本文主要是介绍【DETR系列目标检测算法代码精讲】01 DETR算法03 Dataloader代码精讲,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
与一般的Dataloader的区别在于我们对图像进行了随机裁剪,需要进行额外的操作才能将其打包到dataloader里面
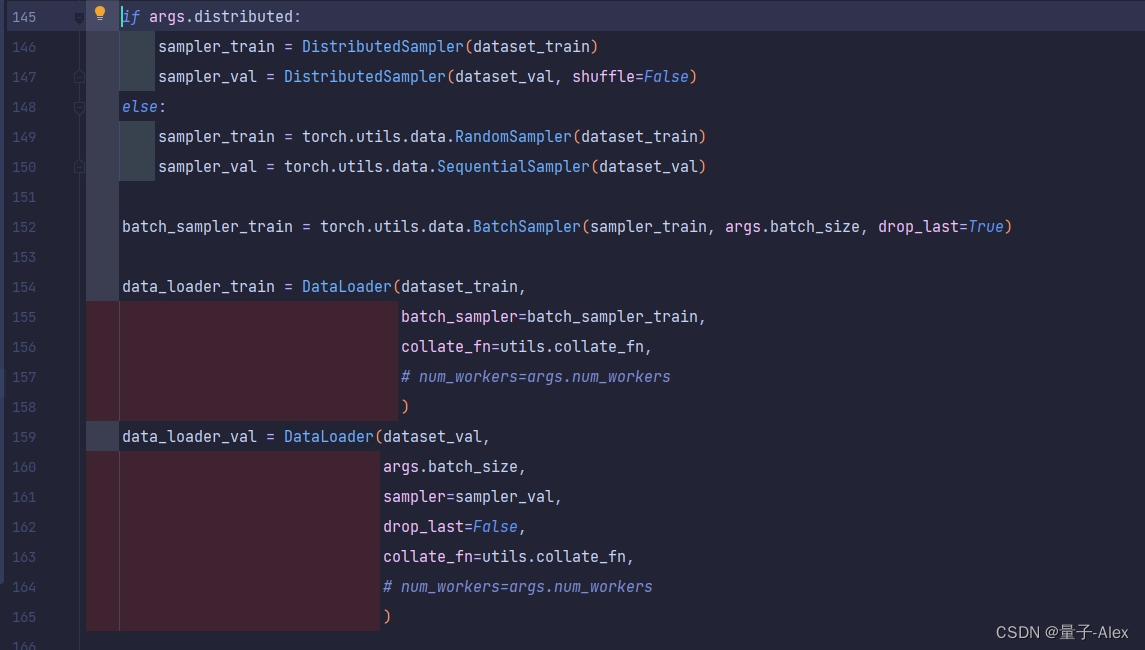
这一段的代码如下:
if args.distributed:sampler_train = DistributedSampler(dataset_train)sampler_val = DistributedSampler(dataset_val, shuffle=False)else:sampler_train = torch.utils.data.RandomSampler(dataset_train)sampler_val = torch.utils.data.SequentialSampler(dataset_val)batch_sampler_train = torch.utils.data.BatchSampler(sampler_train, args.batch_size, drop_last=True)data_loader_train = DataLoader(dataset_train,batch_sampler=batch_sampler_train,collate_fn=utils.collate_fn,# num_workers=args.num_workers)data_loader_val = DataLoader(dataset_val,args.batch_size,sampler=sampler_val,drop_last=False,collate_fn=utils.collate_fn,# num_workers=args.num_workers)
对于训练数据集,使用RandowSampler类进行随机采样
对于验证数据集,使用SequentialSampler进行顺序采样
采样以后,使用BatchSampler打包成batch
然后再使用Dataloader
Dataloader中有个函数
collate_fn

