本文主要是介绍Elasticsearch:BM25 及 使用 Elasticsearch 和 LangChain 的自查询检索器,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
本工作簿演示了 Elasticsearch 的自查询检索器将非结构化查询转换为结构化查询的示例,我们将其用于 BM25 示例。
在这个例子中:
- 我们将摄取 LangChain 之外的电影样本数据集
- 自定义 ElasticsearchStore 中的检索策略以仅使用 BM25
- 使用自查询检索将问题转换为结构化查询
- 使用文档和 RAG 策略来回答问题

安装
如果你还没有安装好自己的 Elasticsearch 及 Kibana,请参考文章:
安装 Elasticsearch 及 Kibana
如果你还没有安装好自己的 Elasticsearch 及 Kibana,那么请参考一下的文章来进行安装:
-
如何在 Linux,MacOS 及 Windows 上进行安装 Elasticsearch
-
Kibana:如何在 Linux,MacOS 及 Windows 上安装 Elastic 栈中的 Kibana
在安装的时候,请选择 Elastic Stack 8.x 进行安装。在安装的时候,我们可以看到如下的安装信息:

Python 安装包
我们需要安装 Python 版本 3.6 及以上版本。我们还需要安装如下的 Python 安装包:
pip3 install lark elasticsearch langchain openai load_dotenv$ pip3 list | grep elasticsearch
elasticsearch 8.12.0
rag-elasticsearch 0.0.1 /Users/liuxg/python/rag-elasticsearch/my-app/packages/rag-elasticsearch环境变量
在启动 Jupyter 之前,我们设置如下的环境变量:
export ES_USER="elastic"
export ES_PASSWORD="xnLj56lTrH98Lf_6n76y"
export ES_ENDPOINT="localhost"
export OPENAI_API_KEY="YOUR_OPEN_AI_KEY"请在上面修改相应的变量的值。特别是你需要输入自己的 OPENAI_API_KEY。
拷贝 Elasticsearch 证书
我们把 Elasticsearch 的证书拷贝到当前的目录下:
$ pwd
/Users/liuxg/python/elser
$ cp ~/elastic/elasticsearch-8.12.0/config/certs/http_ca.crt .
$ ls http_ca.crt
http_ca.crt创建应用
我们在当前的目录下运行 jupyter notebook:
jupyter notebook连接到 Elasticsearch
from elasticsearch import Elasticsearch
from dotenv import load_dotenv
import os
from elasticsearch import Elasticsearchload_dotenv()openai_api_key=os.getenv('OPENAI_API_KEY')
elastic_user=os.getenv('ES_USER')
elastic_password=os.getenv('ES_PASSWORD')
elastic_endpoint=os.getenv("ES_ENDPOINT")url = f"https://{elastic_user}:{elastic_password}@{elastic_endpoint}:9200"
