本文主要是介绍FeatHub:流批一体的实时特征工程平台,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
摘要:本文整理自阿里巴巴高级技术专家、Apache Flink/Kafka PMC 林东,在 FFA 2022 AI 特征工程专场的分享。本篇内容主要分为三个部分:
- 为什么需要 FeatHub
- FeatHub 架构和概念
- FeatHub API 展示
点击查看直播回放和演讲 PPT
一、为什么需要 FeatHub
1.1 目标场景

上图中展示的是 Feathub 需要支持的目标场景。
首先,考虑到机器学习开发者通常是熟悉 Python 环境的数据科学家,他们通常使用诸如 TensorFlow、PyTorch 和 Scikit-Learn 等 Python 算法库进行机器学习的训练和推理作业开发。因此,我们希望继续支持他们使用 Python 进行特征工程开发,以便他们的特征生成作业代码可以与现有的 Python 算法库进行无缝对接。
其次,考虑到目前各个业务领域(如推荐和风控)正在逐渐向实时方向发展,我们希望能够使这些业务的特征工程作业能够像生成离线特征一样轻松地生成实时特征。
第三,考虑到越来越多的企业用户不想受限于特定的云厂商,他们对于多云部署有着强烈的需求。因此,我们计划通过将项目的核心代码开源,允许用户在任意的公有云和私有云上部署 FeatHub。
1.2 实时特征工程的痛点

与离线特征相比,使用实时特征会涉及到额外的痛点,包括实时特征工程的开发、部署、监控和分享四个阶段的覆盖。
在开发阶段,由于特征随着时间而变化,可能会发生特征穿越的问题。为了确保作业生成正确的特征,用户需要在 Flink 作业中编写代码处理时间戳信息,以避免出现特征穿越的情况。对于许多用户,特别是那些专注于算法开发的数据科学家,避免特征穿越的开发成本相对较高。
当数据科学家完成特征开发后,他们需要将特征作业部署到生产环境,并实现高吞吐和低延迟的特征生产。通常情况下,平台方需要提供一些软件工程师来协助数据科学家将实验程序转换为高性能、高可用的分布式程序进行执行,这些作业可能是 Flink 或 Spark。这个转换阶段引入了额外的人力和时间成本,可能会引入更多的错误,同时也可能导致开发周期延长、浪费人力资源等问题。
在监控阶段,用户需要监控已经完成线上部署的实时特征工程作业。监控的难度较大,因为特征质量不仅取决于代码是否存在 bug,还取决于是否受到上游数据源数值分布变化的影响。
当整个作业的推荐效果下降时,通常需要手动检查每个阶段的特征分布变化,以定位问题产生的阶段并进一步进行调试。目前,这一过程需要投入大量人力,导致效率低下。为了加速实时特征工程的部署和运作,我们希望进一步降低监控的难度和人力消耗。
在分享阶段,不同组开发实时特征工程时常常需要定义相似甚至相同的特征。缺乏元数据中心使得开发者难以注册、搜索和复用特征定义和特征数据。因此,他们不得不重复进行开发工作和运行相同的作业,导致资源浪费。为了解决这个问题,我们希望支持用户在一个中心化的元数据中心中搜索、分享和复用已有特征,以降低重复开发的成本。
1.3 point-in-time correct 语义

接下来将举例为大家介绍什么是特征穿越。在上图的示例中,我们有两个数据源,分别代表维表特征和样本数据。维表特征描述了用户在最近两分钟内点击网页的次数,而样本数据描述了用户在看了一个网页后是否有点击广告的行为。
我们希望将这两个数据源中的数据进行拼接,以产生训练样本,进而用于 TensorFlow、PyTorch 等机器学习程序的训练和推理。如果我们在进行样本拼接时,未正确考虑数据的时间因素,可能会影响模型的推理效果。
在上图的例子中,我们可以使用用户 ID 作为 Join Key,将这两个表进行拼接。然而,如果在拼接维表特征时未考虑时间戳,只使用表中最新的点击数,那么我们得到的训练数据中,所有样本的“最近 2 分钟点击数”特征值都会是 6。这个结果与真实情况不符,会降低模型的推理效果。

具有“point-in-time correct”语义的拼接,会比对样本数据和维表特征的时间戳,找到维表特征中时间戳小于样本时间戳、但最接近样本时间戳、并且具有对应 Join Key 的特征作为拼接后的特征值。
在上图的例子中,6:03 时刻的特征值应该来自于 6:00 时刻用户的点击数 10。因此,在生成的训练数据中,6:03 时刻的样本数据中的点击数是 10。
而在 7:05 时刻,由于特征值在 7:00 时刻变为 6,因此在生成的训练数据中,这个样本对应的特征值也是 6。这就是使用”point-in-time correct“语义进行拼接所得到的结果。这种方式可以避免特征穿越问题。
1.4 Feature Store 的核心场景
上图展示了 Feature Store 的核心场景。Feature Store 是一个近两年兴起的概念,旨在解决刚才描述的特征工程场景中的核心痛点,包括特征的开发、部署、监控、共享等阶段。那么,Feature Store 是如何解决这些阶段的痛点的呢?
