datasets专题

Behavior Retrieval: Few-Shot Imitation Learning by Querying Unlabeled Datasets
发表时间:13 May 2023 论文链接:https://readpaper.com/pdf-annotate/note?pdfId=1900983943467731200¬eId=2446646993511259136 作者单位:Stanford University Motivation:使机器人能够以数据有效的方式学习新的视觉运动技能仍然是一个未解决的问题,有无数的挑战。解决这

【论文阅读第一期】Goods:Organizing Google’s Datasets总结
论文阅读第一期的文章《Goods:Organizing Google’s Datasets》讲的是关于谷歌在海量元数据管理方面的实践。本篇总结主要从3个方面进行展开:1.什么是元数据;2.如何管理元数据;3.启发与总结 1.什么是元数据 元数据被称之为描述数据的数据,记录的是文件的特征,包括数据属性、拥有者、权限、数据块等信息。无论是mysql、oracle这样的关系型数据库,还是Hive、H

transformers datasets
☆ 问题描述 在进行自然语言处理项目时,经常需要加载和处理不同的数据集。为了简化这一过程,我们可以使用datasets库来方便地加载、切分、查看和处理数据。本解决方案提供了如何使用datasets库加载、查看和处理数据的详细示例,包括如何加载在线数据集、切分数据集、选择和过滤数据、数据映射和保存等操作。 ★ 解决方案 # load online datasetsdatasets = loa

5 sklearn的数据集-datasets
sklearn的数据集-datasets sklearn的数据集-datasets sklearn 强大数据库文档介绍 1 经典数据2 构造数据 例子1房价例子2创建虚拟数据并可视化 1 sklearn 强大数据库 data sets,有很多有用的,可以用来学习算法模型的数据库。 eg: boston 房价, 糖尿病, 数字, Iris 花。 主要有两种:
7.数据集处理库Hugging Face Datasets
数据集处理库Hugging Face Datasets Datasets 首先解决数据来源问题 使用 Datasets 下载开源数据集 Datasets.load_dataset 实现原理简介 构造 DatasetBuilder 类的主要配置 BuilderConfig 如果您想向数据集添加额外的属性,例如类别标签。有两种方法来填充BuilderConfig类或其子类的属性

Color Constancy Datasets
我的研究领域是颜色以及图像的颜色恒常性,在研究过程中,经常需要找各种的数据集,在此将数据集和下载地址进行整理: 1、Cube+ (2019) The Cube+ dataset is an extension of the Cube dataset proposed earlier by Nikola Banic and Sven Loncaric. This data set contains
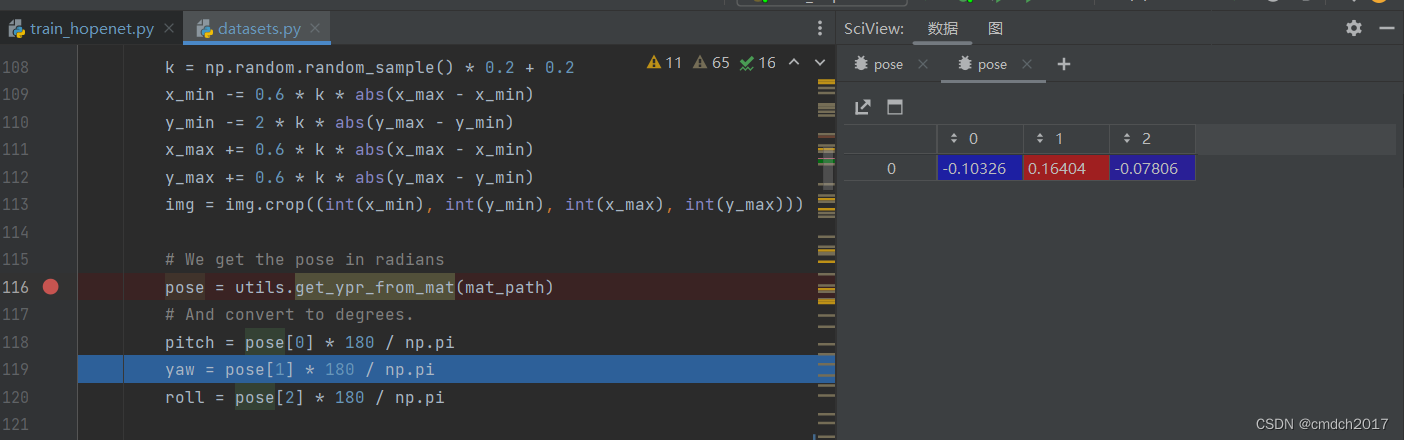
初步研究Pose_300W_LP datasets.py
mat文件参数解读 Color_para:颜色参数,用于描述图像的颜色属性,比如图像的亮度、对比度等信息。 亮度属性、对比度属性、饱和度属性(颜色越鲜艳)、色调属性(色调越偏向蓝色)、色温属性(色温越高,色彩偏白)、色调偏移属性(颜色的相对变化程度)、标志位或者缩放因子 Exp_para:表情参数,用于描述人脸的表情状态,比如微笑、皱眉等。 Illum_para:光照参数,用于描述图像中的光

