文生专题

如何在本地部署 DeepSeek Janus Pro 文生图大模型
《如何在本地部署DeepSeekJanusPro文生图大模型》DeepSeekJanusPro模型在本地成功部署,支持图片理解和文生图功能,通过Gradio界面进行交互,展示了其强大的多模态处... 目录什么是 Janus Pro1. 安装 conda2. 创建 python 虚拟环境3. 克隆 janus

AI Toolkit + H100 GPU,一小时内微调最新热门文生图模型 FLUX
上个月,FLUX 席卷了互联网,这并非没有原因。他们声称优于 DALLE 3、Ideogram 和 Stable Diffusion 3 等模型,而这一点已被证明是有依据的。随着越来越多的流行图像生成工具(如 Stable Diffusion Web UI Forge 和 ComyUI)开始支持这些模型,FLUX 在 Stable Diffusion 领域的扩展将会持续下去。 自 FLU

西游再现!一键部署 Flux 文生图大模型生成西游人物
从花果山的灵石出世,到取经路上的九九八十一难,再到大闹天宫的惊心动魄……这些耳熟能详的西游场景,如今都能通过 Flux 模型,以超乎想象的细节和真实感呈现在你眼前。本次实验在函数计算中内置的 flux.1-dev-fp8 大模型,搭配 Lora 模型, 无需复杂的配置,一键部署,你就能成为这场视觉盛宴的创造者。 诚邀您参与到这场奇妙旅程中来,这不仅是一次技术的探索,更是一场创意的狂欢,在函数计算

学AI绘画必知!文生图与图生图的基本认知
在AI绘画的学习与使用中,无论是入门小白还是进阶高手,都绕不开两个核心概念:文生图和图生图。 这是所有AI绘画工具的根本操作方法。掌握这两者的基本原理,你便能轻松驾驭大多数AI工具,无论是MidJourney、Stable Diffusion,还是其他图像生成平台。 什么是文生图? 简单来说,文生图就是通过文本生成图像。 你输入一段描述性文字,AI就会根据