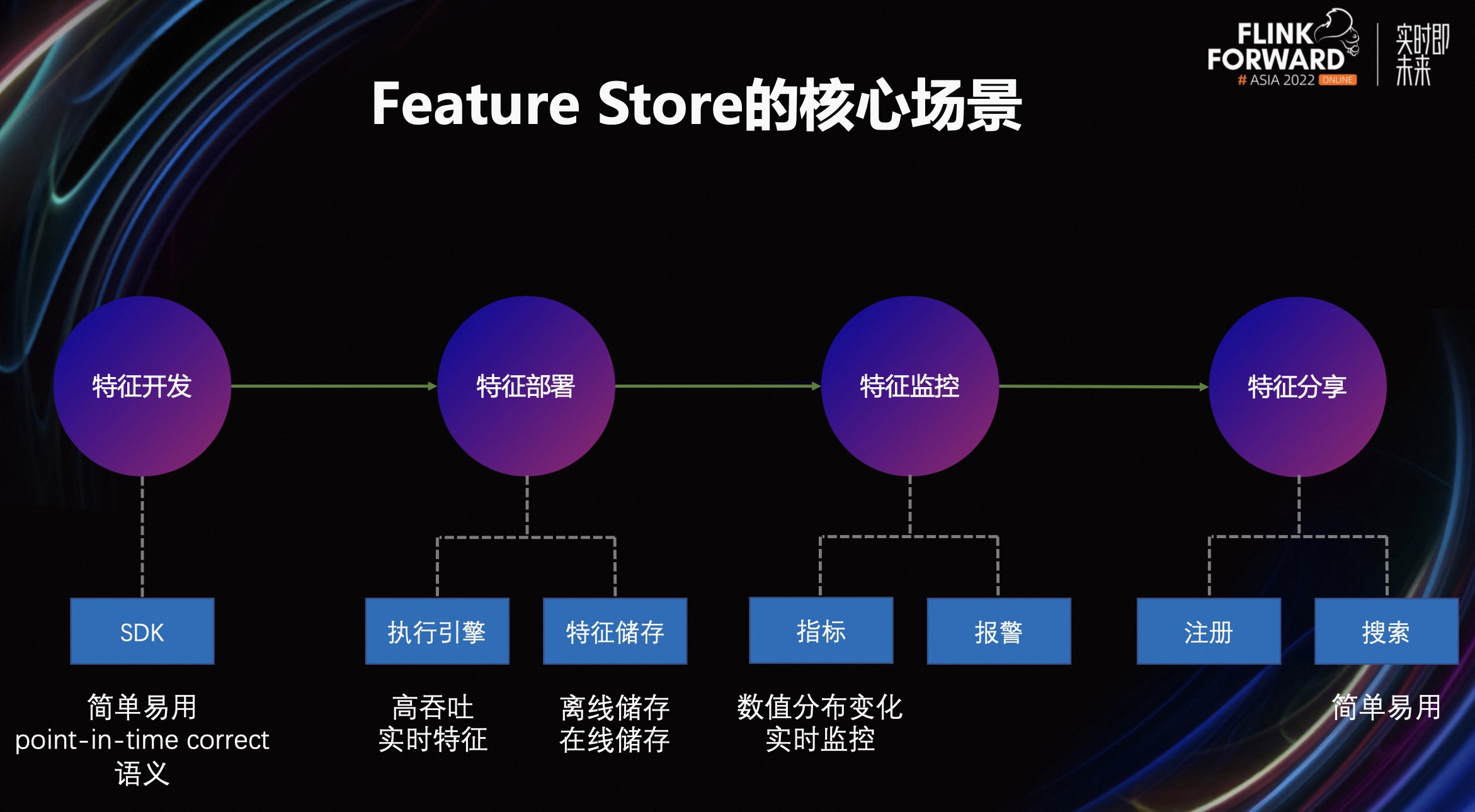
下面我们将分阶段说明 Feature Store 的核心价值。
在特征开发阶段,Feature Store 可以提供一个简单易用的 SDK,让用户专注于定义特征的计算逻辑,例如拼接、聚合、UDF 调用,而无需实现处理特征穿越问题的逻辑。这将极大简化数据科学家定义和使用实时特征的工作。
在特征部署阶段,Feature Store 将使用内置的执行引擎来计算并生成用户定义好的特征,这样用户就不需要直接面对 Spark 或 Flink 等项目的编程 API 来开发分布式作业了。执行引擎需要支持高吞吐、低延迟的特征计算。同时,Feature Store 可以提供丰富的连接器选择,支持用户从不同的数据源和数据存储中读取和写入数据。
在特征监控阶段,Feature Store 可以提供一些通用的标准化指标,让用户可以实时监控特征数值的分布变化,并支持告警引入人工干预来检查和维护机器学习链路的推理效果。
在特征分析阶段,Feature Store 将提供特征元数据中心,支持用户注册、搜索和复用特征,鼓励大家合作分享,以减少重复的开发工作。
1.5 为什么需要 FeatHub

虽然已经有几个开源的 Feature Store,例如 Feast 和 Feather,但为什么我们还要开发 FeatHub 呢?
