本文主要是介绍2021年最新最全Flink系列教程_Flink原理初探和流批一体API(二.五),希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
引言
大家好,我是ChinaManor,直译过来就是中国码农的意思,我希望自己能成为国家复兴道路的铺路人,大数据领域的耕耘者,平凡但不甘于平庸的人。
下面为大家带来阿里巴巴极度热推的Flink,实时数仓是未来的方向,学好Flink,月薪过万不是梦!!

相关教程直通车:
2021年最新最全Flink系列教程_Flink快速入门(概述,安装部署)(一)
2021年最新最全Flink系列教程_Flink原理初探和流批一体API(二)
2021年最新最全Flink系列教程__Flink高级API(三)
day02-03_流批一体API
今日目标
-
流处理原理初探
-
流处理概念(理解)
-
程序结构之数据源Source(掌握)
-
程序结构之数据转换Transformation(掌握)
-
程序结构之数据落地Sink(掌握)
-
Flink连接器Connectors(理解)
流处理原理初探
-
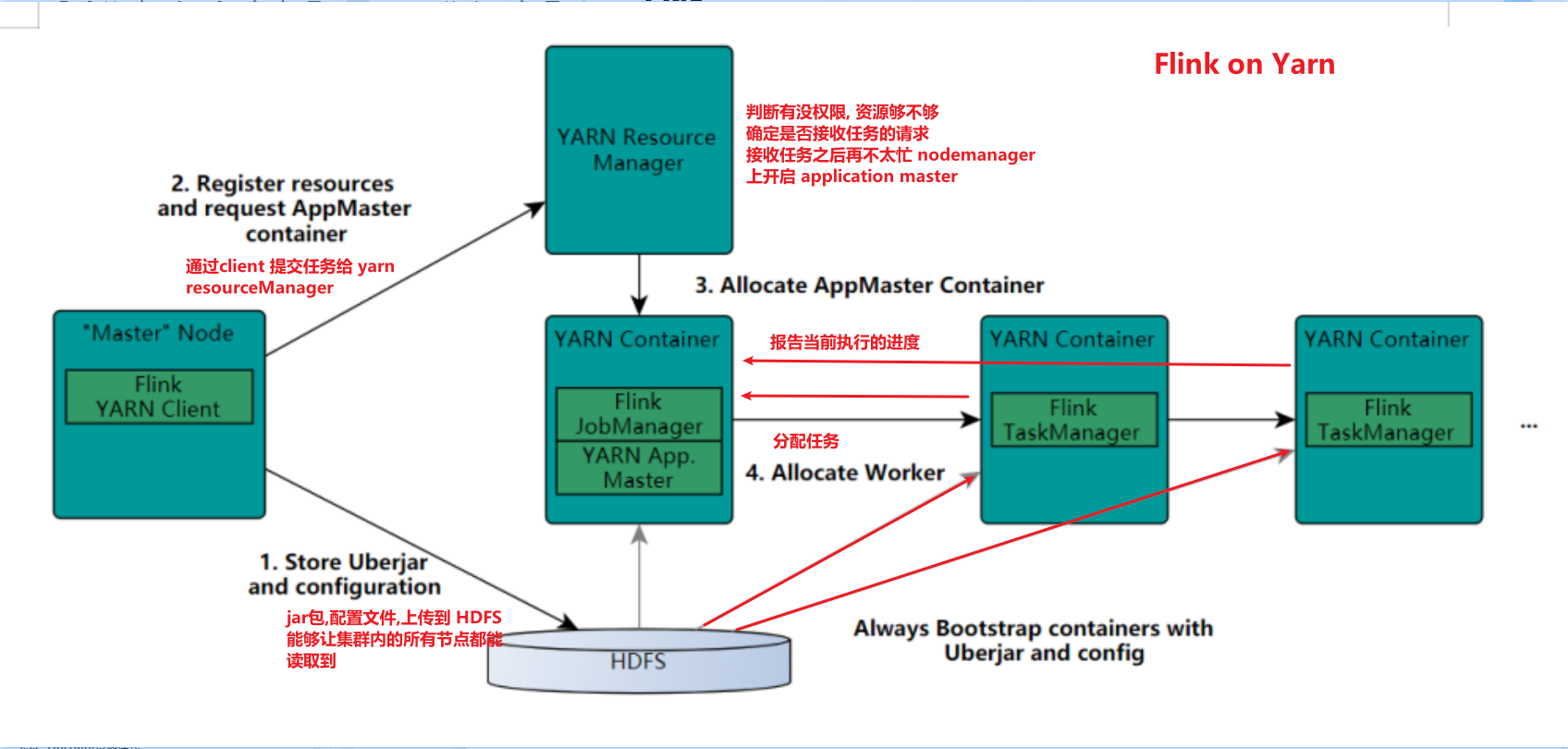
Flink的角色分配
- JobMaster 老大, 主要负责 集群的管理, 故障的恢复, checkpoint 检查点设置
- taskmanager worker 小弟, 具体负责任务的执行节点
- client 提交任务的界面
-
