dataloader专题

PyTorch数据加载:自定义数据集【Dataset:处理每个原始样本】【DataLoader:每次生成batch_size个样本】【collate_fn:重新设置一个Batch中所有样本的加载格式】
一、自定义Dataset Dataset是一个包装类: 用来将数据包装为Dataset类,然后传入DataLoader中,我们再使用DataLoader这个类来更加快捷的对数据进行操作。可以通过继承Dataset来将数据集的源文件、规模和其他非必要的功能打包,从而供DataLoader使用。 1、“文本分类”任务下使用自定义Dataset class.txt:所有类别 finance

Pytorch.Dataloader 详细深度解读和微修改源代码心得
关于pytorch 的dataloader库,使用pytorch 基本都会用到的一个库 今天遇到了一个问题,我在训练的时候,采用batch_size =2 去训练,最终的loss抖动太大了,看得出来应该是某些样本在打标的时候打的不好导致的,需要找出这些样本重新修正。但是一开始是采用的dataloader默认库。然后输入进去的图像dataset 传出来之后是经过shuffle的,没有办法定位到哪张

Pytorch:复写Dataset函数详解,以及Dataloader如何调用
在 PyTorch 中,Dataset 和 DataLoader 是数据加载和处理的重要组件。下面详细介绍 Dataset 类的作用及其 __len__() 和 __getitem__() 方法,以及它们如何与 DataLoader 协作,包括数据打乱(shuffle)和批处理(batching)等功能。 Dataset 类 Dataset 是一个抽象基类,用于表示一个数据集。你需要继承这个基

自己造轮子:深度学习dataloader自己实现
自己造轮子:深度学习dataloader自己实现 **摘要:**因为计算机性能的限制,所有的深度学习框架都是采用批量随机梯度下降,所以每次计算都要读取batch_size的数据。这里以自己实现的方式介绍深度学习框架实现批量读取数据的原理,不涉及具体细节和一些逻辑,只注重大体流程和原理。 总体流程: 采用yield写一个生成器函数实现批量图片/标注信息的读取采用multiprocessing/
DataLoader基础用法
DataLoader 是 PyTorch 中一个非常有用的工具,用于将数据集进行批处理,并提供一个迭代器来简化模型训练和评估过程。以下是 DataLoader 的常见用法和功能介绍: 基本用法 创建数据集: 首先,需要一个数据集。数据集可以是 PyTorch 提供的内置数据集,也可以是自定义的数据集。数据集需要继承 torch.utils.data.Dataset 并实现 __len__ 和
解决pytorch中Dataloader读取数据太慢的问题
提示:文章写完后,目录可以自动生成,如何生成可参考右边的帮助文档 文章目录 前言一、造成的原因二、查找不匹配的原因三、解决方法四、使用方法后言 前言 最近在使用pytorch框架进行模型训练时遇到一个性能问题,即数据读取的速度远远大于GPU训练的速度,导致整个训练流程中有大部分时间都在等待数据发送到GPU,在资源管理器中呈现出CUDA使用率周期性波动,且大部分时间都是
将自己的数据集加载到dataloader中
from torch.utils.data import Datasetclass YourDataset(Dataset): # 继承Dataset类# 构造函数必须存在def __init__(self, root_dir, ann_file, transform=None):self.ann_file = ann_fileself.root_dir = root_dirself.img_