在开发 FeatHub 之前,我们调研了现有的开源 Feature Store 和一些云厂商的 Feature Store(例如 Google Vertex AI、Amazon SageMaker),发现它们提供的 SDK 在能力和易用性方面并不能满足我们之前描述的需求(例如实时特征、Python SDK、开源)。因此,我们重新设计了一套 Python SDK,进一步支持实时特征,并且让 SDK 更加简单易用。我们将在介绍 FeatHub API 时进一步讨论其易用性。
除了支持实时特征和更加易用之外,FeatHub 的架构能够支持多种执行引擎,例如 Flink、Spark 以及基于 Pandas 库实现的单机执行引擎。这使得 FeatHub 能够在单机上快速进行实验和开发,并随时切换到分布式的 Flink/Spark 集群中进行分布式高性能计算。用户可以根据需求选择最合适的执行引擎。这也使得 FeatHub 具有非常好的可扩展性。这些特性是其他开源 Feature Store 所不具备的。
在生产部署阶段,我们希望 FeatHub 能够以最高效的方式计算实时特征。目前大部分开源 Feature Store 只支持使用 Spark 计算离线特征。而 FeatHub 支持使用 Flink,这是目前流计算领域最好的执行引擎,来计算实时特征。这个能力是其他 Feature Store 所没有的。
二、FeatHub 架构和概念
2.1 架构
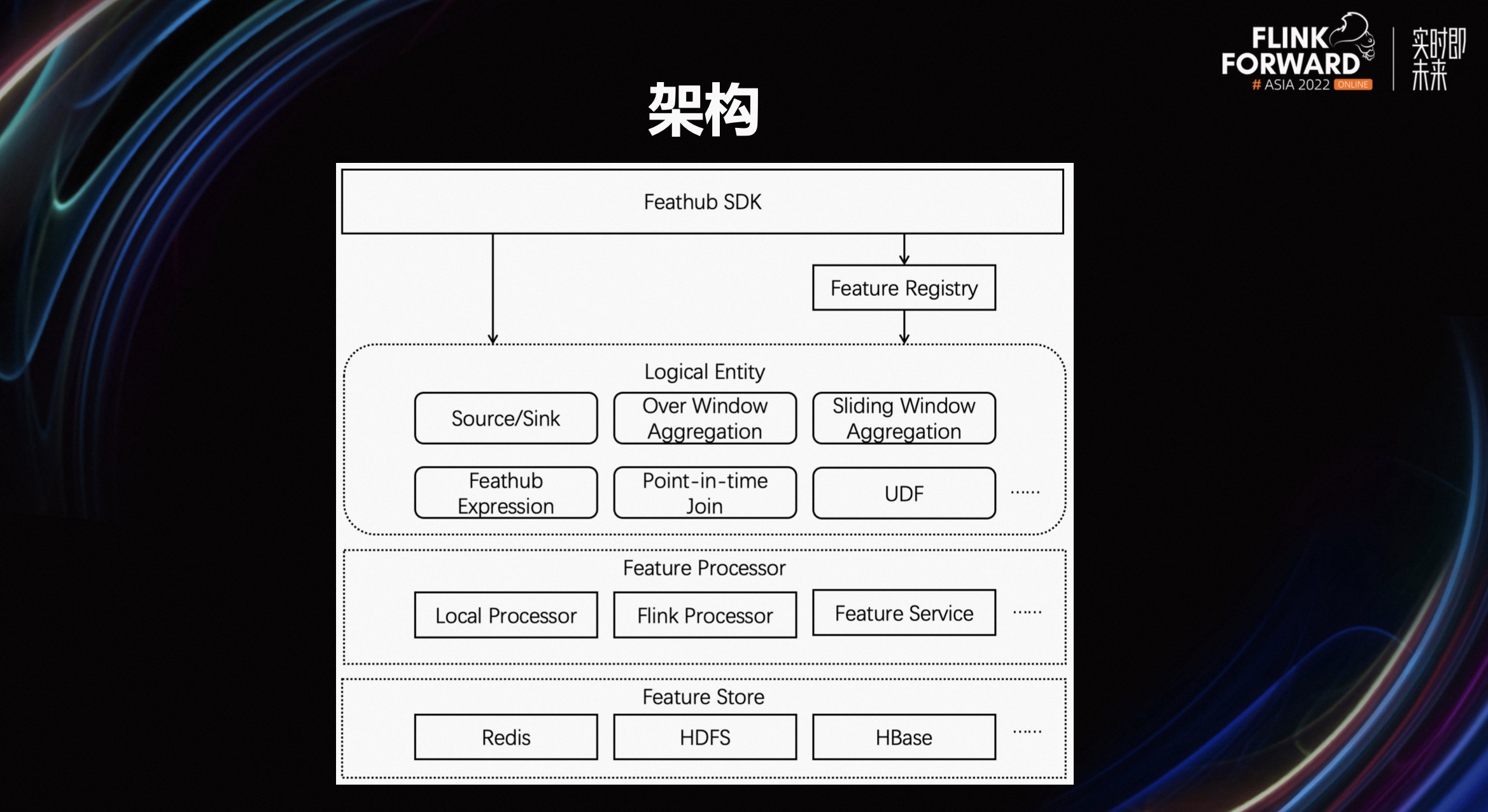
这张架构图展示了 FeatHub 平台的核心组件和架构。最上层是 SDK,目前基于 Python 语言开发,未来将支持 Java 或其他语言的 SDK。用户可以使用 SDK 编写声明式的特征定义,指定特征的数据源和目标存储位置,以及特征计算逻辑,例如基于滑动窗口的聚合和特征拼接。我们预期该 SDK 能够表达所有已知的特征计算逻辑。
中间层是多种执行引擎。其中,Local Processor 支持用户在单机上利用 CPU、磁盘等资源计算特征,以方便用户在单机上完成实验。Flink Processor 可以将用户的特征定义翻译成 Flink 作业,在高可用性、分布式的集群环境中进行低延迟、高吞吐的特征计算。Spark Processor 则可以将用户的特征定义翻译成 Spark 作业,支持用户使用 Spark 执行高吞吐的离线特征计算。
在执行引擎之下是特征的存储,包括离线存储(例如 HDFS)、流式存储(例如 Kafka)和在线存储(例如 Redis)。
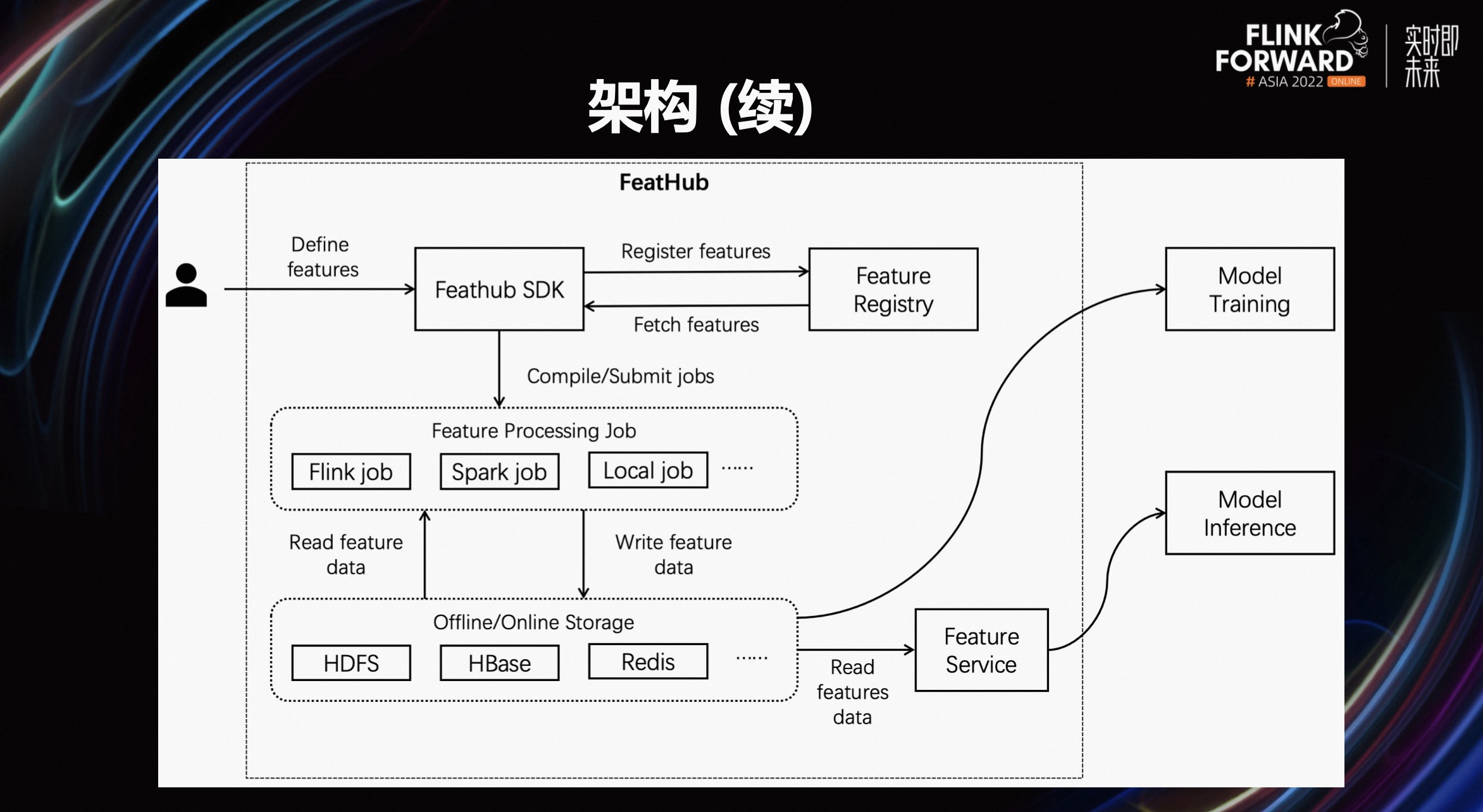
上图展示了 FeatHub 平台如何与机器学习的训练和推理程序对接。
用户可以使用 FeatHub SDK 定义特征。一旦部署了 FeatHub 作业,FeatHub 将启动对应的 Flink/Spark ETL 作业,并从在线或离线存储中读写特征数据。如果用户需要进行离线训练,则训练程序(例如 TensorFlow)可以从离线存储(例如 HDFS)中批量读取相应的特征数据。如果用户需要进行在线推理,则在线推理作业可以从在线存储(例如 Redis)中读取特征数据。
