cartpole专题
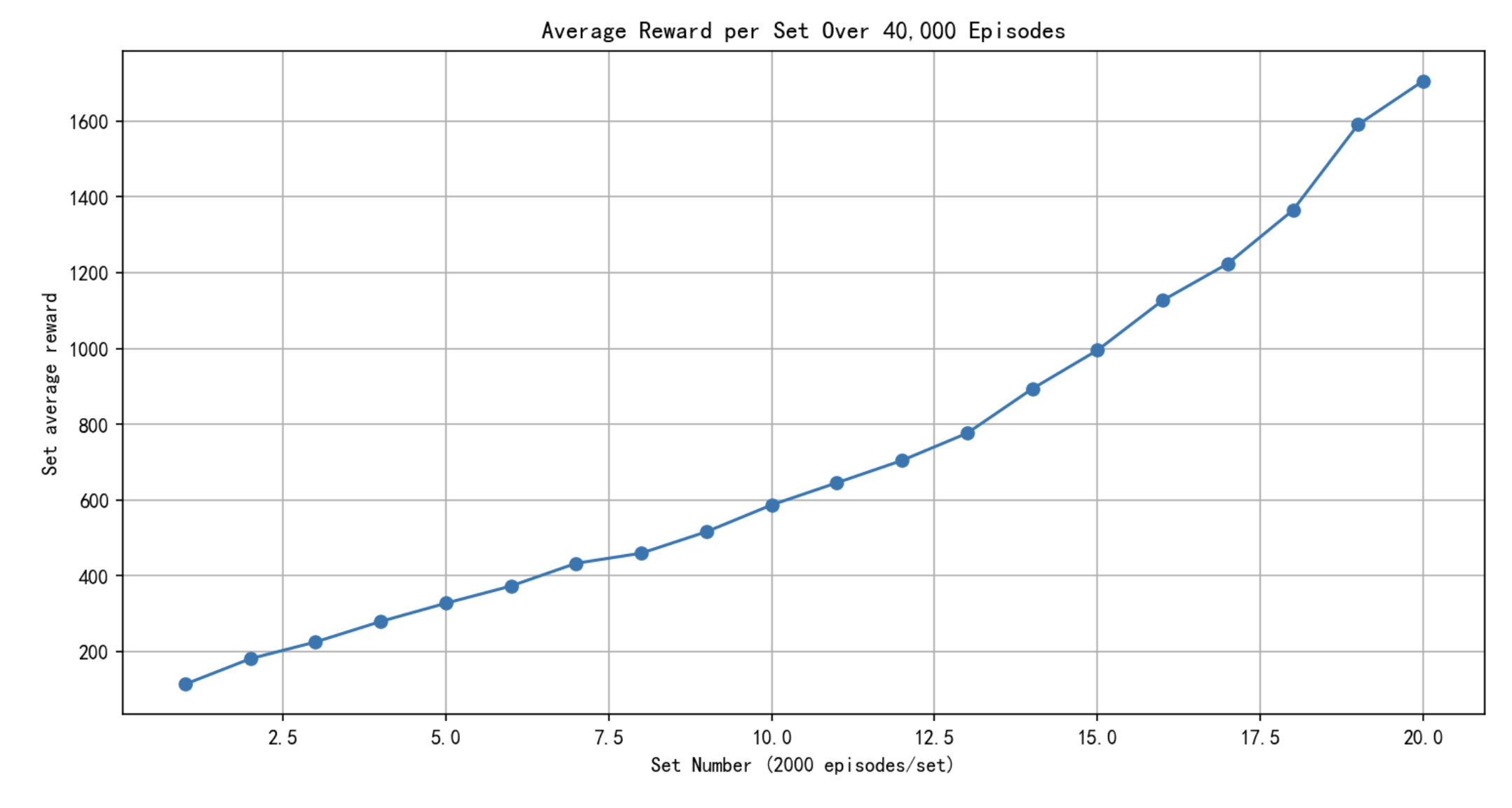
强化学习实例分析:CartPole【Monte Carlo】
强化学习笔记 主要基于b站西湖大学赵世钰老师的【强化学习的数学原理】课程,个人觉得赵老师的课件深入浅出,很适合入门. 第一章 强化学习基本概念 第二章 贝尔曼方程 第三章 贝尔曼最优方程 第四章 值迭代和策略迭代 第五章 强化学习实例分析:GridWorld 第六章 蒙特卡洛方法 第七章 Robbins-Monro算法 第八章 多臂老虎机 第九章 强化学习实例分析:CartPole