AI大模型探索之路-训练篇12:语言模型Transformer库-Datasets组件实践
系列篇章💥 AI大模型探索之路-训练篇1:大语言模型微调基础认知 AI大模型探索之路-训练篇2:大语言模型预训练基础认知 AI大模型探索之路-训练篇3:大语言模型全景解读 AI大模型探索之路-训练篇4:大语言模型训练数据集概览 AI大模型探索之路-训练篇5:大语言模型预训练数据准备-词元化 AI大模型探索之路-训练篇6:大语言模型预训练数据准备-预处理 AI大模型探索之路-训练篇7:大语言模型
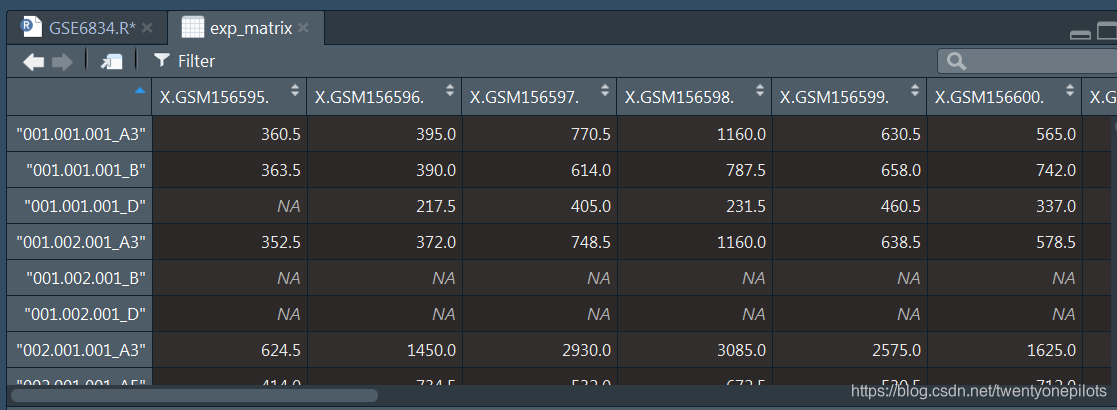
R语言Python GEO DataSets多个Series进行差异基因表达分析以及导入Excel到R的问题
引入 GEO DataSets上,某些Series是由多个series组成的,比如GSE6834,由六个Series组成: This SuperSeries is composed of the following SubSeries: Less… Less… GSE6771 Temporal Cortex Control (mesial temporal lobe epilepsy con
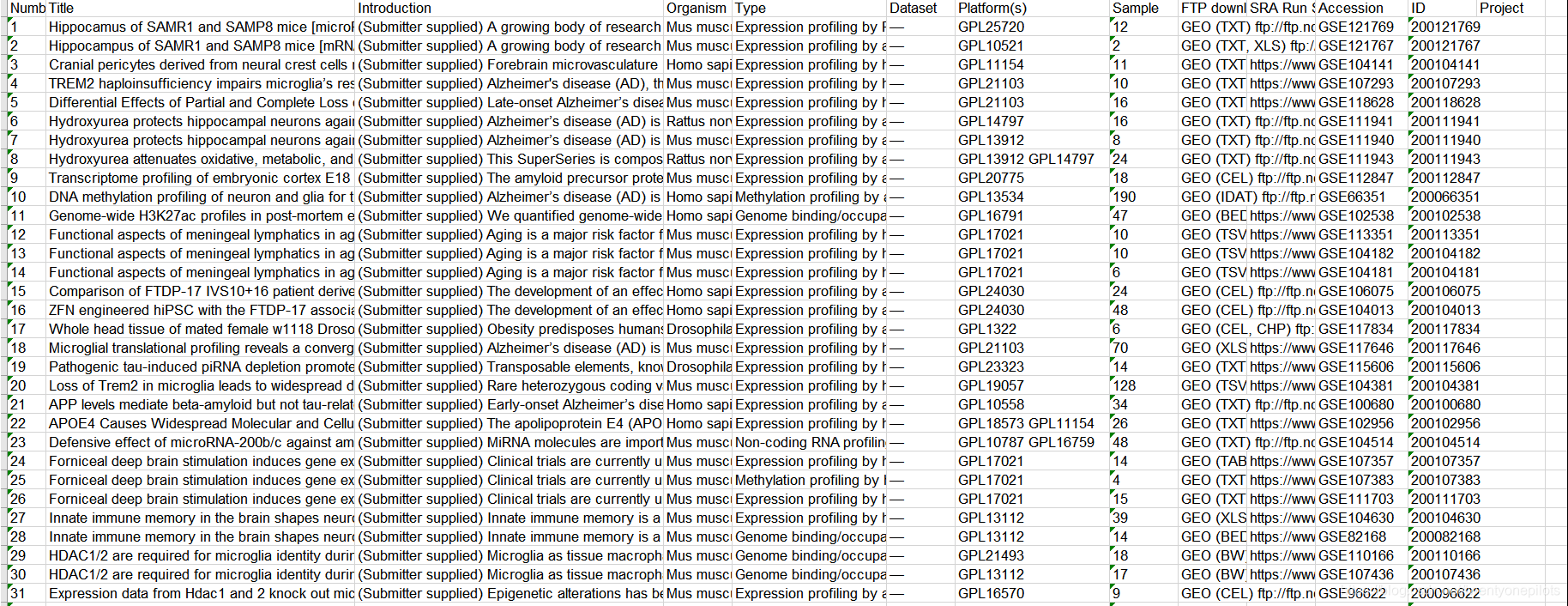
Java 将PubMed GEO DataSets中series类型的检索结果转化为Excel
实际进行生信分析时,更需要的是series类型的数据,和Java 将PubMed GEO DataSets中dataset类型的检索结果转化为Excel中的方法一样,首先转成TXT,然后借助jxl包转为Excel。 源代码如下: /** To change this license header, choose License Headers in Project Properties.*