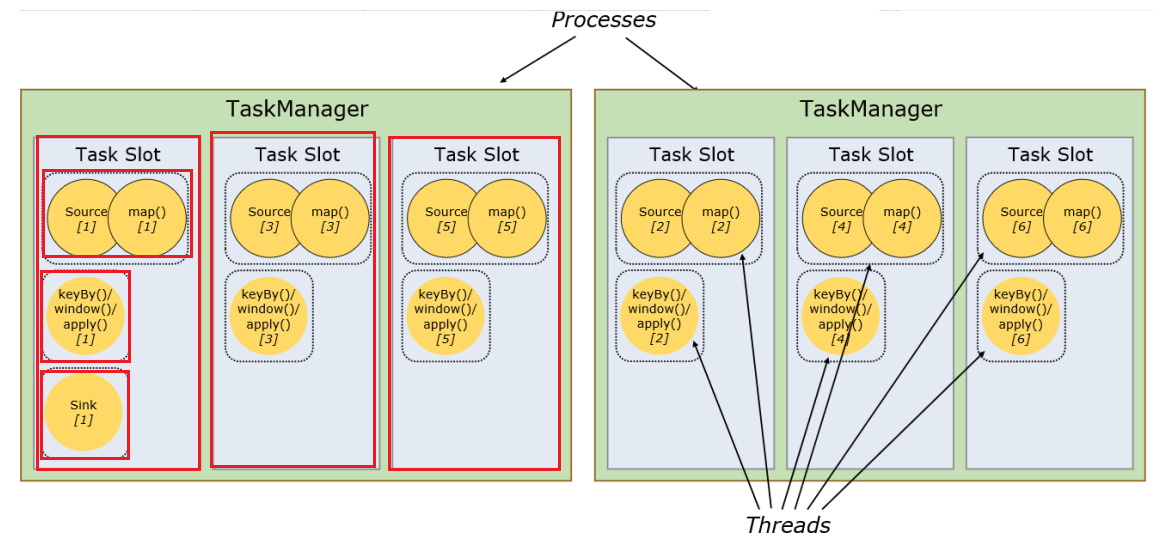
taskmanager 执行能力
- taskslot 静态的概念
- parallelism 并行度 动态概念
-
每个节点就是一个 task 任务
每个任务拆分成多个并行处理的任务, 多个线程就有多个子任务,就叫子任务 subtask
-
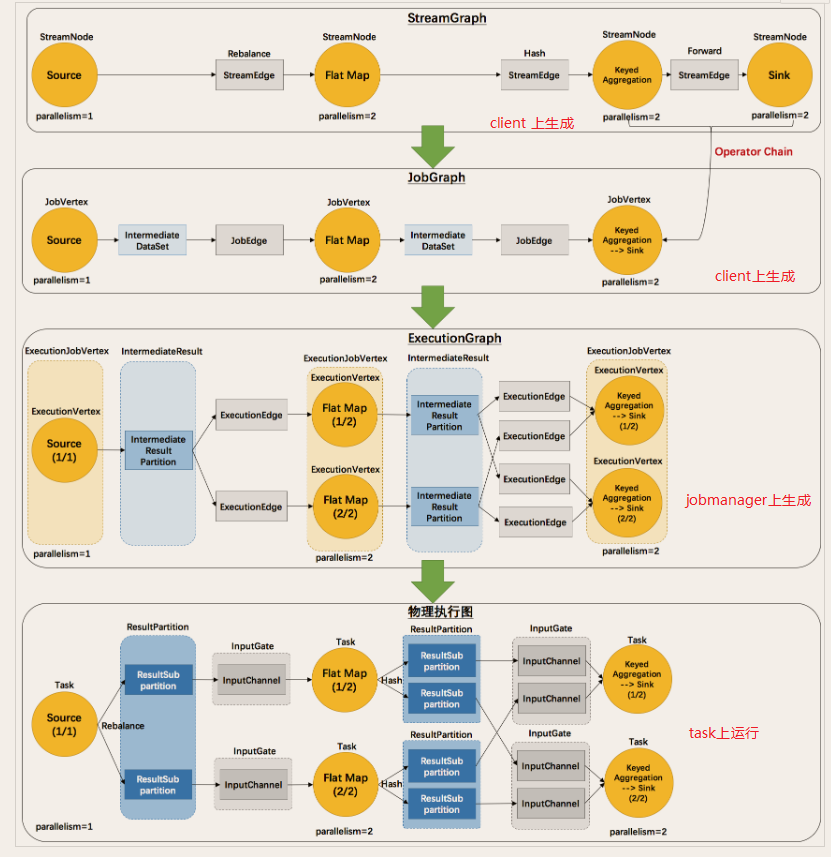
流图 StreamGraph 逻辑执行流图 DataFlow
operator chain 操作链
-
JobGraph
ExecuteGraph 物理执行计划
-
Event 事件 带有时间戳的
-
Operator 传递模式 : one to one 模式, redistributing模式
- Flink之执行图
流处理概念
数据的时效性
-
强调的是数据的处理时效
处理的时间窗口, 按月, 按天, 按小时还是秒级处理
流处理和批处理
-
批处理是有界的数据
- 处理完整的数据集, 比如排序数据, 计算全局的状态, 生成最终的输入概述.
- 批量计算: 统一收集数据->存储到DB->对数据进行批量处理
-
流处理是无界的数据
- 窗口操作来划分数据的边界进行计算
- 流式计算,顾名思义,就是对数据流进行处理
-
在Flink1.12时支持流批一体 既支持流处理也支持批处理。

-
流批一体 Flink1.12.x 批处理和流处理
- 可复用性: 作业在流模式或者批处理两种模式自由切换, 无需重写任何代码.
