本文主要是介绍专转本校园资讯网站(BM25相似性匹配算法),希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
专升本是提升自己专科学历到达本科阶段的一个方法和手段,考试成功之后就读两年就是本科的学历了,对于大多数的学生来说还是很有必要和帮助的。对于有决心考上专升本的学生以及愿意在这期间努力付出的学生而言,成功考上专升本以后就读两年是非常有必要也是非常值得的。一方面是因为专升本以后的学历是本科学历,相比之前的专科学历,本科学历无论是在就业找工作过程中,还是在工作中的升职加薪,甚至是职称的评定过程中都是有辅助作用的。另一方面,专升本就读的两年以及毕业以后接触到的人物和事物,你会发现和你专科阶段所处的环境有很大的不同,专升本不仅是对自己学历的提升,也是对自己能力在一定程度的提高。
一、设计理念
- 设计原因
专转本考试将要来临,作为一个参加专转本考试的考生,我深知其中的压力,因此这里选泽“我在城院准备专转本的主题”来进行网站的设计与开发,通过改网站来展示一些我对专转本的看法。 - 设计理念
本网站主要是针对于专转本考试的相关内容来进行制作的。通过该网站来对参加专转本考试的学生进行相应的参考,同时也有一定的激励作用,希望参加专转本考试的考生都能够考上自己理想的大学。
二、功能模块
功能模块说明:
1、本网站是通过前端网页模板与Flask前端Web框架进行联合开发。
2、网站主要分为9个网页,每个网页的背景、header和footer都是相同的。
3、网站主要分为六个板块,分别是首页、我的城院、转本资讯、砥砺前行、转本答疑和联系我们。
4、网站整体搭建流程分为三个部分:数据的获取与存储、服务器的搭建和页面的渲染。
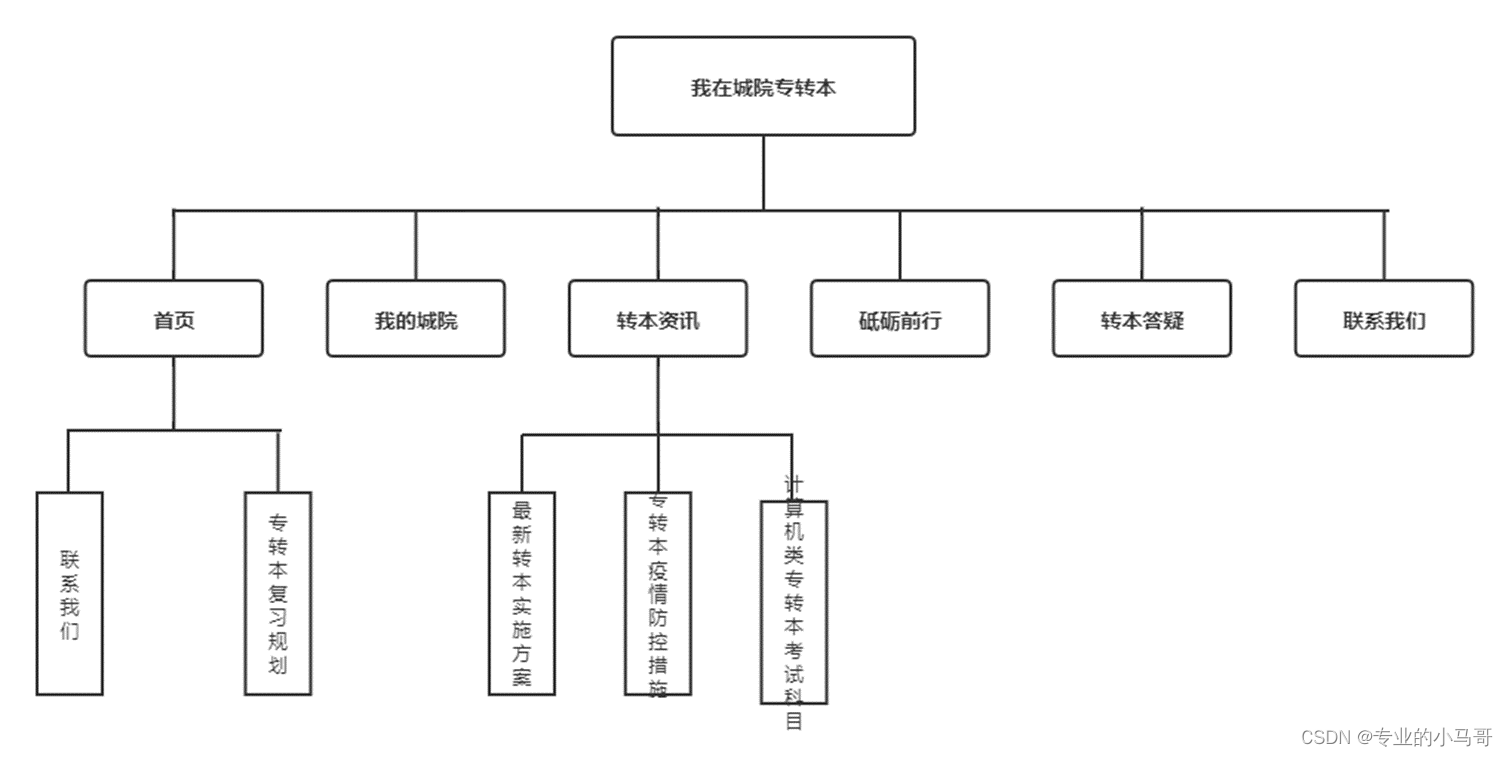
功能流程说明:

二、项目特点
- 实时数据及动态变换
- 网站中所涉及到的名人名言以及激励美句都是通过爬虫技术爬取相应网站来获得的数据并将爬取的数据存储到数据库中,保证了数据的实时性。
- 网站中使用了随机处理策略,保证了网页在显示数据时的多样性,每次刷新网页所呈现的内容都是不相同的。
- 在线提问和申请加入
- 本网站采用在线提问的方式,用户可以在线提问,用户提出问题后,系统会根据用户提问的内容去数据库中匹配最相似的问题并呈现出问题所对应的回答,在问题匹配过程中我采用了传统的BM25算法来计算文本相似度。
- 访问者可通过输入相关个人信息加入我们,我们会将浏览者的信息会存储至数据库中。
三、代码展示
-
爬虫代码
import requests from lxml import html import pymysql import re class CrawlTask(object):def __init__(self):self.url_temp = "https://www.diyifanwen.com/tool/mrmydq/{}.html"self.headers = {"Host": "www.diyifanwen.com","Cookie": "SetCookieTF=1; testcookie=yes; DYFWUID=16194263885649fmldrc6ia0w4ia; Hm_lvt_3a5e11b41af918022c823a8041a34e78=1638774720; Hm_lpvt_3a5e11b41af918022c823a8041a34e78=1638775048","User-Agent": "Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/96.0.4664.45 Safari/537.36"}def get_url_list(self):pages = ["651259","651327","650197","651325","651264","651267"]return [self.url_temp.format(i) for i in pages]def parse(self,url):rest = requests.get(url,headers=self.headers)rest.encoding = rest.apparent_encodingreturn rest.textdef get_content(self,rest):html_rest = html.etree.HTML(rest)p_list = html_rest.xpath("//div[@id='ArtContent']/p[position()<=100]")item_list = []for p in p_list:item = {}content = p.xpath("./text()")[0] if len(p.xpath("./text()"))>0 else Noneif content and len(content)<50 and len(re.findall("――",content))>0 and not len(re.findall("佚名",content))>0:author = re.findall(r"――(.*)",content)[0]content = re.findall("、(.*。).*――",content)if len(author)>0 and len(content)>0:item["author"] = authoritem["content"] = content[0]print(item)item_list.append(item)return item_listdef save(self,content_list):data = [[i["author"],i["content"]] for i in content_list]conn = pymysql.connect(host='localhost',port=3306,user='root',password='123456',database='my_college',charset='utf8')with conn.cursor() as cursor:try:sql = "insert into db_saying(author,content) values(%s,%s)"cursor.executemany(sql,data)conn.commit()except Exception as e:conn.rollback()print(e)finally:conn.close()def run(self):url_list = self.get_url_list()for url in url_list:rest = self.parse(url)content_list = self.get_content(rest)self.save(content_list)if __name__ == '__main__':ct = CrawlTask()ct.run() -
相似度匹配代码
import numpy as np from collections import Counter import jiebaclass BM25_Model(object):def __init__(self, documents_list, k1=2, k2=1, b=0.5):self.documents_list = documents_listself.documents_number = len(documents_list)self.avg_documents_len = sum([len(document) for document in documents_list]) / self.documents_numberself.f = []self.idf = {}self.k1 = k1self.k2 = k2self.b = bself.init()def init(self):df = {}for document in self.documents_list:temp = {}for word in document:temp[word] = temp.get(word, 0) + 1self.f.append(temp)for key in temp.keys():df[key] = df.get(key, 