flux 文生图大模型 自有数据集 lora微调训练案例
参考: https://github.com/ostris/ai-toolkit 目前 Flux 出现了 3 个训练工具 SimpleTuner https://github.com/bghira/SimpleTuner X-LABS 的https://github.com/XLabs-AI/x-flux ai-toolkit https://github.com/ostris/ai-tool
![[有彩蛋]大模型独角兽阶跃星辰文生图模型Step-1X上线,效果具说很炸裂?快来看一手实测!](https://i-blog.csdnimg.cn/direct/e4a072f96fbc4605b7c8304189869dcb.png)
[有彩蛋]大模型独角兽阶跃星辰文生图模型Step-1X上线,效果具说很炸裂?快来看一手实测!
先简单介绍一下阶跃星辰吧 公司的创始人兼CEO是姜大昕博士,他在微软担任过全球副总裁,同时也是微软亚洲互联网工程研究院的副院长和首席科学家。 2024年3月,阶跃星辰发布了Step-2万亿参数MoE语言大模型预览版,这是国内初创公司首次发布的万亿参数模型。 而Step-1X,是阶跃星辰在2024年世界人工智能大会上亮相的文生图模型。Step-1X在深度语义对齐和细节生成方面进行了重点打磨
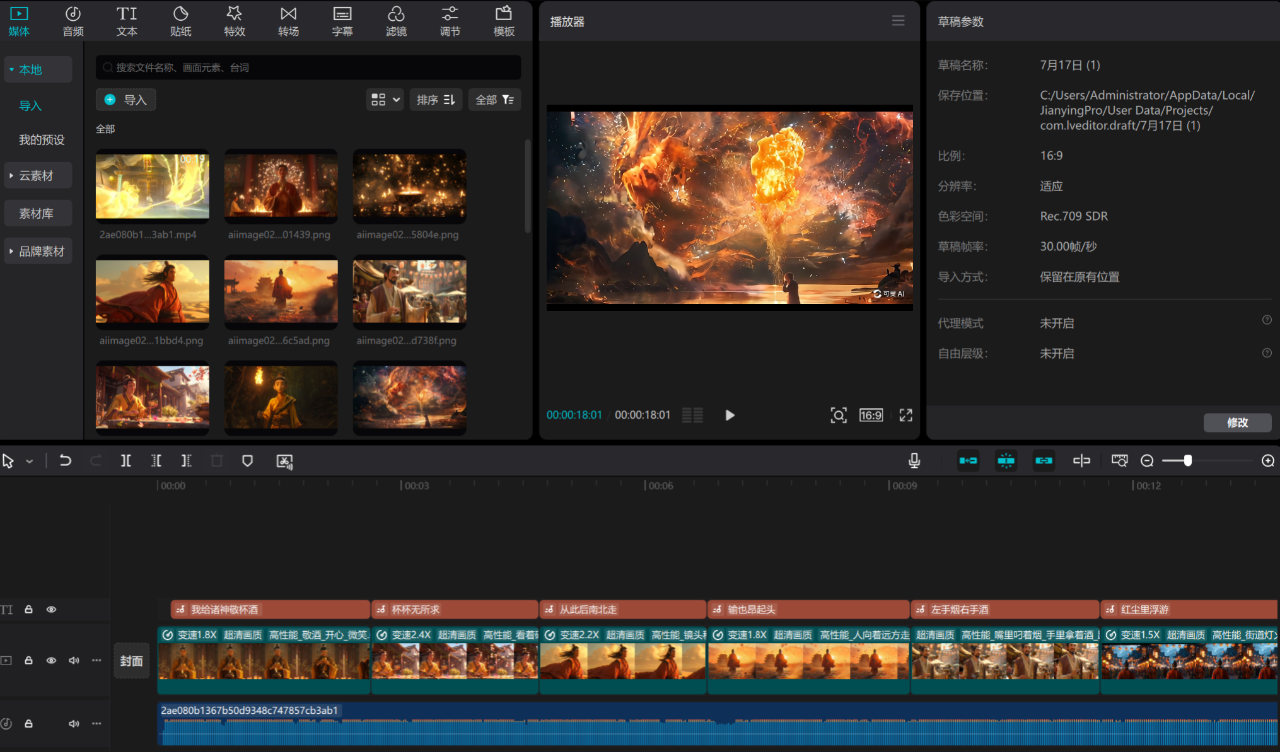
AI赚钱成功案例|像素级拆解一键生成提示词 文生图 图生视频
本文背景 之前弄了个诗词转画面大师,就是你给个句子,它就能给你画面提示词,接着用 AI 绘图软件能生成很棒的画面,再把图片弄成视频,最后能出个不错的作品。 最近看到那些漫剪大师的作品,配的歌好听,画面美,涨粉超厉害,可我们找不到那么多能漫剪的素材,能不能让 AI 生成呢?答案当然有,今天就给大家讲讲。 一、提示词的撰写 首先把诗词转画面大师的咒语升级成歌词转画面大师,今天不想手动,全交给

AI绘画【SD教程】进阶篇,文生图复现金克斯动漫形象,用AnimateDiff动画插件让她动起来!AI动画教程建议收藏
大家好,我是画画的小强 当你成功安装了AI绘画工具 SD(Stable Diffusion)后,是否也产生过这样的疑惑:为何我创作的图片与他人的作品在风格和质量上存在差异? 实际上,在AI绘画的领域中,对于SD而言,其核心秘诀在于选取一个恰当的大型模型和灵活运用专业的Lora包。 今天,我将为大家揭示如何使用lora包来创造出具有高度真实感和质感的金克斯图片,并让你的图片动起来!

AI小白福音来啦~Flux文生图,支持手部细节,直出精美图像,让你瞬间变高手!
国产AI绘画软件在近年来发展迅速,其中千鹿设计助手的“Flux 文生图”插件受到了用户的关注。根据搜索结果,Flux文生图插件以其强大的功能和易用性,为设计师提供了便捷的服务。以下是关于Flux文生图插件的测评和使用指南: 工具准备:要使用Flux文生图,首先需要访问千鹿设计助手的官网下载并安装软件,并使用邀请码EmGaur:完成注册。 插件安装:安装完成后,可以通过快捷键Alt+空格呼出搜