Java 将PubMed GEO DataSets中dataset类型的检索结果转化为Excel
检索结果举例 为进行生信分析,需要对检索结果转化为Excel并且以标签作为列。首先将检索结果Send to File转化成TXT格式,如下: 通过下面的程序进一步转为Excel(使用jxl包): 源代码: /** To change this license header, choose License Headers in Project Properties.* To change t
【深度学习|Pytorch】torchvision.datasets.ImageFolder详解
ImageFolder详解 1、数据准备2、ImageFolder类的定义transforms.ToTensor()解析 3、ImageFolder返回对象 1、数据准备 创建一个文件夹,比如叫dataset,将cat和dog文件夹都放在dataset文件夹路径下: 2、ImageFolder类的定义 class ImageFolder(DatasetFolder):def
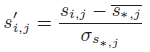
2.app recommendation with very sparse datasets
1.摘要 app的使用曲线呈现很高的峰态和更显著的长尾现象。即,少数最受欢迎的的app享有很高的下载量,绝大多数app所占份额极少,甚至屈指可数,具有很大的稀疏性。 主要原因有:与电影等商品相比,app开发者使用的资源具有很大的多样性且发布app的开支更小。 对稀疏集的处理,可提高降维的使用。 2.我的想法 现有的app商店多数使用以下三种方法提供app:(1)最受欢迎的app列表

Pytorch——torchvision.datasets
torchvision 是PyTorch中专门用来处理图像的库,这个包中有四个大类。 torchvision.datasetstorchvision.modelstorchvision.transformstorchvision.utils torchvision.datasets 是用来进行数据加载的,PyTorch团队在这个包中提前处理好了很多很多图片数据集。 MNISTCOCO(