此外,存在需要进行在线计算的场景,其中特征的值需要在接收到用户请求后进行在线计算。例如,在地图手机应用中,当服务器收到用户请求时,可能需要根据用户当前请求和上一次请求的地理位置相对距离计算用户的移动速度特征。为满足这一场景需求,Feature Service 可以提供在线计算服务。
2.2 核心概念

上图中的 Table Descriptor 表示一个具有 Schema 的特征表,其概念类似于 Flink Table。我们可以基于数据源(例如 Kafka Topic)定义一个 Table Descriptor,并对其应用计算逻辑(例如滑动窗口聚合),从而产生一个新的 Table Descriptor,并将 Table Descriptor 的数据输出到外部存储(例如 Redis)中。
Table Descriptor 可以分为 FeatureTable 和 FeatureView。FeatureTable 是指特征存储中的一个物理特征表。例如,用户可以将 FeatureTable 定义为 Kafka 中的一个 Topic。而 FeatureView 则是对 FeatureTable 应用一个或多个计算逻辑后得到的结果。例如,用户可以对来自 Kafka 的 FeatureTable 应用不同的计算逻辑,从而得到以下三类不同的 FeatureView:
- DerivedFeatureView:它的输入行和输出行是一一对应的。用户可以使用这类 FeatureView 进行样本拼接,生成训练样本。DerivedFeatureView 可以包含基于单行计算和 Table Join 获得的特征。
- SlidingFeatureView:这是一个输出随时间变化的 FeatureView。它的输入行和输出行通常没有一一对应的关系。例如,我们需要计算用户最近两分钟内点击某商品的次数,输入的数据是用户的点击行为。即使用户不再产生新的点击行为,随着时间的推移,我们知道这个特征的数值也会逐渐递减,直至降为零。SlidingFeatureView 可以包含基于单行计算和滑动窗口聚合获得的特征。
- OnDemandFeatureView:它可以使用来自在线请求的特征作为输入来计算新的特征。因此,我们需要 Feature Service 来在线计算这个 FeatureView 包含的特征。OnDemandFeatureView 可以包含基于单行计算获得的特征。
FeatHub 支持多种特征计算逻辑,包括:
- ExpressionTransform:支持声明式的计算表达式,类似于 SQL Select 语句中的表达式。用户可以对特征进行加减乘除等操作,并调用内置的 UDF 函数。
- JoinTransform:支持拼接不同 Table Descriptor 的特征,用户可以指定样本数据表和维表,以获得训练样本。
- PythonUDFTransform:支持用户在 FeatHub SDK 中自定义和调用 Python 函数,方便熟悉 Python 的数据科学家进行特征开发。