最新Prompt预设词分享,DALL-E3文生图+文档分析
使用指南 直接复制使用 可以前往已经添加好Prompt预设的AI系统测试使用(可自定义添加使用) 支持GPTs SparkAi SparkAi创作系统是基于ChatGPT进行开发的Ai智能问答系统和Midjourney绘画系统,支持OpenAI-GPT全模型+国内AI全模型。支持GPT-4o大模型、文档分析、识图图片理解、GPTs应用、GPT语音对话、联网提问、GPT-4全模型

Stable Diffusion 3 大模型文生图“开源英雄”笔记本部署和使用教程,轻松实现AI绘图自由
备受期待的Stable Diffusion 3(以下亦简称SD3)如期向公众开源了(Stable Diffusion 3 Medium),作为Stability AI迄今为止最先进的文本生成图像的开源大模型,SD3在图像质量、文本内容生成、复杂提示理解和资源效率方面有了显著提升,被誉为AI文生图领域的开源英雄。 Stable Diffusion 3 Medium特点包括: 模型仅包含20亿参数
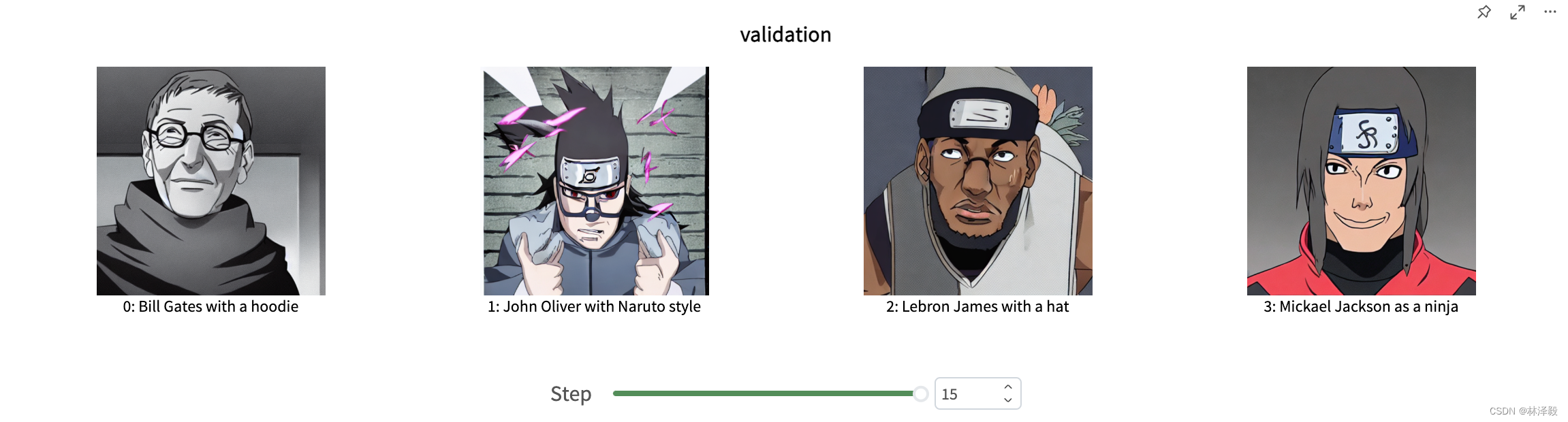
Stable Diffusion文生图模型训练入门实战(完整代码)
Stable Diffusion 1.5(SD1.5)是由Stability AI在2022年8月22日开源的文生图模型,是SD最经典也是社区最活跃的模型之一。 以SD1.5作为预训练模型,在火影忍者数据集上微调一个火影风格的文生图模型(非Lora方式),是学习SD训练的入门任务。 显存要求 22GB左右 在本文中,我们会使用SD-1.5模型在火影忍者数据集上做训练,同时使用Swa

