bbr专题

BBR 与 AIMD 共存公平性探究
一个古已有之的结论: deep buffer 场景,bbr 相对 reno/cubic 等 aimd 有优势,侵占性强;shallow buffer 场景,aimd 有优势,bbr 带宽被挤占。 本文用实例分析 why 并给出 how。 先看 deep buffer 场景 bbr 单挑 aimd 双流的效果,下图是标准 bbr,被虐成经理: 下图是用 max(bw/delay) 替代 ma

TCP拥塞控制算法BBR源码分析
BBR是谷歌与2016年提出的TCP拥塞控制算法,在Linux4.9的patch中正式加入。该算法一出,瞬间引起了极大的轰动。在CSDN上也有众多大佬对此进行分析讨论,褒贬不一。 本文首先对源码进行了分析,并在此基础上对BBR算法进行总结。 1.源码分析 /* Bottleneck Bandwidth and RTT (BBR) congestion control** BBR co

用相图分析 bbr,inflight 守恒的收敛速度
以下的代码绘制了 bbr 的收敛相图: #!/opt/homebrew/bin/python3import numpy as npimport matplotlib.pyplot as pltfrom scipy.integrate import odeintdef model(vars, t, C, g):x, y = varsdxdt = C * (g * x) / (g * x + y

bbr 微观建模与 inflight 守恒
