本文主要是介绍AI大模型日报#0515:Google I/O大会、 Ilya官宣离职、腾讯混元文生图大模型开源,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
导读:欢迎阅读《AI大模型日报》,内容基于Python爬虫和LLM自动生成。目前采用“文心一言”(ERNIE 4.0)、“零一万物”(Yi-34B)生成了今日要点以及每条资讯的摘要。
《AI大模型日报》今日要点:谷歌Google I/O大会上宣布了一系列AI更新,包括Gemini 1.5 Pro的升级,其上下文窗口已扩展至200万tokens,同时推出了轻量级模型Gemini 1.5 Flash。此外,谷歌还展示了多模态理解和实时对话能力的Project Astra,以及最新的视频生成模型Veo和高质量文本到图像模型Imagen 3,彰显了其在AI领域的持续投入与竞争力。另一方面,大模型分词故障自动检测方法获科技大神Karpathy推荐,此方法可望解决大模型分词故障问题,并提升模型表现。在模型性价比方面,火山引擎推出了价格低至行业价格0.7%的豆包大模型,其对外开放服务提供极致性价比,标志着大模型落地应用的又一重要进展。然而,在业界人事变动方面,OpenAI联合创始人、首席科学家Ilya Sutskever宣布离职,引发了业界对于OpenAI未来走向的关注。同时,百度团队开发的基于Transformer的RNA语言模型RNAErnie在多功能RNA分析方面取得显著成果,成功登上Nature子刊。最后,腾讯宣布其混元文生图大模型全面升级并开源,此举有望丰富中文文生图开源生态,推动大模型行业的加速发展。
标题: 谷歌Gemini时代来了!加固搜索护城河、赋能全家桶,Gemini 1.5 Pro升级至200万token
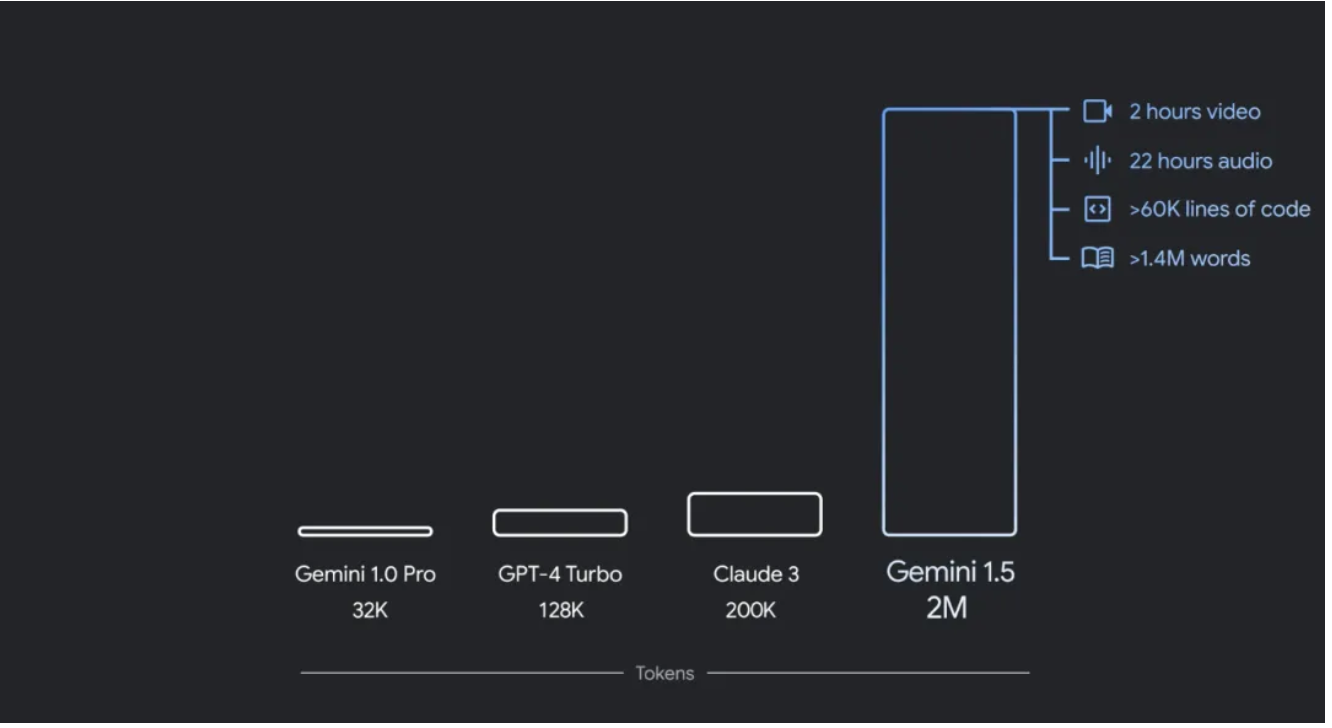
摘要: 谷歌的Google I/O大会上宣布了一系列的AI更新,包括Gemini 1.5 Pro的上下文窗口扩展到200万tokens,以及轻量级模型Gemini 1.5 Flash的推出。同时,DeepMind CEO Demis Hassabis介绍了Gemini 1.5 Flash的多模态特性和Gemma 2的新架构。此外,谷歌还展示了Project Astra的多模态理解和实时对话能力,以及最新的视频生成模型Veo和高质量文本到图像模型Imagen 3。这些更新表明谷歌在AI领域持续发力,与竞争对手OpenAI及其背后的微软展开激烈竞争。
网址: 谷歌Gemini时代来了!加固搜索护城河、赋能全家桶,Gemini 1.5 Pro升级至200万token - 智源社区
标题: 大神Karpathy强推,分词领域必读:自动钓鱼让大模型“发疯”的token,来自Transformer作者创业公司