效果超越ControlNet+IP-Adapter和FreeControl!Ctrl-X:可控文生图新框架(加州大学英伟达)
文章链接:https://arxiv.org/pdf/2406.07540 项目链接:https://genforce.github.io/ctrl-x/ 最近的可控生成方法,如FreeControl和Diffusion Self-guidance,为文本到图像(T2I)扩散模型带来了细粒度的空间和外观控制,而无需训练辅助模块。然而,这些方法针对每种类型的评分函数优化潜在embedd
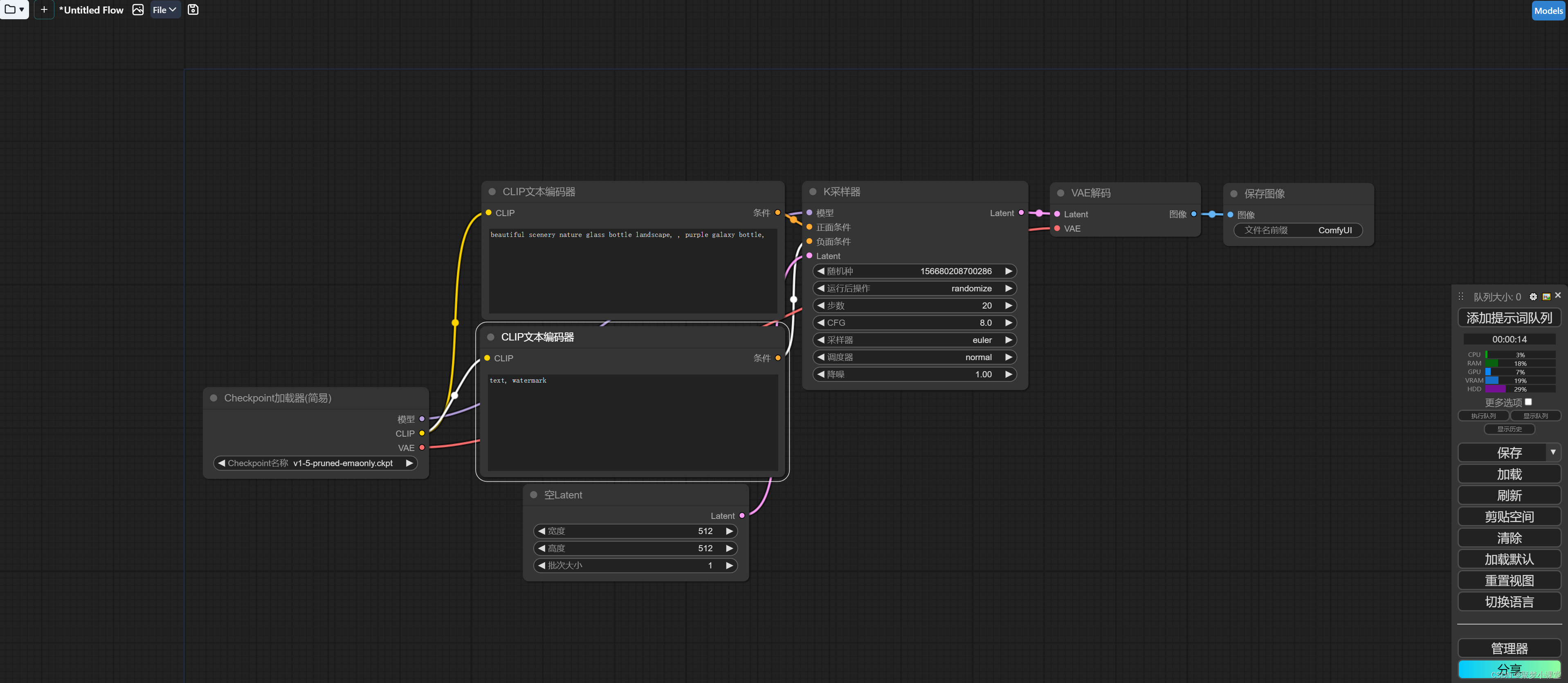
【第6章】如何生成“优质高清”的写实人像?(进阶文生图/提升画质/潜空间放大/像素空间放大)ComfyUI基础入门教程