Pytorch学习 day06(torchvision中的datasets、dataloader)
torchvision的datasets 使用torchvision提供的数据集API,比较方便,如果在pycharm中下载很慢,可以URL链接到迅雷中进行下载(有些URL链接在源码里)代码如下: import torchvision # 导入 torchvision 库# 使用torchvision的datasets模块,模块中包含CIFAR10、CIFAR100、ImageNet、CO
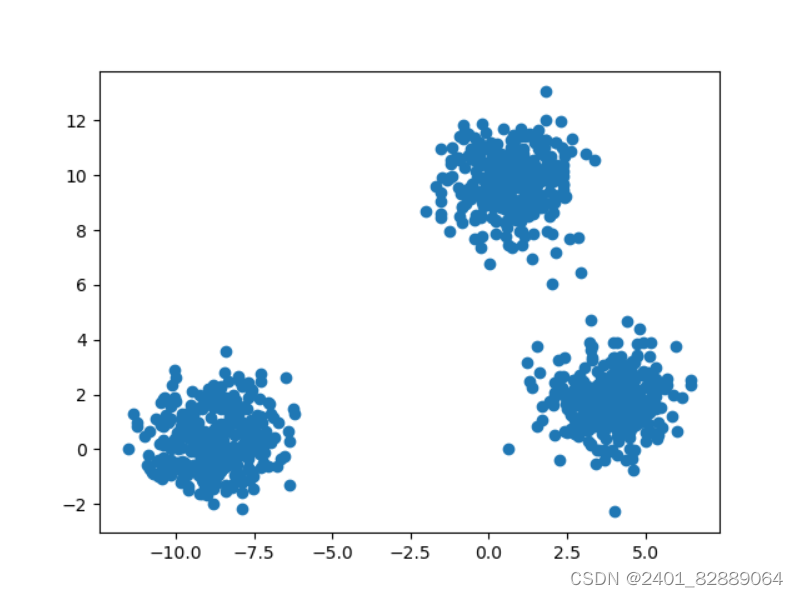
Python-sklearn.datasets-make_blobs
sklearn.datasets.make_blobs()函数形参详解 """@Title: datasets for regression@Time: 2024/3/5@Author: Michael Jie"""from sklearn import datasetsimport matplotlib.pyplot as plt# 产生服从正态分布的聚类数据x, y,
datasets.ImageFolder和train_dataset.class_to_idx的用法
datasets.ImageFolder用法,是将文件夹的名字转化为标签。用于分类任务。 from torchvision import datasetstrain_dataset = datasets.ImageFolder(root=os.path.join(image_path, "train"),transform=data_transform["train"]) 比如在flowe
Scaling Up Crowd-Sourcing to Very Large Datasets: A Case for Active Learning-笔记
通过Active Learning(AL)算法,找到最小的需要标注的数据进行训练,来标记未标记的数据。 AL必须满需下边的需求才能作为crowd-sourced database的默认的最优策略: Generality:算法必须能够应用到任意的分类和标记任务。因为crowd-sourced systems应用广泛。Black-box treatment of the classife

Bootstrap-Scaling Up Crowd-Sourcing to Very Large Datasets: A Case for Active Learning
论文Scaling Up Crowd-Sourcing to Very Large Datasets A Case for Active Learning对bootstrap做了介绍。 原书(B. Efron and R. J. Tibshirani. An Introduction to the Bootstrap. Chapman & Hall, 1993.)

ranker-Scaling Up Crowd-Sourcing to Very Large Datasets: A Case for Active Learning
论文Scaling Up Crowd-Sourcing to Very Large Datasets A Case for Active Learning提出两种AL算法。 首先找到分类器θ对未标注数据的不确定程度。然后让crowd对这些数据进行标定。下边介绍两种不确定性方法。 下边的u是未标记数据,但是是指未标注数据的每一个,而不是整体。 一:Uncertainty Algorithm

activate learning-Scaling Up Crowd-Sourcing to Very Large Datasets: A Case for Active Learning
Active Learning Notation 本文是介绍论文Scaling Up Crowd-Sourcing to Very Large Datasets A Case for Active Learning中的AL算法。 Active learning algorithm主要由:1.一个ranker R; 2. selection strategy S;3. budget allo

Language Models and Datasets - 语言模型与数据集(RNN循环神经网络)
文章目录 语言模型与数据集学习语言模型马尔可夫模型与n元语法自然语言统计读取长序列数据随机采样顺序分区 小结 语言模型与数据集 之前,我们了解了如何将文本数据映射为词元,以及将这些词元可以视为一系列离散的观测,例如单词或字符。 假设长度为 T T T的文本序列中的词元依次为 x 1 , x 2 , … , x T x_1, x_2, \ldots, x_T x1,x2,
from sklearn.datasets import make_classification生成随机类别的数据
先看help结果,及返回的结果,就是训练用的数据 make_classification(n_samples=100, n_features=20, n_informative=2, n_redundant=2, n_repeated=0, n_classes=2, n_clusters_per_class=2, weights=None, flip_y=0.01, class_sep=1.

【PyTorch简介】3.Loading and normalizing datasets 加载和规范化数据集
Loading and normalizing datasets 加载和规范化数据集 文章目录 Loading and normalizing datasets 加载和规范化数据集Datasets & DataLoaders 数据集和数据加载器Loading a Dataset 加载数据集Iterating and Visualizing the Dataset 迭代和可视化数据集Crea

【HuggingFace Transformer库学习笔记】基础组件学习:Datasets
基础组件——Datasets datasets基本使用 导入包 from datasets import * 加载数据 datasets = load_dataset("madao33/new-title-chinese")datasetsDatasetDict({train: Dataset({features: ['title', 'content'],num_rows
torchvision.datasets.ImageFolder 数据加载
1、torchvision已经余弦实现了常用的Dataset,包括CIFAR-10,以及ImageNet、COCO、MNIST、LSUN等数据集,可通过诸如torchvision.datasets.CIFAR10来调用。 2、ImageFolder假设所有的文件按文件夹保存,每个文件下存储同一类别的图片,文件夹名为类名,构造函数如下: ImageFolder(root,transform=Non