bbr 解决 bufferbloat 的核心在于一个负反馈方程,设 x 为预估带宽,x_i 为 inflt,则: d x i d t = x ⋅ R − x i \dfrac{dx_i}{dt}=x\cdot R-x_i dtdxi=x⋅R−xi 这个简单的负反馈能让数据流收住 buffer,显然,当其 inflt 大于 bdp 时,方程为负数,直到排空 buffer。如果没有这个方程

闲聊:为什么需要正确的了解BBR?
为什么需要正确的了解BBR,当人们了解了BBR才能明白如KCP、锐速等解决方案与BBR本身的不同性,而不是听信谗言,一顿乱输出。 BBR是一个关注尽可能吃满管道宽频上限的算法,所以BBR并不关心丢包的问题,而类似 cubic、kcp 等拥塞控制算法都需要考虑丢包的问题。 这也意味着BBR,在产生拥塞的时候会存在一定的滞后性,它通过G(增益因子)来保持扩大带宽及感知,但过程至少需要一个R

TCP BBR算法加速效果实测(比对)
作为一枚学生党,国内的云服务器价格和带宽太过昂贵,有提供学生优惠的云服务带宽也只有1M,而我想做的是在服务器上搭建一个同步云盘,当然这些都不是最重要的,最重要的是无法帮助我科学上网。 恰巧去年暑假的时候,Vultr搞活动注册了一个账号,现还有15美元,当时因为它们的网络对电信太不友好,速度慢丢包率高,用了一小段时间后就抛弃了,而后在去年年底Google 发布了TCP BBR算法,最近突然
让WSL内核使用BBR拥塞控制算法