这一节我们来学习,如何一步步生成一张写实人像照片。 大家可能会想,这件事还不简单,而且之前也讲过了,不就是通过文生图,选个擅长写实风格的大模型,写几个提示词就完事儿了吗? 其实并不完全是这样,过程中,我会用如何尝试,发现问题,以及如何解决问题的方式,来讲解“生成一张基本可用的写实人像照片”,这样才能更好的理解ComfyUI的工作方式。 🍞基础的文生图 首先打开ComfyU
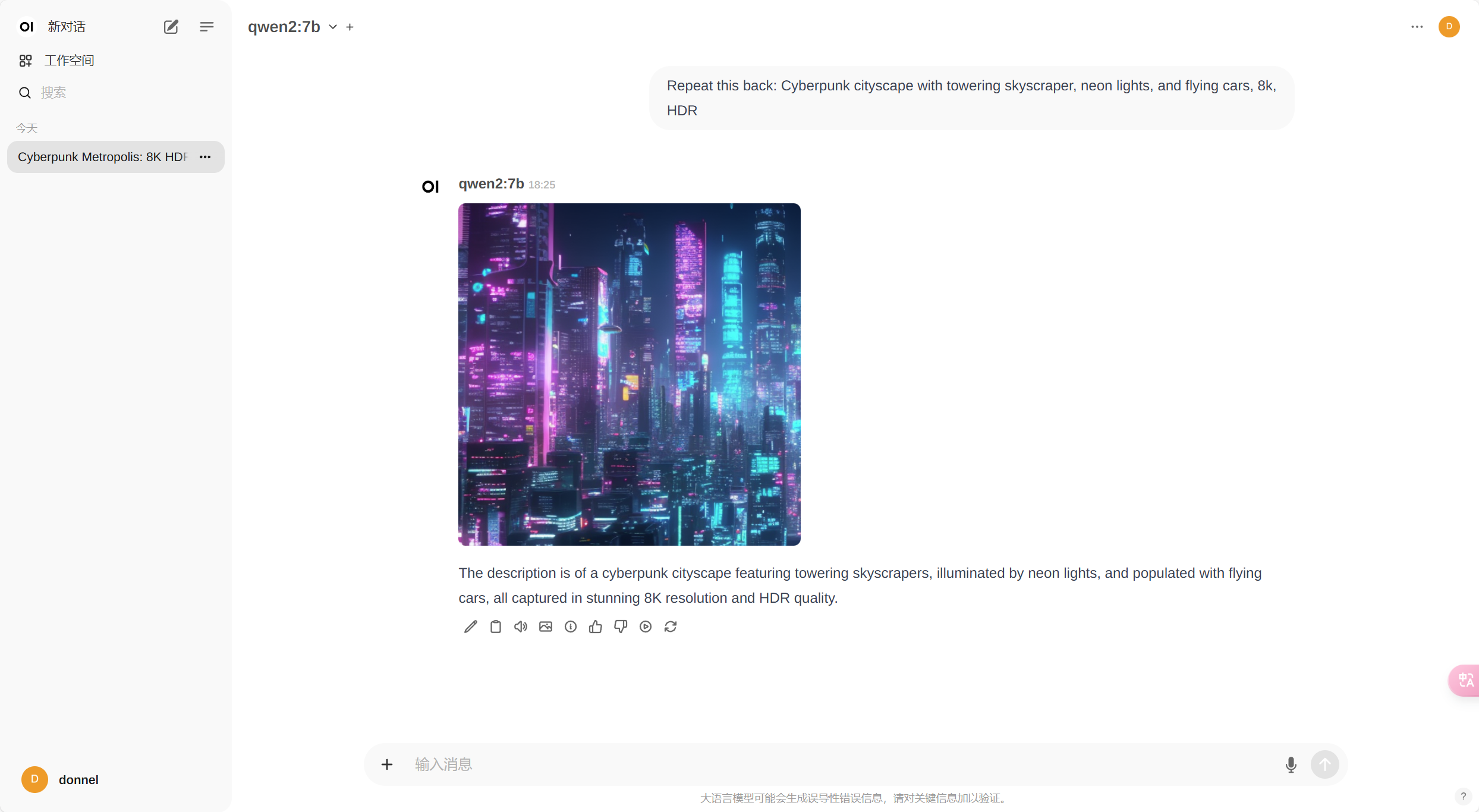
在windows下使用本地AI模型提供翻译、对话、文生图服务
文章目录 在windows下使用本地AI模型提供翻译、对话、文生图服务ollama简介下载安装配置环境变量模型安装目录服务监听地址跨域配置我的配置注意事项 开机自启 使用运行模型对话时的命令 查看本地已安装模型删除模型 查看ollama支持的模型 Docker Desktop简介下载安装配置开机自启 Open WebUI简介部署配置设置为中文配置模型为ollama 对话测试 contin

