bm25专题

句子相似 BM25 python 实现
# -*- coding: utf-8 -*-import mathclass BM25(object):def __init__(self, docs):""":param docs: 分好词的list"""self.D = len(docs)self.avgdl = sum([len(doc)+0.0 for doc in docs]) / self.Dself.docs =

搜索相似之——BM25算法
1. BM25算法 BM25是二元独立模型的扩展,其得分函数有很多形式,最普通的形式如下: ∑ 其中,k1,k2,K均为经验设置的参数,fi是词项在文档中的频率,qfi是词项在查询中的频率。 K1通常为1.2,通常为0-1000 K的形式较为复杂 K=
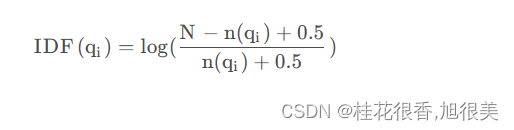
BM25检索算法 python
1.简介 BM25(Best Matching 25)是一种经典的信息检索算法,是基于 TF-IDF算法的改进版本,旨在解决、TF-IDF算法的一些不足之处。其被广泛应用于信息检索领域的排名函数,用于估计文档D与用户查询Q之间的相关性。它是一种基于概率检索框架的改进,特别是在处理长文档和短查询时表现出色。BM25的核心思想是基于词频(TF)和逆文档频率(IDF)来,同时还引入了文档的长度信息来计

Elasticsearch:BM25 及 使用 Elasticsearch 和 LangChain 的自查询检索器
本工作簿演示了 Elasticsearch 的自查询检索器将非结构化查询转换为结构化查询的示例,我们将其用于 BM25 示例。 在这个例子中: 我们将摄取 LangChain 之外的电影样本数据集自定义 ElasticsearchStore 中的检索策略以仅使用 BM25使用自查询检索将问题转换为结构化查询使用文档和 RAG 策略来回答问题 安装 如果你还没有安装好自己的 Elas
![]搜索引擎的文档相关性计算和检索模型(BM25/TF-IDF)](http://upload.wikimedia.org/wikipedia/zh/math/b/0/6/b06a060c28253c8dd2528811c447862e.png)
]搜索引擎的文档相关性计算和检索模型(BM25/TF-IDF)
搜索引擎的检索模型-查询与文档的相关度计算 1. 检索模型概述 搜索结果排序时搜索引擎最核心的部分,很大程度度上决定了搜索引擎的质量好坏及用户满意度。实际搜索结果排序的因子有很多,但最主要的两个因素是用户查询和网页内容的相关度,以及网页链接情况。这里我们主要总结网页内容和用户查询相关的内容。 判断网页内容是否与用户査询相关,这依赖于搜索引擎所来用的检索模型。检