- OverWindowTransform:支持基于 Over 窗口的聚合计算,类似于 SQL 中所支持的 Over 窗口聚合。例如,对于一个代表用户购买行为的输入表,使用 OverWindowTransform 找到这一时刻之前的2分钟内的该用户的行为数据,并统计购买总额度,作为该用户的特征。
- SlidingWindowTransform:支持基于滑动窗口的集合计算,可以随着时间变化输出新的实时特征数据。该计算逻辑可以将结果输出到在线特征储存 (e.g. Redis),方便下游机器学习推理程序实时查询和使用。与 OverWindowTransform 不同的是,SlidingWindowTransform 可以在没有新的输入时过期数据。
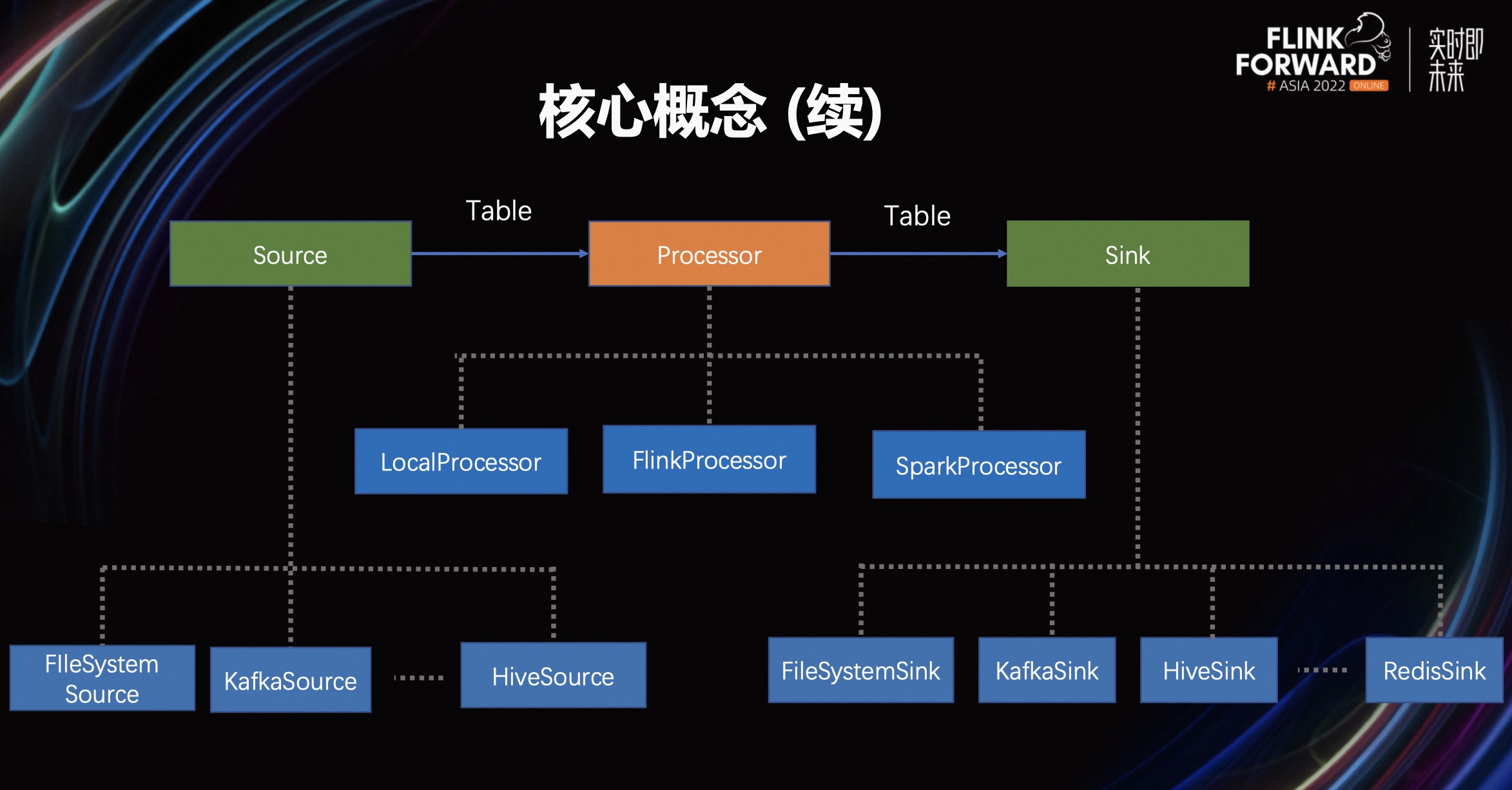
上图展示了 FeatHub 的执行引擎与特征储存的工作流程。
首先,用户需要定义 Source 来表达数据源。 Source 中的数据会被执行引擎按照所定义的各种 Transform 逻辑进行处理,再输出到外部特征储存 Sink,以便下游调用。这个过程类似于传统的 ETL。
Source 可以对接常见的离线或在线储存,例如 FileSystem、Kafka、Hive 等等。而 Sink 同样可以对接常见的离线或在线储存,例如 FileSystem、Kafka、Redis等等。Redis 是目前特征工程领域使用比较多的在线储存。
FeatHub 支持多种执行引擎,包括 LocalProcessor、FlinkProcessor 和 SparkProcessor。用户可以根据自己生产环境的具体情况,选择最合适的引擎来生成所需的特征。
- LocalProcessor 会在本地机器上执行特征计算逻辑,基于 Pandas 库实现。用户可以在单机上开发特征定义和运行实验,无需部署和使用分布式集群(例如 Flink)。LocalProcessor 仅支持离线特征计算。
- FlinkProcessor 会将特征定义翻译成可以分布式执行的 Flink 作业,可以基于流计算模式来生成实时特征。FeatHub 支持 Flink Session 模式和 Flink Application 模式。
- SparkProcessor 会将特征定义翻译成可以分布式执行的 Spark 作业,可以基于批计算模式来生成离线特征。
三、FeatHub API 展示
3.1 特征计算功能

接下来,我们将通过一些示例程序,展示如何使用 FeatHub 完成特征开发,并展示用户代码的简洁性和易读性。
左上角的图像显示了使用 JoinTransform 完成特征拼接的代码段。如果用户需要将来自维表的特定列连接作为特征,则可以在特征上提供新的特征名称、特征数据类型、连接键以及 JoinTransform 实例。在 JoinTransform 上,用户可以提供维表名称和列名称。需要注意的是,用户只需提供连接所需的基本信息,这种声明式的定义非常简洁。