0) + 1for key, value in df.items():self.idf[key] = np.log((self.documents_number - value + 0.5) / (value + 0.5))def get_score(self, index, query):score = 0.0document_len = len(self.f[index])qf = Counter(query)for q in query:if q not in self.f[index]:continuescore += self.idf[q] * (self.f[index][q] * (self.k1 + 1) / (self.f[index][q] + self.k1 * (1 - self.b + self.b * document_len / self.avg_documents_len))) * (qf[q] * (self.k2 + 1) / (qf[q] + self.k2))return scoredef get_documents_score(self, query):score_list = []for i in range(self.documents_number):score_list.append(self.get_score(i, query))return score_listif __name__ == '__main__':# document_list = ["行政机关强行解除行政协议造成损失,如何索取赔偿?",# "借钱给朋友到期不还得什么时候可以起诉?怎么起诉?",# "我在微信上被骗了,请问被骗多少钱才可以立案?",# "公民对于选举委员会对选民的资格申诉的处理决定不服,能不能去法院起诉吗?",# "有人走私两万元,怎么处置他?",# "法律上餐具、饮具集中消毒服务单位的责任是不是对消毒餐具、饮具进行检验?"]# document_list_split = [list(jieba.cut(doc)) for doc in document_list]# bm25_model = BM25_Model(document_list)# query = "走私了两万元,在法律上应该怎么量刑?"# query = list(jieba.cut(query))# scores = bm25_model.get_documents_score(query)# print(document_list[scores.index(max(scores))])test = [["a","b"],["c","d"]]test.remove(["c","d"])print(test) -
视图函数代码
import jieba
from flask import request,jsonify,session,redirect,render_template
from . import api
from my_college.models import db,Saying,Questions,User,Sentence,Answer_Questions
import json
from my_college.utils.common import BM25_Model
import random
# 首页
@api.route('/init_index')
def init_index():return render_template('index.html')# 我的城院页面
@api.route('/about')
def about():return render_template('about.html')# 转本资讯视图函数
@api.route('/activities')
def activities():return render_template('activities.html')# 转本资讯视图函数
@api.route('/application')
def application():return render_template('application.html')# 砥砺前行视图函数
