本文主要是介绍Piranha: A GPU Platform for Secure Computation,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
目录
- 概述
- 设备层
- 协议层
- 应用层
概述
Piranha是一款通用的模块化平台用于使用GPU加速基于密钥共享的MPC协议,它的结构如下图所示。
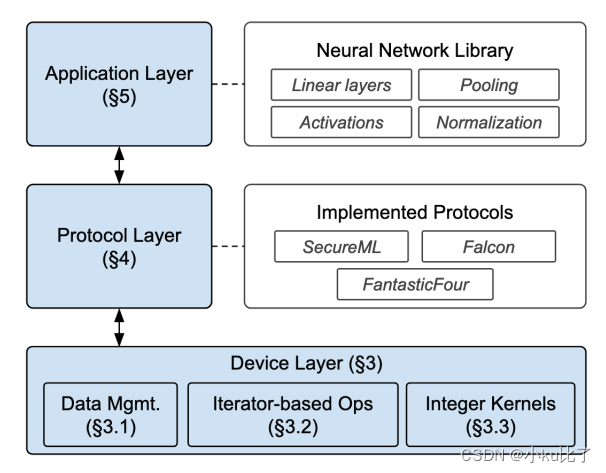
Piranha有三层结构:设备层,协议层,应用层。下文将对三层的功能做具体介绍。
设备层
设备层通过提供当前通用GPU库缺失的基于整数的内核可以进行独立的加速密钥共享协议。
设备层有三个模块分别是:数据管理(data managemnet),基于迭代器的操作以及整数内核。
数据管理
文章提出了一个:DeviceData buffer的概念。为什么要有DeviceData buffer?将数据存放在GPU上而不是CPU上可以避免GPU内核计算时的数据传输开销。
如何提高协议性能?对秘密共享值的集合进行逐元素操作是一种常见的操作。由于这些操作常常涉及大量的计算,因此将它们并行化加速,利用 GPU(图形处理单元)的性能,可以自然而然地提高协议性能。独立于特定协议,秘密共享数据上的MPC功能分解为一组通用的局部算术运算,这样就可以适配大部分的MPC协议。
基于迭代器的操作
由于GPU的空间有限,所以需要提高存储效率。Piranha的迭代器允许开发者通过程序定义的顺序遍历数据向量,同时在一个与实际物理数据布局无关的视图上执行操作。可以在原地进行逐元素操作,并将计算结果存储在现有内存中从而节省内存。
整数内核
MPC协议需要32位或64位类型的数据类型进行加密共享。目前研究仅仅针对于浮点数据类型,所以作者提出了自己的解决方法:直接在整数数据类型上面实现内核。Piranha直接在设备层提供了所有大小的整数矩阵乘法和卷积内核(CUTLASS)。
协议层
Piranha实现任何一个协议需要指定两件事:1.密钥共享基础(包括攻击模型)。2.在此之上的操作。
下图展示了一个简单的三方协商的实现。
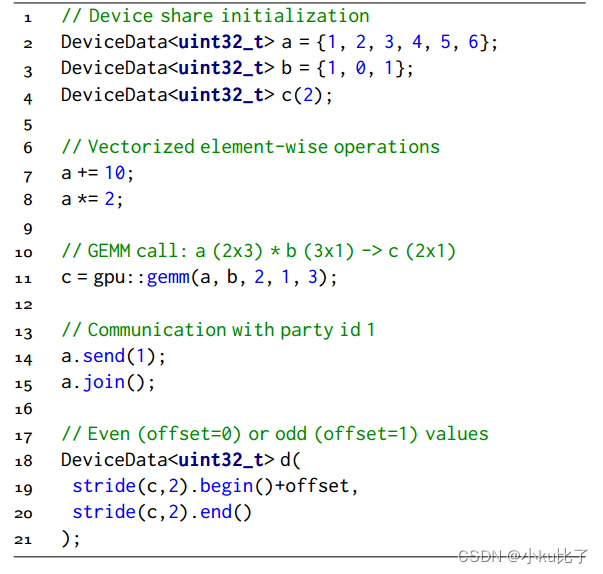
高效存储的开发
上文提到了高效存储的开发:普通的加法进位器需要分别存储共享密钥的每一位增加了内存占用。
其次使用连续的分配去隔离成对的位会导致额外的内存使用和数据复制。下图(a)展示了标准的加法进位器的内存使用情况。
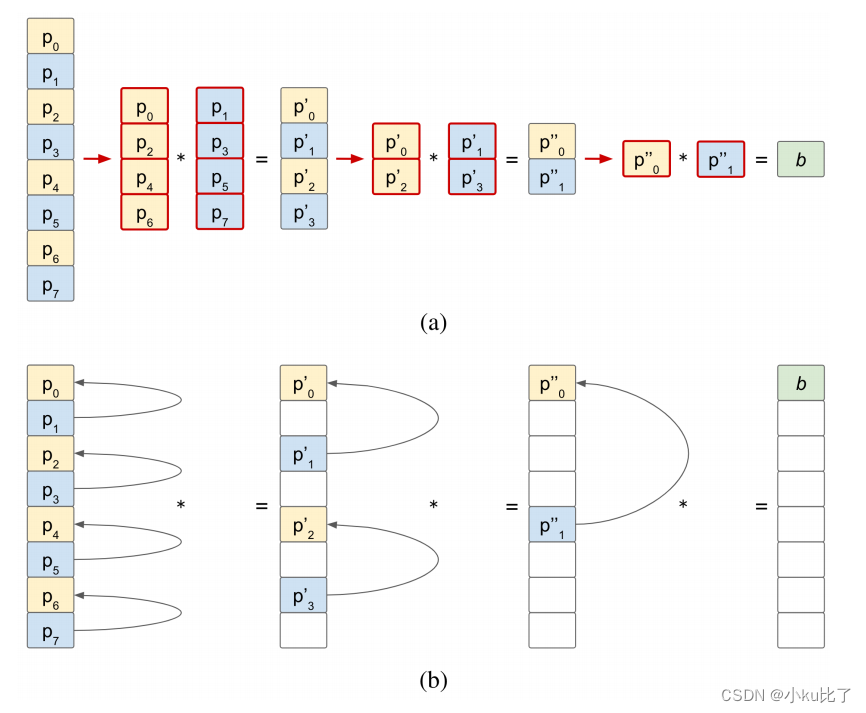
相反在(b)中Piranha使用了基于迭代器的视图按照一定的步幅访问非连续的数据元素,并将结果存储在相同位置,提高了内存的使用效率。
可重用协议组件
Piranha的结构支持重用协议实现,因此协议可以构建在其它应用上。作者实现了几种可重复使用的模型包括:安全比较, 近似计算等
MPC协议
文章实现了三个不同的MPC协议以便展示Piranha的通用性包括:P-SecureML,P-Falcon,P-FantasticFour。
应用层
应用层的目的主要是为了进行神经网络的相关训练,如下图所示为Piranha实现的协议无关版本的神经网络基础模块。

连接神经网络库 Piranha为了支持神经网络库在多MPC协议上,需要每个MPC协议实现在一个通用功能集上,这样便可以在支持层的帮助下进行训练和推理任何神经网络结构。
神经网络的安全训练
Piranha提出了新的梯度计算方法以便实现更加稳定的损失。
这篇关于Piranha: A GPU Platform for Secure Computation的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!