中间的图像展示了使用 OverWindowTransform 完成 Over 窗口聚合的代码段。如果我们需要计算最近两分钟内用户购买商品的消费金额总数,则用户除了提供特征名称和数据类型外,还可以提供一个 OverWindowTransform 实例。在 OverWindowTransform 上,用户可以提供一个声明式的计算表达式 item_count * price,用于计算每个订单的消费金额,并设置 agg_function = SUM,以将所有订单的消费金额相加。此外,用户可以将 window_size 设置为 2 分钟,即每次特征计算都会聚合前 2 分钟内的原始数据输入。group_by_key = ["user_id"] 表示对每个用户 ID 进行聚合计算。将所有信息结合起来,即可完整地表达所需的 Over 窗口聚合逻辑。这种声明式的表达非常简洁,类似于 SQL 的 select / from / where / groupBy。
上图右上角展示了使用 SlidingWindowTransform 完成滑动窗口聚合的代码片段,与 Over 窗口聚合非常相似。区别在于需要指定 step_size,这里设为 1 分钟,表示每隔 1 分钟窗口会滑动一次,移除过期数据,重新计算并输出新特征值。
上图左下角展示了使用 ExpressionTransform 调用内置函数的代码片段。FeatHub 提供常用内置函数,类似于 Flink SQL 或 Spark SQL。代码片段中的 UNIX_TIMESTAMP 将输入的时间戳字符串转换为整数类型的 Unix 时间戳。例如,在这个例子中,用户可以将出租车的上车和下车时间的字符串类型特征分别转换为整数类型,并相减得到代表本次行程总时间的特征。
上图右下角展示了使用 PythonUdfTransform 调用用户自定义 Python 函数的代码片段。在此例中,用户使用 Python lambda 函数将输入字符串转换为小写字来获得新的特征。
3.2 样例场景
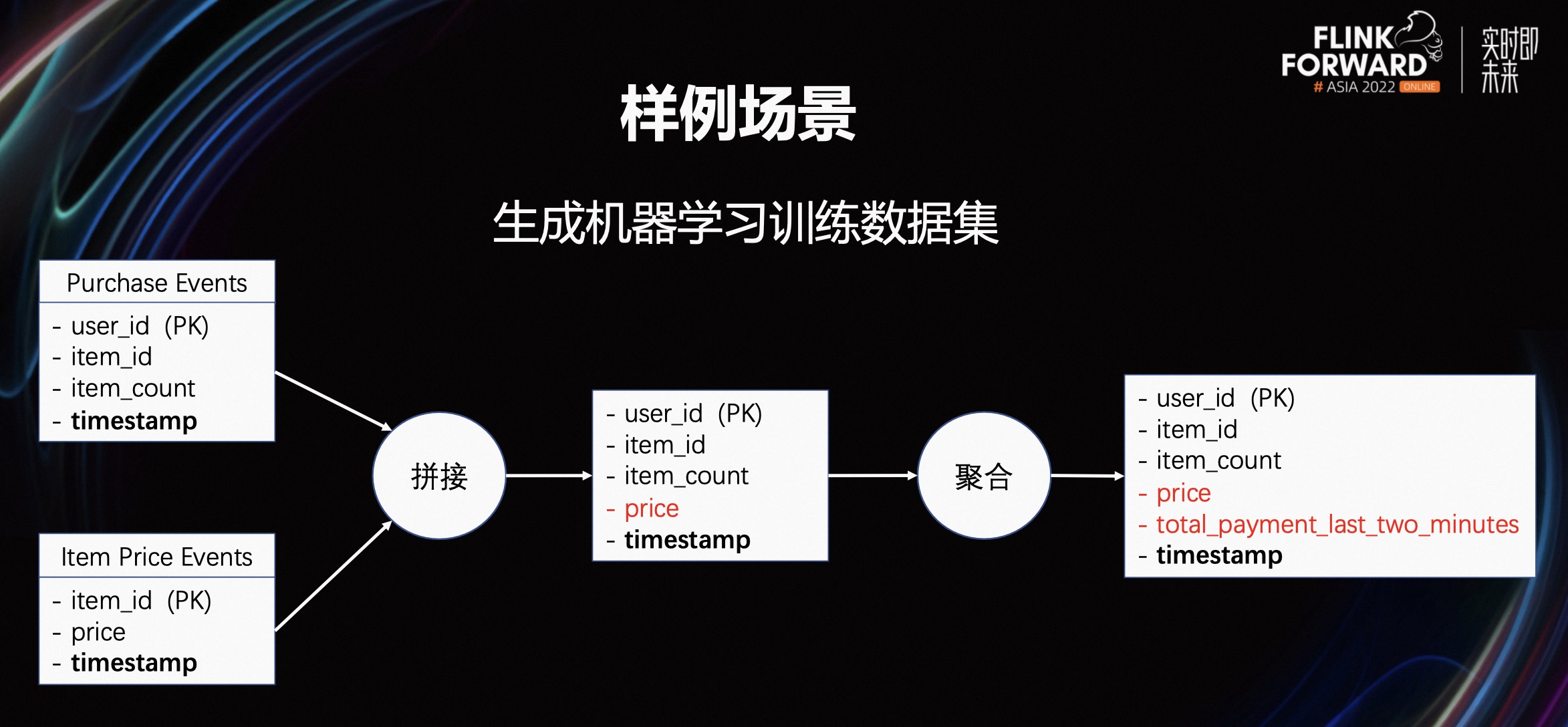
为了更清晰地展示如何使用 Feathub 完成端到端的作业开发,我们将以生成机器学习训练数据集为例,并提供详细的讲解。在本例中,我们假设用户数据来自于两个表:Purchase Events 和 Item Price Events。
Purchase Events 中的每行数据代表一次购买商品的行为。其中,user_id 代表用户,item_id 代表被购买的商品,item_count 代表购买的商品个数,而 timestamp 代表购买商品的时间。
Item Price Events 中的每行数据代表一次商品价格变化的事件。其中,item_id 代表价格发生变化的商品,price 代表最新的价格,timestamp 代表价格变化的时间。
为了为机器学习训练生成一个数据集,我们需要在这两个表格中的信息的基础上创建一个新的数据集。该数据集需要在每次购买商品的行为发生时,记录购买商品的用户在当前时刻之前的 30 分钟内的总消费金额作为新特征。