- 维护简单: 统一的 API 意味着流和批可以共用同一组 connector,维护同一套代码.
编程模型
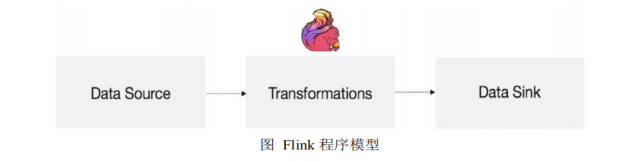
- source - 读取数据源
- transformation - 数据转换 map flatMap groupBy keyBy sum
- sink - 落地数据 addSink print
Source
基于集合的Source
-
开发和测试使用
-
分类
1.env.fromElements(可变参数); 2.env.fromColletion(各种集合); # 过期 3.env.generateSequence(开始,结束); 4.env.fromSequence(开始,结束); -
使用集合 Source
import org.apache.flink.streaming.api.datastream.DataStreamSource; import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;import java.util.ArrayList;/*** Author itcast* Date 2021/6/16 9:29* 需求: 通过集合source打印结果,查看如何使用* 开发步骤:* 1. 创建流环境* 2. 从集合中读取数据* 3. 打印输出* 4. 运行执行*/ public class SourceDemo01 {public static void main(String[] args) throws Exception {//1. 创建流环境StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();//2. 从集合中读取数据//2.1 fromElement 从元素集合DataStreamSource<String> source1 = env.fromElements("hello world", "hello spark", "hello flink");//2.2 fromCollection 从集合列表ArrayList<String> strings = new ArrayList<>();strings.add("hello world");strings.add("hello flink");DataStreamSource<String> source2 = env.fromCollection(strings);//2.3 fromSequence 从序列DataStreamSource<Long> source3 = env.fromSequence(1, 10);//3. 打印输出source1.print();//4. 运行执行env.execute();} } -
socket 数据源 wordcount 统计
/*** Author itcast* Desc* SocketSource*/ public class SourceDemo03 {public static void main(String[] args) throws Exception {//1.envStreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();env.setRuntimeMode(RuntimeExecutionMode.AUTOMATIC);//2.sourceDataStream<String> linesDS = env.socketTextStream("node1", 9999);//3.处理数据-transformation//3.1每一行数据按照空格切分成一个个的单词组成一个集合DataStream<String> wordsDS = linesDS.flatMap(new FlatMapFunction<String, String>() {@Overridepublic void flatMap(String value, Collector<String> out) throws Exception {//value就是一行行的数据String[] words = value.split(" ");for (String word : words) {out.collect(word);//将切割处理的一个个的单词收集起来并返回}}});//3.2对集合中的每个单词记为1DataStream<Tuple2<String, Integer>> wordAndOnesDS = wordsDS.map(new MapFunction<String, Tuple2<String, Integer>>() {@Overridepublic Tuple2<String, Integer> map(String value) throws Exception {//value就是进来一个个的单词return Tuple2.of(value, 1);}});//3.3对数据按照单词(key)进行分组//KeyedStream<Tuple2<String, Integer>, Tuple> groupedDS = wordAndOnesDS.keyBy(0);KeyedStream<Tuple2<String, Integer>, String> groupedDS = wordAndOnesDS.keyBy(t -> t.f0);//3.4对各个组内的数据按照数量(value)进行聚合就是求sumDataStream<Tuple2<String, Integer>> result = groupedDS.sum(1);//4.输出结果-sinkresult.print();//5.触发执行-executeenv.execute();} } -
自定义数据源 - 随机数据
import lombok.AllArgsConstructor; import lombok.Data; import lombok.NoArgsConstructor; import org.apache.flink.streaming.api.datastream.DataStreamSource; import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment; import org.apache.flink.streaming.api.functions.source.RichParallelSourceFunction;import java.util.Random; import java.util.UUID;/*** Author itcast* Date 2021/6/16 10:18* 每隔1秒随机生成一条订单信息(订单ID、用户ID、订单金额、时间戳)* 要求:* - 随机生成订单ID(UUID)* - 随机生成用户ID(0-2)* - 随机生成订单金额(0-100)* - 时间戳为当前系统时间** SourceFunction:非并行数据源(并行度只能=1)* RichSourceFunction:多功能非并行数据源(并行度只能=1)* ParallelSourceFunction:并行数据源(并行度能够>=1)* RichParallelSourceFunction:多功能并行数据源(并行度能够>=1)--后续学习的Kafka数据源使用的就是该接口*/ public class CustomSource01 {public static void main(String[] args) throws Exception {//1.env 创建 StreamExectutionStreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();env.setParallelism(1);//2.source,创建自动生成 Order 数据源DataStreamSource<Order> source = env.addSource(new MyOrderSource());//3.打印数据源source.print();//4.