使用git命令从Linux内核的Git仓库中获取源代码,$ git clone --depth 1 https://github.com/microsoft/WSL2-Linux-Kernel.git,找到对应的内核版本$ git log --grep="5.15.146.1-microsoft-standard-WSL2",回退到本机安装的内核版本$ git checkout <commit-
安装新版的Ubuntu WSL以使能BBR拥塞控制算法
【多次尝试成功的方案】通过> wsl - -list -online列出可以安装的版本,用命令> wsl --install -d Ubuntu-24.04 安装。 【未成功的方案】通过挂在ubuntu24.04.iso到E盘后,用命令> wsl --import Ubuntu24.04 C:\WSL\Ubuntu24.04\ E:\ --version 2安装。
cubic 相比 bbr 并非很糟糕
迷信 bbr 的人是被它的大吞吐所迷惑,我也不想再解释,但我得反过来说一下 cubic 并非那么糟。 想搞大吞吐的,看看我这个 pixie 算法:https://github.com/marywangran/pixie,就着它的思路改就是了。 cubic 属于 aimd-based 算法,以 aimd 描述全程。以下是一个参数为 1,0.5 的 aimd 过程 tcptrace 图,md 采用

安装BBR教程,来加速VPS
安装BBR教程,来加速VPS 开源了其 TCP BBR 拥塞控制算法,并提交到了 Linux 内核,从 4.9 开始,Linux 内核已经用上了该算法。根据以往的传统,Google 总是先在自家的生产环境上线运用后,才会将代码开源,此次也不例外。 根据实地测试,在部署了最新版内核并开启了 TCP BBR 的机器上,网速甚至可以提升好几个数量级。 根据目前三大发行版的最新内核,一键安装最新内核并