为了创建这个数据集,我们可以使用 JoinTransform,使用 item_id 作为 Join Key,将 Item Price Events 中的价格以 point-in-time-correct 的方式拼接到每个 Purchase Events 行的数据中。然后,我们可以使用OverWindowTransform,以 user_id 为 group_by_key,并设置 window_size 为 30 分钟,计算每行的 item_count 乘以价格,并使用 SUM 函数进行聚合,以获得所需的新特征。
3.3 样例代码

上图展示了完成样例场景的代码片段。
首先,用户需要创建一个 FeatHubClient 实例。FeatHubClient 包含了核心 FeatHub 组件的配置。在这个例子中,我们配置 FeatHubClient 使用 Flink 作为执行引擎。用户还可以进一步提供 Flink 相关的配置信息,例如 Flink 的端口和 IP 地址等。
接下来,用户需要创建 Source 来指定特征的数据源。在这个示例中,特征数据来自本地文件,因此可以使用 FileSystemSource 表达。在需要实时计算特征的场景中,用户可以使用 KafkaSource 从 Kafka 实时读取特征数据。为了能够在之后的特征计算中引用这些特征,用户需要指定 Source 的名称。
在 FileSystemSource 上,data_format 表示文件的数据格式,例如 JSON、Avro 等。timestamp_field 则指定了代表数据时间戳的列名。有了时间戳信息,FeatHub 就可以执行遵循 point-in-time-correct 语义的拼接和聚合计算,避免特征穿越问题。
在创建了 Source 后,用户可以创建 FeatureView 来定义所需的拼接和聚合逻辑。在代码片段中,item_price_events.price 表示需要拼接来自 item_price_events 表上的 price 列。total_payment_last_two_minutes 表示 Over 窗口聚合得到的特征。对于来自 purchase_event_source 的每一行,它会找到之前 2 分钟内具有相同 user_id 的所有行,计算 item_count * price,然后将计算结果相加,作为特征的数值。
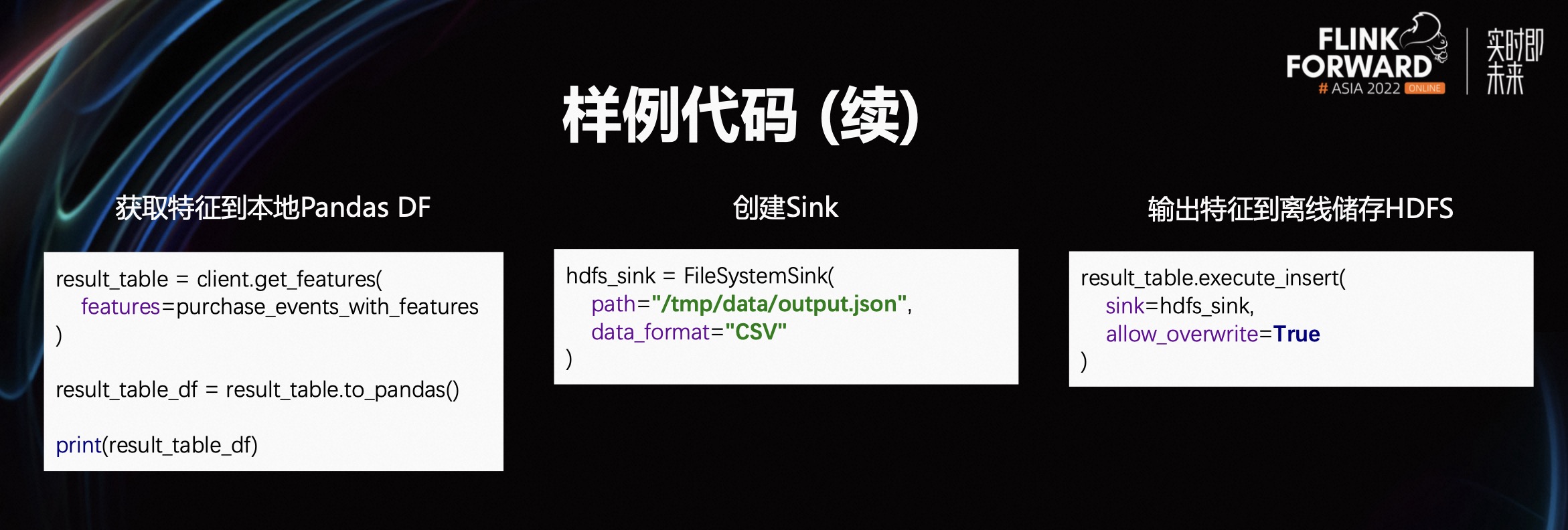
定义 FeatureView 后,用户就可以从中获取特征数据,并将数据输出到特征存储中。用户可以调用 FeatHub 提供的 table#to_pandas 函数获取包含特征数据的 Pandas DataFrame,然后检查数据的正确性,或者将获得的数据传递给 Scikit-learn 等 Python 算法库进行训练。
完成特征作业开发后,用户需要将作业部署到生产环境中的分布式集群来处理大规模的特征数据。用户需要创建一个 Sink 实例来表达特征输出的存储位置和相关格式信息。在样例代码中,FileSystemSink 指定了 HDFS 路径以及 CSV 数据格式。
最后,用户可以调用 FeatHub 提供的 table#execute_insert 函数将作业部署到远程的 Flink 集群进行异步执行。
3.4 FeatHub 性能优化