执行env.execute();//定义实体类 Order 包括四个字段 oid uid money currentTime//定义静态内部类 MyOrderSource 继承 RichParallelSourceFunction//每隔1秒随机生成一条订单信息(订单ID、用户ID、订单金额、时间戳)//要求://- 随机生成订单ID(UUID)//- 随机生成用户ID(0-2)//- 随机生成订单金额(0-100)//- 时间戳为当前系统时间}public static class MyOrderSource extends RichParallelSourceFunction<Order> {boolean flag = true;Random rn = new Random();@Overridepublic void run(SourceContext<Order> ctx) throws Exception {//每隔1秒随机生成一条订单信息(订单ID、用户ID、订单金额、时间戳)//要求:while(flag) {//- 随机生成订单ID(UUID)String oid = UUID.randomUUID().toString();//- 随机生成用户ID(0-2)int uid = rn.nextInt(3);//- 随机生成订单金额(0-100)int money = rn.nextInt(101);//- 时间戳为当前系统时间long currentTime = System.currentTimeMillis();ctx.collect(new Order(oid,uid,money,currentTime));//一秒钟休息一下Thread.sleep(1000);}}@Overridepublic void cancel() {flag = false;}}//创建 Order 对象@AllArgsConstructor@NoArgsConstructor@Datapublic static class Order{private String oid;private int uid;private int money;private long currentTime;} } -
自定义数据源 - 从MySQL数据库中读取 t_student表中数据( 这种场景用的非常少 - 自定义数据源 )
import lombok.AllArgsConstructor; import lombok.Data; import lombok.NoArgsConstructor; import org.apache.flink.configuration.Configuration; import org.apache.flink.streaming.api.datastream.DataStreamSource; import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment; import org.apache.flink.streaming.api.functions.source.RichSourceFunction;import java.sql.Connection; import java.sql.DriverManager; import java.sql.PreparedStatement; import java.sql.ResultSet;/*** Author itcast* Date 2021/6/16 10:37* 需求:* 从MySql数据库中读取 t_student 表数据* 开发步骤:* //1.env 设置并行度为 1* //2.source,创建连接MySQL数据源 数据源,每2秒钟生成一条数据* //3.打印数据源* //4.执行* //创建静态内部类 Student ,字段为 id:int name:String age:int* //创建静态内部类 MySQLSource 继承RichParallelSourceFunction<Student>* // 实现 open 方法 ,创建 connection 和 prepareStatement* // 获取数据库连接 mysql5.7版本* jdbc:mysql://192.168.88.163:3306/bigdata?useSSL=false* // 实现 run 方法, 每 5秒钟创建一条数据* // 实现 close 方法*/ public class CustomSourceMySQL {public static void main(String[] args) throws Exception {//1.env 设置并行度为 1StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();env.setParallelism(1);//2.source,创建连接MySQL数据源 数据源,每2秒钟生成一条数据DataStreamSource<Student> source = env.addSource(new MySQLSource());//3.打印数据源source.print();//4.执行env.execute();//创建静态内部类 Student ,字段为 id:int name:String age:int//创建静态内部类 MySQLSource 继承RichParallelSourceFunction<Student>// 实现 open 方法 ,创建 connection 和 prepareStatement// 获取数据库连接 mysql5.7版本 jdbc:mysql://192.168.88.163:3306/bigdata?useSSL=false// 实现 run 方法, 每 5秒钟创建一条数据// 实现 close 方法}public static class MySQLSource extends RichSourceFunction<Student> {boolean flag = true;Connection conn = null;PreparedStatement ps = null;// open 生命周期的开始, 只做一次@Overridepublic void open(Configuration parameters) throws Exception {conn = DriverManager.getConnection("jdbc:mysql://192.168.88.163:3306/bigdata?useSSL=false","root", "123456");String sql = "select id,name,age from t_student";// 执行 preparementps = conn.prepareStatement(sql);}@Overridepublic void run(SourceContext<Student> ctx) throws Exception {while(flag){// 查询结果集ResultSet rs = ps.executeQuery();while(rs.next()){int id = rs.getInt("id");String name = rs.getString("name");int age = rs.getInt("age");ctx.collect(new Student(id,name,age));Thread.sleep(5000);}}}@Overridepublic void cancel() {flag = false;}//关闭数据库, 在整个生命周期也只做一次@Overridepublic void close() throws Exception {if(!ps.isClosed()) ps.close();if(!conn.isClosed()) conn.close();}}//定义 student@AllArgsConstructor@NoArgsConstructor@Datapublic static class Student{private int id;private String name ;private int age;} }
合并-拆分
-
合并数据流 将两个数据流合并成一个数据流
-
应用场景
① 将不同的数据源 电脑, app , ipad ,微信小程序的所有的订单的信息 ,统计分析,挖掘
② 将不同的手持设备, 电脑用户行为轨迹收集统计分析
-
union 和connect 区别
union 和 connect 合流
union 算子 要求数据流的类型必须保持一致.
