computation专题
【利兹】XJCO3221 Parallel Computation 并行计算考试资料辅导
XJCO3221 (34964) 西交利兹院 【并行计算】 Parallel Computation 资料or辅导 需要请私聊 1.独家近年考试题 包你高分 2.cw: Coursework 1: OpenMP Programming Assignment Coursework 2: MPI Programming Assignment and Analysis Coursewor

全量知识系统 祖传代码 之1 概要-“计算computation”的“概念图式schema”
祖传代码 概要 祖传代码作为整个系统中的三种程序(母语脚本、父类源码、子代基线)的共同基础。它限定了三种程序中的每一个的过程规格(process specification),包括所有 活动类型、活动范围及其应有的规矩。 这种1+3的三位一体的设计结构是全量知识系统的架构风格。这个架构风格的核心任务是“计算computation”--核心目标(主题词)。为了这一核心计算任务的目标,它树立了

Piranha: A GPU Platform for Secure Computation
目录 概述设备层协议层应用层 概述 Piranha是一款通用的模块化平台用于使用GPU加速基于密钥共享的MPC协议,它的结构如下图所示。 Piranha有三层结构:设备层,协议层,应用层。下文将对三层的功能做具体介绍。 设备层 设备层通过提供当前通用GPU库缺失的基于整数的内核可以进行独立的加速密钥共享协议。 设备层有三个模块分别是:数据管理(data managemn


通用图形处理单元GPGPU计算管线(General Purpose computation on Graphics Processing Units)介绍
文章目录 GPGPU计算管线一、引言二、GPGPU计算模型2.1 数据并行性2.2 计算密集型 三、GPGPU计算管线3.1 管线(Pipeline)概述3.2 计算管线结构输入阶段执行阶段输出阶段 3.3 计算管线优化内存优化计算优化 四、代码示例五、结论 GPGPU计算管线 一、引言 通用图形处理单元(General Purpose computation on Gra
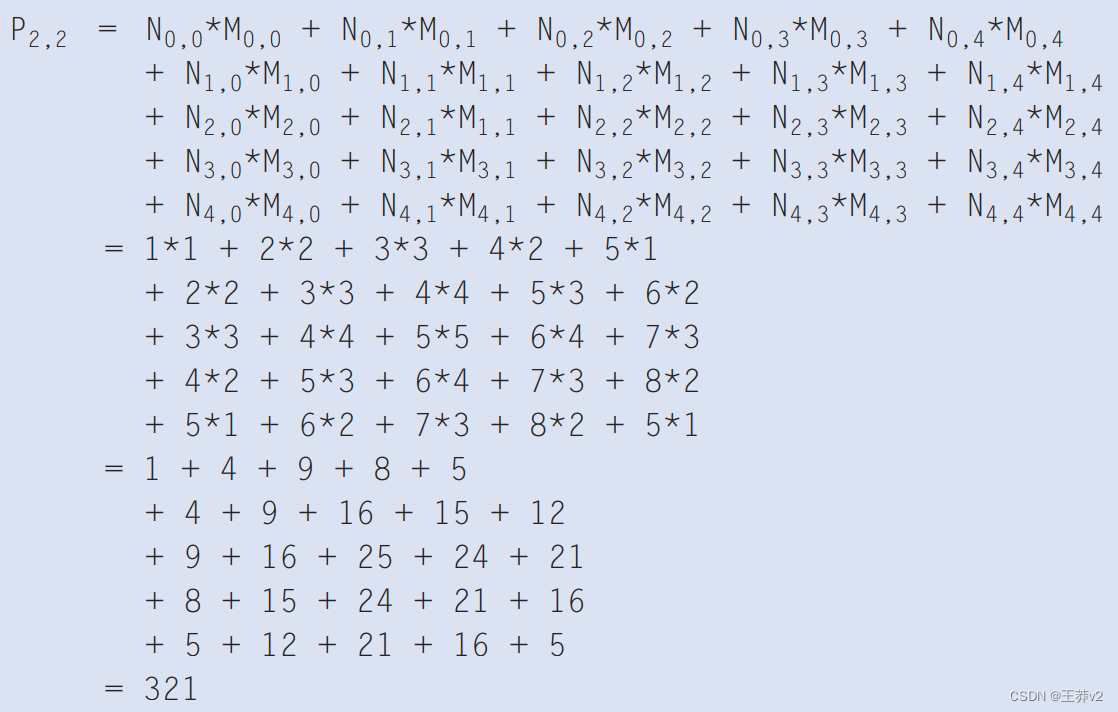
Parallel patterns: convolution —— An introduction to stencil computation
在接下来的几章中,我们将讨论一组重要的并行计算模式。这些模式是许多并行应用中出现的广泛并行算法的基础。我们将从卷积开始,这是一种流行的阵列操作,以各种形式用于信号处理、数字记录、图像处理、视频处理和计算机视觉。在这些应用领域,卷积通常作为过滤器执行,将信号和像素转换为更理想的值。我们的图像模糊内核是一个过滤器,可以平滑信号值,以便人们可以看到大画面的趋势。另一个例子是,高斯滤波器是卷积滤波器,可用
立体视觉算法步骤-Matching cost computation(匹配代价计算)
一提到视觉算法的步骤,不得不提《A Taxonomy and Evaluation of Dense Two-Frame Stereo Correspondence Algorithms》这篇文章。 因为目前大多数提到这个步骤,都是引用了这边文章,因为是这篇文章首次提出了立体视觉的四个步骤。而且《Stereo Vision:Algorithms and Applications》也是按照这四个步
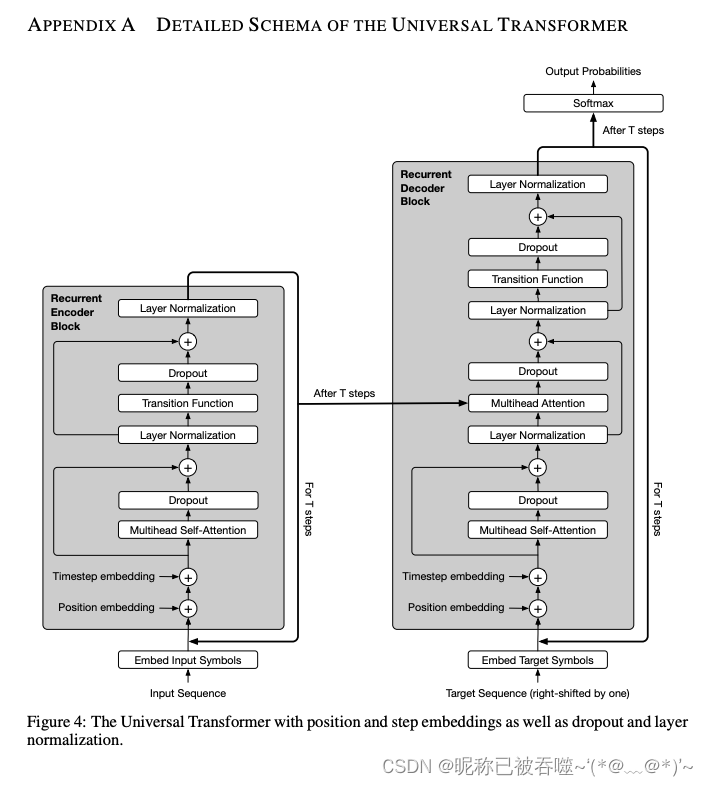
UniversalTransformer with Adaptive Computation Time(ACT)
原论文链接:https://arxiv.org/abs/1807.03819 Main code import torchimport numpy as npclass PositionTimestepEmbedding(torch.nn.Module):def forward(self, x, t):device = x.devicesequence_length = x.si