OpenAI Gym 关于CartPole的模拟退火解法
前言 今天测试OpenAI Gym,然后发现CartPole的最快实现快到离谱,使用Simulated Annealing,也就是SA模拟退火法。效果如下图: 代码地址:模拟退火解CartPole 于是好好研究了一下。 关于模拟退火法 一种最优控制算法,基本思想就是每次找一个邻近的点(解法),如果邻近的点比较优,就接受这个点,但是下一次使用随机有一定概率继续选择新的邻近的点,从而避免

PPO 跑CartPole-v1
gym-0.26.2 cartPole-v1 参考动手学强化学习书中的代码,并做了一些修改 代码 import gymimport torchimport torch.nn as nnimport torch.nn.functional as Fimport numpy as npimport matplotlib.pyplot as pltfrom tqdm import

Actor-Critic 跑 CartPole-v1
gym-0.26.1 CartPole-v1 Actor-Critic 这里采用 时序差分残差 ψ t = r t + γ V π θ ( s t + 1 ) − V π θ ( s t ) \psi_t = r_t + \gamma V_{\pi _ \theta} (s_{t+1}) - V_{\pi _ \theta}({s_t}) ψt=rt+γVπθ(st+1)−Vπθ
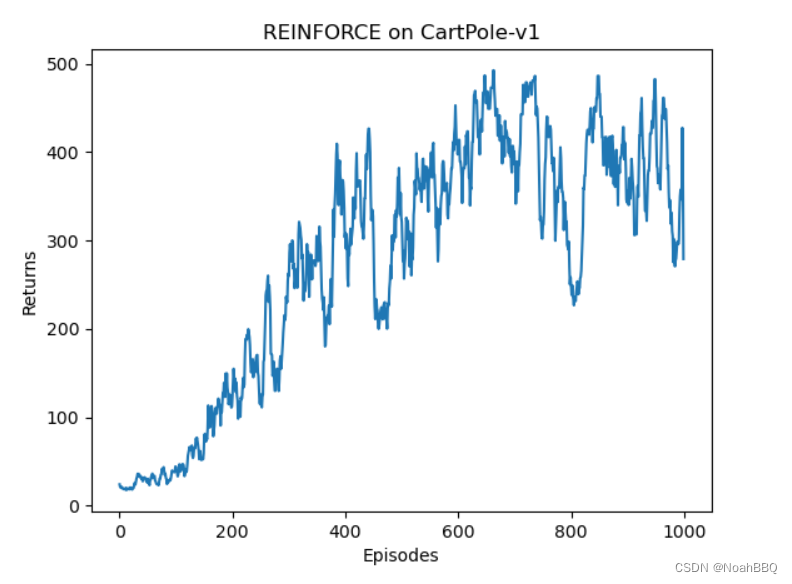
reinforce 跑 CartPole-v1
gym版本是0.26.1 CartPole-v1的详细信息,点链接里看就行了。 修改了下动手深度强化学习对应的代码。 然后这里 J ( θ ) J(\theta) J(θ)梯度上升更新的公式是用的不严谨的,这个和王树森书里讲的严谨公式有点区别。 代码 import gymimport torchfrom torch import nnfrom torch.nn import fu
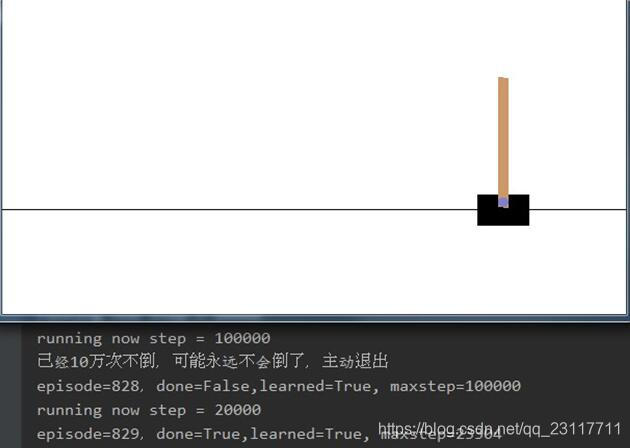
使用DDPG算法实现cartpole 100万次不倒
DDPG的全称是Deep Deterministic Policy Gradient,一种Actor Critic机器增强学习方法。 CartPole是http://gym.openai.com/envs/CartPole-v0/ 这个网站提供的一个杆子不倒的测试环境。 CartPole环境返回一个状态包括位置、加速度、杆子垂直夹角和角加速度。玩家控制左右两个方向使杆子不倒。杆子倒了或超出水平位置