@api.route('/blog')
def blog():sentence_list = [i.sentence for i in Sentence.query.all()]sentence_number = []while True:if len(set(sentence_number))==8:breaksentence_number.append(random.randint(0, len(sentence_list) - 1))random_sentence_list = [sentence_list[i] for i in set(sentence_number)]saying_list = [[i.author, i.content] for i in Saying.query.all()]saying_number = []while True:if len(set(saying_number))==4:breaksaying_number.append(random.randint(0, len(saying_list) - 1))random_saying_list = [saying_list[i] for i in set(saying_number)]return render_template('blog.html',saying_list=random_saying_list,sentence_list=random_sentence_list)# 转本资讯视图函数
@api.route('/competition')
def competition():return render_template('competition.html')# 联系我们视图函数
@api.route('/contact')
def contact():return render_template('contact.html')# 查看详情视图函数
@api.route('/events')
def events():return render_template('events.html')# 转本资讯视图函数
@api.route('/programs')
def programs():return render_template('programs.html')# 转本答疑视图函数
@api.route('/staff')
def staff():question_answer_list = [[i.question, i.answer] for i in Answer_Questions.query.all()]try:q_content = session["question"]sign = Truequestion_list = [i[0] for i in question_answer_list]question_list_split = [list(jieba.cut(doc)) for doc in question_list]bm25_model = BM25_Model(question_list_split)query = list(jieba.cut(q_content))scores = bm25_model.get_documents_score(query)find_question = question_list[scores.index(max(scores))]find_answer = ""remove_item = []for i in question_answer_list:if i[0] == find_question:find_answer = i[1]remove_item = i# 随机获取提问问题和解答# 将匹配到的问题从列表中移出question_answer_list.remove(remove_item)question_answer_number = []while True:if len(set(question_answer_number)) == 5:breakquestion_answer_number.append(random.randint(0, len(question_answer_list) - 