Discretized Streams: Fault-Tolerant Streaming Computation at Scale
Abstract Many “big data” applications must act on data in real time. Running these applications at ever-larger scales re- quires parallel platforms that automatically handle faults and stragglers. Un
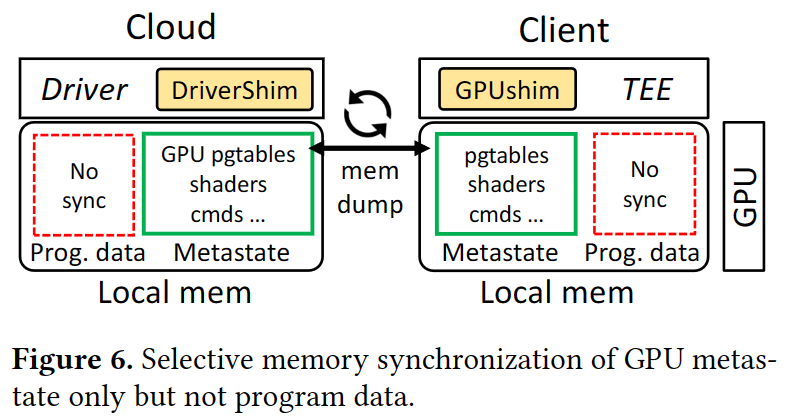
Safe and Practical GPU Computation in TrustZone论文阅读笔记
Safe and Practical GPU Computation in TrustZone 背景知识: youtube GR视频讲解链接:ASPLOS’22 - Session 2A - GPUReplay: A 50-KB GPU Stack for Client ML - YouTube GPU软件栈: 概念:"GPU软件栈"指的是与GPU硬件相关的全部软件组件,通常包括GPU驱动

Automatic Management of Data and Computation in Datacenters
最近在研究数据中心的数据管理和性能优化,看了一篇2010的论文Nectar:Automatic Management of Data and Computation in Datacenters,还是有一定的启发的,简要介绍给大家。详细的建议大家download论文下来看下。 Nectar核心思路有两个: 1、大部分数据计算存储之后是无效的,根据论文中研究统计结果,有50%的文件在过去的250天

单目标优化:蜣螂优化算法(Dung beetle optimizer,DBO)求解CEC2017(2017 IEEE Conference on Evolutionary Computation)
蜣螂优化算法(Dung beetle optimizer,DBO)由Jiankai Xue和Bo Shen于2022年提出,该算法主要受蜣螂的滚球、跳舞、觅食、偷窃和繁殖行为的启发所得。 一、蜣螂优化算法 1.1蜣螂滚球 (1)当蜣螂前行无障碍时,蜣螂在滚粪球过程中会利用太阳进行导航,下图中红色箭头表示滚动方向 本文假设光源的强度会影响蜣螂的位置,蜣螂在滚粪球过程中位置更新如下: x
pytorch报错:RuntimeError: one of the variables needed for gradient computation has been modified by an
修改网络时 pytroch报错: RuntimeError: one of the variables needed for gradient computation has been modified by an inplace operation: [torch.cuda.FloatTensor [1600, 16, 256]], which is output 0 of CudnnConv

空中计算(Over-the-Air Computation)学习笔记
文章目录 写在前面 写在前面 本文是论文A Survey on Over-the-Air Computation的阅读笔记: 通信和计算通常被视为独立的任务。 从工程的角度来看,这种方法是非常有效的,因为可以执行孤立的优化。 然而,对于许多面向计算的应用程序,主要关注的是设备上的本地信息的函数,而不是本地信息本身。 在这种情况下,信息论的结果表明,利用多址信道中的干扰进行