除了提供 Python SDK 方便用户开发特征作业外,FeatHub 还为常见的特征作业提供多种内置性能优化,以降低特征作业的生产部署成本并提高效率。
在实时搜索推荐等领域,经常会用到多个滑动窗口聚合的特征,它们的定义几乎相同,只是窗口大小不同。例如,为了判断是否要向用户推荐某个商品,需要知道该用户在最近 2 分钟、60 分钟、5 小时和 24 小时内点击某类商品的次数。如果直接使用 Flink API 来生成这些特征,每个特征都会有一个独立的 Window 算子来记录窗口范围内的数据。在这个例子中,最近 2 分钟内的数据会被复制多份存放在所有算子中,导致浪费内存和磁盘空间。而 FeatHub 提供了优化,使用一个算子来记录最大窗口范围内的数据,并复用这些数据来计算这些特征的数值,从而降低 CPU 和内存成本。
此外,针对前文提到的滑动窗口聚合的特征,我们发现它们的输入数据通常具有稀疏性。以计算用户最近 24 小时中点击商品的次数为例,大多数用户的点击事件可能只集中在其中某一小时,而其他时间段则没有点击行为,因此不会产生特征数值的变化。如果直接使用 Flink API 生成此特征并要求步长为 1 秒,则 Flink 的滑动窗口每秒都会输出数据。相比之下,FeatHub 会提供优化,仅在特征数值发生变化时才输出数据。这样可以显著减少 Flink 输出的数据所占用的网络带宽,并降低下游计算和存储资源的消耗。
在特征工程方面,我们计划在 FeatHub 中增加更多的优化措施,例如通过使用 SideOutput 获取迟到的数据来更新滑动窗口特征,提高特征的在线和离线一致性。我们还将提供机制来减少爬虫造成的 hot-key 对 Flink 作业性能的影响。
3.5 FeatHub 未来工作
我们正在积极开发 FeatHub,希望尽早为用户提供生产可用的能力。 以下是我们计划完成的工作。
- 完善基于 Pandas、Spark 和 Flink 的执行引擎实现,并提供尽可能多的内置性能优化,以加速特征计算的过程并提高生产环境中的性能表现。
- 扩展支持更多的离线和在线储存系统,例如 Redis、Kafka、HBase 等,使得 FeatHub 能够覆盖更广泛的场景和应用。
- 提供可视化 UI,帮助用户访问特征元数据中心,轻松注册、查询和复用特征,从而提高开发和部署的效率。
- 提供常见的指标和监控功能,例如特征的覆盖率和缺失率等,支持开箱即用的特征质量监控和告警机制,保证特征的稳定性和准确性。

欢迎尝试使用 FeatHub 并提供您的开发建议。FeatHub 是一个开源库,其地址为 https://github.com/alibaba/feathub。还可以访问 GitHub - flink-extended/feathub-examples: This project provides example FeatHub (https://github.com/alibaba/feathub) programs 获取更多的 FeatHub 使用代码样例。
点击查看直播回放和演讲 PPT
这篇关于FeatHub:流批一体的实时特征工程平台的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!