这个函数又调用了一个函数nested_tensor_from_tensor_list
这个函数重新定义了我们输入数据的格式
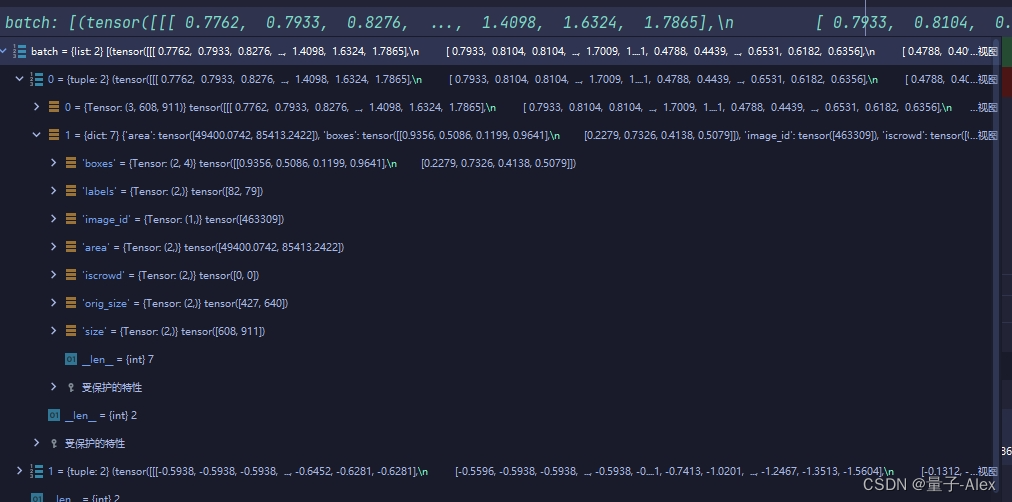
默认的batch为2,我们输入的就是包含了两个元素的list,其中每个元素都是我们从dataset的__getitem__方法获得的输出
然后通过zip函数进行解析
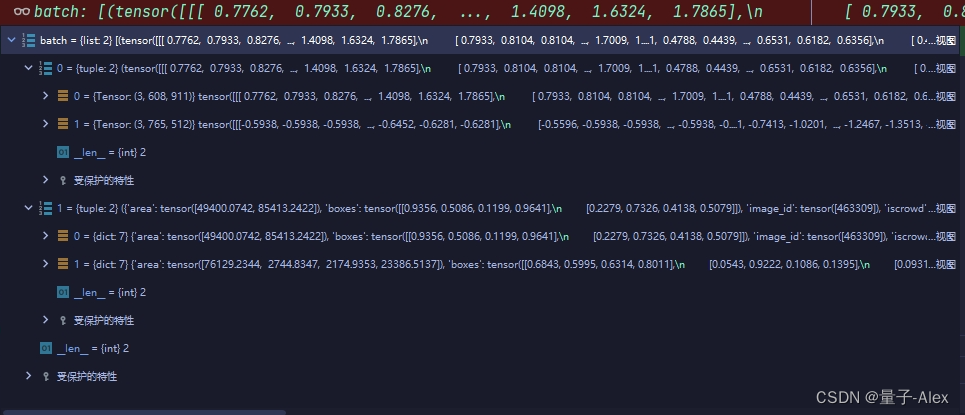
可以看到之前的形式是一个元素中是img+target
现在变成了一个元素里面都是img,另一个元素里面都是target
batch[0] = nested_tensor_from_tensor_list(batch[0])
然后通过索引0取出图像部分
传入到nested_tensor_from_tensor_list方法中
这个方法的全部代码如下
def nested_tensor_from_tensor_list(tensor_list: List[Tensor]):# TODO make this more generalif tensor_list[0].ndim == 3:if torchvision._is_tracing():# nested_tensor_from_tensor_list() does not export well to ONNX# call _onnx_nested_tensor_from_tensor_list() insteadreturn _onnx_nested_tensor_from_tensor_list(tensor_list)# TODO make it support different-sized imagesmax_size = _max_by_axis([list(img.shape) for img in tensor_list])batch_shape = [len(tensor_list)] + max_sizeb, c, h, w = batch_shapedtype = tensor_list[0].dtypedevice = tensor_list[0].devicetensor = torch.zeros(batch_shape, dtype=dtype, device=device)mask = torch.ones((b, h, w), dtype=torch.bool, device=device)for img, pad_img, m in zip(tensor_list, tensor, mask):pad_img[: img.shape[0], : img.shape[1], : img.shape[2]].copy_(img)m[: img.shape[1], :img.shape[2]] = Falseelse:raise ValueError('not supported')return NestedTensor(tensor, mask)
定义了一个函数nested_tensor_from_tensor_list,该函数接受一个Tensor列表(tensor_list)作为输入,并返回一个NestedTensor对象。NestedTensor是一个特殊的数据结构,通常用于表示图像数据,其中可以包含不同大小的图像,并且有一个与之对应的掩码(mask)来表示每个图像的实际大小。
检查tensor_list中的第一个Tensor的维度是否为3。
通过_max_by_axis函数来确定tensor_list中所有图像的最大尺寸。这意味着最终生成的NestedTensor将包含所有图像的最大高度和宽度。
这个_max_by_axis函数的代码如下:
def _max_by_axis(the_list):# type: (List[List[int]]) -> List[int]maxes = the_list[0]for sublist in the_list[1:]:for index, item in enumerate(sublist):maxes[index] = max(maxes[index], item)return maxes
对于归一化处理后的图像,我们的输入是一个三维的矩阵
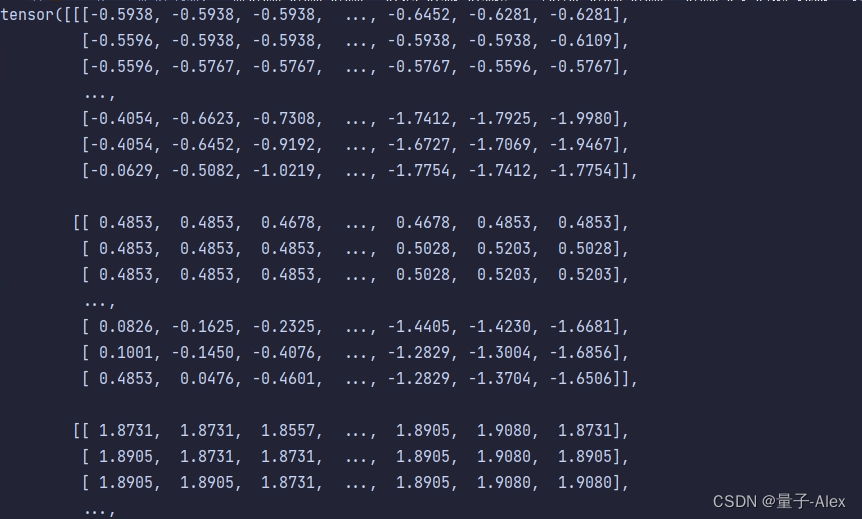