摘要: 科技记者讯,新论文提出大模型分词故障自动检测方法,获大神Karpathy推荐。大模型tokenizer的创建和模型训练分离,可能导致训练不足的token,引发模型异常输出。Cohere研究人员通过三步骤检测故障token,包括分析tokenizer,找出特殊token如不完整UTF-8序列等;根据模型计算识别指标,找出嵌入向量异常token;通过特定prompt验证。此方法在多个主流大语言模型上发现数千个训练不足token,如单字节token和特殊字符。词汇表较大的模型训练不足token更多。论文建议优化词汇表结构和tokenizer算法,确保数据预处理相同,检查无法访问token等。此研究有望解决大模型分词故障问题,提升模型表现。
网址: 大神Karpathy强推,分词领域必读:自动钓鱼让大模型“发疯”的token,来自Transformer作者创业公司 - 智源社区
标题: 大模型价格进入“厘”时代,豆包大模型定价每千tokens仅0.8厘

摘要: 要点提炼: 1. 大模型性价比之战升级,火山引擎推出自研豆包大模型,价格低至行业价格的0.7%。 2. 豆包大模型在火山引擎上对外开放服务,提供极致性价比,一元钱能购买到相当于三本《三国演义》输入量的模型服务。 3. 火山引擎总裁谭待认为,降低成本是推动大模型快速进入价值创造阶段的关键因素。 4. 过去一年,许多企业已将大模型与核心业务流结合,但成本高昂问题仍是制约大模型落地的关键要素。 5. 火山引擎智能算法负责人吴迪透露,预计2024年底或2025年初,企业对大模型的调用量将出现陡峭上升。 6. 火山方舟2.0版本在模型效果、系统承载力、性价比三个方面提出具体解决方案,并发布企业级AI应用开发平台扣子专业版。 7. 豆包大模型在字节跳动内部经过50余个业务场景的打磨,日调用量达到1200亿tokens,图片生成量超过3000万张。 8. 火山方舟在系统承载力方面增强,拥有充沛的公有云GPU资源池,能够分钟级完成千卡扩缩容,并提供丰富的插件生态,包括联网插件、内容插件和RAG知识库插件。 9. 吴迪强调,火山方舟的目的是帮助企业更快、更省地推进大模型落地,解除技术障碍,共同将大模型技术推向新的高度。
网址: 大模型价格进入“厘”时代,豆包大模型定价每千tokens仅0.8厘 | 机器之心
标题: Ilya官宣离职,超级对齐负责人Jan直接辞职,OpenAI还是走散了

摘要: OpenAI 联合创始人、首席科学家 Ilya Sutskever 宣布离职,结束了他近 10 年的 OpenAI 生涯。他在推文中表达了对团队和 OpenAI 成就的感激,并透露了离职后将专注于一个对他来说意义非凡的项目。OpenAI CEO Dmitry 奥特曼对 Ilya 的离职表示了遗憾,并高度评价了 Ilya 的才华、远见和领导力。新任首席科学家 Jakub Pachocki 感谢了 Ilya 的指导和合作,并承诺将继续推动 OpenAI 的使命。Ilya Sutskever 的离职和超级对齐团队共同领导者 Jan Leike 的离开,标志着 OpenAI 创始团队成员的又一次变动,也留下了对超级对齐项目未来走向的疑问。
网址: Ilya官宣离职,超级对齐负责人Jan直接辞职,OpenAI还是走散了 | 机器之心
标题: 多功能RNA分析,百度团队基于Transformer的RNA语言模型登Nature子刊