BM25(Best Matching 25)算法基本思想
BM25(Best Matching 25)是一种用于信息检索(Information Retrieval)和文本挖掘的算法,它被广泛应用于搜索引擎和相关领域。BM25 基于 TF-IDF(Term Frequency-Inverse Document Frequency)的思想,但对其进行了改进以考虑文档的长度等因素。 一.基本思想 以下是 BM25 算法的基本思想: TF-IDF
ElasticSearch IDF BM25 函数图像
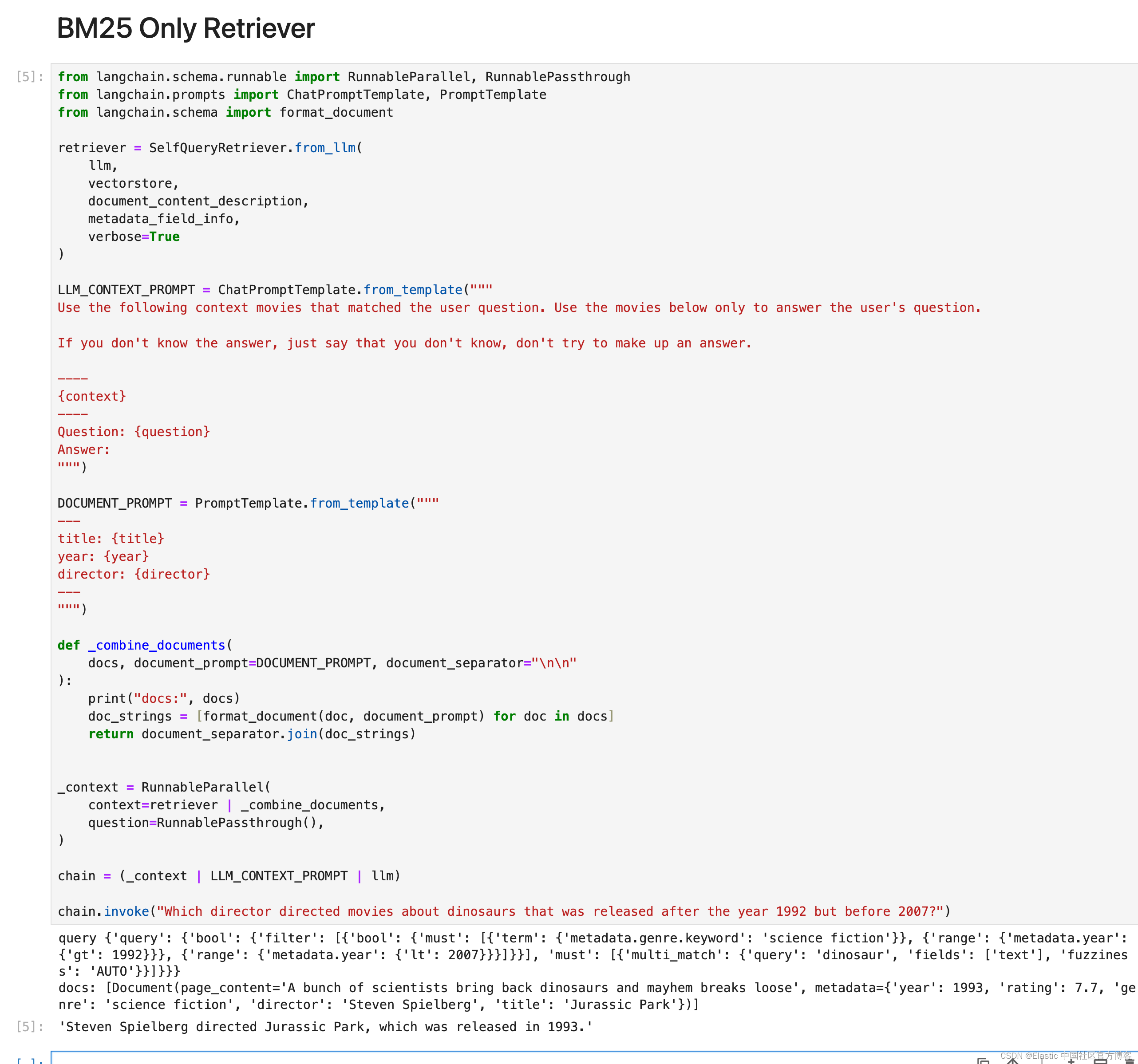
elasticSearch IDF BM25 函数图像 什么是IDF?IDF函数图像什么是BM25BM25函数图像 什么是IDF? 逆向文件频率(inverse document frequency,IDF)是一个词语普遍重要性的度量。某一特定词语的IDF,可以由总文件数目除以包含该词语之文件的数目,再将得到的商取以10为底的对数得到 IDF函数图像 es 的idf公式
Elasticsearch:相关性工作台 - BM25 及 ELSER 的相关性比较
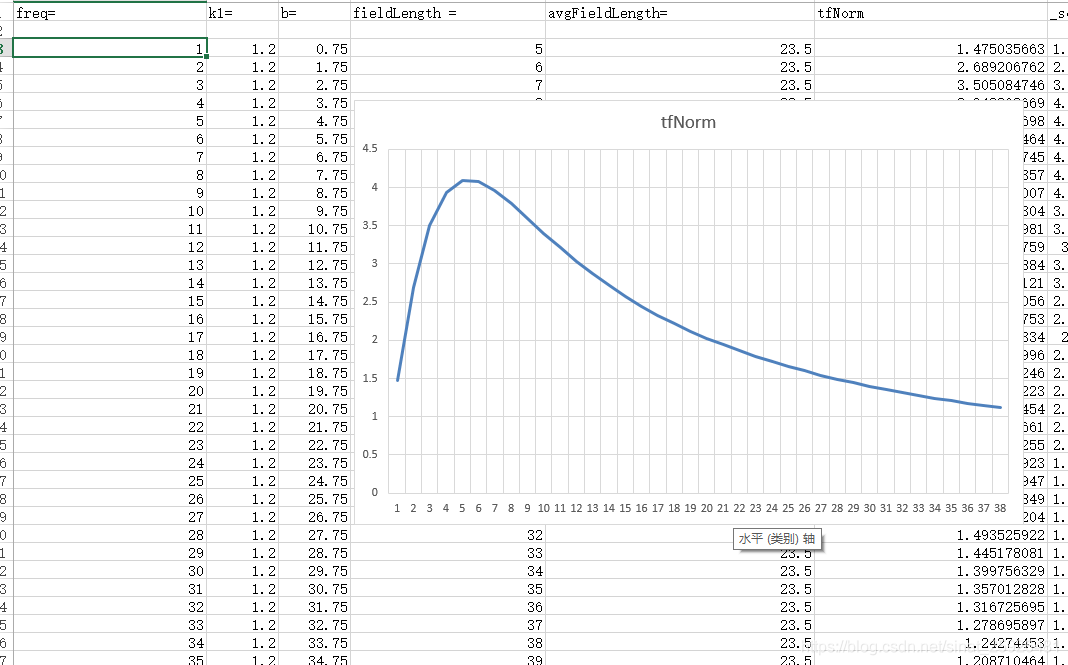
我们知道 Elastics Learned Sparse EncoderR (ELSER) 可以被用来做语义搜索。它是一个 out-of-domain 的语义搜索模型。无需训练,我们就可以得到很好的相关性。有关 ELSER 的更多知识,请参考文章 “Elastic Learned Sparse Encoder 简介:Elastic 用于语义搜索的 AI 模型”。在传统的 BM25 搜索中,我们可以
Elasticsearch:相关性工作台 - BM25 及 ELSER 的相关性比较
我们知道 Elastics Learned Sparse EncoderR (ELSER) 可以被用来做语义搜索。它是一个 out-of-domain 的语义搜索模型。无需训练,我们就可以得到很好的相关性。有关 ELSER 的更多知识,请参考文章 “Elastic Learned Sparse Encoder 简介:Elastic 用于语义搜索的 AI 模型”。在传统的 BM25 搜索中,我们可以