将两个三维矩阵传入这个方法
这个list有两个元素,maxes列表首先被初始化为第一个子列表
遍历the_list中除了第一个子列表之外的所有子列表,
对于当前子列表中的每个元素,我们将其与maxes列表中对应索引的当前最大值进行比较。我们使用max函数来确定这两个值中的较大值,并将其赋值给maxes列表的相应位置。
进行比较的这个索引值就是宽和高的值
比如
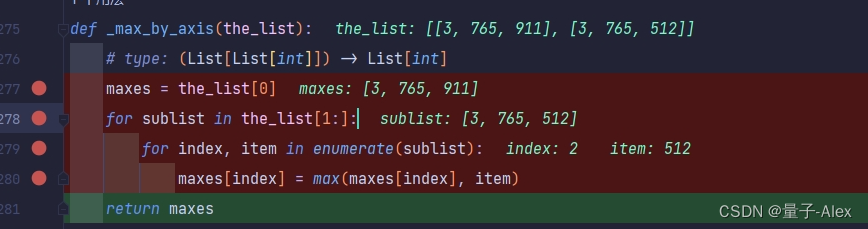
这里第二个子列表的的index是2,值是512
就要与第一个子列表的第2个值进行比较,就是911
所以输出的就是这个batch里面所有图像中最长的宽度和高度
这个尺寸就是这个batch最终的目标尺寸
接下来的操作就是需要将这个batch中的每一张图像加上padding
使得它们的尺寸都满足这个要求

在batch的维度前面加上batch中图像的个数
然后创造一个这个尺寸的底图 值全为0
将所有图像按照左上角点对齐的方式填充到这个底图上

再生成一个batch_size为2,宽和高分别为最大宽和高的全1矩阵
它的作用是记录图像中哪些部分是图像 哪些部分是padding
接下来通过循环记录图像中的每个位置,图像部分都记为false
表示这个位置不是padding
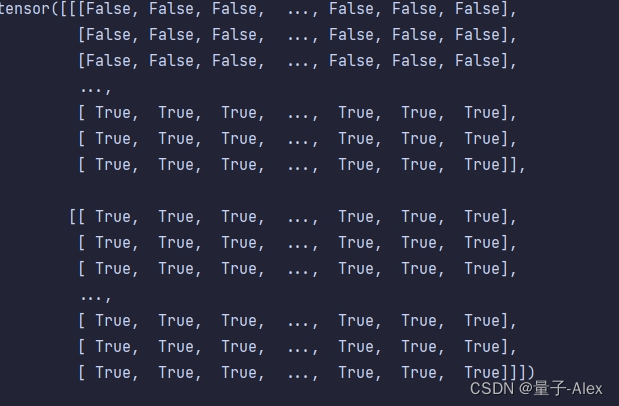
然后用输出的结果替换掉batch的第一个元素,也就是image的部分

这个时候输出的就是
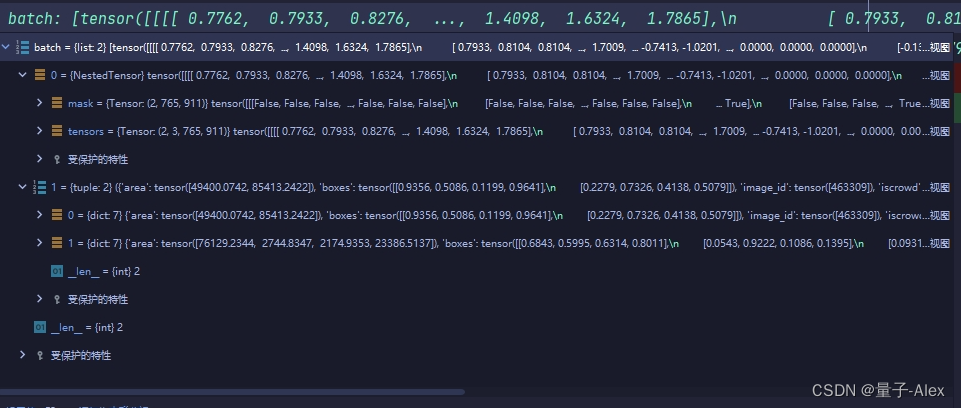
以上就是dataloader的部分
这篇关于【DETR系列目标检测算法代码精讲】01 DETR算法03 Dataloader代码精讲的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!