connect 算子 要求数据流的类型可以不一致
-
需求: 将两个数据流合并到一起
/*** Author itcast* Desc*/ public class TransformationDemo02 {public static void main(String[] args) throws Exception {//1.envStreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();env.setRuntimeMode(RuntimeExecutionMode.AUTOMATIC);env.setParallelism(1);//2.SourceDataStream<String> ds1 = env.fromElements("hadoop", "spark", "flink");DataStream<String> ds2 = env.fromElements("oozie", "flume", "flink");DataStream<Long> ds3 = env.fromElements(1L, 2L, 3L);//3.Transformation// union 算子 保证两个数据流类型保持一致DataStream<String> result1 = ds1.union(ds2);//合并但不去重 https://blog.csdn.net/valada/article/details/104367378// connect 算子 两个数据流类型可以不一样ConnectedStreams<String, Long> tempResult = ds1.connect(ds3);//interface CoMapFunction<IN1, IN2, OUT>DataStream<String> result2 = tempResult.map(new CoMapFunction<String, Long, String>() {@Overridepublic String map1(String value) throws Exception {return "String->String:" + value;}@Overridepublic String map2(Long value) throws Exception {return "Long->String:" + value.toString();}});//4.Sink//result1.print();result2.print();//5.executeenv.execute();} }
分流 select 和 outputside
-
将一个数据流分成多个数据流
-
应用场景
① 服务器日志 分流出正常的日志, 告警日志, 报错日志
-
需求 - 将数据流拆分成 偶数 和 奇数
-
开发步骤
import org.apache.flink.api.common.typeinfo.TypeInformation; import org.apache.flink.streaming.api.datastream.DataStreamSource; import org.apache.flink.streaming.api.datastream.SingleOutputStreamOperator; import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment; import org.apache.flink.streaming.api.functions.ProcessFunction; import org.apache.flink.util.Collector; import org.apache.flink.util.OutputTag;/*** Author itcast* Date 2021/6/16 11:29* 需求: 拆分数据* 开发步骤:* //1.env* //2.Source 比如 1-20之间的数字* //定义两个输出tag 一个奇数 一个偶数,指定类型为Long* //对source的数据进行process处理区分奇偶数* //3.获取两个侧输出流* //4.sink打印输出* //5.execute*/ public class SplitDataStream {public static void main(String[] args) throws Exception {//1.envStreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();env.setParallelism(1);//2.Source 比如 1-20之间的数字DataStreamSource<Long> source = env.fromSequence(1, 21);//定义两个侧输出流 一个奇数 一个偶数, 指定类型为Long// 需要指定对应的数据类型, 默认OutputTag 会用通用类型,需要手动OutputTag<Long> odd = new OutputTag<Long>("odd", TypeInformation.of(Long.class));OutputTag<Long> even = new OutputTag<Long>("even", TypeInformation.of(Long.class));//对source的数据进行process处理区分奇偶数SingleOutputStreamOperator<Long> result = source.process(new ProcessFunction<Long, Long>() {@Overridepublic void processElement(Long value, Context ctx, Collector<Long> out) throws Exception {if (value % 2 == 0) {ctx.output(even, value);} else {ctx.output(odd, value);}}});//3.获取两个侧输出流//result.print();result.getSideOutput(even).print("偶数");result.getSideOutput(odd).print("奇数");//4.sink打印输出//5.executeenv.execute();} }
数据重平衡 rebalance
-
将数据均匀大散到各个节点上, 计算更均匀。
-
需求: 使用3个线程将100个大于10的90个数字,均匀计算
-
代码
import org.apache.flink.api.common.functions.RichMapFunction; import org.apache.flink.api.java.tuple.Tuple2; import org.apache.flink.streaming.api.datastream.DataStream; import org.apache.flink.streaming.api.datastream.DataStreamSource; import org.apache.flink.streaming.api.datastream.SingleOutputStreamOperator; import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;/*** Author itcast* Date 2021/6/17 15:00* 需求: 3个线程处理90个数字, 大于10的数字*/ public class RebalanceDemo {public static void main(String[] args) throws Exception {//1.env 设置并行度为3StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();env.setParallelism(3);//2.source fromSequence 1-100DataStreamSource<Long> source = env.fromSequence(1, 100);//3.Transformation//下面的操作相当于将数据随机分配一下,有可能出现数据倾斜,过滤出来大于10DataStream<Long> filterDS = source.filter(s -> s > 10);//3.1 接下来使用map操作,将Long数据转为 tuple2(分区编号/子任务编号, 1)/*SingleOutputStreamOperator<Tuple2<Integer, Integer>> mapDS = filterDS.map(new RichMapFunction<Long, Tuple2<Integer*//**CPU的核心编号*//*, Integer>>() {@Overridepublic Tuple2<Integer, Integer> map(Long value) throws Exception {//通过getRuntimeContext获取到任务Indexint idx = getRuntimeContext().getIndexOfThisSubtask();//返回Tuple2(任务Index,1)return Tuple2.of(idx, 1);}});//按照子任务id/分区编号分组,统计每个子任务/分区中有几个元素SingleOutputStreamOperator<Tuple2<Integer, Integer>> result1 = mapDS.keyBy(i -> i.f0)//对当前的数据流根据 key 进行分组聚合.sum(1);*///3.2 重新执行以上操作在filter之后先 rebalance 再map ,同上SingleOutputStreamOperator<Tuple2<Integer, Integer>> mapDS = filterDS.rebalance().map(new RichMapFunction<Long, Tuple2<Integer/**CPU的核心编号*/, Integer>>() {@Overridepublic Tuple2<Integer, Integer> map(Long value) throws Exception {//通过getRuntimeContext获取到任务Indexint idx = getRuntimeContext().getIndexOfThisSubtask();//返回Tuple2(任务Index,1)return Tuple2.of(idx, 1);}});//按照子任务id/分区编号分组,统计每个子任务/分区中有几个元素SingleOutputStreamOperator<Tuple2<Integer, Integer>> result2 = mapDS.keyBy(i -> i.f0)//对当前的数据流根据 key 进行分组聚合.sum(1);//4.sink//result1.print("没有重分区");result2.print("重分区");//5.executeenv.execute();} }
Sink
预定义Sink
/*** Author itcast* Desc* 1.ds.print 直接输出到控制台* 2.ds.printToErr() 直接输出到控制台,用红色* 3.ds.collect 将分布式数据收集为本地集合* 4.ds.setParallelism(1).writeAsText("本地/HDFS的path",WriteMode.OVERWRITE)*/
public class SinkDemo01 {public static void main(String[] args) throws Exception {//1.envStreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();//2.source//DataStream<String> ds = env.fromElements("hadoop", "flink");DataStream<String> ds = env.readTextFile("data/input/words.txt");//3.transformation//4.sinkds.print();ds.printToErr();ds.writeAsText("data/output/test", FileSystem.WriteMode.OVERWRITE).setParallelism(2);//注意://Parallelism=1为文件//Parallelism>1为文件夹//5.executeenv.execute();}
}
自定义Sink
-
需求
将集合中的数据写入到 MySQL 中
-
开发步骤
import lombok.AllArgsConstructor; import lombok.Data; import lombok.NoArgsConstructor; import org.apache.flink.configuration.Configuration; import org.apache.flink.streaming.api.datastream.DataStream; import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment; import org.apache.flink.streaming.api.functions.sink.RichSinkFunction;import java.sql.Connection; import java.sql.DriverManager; import java.sql.PreparedStatement;/*** Author itcast* Date 2021/6/17 15:43* Desc TODO*/ public class CustomSinkMySQL {public static void main(String[] args) throws Exception {//1.envStreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();//2.SourceDataStream<Student> studentDS = env.fromElements(new Student(null, "tonyma", 18));//3.Transformation//4.SinkstudentDS.addSink(new MySQLSink());//5.executeenv.execute();}//实现 RichSinkFunction 来实现将数据插入到 MySQL 中 t_student 表中public static class MySQLSink extends RichSinkFunction<Student>{Connection conn ;PreparedStatement ps;//连接数据库@Overridepublic void open(Configuration parameters) throws Exception {conn = DriverManager.getConnection("jdbc:mysql://192.168.88.163:3306/bigdata?useSSL=false","root","123456");String sql = "INSERT INTO `t_student` (`id`, `name`, `age`) VALUES (null, ?, ?)";ps = conn.prepareStatement(sql);}//将数据插入到数据库@Overridepublic void invoke(Student value, Context context) throws Exception {ps.setString(1,value.name);ps.setInt(2,value.age);ps.executeUpdate();}//关闭数据库@Overridepublic void close() throws Exception {if(!ps.isClosed()) ps.close();if(!conn.isClosed()) conn.close();}}@Data@NoArgsConstructor@AllArgsConstructorpublic static class Student {private Integer id;private String name;private Integer age;} }
Connector
- Flink官方提供的连接器, 用于连接 JDBC 或者 Kafka ,MQ等
JDBC 连接方式
-
需求:将数据元素通过JDBC方式存储到MySQL数据库
/*** Author itcast* Date 2021/6/17 15:59* Desc TODO*/ public class JDBCSinkMySQL {public static void main(String[] args) throws Exception {//1.envStreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();//2.SourceDataStreamSource<Student> source = env.fromElements(new Student(null, "JackMa", 42));//3.将数据通过 jdbc 插入到 mysql 数据库source.addSink(JdbcSink.sink(// 输入 SQL 执行插入SQL 语句"INSERT INTO t_student(id,name,age) values (null,?,?)",// 执行插入的赋值(ps, student) -> {ps.setString(1,student.name);ps.setInt(2,student.age);},//构造器// 执行的选项 设置批处理大小等参数JdbcExecutionOptions.builder().withBatchSize(1000).withBatchIntervalMs(200).withMaxRetries(5).build(),//4.参数配置 连接参数new JdbcConnectionOptions.JdbcConnectionOptionsBuilder().withUrl("jdbc:mysql://192.168.88.163:3306/bigdata?useSSL=false").withUsername("root").withPassword("123456").withDriverName("com.mysql.jdbc.Driver").build()));//5.执行环境env.execute();}@Data@NoArgsConstructor@AllArgsConstructorpublic static class Student {private Integer id;private String name;private Integer age;} }