CentOS使用bbr拥塞控制算法
CentOS使用bbr拥塞控制算法 一.升级CentOS的Linux内核(bbr算法出现在Linux4.9及以上内核版本) 升级内核的方式有两种,一个是通过编译内核包进行安装升级,一个是直接使用rpm包进行升级; 为了提高升级速度,我们使用rpm的方式进行升级,详细如下: 1、查看当期kernel版本 uname –r 2、导入public key rpm --im

CentOS7开启Google TCP-BBR优化算法
概述 之前抱着试试看的心态入手了Virmach 最便宜的KVM构架的VPS 没想到速度如此之慢…… 跟国内的链接速度实在感人…… 到手折腾了一下,今天重装成CentOS7的系统 最近很火的Google TCP-BBR优化算法可以在KVM构架的VPS里面开启,今天就试试了。 这是2016年9月份才开源的一个优化网络拥堵的算法。 开源地址 https://github.com/go
BBR加速及错误处理
一、升级内核 Google 开源了其TCP BBR 拥塞控制算法,并提交到了Linux内核,从4.9 开始,Linux 内核已经用上了该算法。根据实地测试,在部署了最新版内核并开启了TCP BBR 的机器上,网速甚至可以提升好几个数量级。 使用root用户登录,运行以下命令:(搬自秋水逸冰) wget --no-check-certificate https://github.com/
centos8开启BBR
