控数据聚合、流式数据处理、在线和离线分析等大数据领域。 docker部署zookeeper docker pull wurstmeister/zookeeperdocker run -d --restart=always \--log-driver json-file \--lo
流批一体历史背景及基础介绍
目录 一、历史背景1.BI系统2.传统大数据架构3.流式架构4.Lambda架构5.Kappa架构 二、流批一体与数据架构的关系数据分析型应用数据管道型应用 三、流与批的桥梁Dataflow模型四、Dataflow模型的本质一个基本点两个时间域三个子模型1.窗口模型2.触发器模型3. 增量计算模型 四个分析维度 五、举例固定窗口,批处理固定窗口,流处理,多种触发方式 一、历史背景
Flink流批一体计算(21):Flink SQL之Flink DDL
目录 执行 CREATE 语句 Python脚本 Java代码 SQL语句 列定义 物理/常规列 元数据列 计算列 WATERMARK PRIMARY KEY PARTITIONED BY AS select_statement Flink SQL是为了简化计算模型、降低您使用Flink门槛而设计的一套符合标准SQL语义的开发语言。 执行 CREATE 语句
Flink流批一体计算(22):Flink SQL之单流kafka写入mysql
1. 准备工作 什么是Kafka源表 Kafka是分布式、高吞吐、可扩展的消息队列服务,广泛用于日志收集、监控数据聚合、流式数据处理、在线和离线分析等大数据领域。 docker部署zookeeper docker pull wurstmeister/zookeeperdocker run -d --restart=always \--log-driver json-file \--lo

从 Spark 做批处理到 Flink 做流批一体
摘要:本⽂主要内容为: 为什么要做流批一体?当前行业已有的解决方案和现状,优势和劣势探索生产实践场景的经验Shuflle Service 在 Spark 和 Flink 上的对比,以及 Flink 社区后面可以考虑做的工作总结 一、为什么要做流批一体 做流批一体到底有哪些益处,尤其是在 BI/AI/ETL 的场景下。整体来看,如果能帮助用户做到流批一体,会有以上 4 个比较明显的益处: 可以避

Flink1.14.3流批一体体验
前言 Flink自从1.10就喊着要搞流批一体,据说1.14是个里程碑,特意体验下。 变化 DataSet消失 笔者隐约记得,Flink1.8老版本和Spark很像,同样分Stream流处理和DataSet批处理。新版本中: package com.zhiyong.flinkStudy;import org.apache.flink.api.common.functions.FlatMa