本文主要是介绍reinforce 跑 CartPole-v1,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
gym版本是0.26.1
CartPole-v1的详细信息,点链接里看就行了。
修改了下动手深度强化学习对应的代码。
然后这里 J ( θ ) J(\theta) J(θ)梯度上升更新的公式是用的不严谨的,这个和王树森书里讲的严谨公式有点区别。
代码
import gym
import torch
from torch import nn
from torch.nn import functional as F
import numpy as np
import matplotlib.pyplot as plt
from tqdm import tqdm
import rl_utils # 这个要下载源码,然后放到同个文件目录下,链接在上面给出了
from d2l import torch as d2l # 这个是动手深度学习的库, pip/conda install d2l 就好了class PolicyNet(nn.Module):def __init__(self, state_dim, hidden_dim, action_dim):super().__init__()self.fc1 = nn.Linear(state_dim, hidden_dim)self.fc2 = nn.Linear(hidden_dim, action_dim)def forward(self, X):X = F.relu(self.fc1(X))return F.softmax(self.fc2(X),dim=1)class REINFORCE:def __init__(self, state_dim, hidden_dim, action_dim, learning_rate, gamma, device):self.policy_net = PolicyNet(state_dim, hidden_dim, action_dim).to(device)self.optimizer = torch.optim.Adam(self.policy_net.parameters(), lr = learning_rate)self.gamma = gamma # 折扣因子self.device = devicedef take_action(self, state): # 根据动作概率分布随机采样state = torch.tensor(np.array([state]),dtype=torch.float).to(self.device)probs = self.policy_net(state)action_dist = torch.distributions.Categorical(probs)action = action_dist.sample()return action.item()def update(self, transition_dict): # 公式用的是简化推导reward_list = transition_dict['rewards']state_list = transition_dict['states']action_list = transition_dict['actions']G = 0self.optimizer.zero_grad()for i in reversed(range(len(reward_list))): # 从最后一步算起reward = reward_list[i]state = torch.tensor(np.array([state_list[i]]), dtype=torch.float).to(self.device)action = torch.tensor([action_list[i]]).reshape(-1,1).to(self.device)log_prob = torch.log(self.policy_net(state).gather(1, action))G = self.gamma * G + reward loss = -log_prob * G # 因为梯度更新是减的,所以取个负号loss.backward()self.optimizer.step()lr = 1e-3
num_episodes = 1000
hidden_dim = 128
gamma = 0.98
device = d2l.try_gpu()env_name="CartPole-v1"
env = gym.make(env_name)
print(f"_max_episode_steps:{env._max_episode_steps}")
torch.manual_seed(0)
state_dim = env.observation_space.shape[0]
action_dim = env.action_space.nagent = REINFORCE(state_dim, hidden_dim, action_dim, lr, gamma, device)
return_list = []
for i in range(10):with tqdm(total=int(num_episodes/10), desc=f'Iteration {i}') as pbar:for i_episode in range(int(num_episodes/10)):episode_return = 0transition_dict = {'states': [], 'actions': [], 'next_states': [], 'rewards': [], 'dones': []}state = env.reset()[0]done, truncated= False, Falsewhile not done and not truncated : # 主要是这部分和原始的有点不同action = agent.take_action(state)next_state, reward, done, truncated, info = env.step(action)transition_dict['states'].append(state)transition_dict['actions'].append(action)transition_dict['next_states'].append(next_state)transition_dict['rewards'].append(reward)transition_dict['dones'].append(done)state = next_stateepisode_return += rewardreturn_list.append(episode_return)agent.update(transition_dict)if (i_episode+1) % 10 == 0:pbar.set_postfix({'episode': '%d' % (num_episodes / 10 * i + i_episode+1), 'return': '%.3f' % np.mean(return_list[-10:])})pbar.update(1)episodes_list = list(range(len(return_list)))
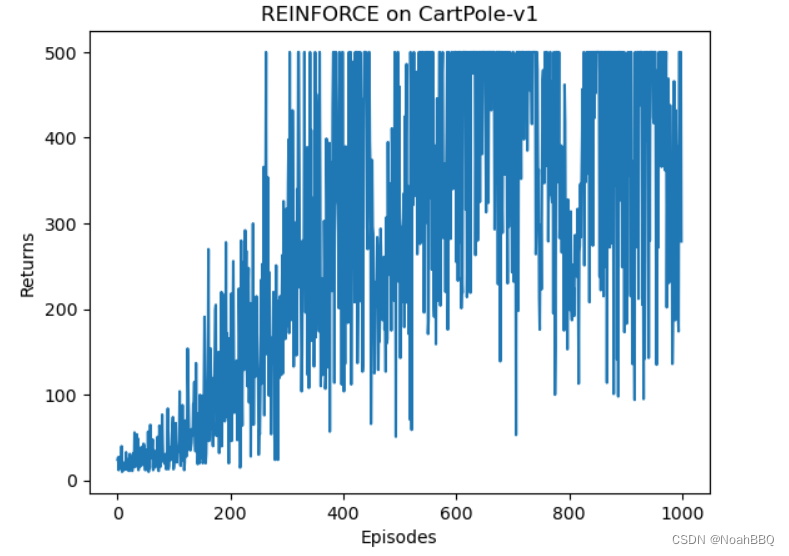
plt.plot(episodes_list, return_list)
plt.xlabel('Episodes')
plt.ylabel('Returns')
plt.title(f'REINFORCE on {env_name}')
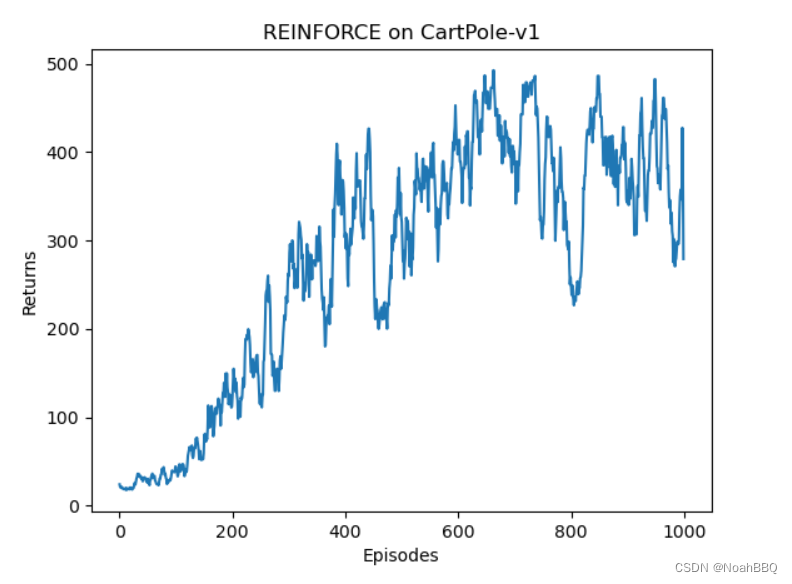
plt.show()mv_return = rl_utils.moving_average(return_list, 9)
plt.plot(episodes_list, mv_return)
plt.xlabel('Episodes')
plt.ylabel('Returns')
plt.title(f'REINFORCE on {env_name}')
plt.show()
我是在jupyter里直接跑的,结果如下所示。

这篇关于reinforce 跑 CartPole-v1的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!