client = Elasticsearch(url, ca_certs = "./http_ca.crt", verify_certs = True)print(client.info())
准备示例数据集
docs = [{"text": "A bunch of scientists bring back dinosaurs and mayhem breaks loose","metadata": {"year": 1993, "rating": 7.7, "genre": "science fiction", "director": "Steven Spielberg", "title": "Jurassic Park"},},{"text": "Leo DiCaprio gets lost in a dream within a dream within a dream within a ...","metadata": {"year": 2010, "director": "Christopher Nolan", "rating": 8.2, "title": "Inception"},},{"text": "A psychologist / detective gets lost in a series of dreams within dreams within dreams and Inception reused the idea","metadata": {"year": 2006, "director": "Satoshi Kon", "rating": 8.6, "title": "Paprika"},},{"text":"A bunch of normal-sized women are supremely wholesome and some men pine after them","metadata":{"year": 2019, "director": "Greta Gerwig", "rating": 8.3, "title": "Little Women"},},{"text":"Toys come alive and have a blast doing so","metadata":{"year": 1995, "genre": "animated", "director": "John Lasseter", "rating": 8.3, "title": "Toy Story"},},{"text":"Three men walk into the Zone, three men walk out of the Zone","metadata":{"year": 1979,"rating": 9.9,"director": "Andrei Tarkovsky","genre": "science fiction","rating": 9.9,"title": "Stalker",}}
]索引数据到 Elasticsearch
我们选择对 Langchain 外部的数据进行索引,以演示如何将 Langchain 用于 RAG 并在任何 Elasticsearch 索引上使用自查询检索。
from elasticsearch import helpers# create the index
client.indices.create(index="movies_self_query")operations = [{"_index": "movies_self_query","_id": i,"text": doc["text"],"metadata": doc["metadata"]} for i, doc in enumerate(docs)
]# Add the documents to the index directly
response = helpers.bulk(client,operations,