1))random_question_answer_list = [question_answer_list[i] for i in set(question_answer_number)]print("访问者提出问题")print(q_content)print("匹配到的问题")print(find_question)print("问题所对应的回答")print(find_answer)return render_template("staff.html", question=find_question, answer=find_answer,question_answer_list=random_question_answer_list, sign=sign)except:q_content = Nonesign = Falsequestion_answer_number = []while True:if len(set(question_answer_number)) == 5:breakquestion_answer_number.append(random.randint(0, len(question_answer_list) - 1))random_question_answer_list = [question_answer_list[i] for i in set(question_answer_number)]print(random_question_answer_list)return render_template("staff.html",question_answer_list=random_question_answer_list, sign=sign)# 问题资讯视图函数
@api.route('/questions')
def questions():q_content = request.args.get("q_content")# question = Questions(question=q_content)# 将提问的问题存储到session中session["question"] = q_contenttry:# 将提问问题插入到数据库中# db.session.add(question)# db.session.commit()return jsonify(errno="200")except Exception as e:return jsonify(errno="500")# 联系我们视图函数
@api.route('/user')
def user():name = request.args.get("name")email = request.args.get("email")subject = request.args.get("subject")message = request.args.get("message")user = User(name=name,email=email,major_class=subject,reason=message)try:db.session.add(user)db.session.commit()return jsonify(errno="200")except Exception as e:return jsonify(errno="500")四、页面展示
页面展示说明:
1、每个页面的头部和尾部是相同的
- 头部和尾部


- 首页页面


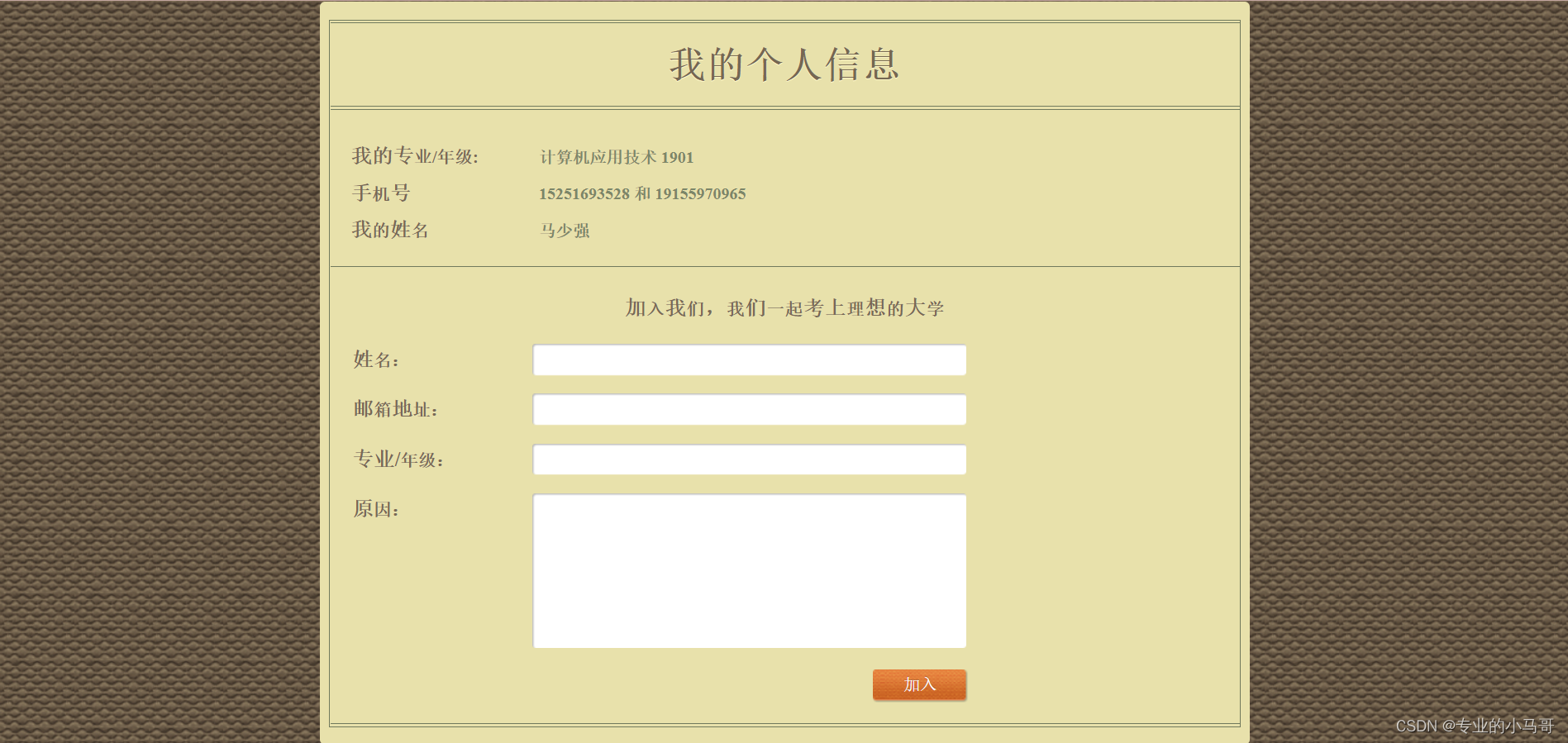
- 我的城院页面


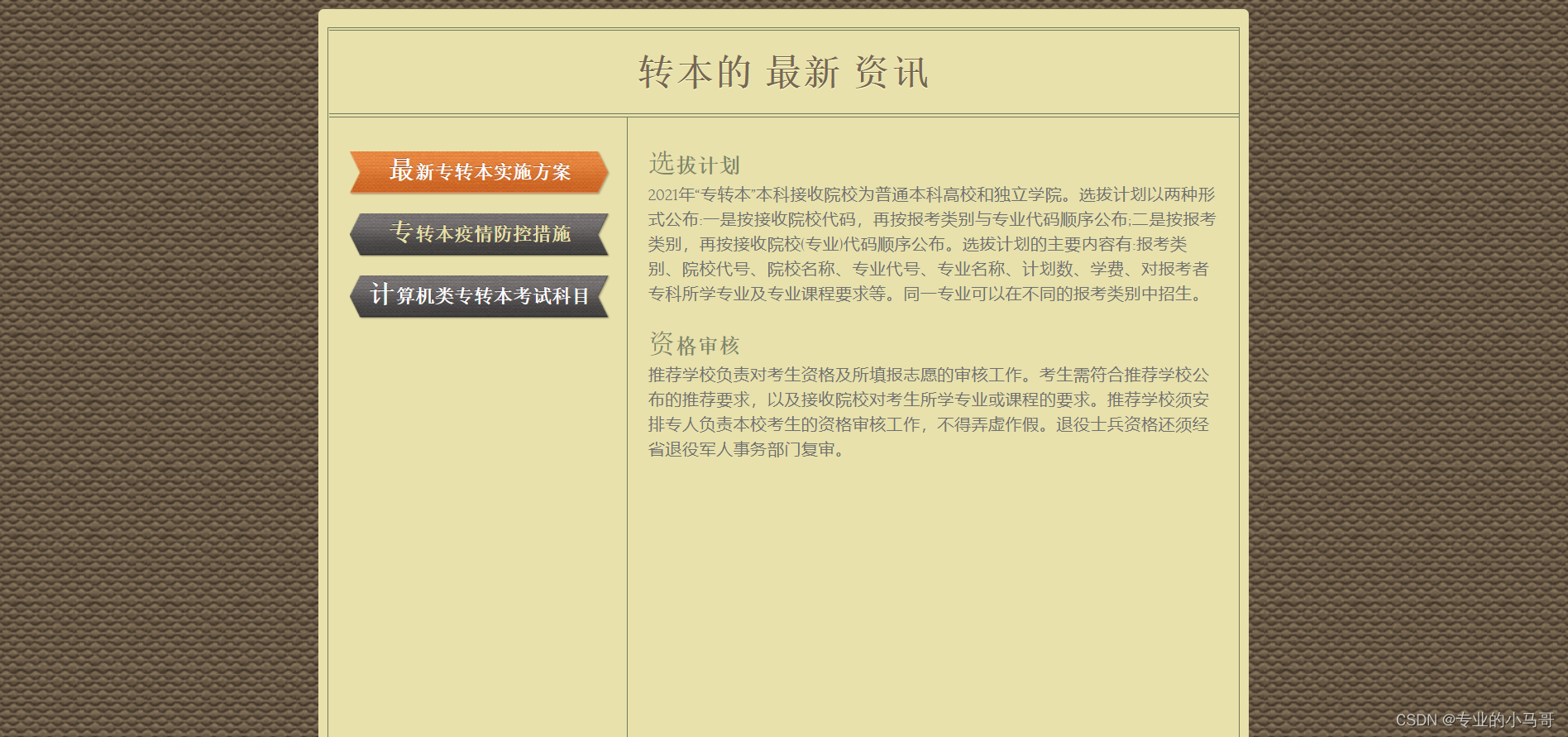
- 转本资讯页面


- 砥砺前行页面


- 转本答疑页面

- 联系我们页面
以上是本项目的核心内容,静态页面没有展示,希望能够帮助你们,如需源代码,私信博主
这篇关于专转本校园资讯网站(BM25相似性匹配算法)的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!