【深度学习实战(11)】搭建自己的dataset和dataloader
一、dataset和dataloader要点说明 在我们搭建自己的网络时,往往需要定义自己的dataset和dataloader,将图像和标签数据送入模型。 (1)在我们定义dataset时,需要继承torch.utils.data.dataset,再重写三个方法: init方法,主要用来定义数据的预处理getitem方法,数据增强;返回数据的item和labellen方法,返回数据数量 (
DataLoader自定义数据集制作
如何自定义数据集: - 1.数据和标签的目录结构先搞定(得知道到哪读数据) - 2.写好读取数据和标签路径的函数(根据自己数据集情况来写) - 3.完成单个数据与标签读取函数(给dataloader举一个例子) 以花朵数据集为例: - 原来数据集都是以文件夹为类别ID,现在咱们换一个套路,用txt文件指定数据路径与标签(实际情况基本都这样) - 这回咱们的任务就是在txt文件中获取图像路径与
DataLoader 的 collate_fn 解释与示例教程
文章目录 导包数据Dataloadercollate_fn 导包 import torchfrom torch.utils.data import Datasetfrom typing import Any 数据 class CustomDataset(Dataset):def __init__(self, length) -> None:super().__init
Pytorch torch.utils.data.DataLoader 用法详细介绍
文章目录 1. 介绍2. 参数详解3. 用法4. 参考 1. 介绍 torch.utils.data.DataLoader 是 PyTorch 提供的一个用于数据加载的工具类,用于批量加载数据并为模型提供输入。它可以将数据集包装成一个可迭代的对象,方便地进行数据加载和批处理操作。Pytorch DataLoader 的详细官方介绍看这里 2. 参数详解 dataset
pytorch 函数DataLoader
Dataset(https://blog.csdn.net/TH_NUM/article/details/80877196)只负责数据的抽象,一次调用getitem只返回一个样本。前面提到过,在训练神经网络时,最好是对一个batch的数据进行操作,同时还需要对数据进行shuffle和并行加速等。对此,PyTorch提供了DataLoader帮助我们实现这些功能。 DataLoader的函数定义如
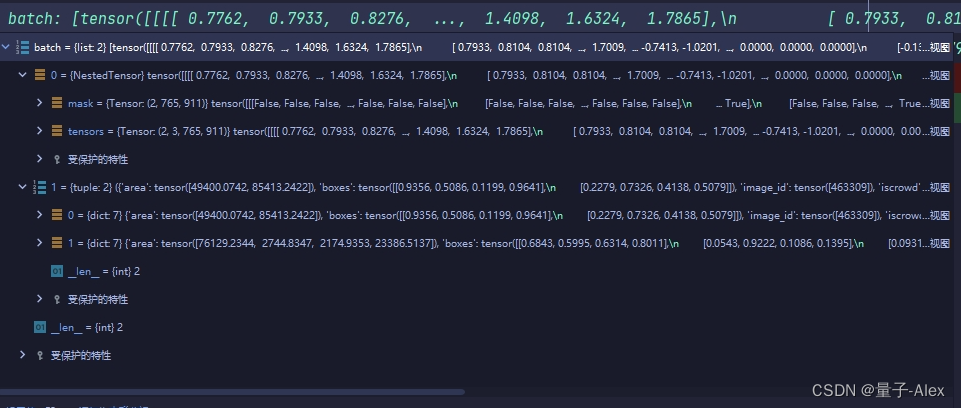
【DETR系列目标检测算法代码精讲】01 DETR算法03 Dataloader代码精讲
与一般的Dataloader的区别在于我们对图像进行了随机裁剪,需要进行额外的操作才能将其打包到dataloader里面 这一段的代码如下: if args.distributed:sampler_train = DistributedSampler(dataset_train)sampler_val = DistributedSampler(dataset_val, shuffle
DataLoader;model_best.eval():设置模型为评估模式:
目录 DataLoader model_best.eval():设置模型为评估模式: DataLoader 您正在使用PaddlePaddle框架的DataLoader来创建一个测试数据加载器。这个加载器会从FoodDataset数据集中读取数据,并且按照指定的参数进行配置。以下是对您提供的代码片段的详细解释: pythonbatch_size = 128 # 设置每个batch
Pytorch学习系列之六: 数据并行处理及模型文件批量自动加载(Dataset, DataLoader用法)
说明 将学习如何用 DataParallel 来使用多 GPU。 通过 PyTorch 使用多个 GPU 非常简单。 device = torch.device("cuda:0")model.to(device) 然后,你可以复制所有的张量到 GPU: mytensor = my_tensor.to(device) 请注意,只是调用 my_tensor.to(device) 返回一
Pytorch之Dataset和DataLoader的注意事项
1、数据集的保存形式:一行一行的。 比如说预测两个值的加法:a+b=c,那么传进Dataset的形式应该是 a1,b1,c1 a2,b2,c2 ... an,bn,cn 2、代码 import numpy as npimport pandas as pdimport torchfrom torch.utils.data import DataLoader, Dataset# 创
pytorch中的dataset和dataloader
PyTorch为我们提供了Dataset和DataLoader类分别负责可被Pytorch使用的数据集的创建以及向训练传递数据的任务。一般在项目中,我们需要根据自己的数据集个性化pytorch中储存数据集的方式和数据传递的方式,需要自己重写一些子类。 torch.utils.data.Dataset 是一个表示数据集的抽象类。任何自定义的数据集都需要继承这个类并覆写相关方法。数据集主要有两
pytoch如何加载批量数据--Dataset,DataLoader
Dataset Dataset 是一个抽象类。我们可以定义一个类继承这个类,从而加载数据,构造数据集(索引) DataLoader DataLoader是一个帮助我们在Pytorch中加载数据的类,在训练测试时加载数据,获取mini-batch 使用说明:¶ epoch:One forward pass and one backward pass of all the training
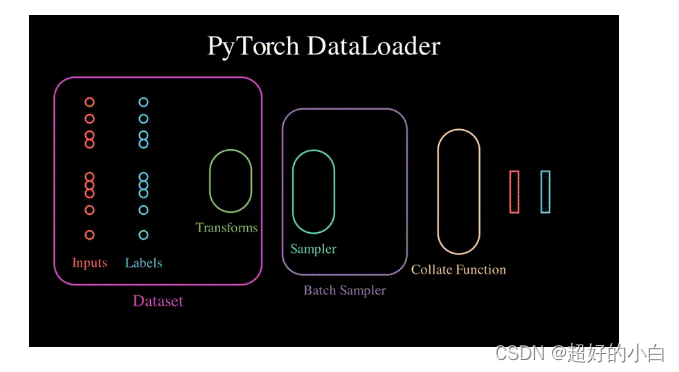
【学习】pytorch框架的数据管理—— 理解Dataloader
参考:https://spite-triangle.github.io/artificial_intelligence/#/./README 1.标准数据集 使用:以 CIFAR10 数据集为例,其他数据集类似。 # root:数据存放路径# train:区分训练集,还是测试集# transform:对数据集中的图进行预处理# target_transfrom:对期望输出进行预处理#