)经过上面的操作后,我们可以在 Kibana 中进行查看:
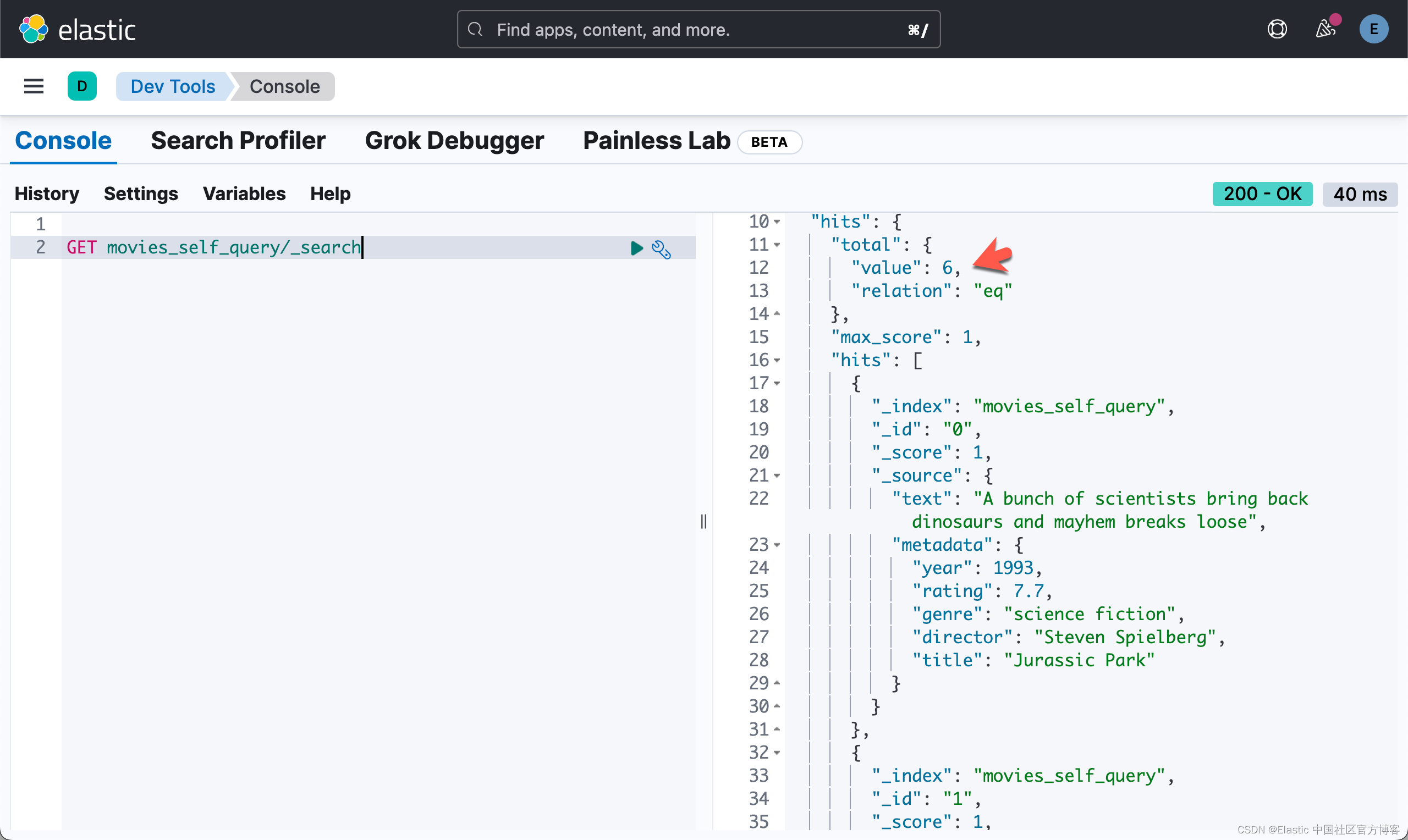
设置查询检索器
接下来,我们将通过提供有关文档属性的一些信息和有关文档的简短描述来实例化自查询检索器。
然后我们将使用 SelfQueryRetriever.from_llm 实例化检索器
from langchain.vectorstores.elasticsearch import ApproxRetrievalStrategy
from typing import List, Union
from langchain.retrievers.self_query.base import SelfQueryRetriever
from langchain.chains.query_constructor.base import AttributeInfo
from langchain.llms import OpenAI
from langchain.vectorstores.elasticsearch import ElasticsearchStore# Add details about metadata fields
metadata_field_info = [AttributeInfo(name="genre",description="The genre of the movie. Can be either 'science fiction' or 'animated'.",type="string or list[string]",),AttributeInfo(name="year",description="The year the movie was released",type="integer",),AttributeInfo(name="director",description="The name of the movie director",type="string",),AttributeInfo(name="rating", description="A 1-10 rating for the movie", type="float"),
]document_content_description = "Brief summary of a movie"# Set up openAI llm with sampling temperature 0
llm = OpenAI(temperature=0, openai_api_key=openai_api_key)class BM25RetrievalStrategy(ApproxRetrievalStrategy):def __init__(self):passdef query(self,query: Union[str, None],filter: List[dict],**kwargs,):if query:query_clause = [{"multi_match": {"query": query,"fields": ["text"],"fuzziness": "AUTO",}}]else:query_clause = []bm25_query = {"query": {"bool": {"filter": filter,"must": query_clause}},}print("query", bm25_query)return bm25_queryvectorstore = ElasticsearchStore(index_name="movies_self_query",es_connection=client,strategy=BM25RetrievalStrategy()
)仅使用 BM25 的检索器
一种选择是自定义查询以仅使用 BM25 检索方法。 我们可以通过重写 custom_query 函数,指定查询仅使用 multi_match 来做到这一点。