摘要: RNAErnie 是一种基于 Transformer 架构的预训练语言模型,专门设计用于分析核苷酸序列。该模型由百度大数据实验室(BDL)和上海交通大学团队开发,通过多级掩蔽策略进行预训练,以捕获不同层次的序列信息。RNAErnie 在七个数据集和五个任务上的评估显示出了其优越性,包括分类、交互预测和结构预测。该研究以「Multi-purpose RNA language modelling with motif-aware pretraining and type-guided fine-tuning」为题,发表在《Nature Machine Intelligence》上。
网址: 多功能RNA分析,百度团队基于Transformer的RNA语言模型登Nature子刊 | 机器之心
标题: 刚刚,Ilya官宣离职OpenAI,“下一个项目意义重大”
摘要: 提炼要点: 1. Ilya Sutskever宣布离职OpenAI,并透露已有新的个人项目,但未提供详细信息。 2. OpenAI的CEO Dmitry "Dima" Grishin对Ilya的贡献给予高度评价,并感谢他在公司发展中的角色。 3. OpenAI发布GPT-4模型,Ilya的名字出现在“额外领导者”一栏,可能是其最后的贡献。 4. 离职消息发布在谷歌I/O大会之后,吸引了广泛关注。 5. 新任首席科学家Jakub Pachocki接替Ilya的职位,并获得CEO的积极评价。 6. 网友对Ilya的离职表示祝福,并猜测其下一步可能加入马斯克的xAI。 7. Jakub Pachocki在OpenAI中担任过多个重要项目的负责人,包括Dota游戏项目、ChatGPT和GPT-4。 8. 对于Ilya离职后的去向及其所见的“重大意义”项目,外界充满好奇,并期待未来揭晓答案。
网址: 刚刚,Ilya官宣离职OpenAI,"下一个项目意义重大" | 量子位
标题: 腾讯宣布混元文生图大模型开源: Sora 同架构,可免费商用

摘要: 腾讯宣布其混元文生图大模型全面升级并开源,该模型基于DiT架构,参数量为15亿,支持中英文双语输入和理解。评测数据显示,该模型效果远超Stable Diffusion,达到国际领先水平。腾讯混元文生图团队自2023年7月起明确基于DiT架构的模型方向,并在今年初全面升级为DiT架构。模型在算法层面优化了长文本理解能力,并实现了多轮生图和对话能力。 混元文生图大模型是首个中文原生的DiT模型,在生成中国元素的内容上表现出色。腾讯混元文生图能力已应用于多个业务及场景,包括广告创意和新闻内容生产。腾讯文生图负责人芦清林表示,此次开源是希望与行业共享实践经验和研究成果,丰富中文文生图开源生态,推动大模型行业加速发展。 基于腾讯开源的文生图模型,开发者和企业可以直接用于推理,并基于混元文生图打造专属的AI绘画应用和服务,节约大量人力和算力。同时,这也有利于丰富以中文为主的文生图开源生态,推动中文文生图技术研发和应用。腾讯在开源上一直持开放态度,已开源了超170个项目,并在Github上获得超47万开发者关注及点赞。
网址: 腾讯宣布混元文生图大模型开源: Sora 同架构,可免费商用 | 量子位
标题: 无需OpenAI数据,跻身代码大模型榜单!UIUC发布StarCoder-15B-Instruct

摘要: StarCoder2-15B-Instruct是由UIUC张令明团队与BigCode组织合作开发的一个代码生成模型,它在性能上超过了CodeLlama-70B-Instruct,成为代码生成领域的领先者。该模型的独特之处在于其纯自对齐策略,即通过自我验证机制生成指令-响应对,而不依赖于外部教师模型或昂贵的人工标注数据。这一过程确保了模型的训练流程公开透明且完全自主可控。在HumanEval测试和LiveCodeBench评估中,StarCoder2-15B-Instruct表现出色,证明了通过自身数据分布,大模型可以有效地学习与人类偏好对齐,而无需依赖外部模型的偏移分布。该项目的成功实施得到了多家学术和企业的支持。
网址: 无需OpenAI数据,跻身代码大模型榜单!UIUC发布StarCoder-15B-Instruct|指令_新浪新闻
这篇关于AI大模型日报#0515:Google I/O大会、 Ilya官宣离职、腾讯混元文生图大模型开源的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!