Pytorch学习 day06(torchvision中的datasets、dataloader)
torchvision的datasets 使用torchvision提供的数据集API,比较方便,如果在pycharm中下载很慢,可以URL链接到迅雷中进行下载(有些URL链接在源码里)代码如下: import torchvision # 导入 torchvision 库# 使用torchvision的datasets模块,模块中包含CIFAR10、CIFAR100、ImageNet、CO
pytorch dataloader worker is killed by signal killed
在网上查了很久的资料都说是内存的问题,或者把num_work给调成0。但是对于我的问题没有得到解决 这里提供另一个思路,可能是dataloader在读__get_item__的时候没有读正确,我的问题就是因为这个,没有读到正确的数据集,所以可以检查一下自己的数据集是不是读正确了
pytorch -- DataLoader
定义 提供了给定数据集的迭代器 torch.utils.data.DataLoader(dataset, batch_size=1, 每次拿多少数据shuffle=None, 是否打乱sampler=None, batch_sampler=None, num_workers=0, 多进程(加载数据时采用)默认是0,使用主进程加载数据collate_fn=None, pin_memo
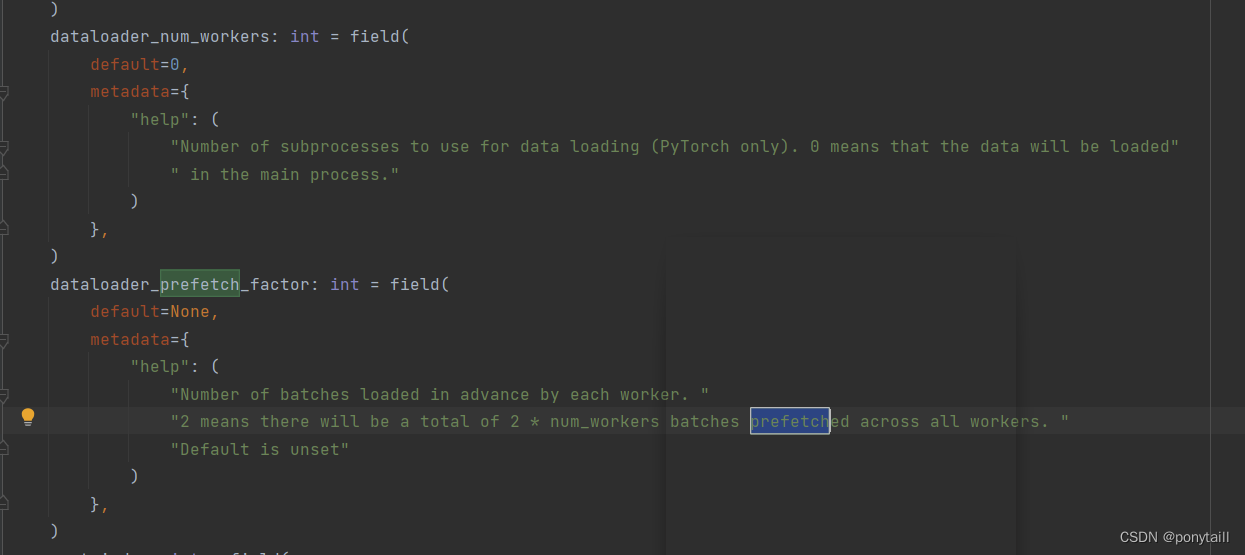
pytorch中dataloader的prefetch_factor出错
今天跑huggingface的示例的时候,遇到了最让我头疼的问题,国内网上还没有对应的解释,我可能是第一人(汗)先看看报错: Traceback (most recent call last):File "F:\transformer\transformers\examples\pytorch\image-classification\run_image_classification.py",

浅谈Dataset和Dataloader在加载数据时如何调用到__getitem__()函数
浅谈Dataset和Dataloader • 1 Dataset基类 • 2 构建Dataset子类 o 2.1 Init o 2.2 getitem • 3 dataloader 1 Dataset基类 PyTorch 读取其他的数据,主要是通过 Dataset 类,所以先简单了解一下 Dataset 类。在看很多PyTorch的代码的时候,也会经常看到dataset这个东西的存在。Datas
python使用DataLoader对数据集进行批处理
使用DataLoader对数据集进行批处理,转自 https://www.cnblogs.com/JeasonIsCoding/p/10168753.html 第一步:创建torch能够识别的数据集类型 首先建立两个向量X和Y,一个作为输入的数据,一个作为正确的结果: import torchimport torch.utils.data as DataBATCH_SIZE = 3
数据读取机制Dataloader和Dataset
Dataloader 功能:构建可迭代的数据转载器 dataset:Dataset类,决定数据从哪里读取,以及如何读取bathsize:批的大小num_works:是否多进程读取数据shuffle:每个epoch是否乱序drop_last:当样本数不能被bathsize整除时,是否舍弃最后一批数 Epoch:一个epoch等于使用训练集中的全部样本训练一次 Iteration:一个iterat