在下面的示例中,自查询检索器使用 LLM 将问题转换为关键字和过滤器查询(query: dreams, filter: year range)。 然后使用自定义查询对关键字查询和过滤器查询执行基于 BM25 的查询。
这意味着如果你想在现有 Elasticsearch 索引上执行问题/答案用例,则不必对所有文档进行向量化。
from langchain.schema.runnable import RunnableParallel, RunnablePassthrough
from langchain.prompts import ChatPromptTemplate, PromptTemplate
from langchain.schema import format_documentretriever = SelfQueryRetriever.from_llm(llm, vectorstore, document_content_description, metadata_field_info, verbose=True
)LLM_CONTEXT_PROMPT = ChatPromptTemplate.from_template("""
Use the following context movies that matched the user question. Use the movies below only to answer the user's question.If you don't know the answer, just say that you don't know, don't try to make up an answer.----
{context}
----
Question: {question}
Answer:
""")DOCUMENT_PROMPT = PromptTemplate.from_template("""
---
title: {title}
year: {year}
director: {director}
---
""")def _combine_documents(docs, document_prompt=DOCUMENT_PROMPT, document_separator="\n\n"
):print("docs:", docs)doc_strings = [format_document(doc, document_prompt) for doc in docs]return document_separator.join(doc_strings)_context = RunnableParallel(context=retriever | _combine_documents,question=RunnablePassthrough(),
)chain = (_context | LLM_CONTEXT_PROMPT | llm)chain.invoke("Which director directed movies about dinosaurs that was released after the year 1992 but before 2007?")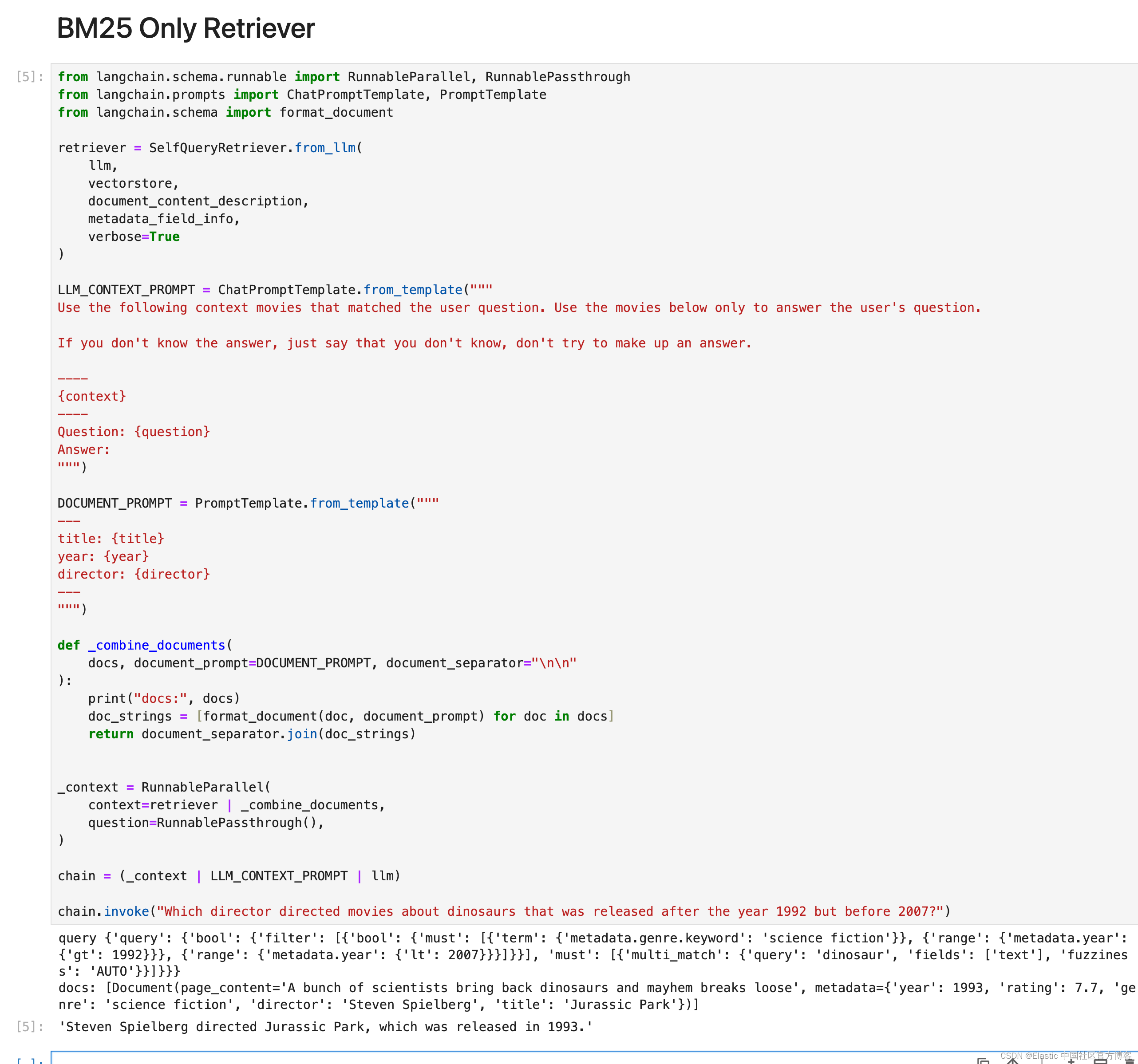
整个 notebook 的源码可以在地址下载:https://github.com/liu-xiao-guo/semantic_search_es/blob/main/chatbot-with-bm25-only-example.ipynb
这篇关于Elasticsearch:BM25 及 使用 Elasticsearch 和 LangChain 的自查询检索器的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!