2016 年,Google 团队推出了 BBR 用塞控制算法,能尽量跑满带宽。 Linux 社区集成速度很快啊,4.9 内核里面已经将 BBR 集成进去了,但是默认不开启。这么好的东西,为什么不开启呢? 开启 BBR 首先使用 uname -r 确认一下当前内核是不是 4.9+。 写进去两个参数: echo “net.core.default_qdisc=fq” >> /etc/sysct
linux contes 安装bbr及防火墙设置
这z里写自定义目录标题 一、开启BBR 1、检测系统版本 uname -r //查看内核版本bbr需要内核大于4.9 2、升级 rpm --import https://www.elrepo.org/RPM-GPG-KEY-elrepo.orgrpm -Uvh http://www.elrepo.org/elrepo-release-7.0-2.el7.elr
bbr 的 “最优操作点”
最近做一组测试,我复现了一组结果准备阐释另一个事。先看这个测试结果: 常规的一个 wrk2(expected_latency_timing 改为 actual_latency_timing 计数) 压 nginx 的测试,调整 -R 参数,Req/sec 同步增加,当 Req/sec 不再增加,nginx CPU 已 100%,处理饱和,在此之前 latency 几乎不变,在此之后,laten
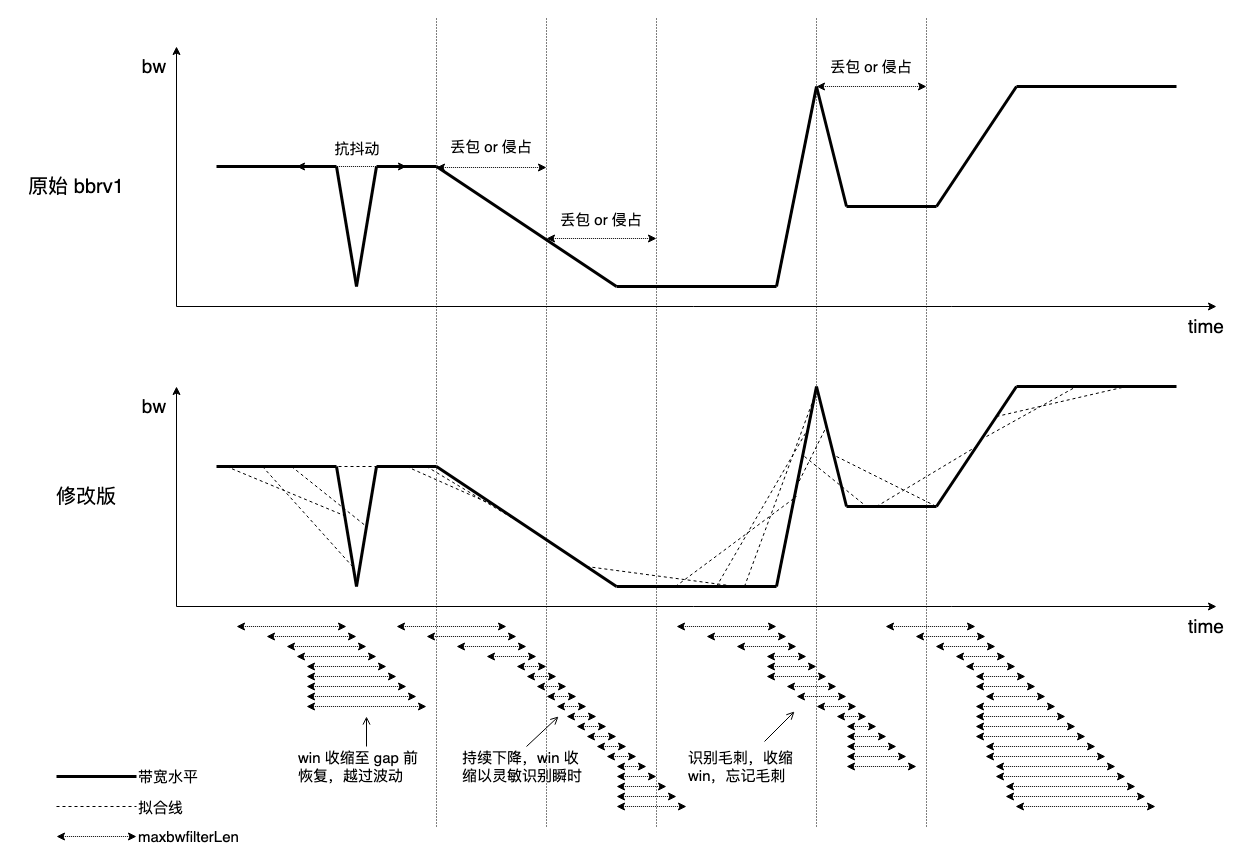
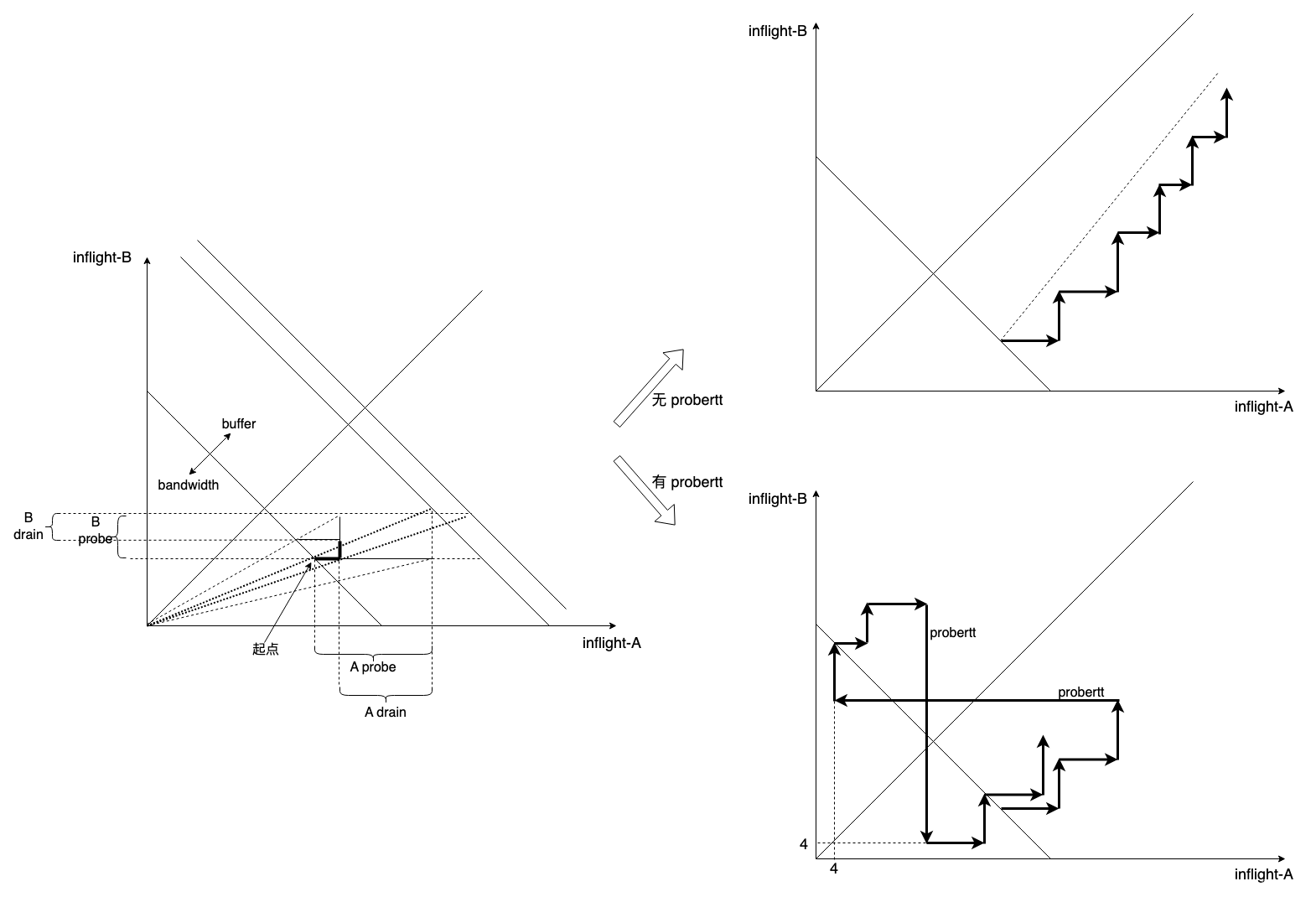
提高 bbr 的灵敏性