![集成多元算法,打造高效字面文本相似度计算与匹配搜索解决方案,助力文本匹配冷启动[BM25、词向量、SimHash、Tfidf、SequenceMatcher]](https://img-blog.csdnimg.cn/d553c7dadca54bdb82a3a234befb74d8.png#pic_center)
集成多元算法,打造高效字面文本相似度计算与匹配搜索解决方案,助力文本匹配冷启动[BM25、词向量、SimHash、Tfidf、SequenceMatcher]
搜索推荐系统专栏简介:搜索推荐全流程讲解(召回粗排精排重排混排)、系统架构、常见问题、算法项目实战总结、技术细节以及项目实战(含码源) 专栏详细介绍:搜索推荐系统专栏简介:搜索推荐全流程讲解(召回粗排精排重排混排)、系统架构、常见问题、算法项目实战总结、技术细节以及项目实战(含码源) 前人栽树后人乘凉,本专栏提供资料: 推荐系统算法库,包含推荐系统经典及最新算法讲解,以及涉及后续业务落地
NLP之BM25:BM25算法的简介、相关库、案例应用之详细攻略
NLP之BM25:BM25算法的简介、相关库、案例应用之详细攻略 目录 相关文章 NLP之BM25:BM25算法的简介、相关库、案例应用之详细攻略 Py之rank_bm25:rank_bm25的简介、安装、使用方法 BM25算法的简介

NLP之BM25:BM25算法的简介、相关库、案例应用之详细攻略
NLP之BM25:BM25算法的简介、相关库、案例应用之详细攻略 目录 相关文章 NLP之BM25:BM25算法的简介、相关库、案例应用之详细攻略 Py之rank_bm25:rank_bm25的简介、安装、使用方法 BM25算法的简介
专转本校园资讯网站(BM25相似性匹配算法)
专升本是提升自己专科学历到达本科阶段的一个方法和手段,考试成功之后就读两年就是本科的学历了,对于大多数的学生来说还是很有必要和帮助的。对于有决心考上专升本的学生以及愿意在这期间努力付出的学生而言,成功考上专升本以后就读两年是非常有必要也是非常值得的。一方面是因为专升本以后的学历是本科学历,相比之前的专科学历,本科学历无论是在就业找工作过程中,还是在工作中的升职加薪,甚至是职称的评定