本文主要是介绍2.app recommendation with very sparse datasets,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
1.摘要
app的使用曲线呈现很高的峰态和更显著的长尾现象。即,少数最受欢迎的的app享有很高的下载量,绝大多数app所占份额极少,甚至屈指可数,具有很大的稀疏性。
主要原因有:与电影等商品相比,app开发者使用的资源具有很大的多样性且发布app的开支更小。
对稀疏集的处理,可提高降维的使用。
2.我的想法
现有的app商店多数使用以下三种方法提供app:(1)最受欢迎的app列表(2)几大类别分类呈现(3)关键字搜索。
存在问题:(1)极少数app因受欢迎而更受欢迎,埋没新生高质量app市场;(2)类别分类太粗糙,通常一个类别下包含超多条目;(3)用户并不知道要搜索什么。搜索的通常是标题。
3.结论
传统基于记忆的算法(memory-based)对少数受欢迎的app更有利,会造成更严重的峰态;
隐语义模型(latent factor model)更适合对电影等商品的处理,对稀疏集的处理准确性不足;
本文所提出的eigenapp model 对于具有稀疏性的长尾app具有优越的推荐效果。
4.数据处理
(1)数据集
使用GetJar上2011年11月7日-11月21日,101106个用户,55020个app的记录。
(2)数据预处理。
峰态和长尾现象明显,定义最受欢迎的100个app作为头部。可能存在同一app功能类似,多次发布。数据集中清除不足20个用户的app数据。
(3)衡量指标设置。
选取使用的天数作为衡量指标。因为对app的评分受上下文影响较大,而且,对于不同类别app,使用的多不一定评分高。
为了说明更合理,采取两种评测系统:1)使用的天数;2)使用和未使用二值。
5.模型设计
(1)非个性化模型
根据受欢迎度进行排序,受欢迎度通过用户数衡量。
(2)基于记忆的模型
通过对数据的分析发现超过90%的app对只有一个或没有共同用户。由于皮尔逊相关系数(Pearson correlation coefficient)需要大量共同用户,所以选择余弦相似度。
用R表示m*n用户-app矩阵,根据 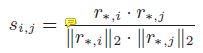 计算得item-item相似度矩阵S,可想而知S较为稀疏。考虑用
计算得item-item相似度矩阵S,可想而知S较为稀疏。考虑用 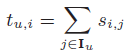 计算亲密度,I_u表示用户u使用的app集合,根据亲密度评分来生成top-N列表。发现用Z评分对S_i,j进行正规化后效果更好,
计算亲密度,I_u表示用户u使用的app集合,根据亲密度评分来生成top-N列表。发现用Z评分对S_i,j进行正规化后效果更好, 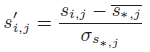 。同时能减少噪声。
。同时能减少噪声。
计算得item-item相似度矩阵S,可想而知S较为稀疏。考虑用 计算亲密度,I_u表示用户u使用的app集合,根据亲密度评分来生成top-N列表。发现用Z评分对S_i,j进行正规化后效果更好, 。同时能减少噪声。
(3)隐语义模型
对于之前构建的R矩阵,利用PureSVD进行因子分解。PureSVD不盲目追求RMSE(均方根误差)最优,而是根据相关评分相对排序(什么鬼?)。
(4)特征app模型(eigenapp model)
对矩阵R的item向量进行正规化,防止倾向于热门app。采用PCA(主成分分析)提取特征。
各种投影,转置提取出较好的特征。
6.评测
评测指标:准确度;长尾app的准确度;流行度;多样性。
这篇关于2.app recommendation with very sparse datasets的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!