bbr draft 给出了 MaxBwFilterLen 的定义: MaxBwFilterLen: The filter window length for BBR.MaxBwFilter = 2 (representing up to 2 ProbeBW cycles, the current cycle and the previous full cycle). 从 v1 到 v3

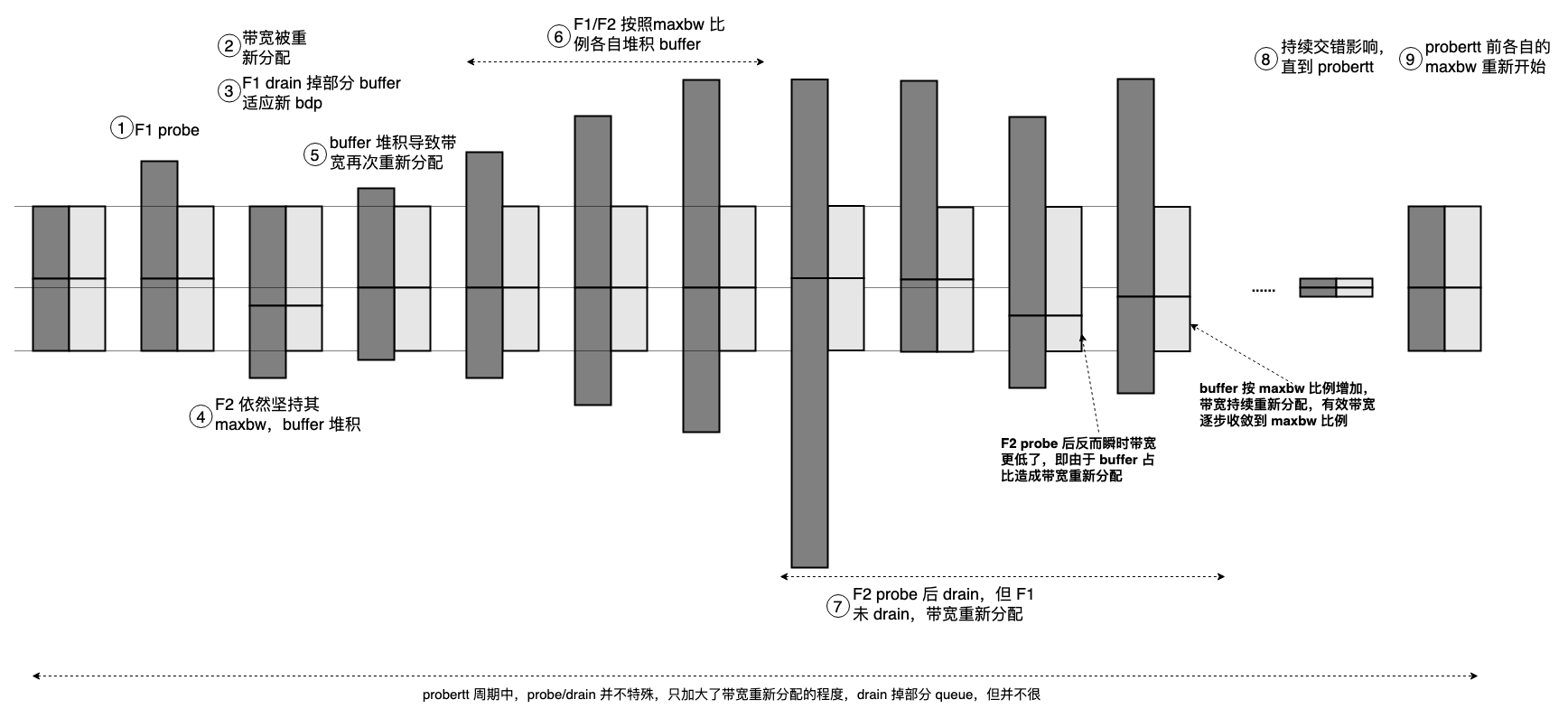
bbr 流相互作用图示
类似 AIMD 收敛图,给出 bbr 的对应图示: bbr 多流相互作用非常复杂,和右下角的 AIMD 相比,毫无美感,但是看一眼左下角的 bbr 单流情况,又过于简陋,而 bbr 的核心就基于这简陋的假设。 浙江温州皮鞋湿,下雨进水不会胖。
bbr 流相互作用图示
类似 AIMD 收敛图,给出 bbr 的对应图示: bbr 多流相互作用非常复杂,和右下角的 AIMD 相比,毫无美感,但是看一眼左下角的 bbr 单流情况,又过于简陋,而 bbr 的核心就基于这简陋的假设。 浙江温州皮鞋湿,下雨进水不会胖。
bbr 的 “最优操作点”
最近做一组测试,我复现了一组结果准备阐释另一个事。先看这个测试结果: 常规的一个 wrk2(expected_latency_timing 改为 actual_latency_timing 计数) 压 nginx 的测试,调整 -R 参数,Req/sec 同步增加,当 Req/sec 不再增加,nginx CPU 已 100%,处理饱和,在此之前 latency 几乎不变,在此之后,laten