Kafka 连接方式
-
Kafka 是消息队列
-
需求:
通过 Flink 将数据元素写入(producer)到 Kafka 中
package cn.itcast.flink.sink;import com.alibaba.fastjson.JSON; import lombok.AllArgsConstructor; import lombok.Data; import lombok.NoArgsConstructor; import org.apache.flink.api.common.functions.MapFunction; import org.apache.flink.api.common.serialization.SimpleStringSchema; import org.apache.flink.streaming.api.datastream.DataStreamSource; import org.apache.flink.streaming.api.datastream.SingleOutputStreamOperator; import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment; import org.apache.flink.streaming.connectors.kafka.FlinkKafkaProducer; import org.apache.flink.streaming.connectors.kafka.internals.KafkaSerializationSchemaWrapper; import org.apache.flink.streaming.connectors.kafka.partitioner.FlinkFixedPartitioner; import org.apache.kafka.clients.producer.ProducerConfig;import java.util.Properties;/*** Author itcast* Date 2021/6/17 16:46* 需求: 将数据元素封装成 JSON字符串 生产到 Kafka 中* 步骤:**/ public class KafkaProducerDemo {public static void main(String[] args) throws Exception {//1.envStreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();//2.Source 生成一个元素 StudentDataStreamSource<Student> studentDS = env.fromElements(new Student(102, "Oking", 25));//3.Transformation//注意:目前来说我们使用Kafka使用的序列化和反序列化都是直接使用最简单的字符串,所以先将Student转为字符串//3.1 map 方法 将 Student转换成字符串SingleOutputStreamOperator<String> mapDS = studentDS.map(new MapFunction<Student, String>() {@Overridepublic String map(Student value) throws Exception {//可以直接调用JSON的toJsonString,也可以转为JSONString json = JSON.toJSONString(value);return json;}});//4.SinkProperties props = new Properties();props.setProperty(ProducerConfig.BOOTSTRAP_SERVERS_CONFIG, "192.168.88.161:9092");//根据参数实例化 FlinkKafkaProducer//4.1如果不需要复杂的参数设置,只需要将数据存储到 kafka 消息队列中,使用第一个重载方法// 如果需要设置复杂的 kafka 的配置的时候, 使用除了第一个之外的重载方法// 如果需要设置仅一次语义 Semantic ,可以使用最后两个/*FlinkKafkaProducer producer = new FlinkKafkaProducer("192.168.88.161:9092,192.168.88.162:9092,192.168.88.163:9092","flink_kafka",new SimpleStringSchema());*/FlinkKafkaProducer<String> producer = new FlinkKafkaProducer<String>("flink_kafka",new KafkaSerializationSchemaWrapper("flink_kafka",new FlinkFixedPartitioner(),false,new SimpleStringSchema()),props,//支持仅一次语义的方式进行提交数据FlinkKafkaProducer.Semantic.EXACTLY_ONCE);mapDS.addSink(producer);// ds.addSink 落地到kafka集群中//5.executeenv.execute();//测试 /export/server/kafka/bin/kafka-console-consumer.sh --bootstrap-server node1:9092 --topic flink_kafka}@Data@NoArgsConstructor@AllArgsConstructorpublic static class Student {private Integer id;private String name;private Integer age;} }
从 kafka 集群中消费数据
-
需求
读取 kafka 中的数据到控制台
-
开发步骤
/*** Author itcast* Date 2021/6/17 16:46* 需求: 将数据元素封装成 JSON字符串 生产到 Kafka 中* 步骤:**/ public class KafkaProducerDemo {public static void main(String[] args) throws Exception {//1.envStreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();//2.Source 生成一个元素 StudentDataStreamSource<Student> studentDS = env.fromElements(new Student(104, "chaoxian", 25));//3.Transformation//注意:目前来说我们使用Kafka使用的序列化和反序列化都是直接使用最简单的字符串,所以先将Student转为字符串//3.1 map 方法 将 Student转换成字符串SingleOutputStreamOperator<String> mapDS = studentDS.map(new MapFunction<Student, String>() {@Overridepublic String map(Student value) throws Exception {//可以直接调用JSON的toJsonString,也可以转为JSONString json = JSON.toJSONString(value);return json;}});//4.SinkProperties props = new Properties();props.setProperty(ProducerConfig.BOOTSTRAP_SERVERS_CONFIG, "192.168.88.161:9092");//根据参数实例化 FlinkKafkaProducer//4.1如果不需要复杂的参数设置,只需要将数据存储到 kafka 消息队列中,使用第一个重载方法// 如果需要设置复杂的 kafka 的配置的时候, 使用除了第一个之外的重载方法// 如果需要设置仅一次语义 