TCP BBR算法加速效果实测(比对)
作为一枚学生党,国内的云服务器价格和带宽太过昂贵,有提供学生优惠的云服务带宽也只有1M,而我想做的是在服务器上搭建一个同步云盘,当然这些都不是最重要的,最重要的是无法帮助我科学上网。 恰巧去年暑假的时候,Vultr搞活动注册了一个账号,现还有15美元,当时因为它们的网络对电信太不友好,速度慢丢包率高,用了一小段时间后就抛弃了,而后在去年年底Google 发布了TCP BBR算法,最近突然
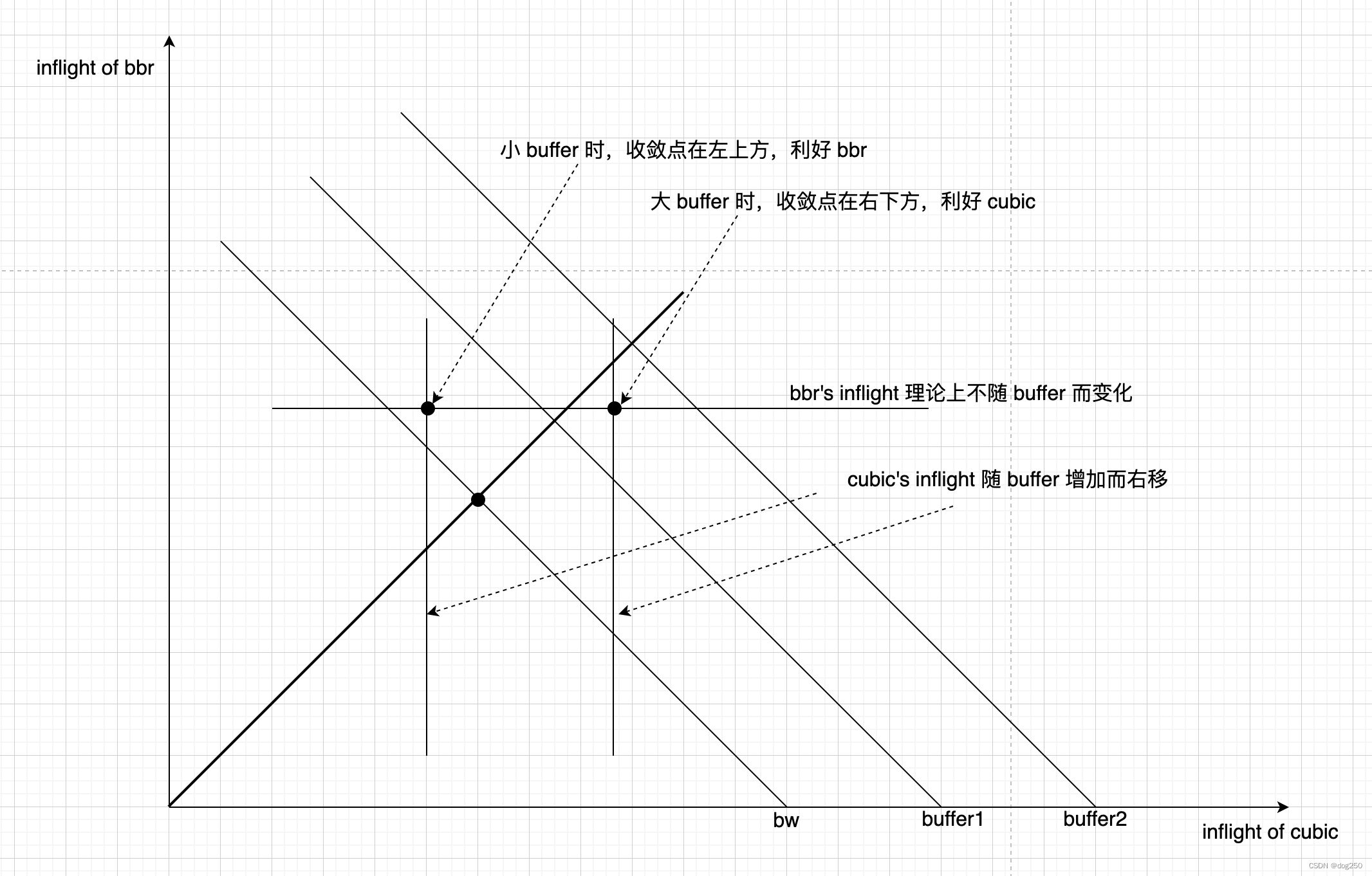
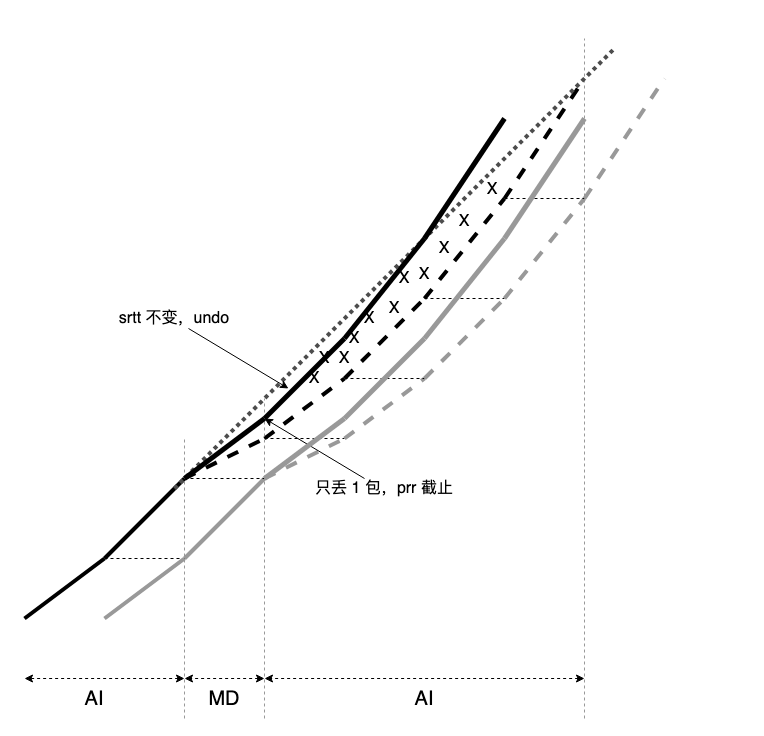
BBR/CUBIC 共存时的 buffer 挤兑
BBR 与 CUBIC 共存时的收敛图,理论情况: 理论上 BBR 不会挤占 buffer,inflight 保持为恒定的 BDP。 但 BBR 的 inflight 做不到恒定,多流共存时,依然会 “主动占用 buffer” 而相互挤兑带宽,而该行为是必须的。 BBR 的本意用 gain = 125% 去 probe,若带宽没增加,说明已挤占 buffer,然后以 gain = 0.75 将

BBR算法及其收敛性
1.TCP拥塞的本质 注意,我并没有把题目定义成网络拥塞的本质,不然又要扯泊松到达和排队论了。事实上,TCP拥塞的本质要好理解的多!TCP拥塞绝大部分是由于其”加性增,乘性减“的特性造成的! 也就是说,是TCP自己造成了拥塞!TCP加性增乘性减的特性引发了丢包,而丢包的拥塞误判带来了巨大的代价,这在深队列+AQM情形下尤其明显。 我尽可能快的解释。争