Semantic ,可以使用最后两个/*FlinkKafkaProducer producer = new FlinkKafkaProducer("192.168.88.161:9092,192.168.88.162:9092,192.168.88.163:9092","flink_kafka",new SimpleStringSchema());*/FlinkKafkaProducer<String> producer = new FlinkKafkaProducer<String>("flink_kafka",new KafkaSerializationSchemaWrapper("flink_kafka",new FlinkFixedPartitioner(),false,new SimpleStringSchema()),props,//支持仅一次语义的方式进行提交数据FlinkKafkaProducer.Semantic.EXACTLY_ONCE);mapDS.addSink(producer);// ds.addSink 落地到kafka集群中//5.executeenv.execute();//测试 /export/server/kafka/bin/kafka-console-consumer.sh --bootstrap-server node1:9092 --topic flink_kafka}@Data@NoArgsConstructor@AllArgsConstructorpublic static class Student {private Integer id;private String name;private Integer age;} }
Flink写入到 Redis 数据库
-
Redis 是支持缓存的内存数据库,支持持久化
-
使用场景
- 热数据处理 , 缓存机制
- 去重
- 五种数据类型 String Hash set Zset List
-
需求:
通过 Flink 将数据写入到 Redis 中
package cn.itcast.flink.sink;import org.apache.flink.api.common.functions.FlatMapFunction; import org.apache.flink.api.java.tuple.Tuple; import org.apache.flink.api.java.tuple.Tuple2; import org.apache.flink.streaming.api.datastream.DataStream; import org.apache.flink.streaming.api.datastream.KeyedStream; import org.apache.flink.streaming.api.datastream.SingleOutputStreamOperator; import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment; import org.apache.flink.streaming.connectors.redis.RedisSink; import org.apache.flink.streaming.connectors.redis.common.config.FlinkJedisPoolConfig; import org.apache.flink.streaming.connectors.redis.common.mapper.RedisCommand; import org.apache.flink.streaming.connectors.redis.common.mapper.RedisCommandDescription; import org.apache.flink.streaming.connectors.redis.common.mapper.RedisMapper; import org.apache.flink.util.Collector;/*** Author itcast* Desc* 需求:* 接收消息并做WordCount,* 最后将结果保存到Redis* 注意:存储到Redis的数据结构:使用hash也就是map* key value* WordCount (单词,数量)*/ public class ConnectorsDemo_Redis {public static void main(String[] args) throws Exception {//1.env 执行环境StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();//2.Source 从 socket 中读取数据DataStream<String> linesDS = env.socketTextStream("192.168.88.163", 9999);//3.Transformation//3.1切割并记为1SingleOutputStreamOperator<Tuple2<String, Integer>> wordAndOneDS = linesDS.flatMap(new FlatMapFunction<String, Tuple2<String, Integer>>() {@Overridepublic void flatMap(String value, Collector<Tuple2<String, Integer>> out) throws Exception {String[] words = value.split(" ");for (String word : words) {out.collect(Tuple2.of(word, 1));}}});//3.2分组KeyedStream<Tuple2<String, Integer>, String> groupedDS = wordAndOneDS.keyBy(t -> t.f0);//3.3聚合SingleOutputStreamOperator<Tuple2<String, Integer>> result = groupedDS.sum(1);//4.Sinkresult.print();// * 最后将结果保存到Redis// * 注意:存储到Redis的数据结构:使用hash也就是map// * key value// * WordCount (单词,数量)//-1.创建RedisSink之前需要创建RedisConfig//连接单机版RedisFlinkJedisPoolConfig conf = new FlinkJedisPoolConfig.Builder().setHost("192.168.88.163").setDatabase(2).build();//-3.创建并使用RedisSinkresult.addSink(new RedisSink<Tuple2<String, Integer>>(conf, new RedisWordCountMapper()));//5.executeenv.execute();}/*** -2.定义一个Mapper用来指定存储到Redis中的数据结构*/public static class RedisWordCountMapper implements RedisMapper<Tuple2<String, Integer>> {@Overridepublic RedisCommandDescription getCommandDescription() {//使用哪一种数据类型, key:WordCountreturn new RedisCommandDescription(RedisCommand.HSET, "WordCount");}@Overridepublic String getKeyFromData(Tuple2<String, Integer> data) {// 存储数据的 keyreturn data.f0;}@Overridepublic String getValueFromData(Tuple2<String, Integer> data) {// 存储数据的 valuereturn data.f1.toString();}} }
问题
-
vmware 打开镜像文件 15.5.x 升级为 16.1.0 , 可以升级为
-
fromSequece(1,10) , CPU 12线程, from <= to
设置的并行度大于生成的数据, 并行度为12, 生成数据只有 10 个,报这个。
-
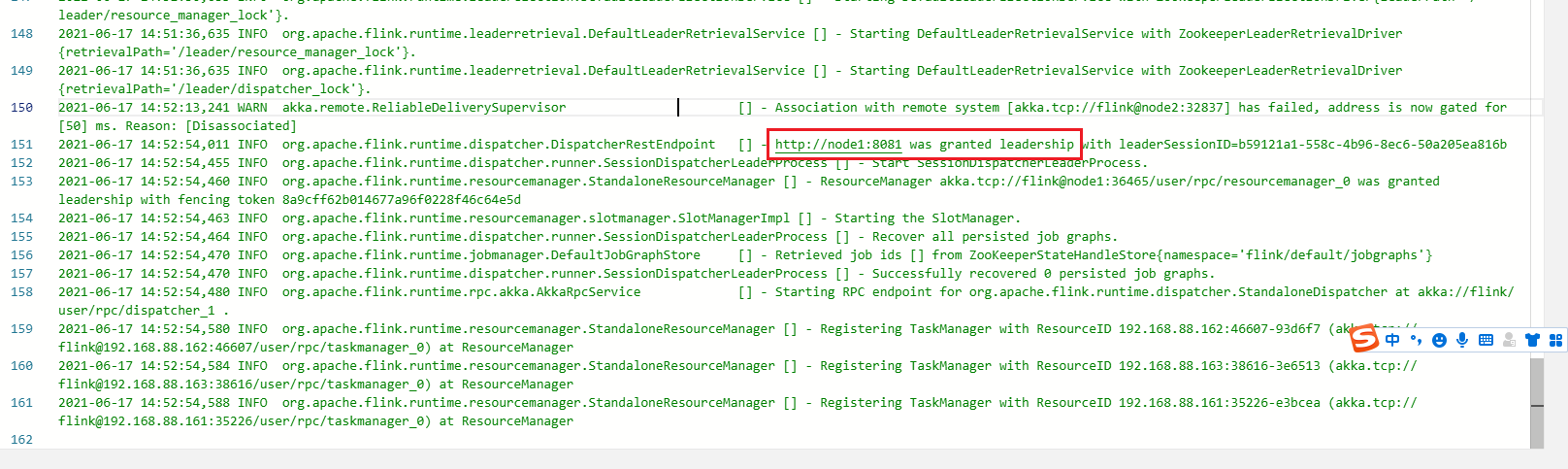
Flink Standalone HA 高可用
jobmanager -> log
总结
以上便是2021年最新最全Flink系列教程_Flink原理初探和流批一体API(二.五)
愿你读过之后有自己的收获,如果有收获不妨一键三连一下~

这篇关于2021年最新最全Flink系列教程_Flink原理初探和流批一体API(二.五)的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!