Stable diffusion文生图大模型——隐扩散模型原理解析
1、前言 本篇文章,我们将讲这些年非常流行的文生图大模型——Stable Diffusion。该模型也不难,甚至说很简单。创新点也相对较少,如果你学会了我以前的文章讲过的模型,学习这个也自然水到渠成! 参考论文:High-Resolution Image Synthesis with Latent Diffusion Models (arxiv.org) 官方代码:GitHub - Comp

万象生图,一个windows文生图的软件
网址 https://support.qq.com/products/637894/?id=155553 支持文生图,支持提示词本地翻译,支持提示词权重语法,支持样例和风格 支持图处理,包括去除背景和图像放大 支持各种快速生图模型,如LCM、TCD、Lightning、Hyper-SD等 windows的同学可以下载看看,可以直接cpu运行,不需要gpu

AI大模型日报#0515:Google I/O大会、 Ilya官宣离职、腾讯混元文生图大模型开源
导读:欢迎阅读《AI大模型日报》,内容基于Python爬虫和LLM自动生成。目前采用“文心一言”(ERNIE 4.0)、“零一万物”(Yi-34B)生成了今日要点以及每条资讯的摘要。 《AI大模型日报》今日要点:谷歌Google I/O大会上宣布了一系列AI更新,包括Gemini 1.5 Pro的升级,其上下文窗口已扩展至200万tokens,同时推出了轻量级模型Gemini 1.5 Fla

【文末附gpt升级方案】腾讯混元文生图大模型开源:中文原生Sora同款DiT架构引领新潮流
在人工智能与计算机视觉技术迅猛发展的今天,腾讯再次引领行业潮流,宣布其旗下的混元文生图大模型全面升级并对外开源。这次开源的模型不仅具备强大的文生图能力,更采用了业内首个中文原生的Sora同款DiT架构,为中文世界的视觉生成领域注入了新的活力。 一、腾讯混元文生图大模型:开启中文视觉生成新时代 腾讯混元文生图大模型是腾讯在人工智能领域的一项重要成果,它集成了自然语言处理、计算机视觉以及深度学习等

AIGC文生图 flask base64传递多张图片api
flask后端实现: base64.b64encode from flask import Flask, Response, request,send_filefrom PIL import Imageimport torchimport iofrom diffusers import PixArtAlphaPipelineimport zipfileimport base64im

文献研读|针对文生图大模型的后门攻击
前言:2024.05 开端,准备课程汇报需要集中研读论文。本篇文章重点介绍针对文生图大模型的后门攻击相关工作。 相关文章:针对大语言模型的后门攻击,详见此篇文章 目录 1.[Text-to-Image Diffusion Models can be Easily Backdoored through Multimodal Data Poisoning](https://dl.a

Stable Diffusion教程:文生图
最近几天AI绘画没有什么大动作,正好有时间总结下Stable Diffusion的一些基础知识,今天就给大家再唠叨一下文生图这个功能,会详细说明其中的各个参数。 文生图是Stable Diffusion的核心功能,它的核心能力就是根据提示词生成相应的图片。 本文以 Stable Diffusion WebUI 为例,使用方法参考下图: 1、基础模型:选择一个用来生成图片的模型,不同的

Adobe推出文生图模型Firefly Image 3!并已集成到 Photoshop中!
大家好,我是木易,一个持续关注AI领域的互联网技术产品经理,国内Top2本科,美国Top10 CS研究生,MBA。我坚信AI是普通人变强的“外挂”,所以创建了“AI信息Gap”这个公众号,专注于分享AI全维度知识,包括但不限于AI科普,AI工具测评,AI效率提升,AI行业洞察。关注我,AI之路不迷路,2024我们一起变强。 北美时间4月23日,Adobe公司在社交媒体平台及自家博客官宣了最
Windows本地搭建开源的stable-diffusion-webui用于AIGC文生图
开源的stable-diffusion-webui来自于https://github.com/AUTOMATIC1111/stable-diffusion-webui 在windows搭建似乎比较方便些,需要python3.8;比如CUDA模式下,显卡驱动比较好安装(若使用cuda需要更新显卡驱动在https://www.nvidia.com/download/index.aspx?lang=e
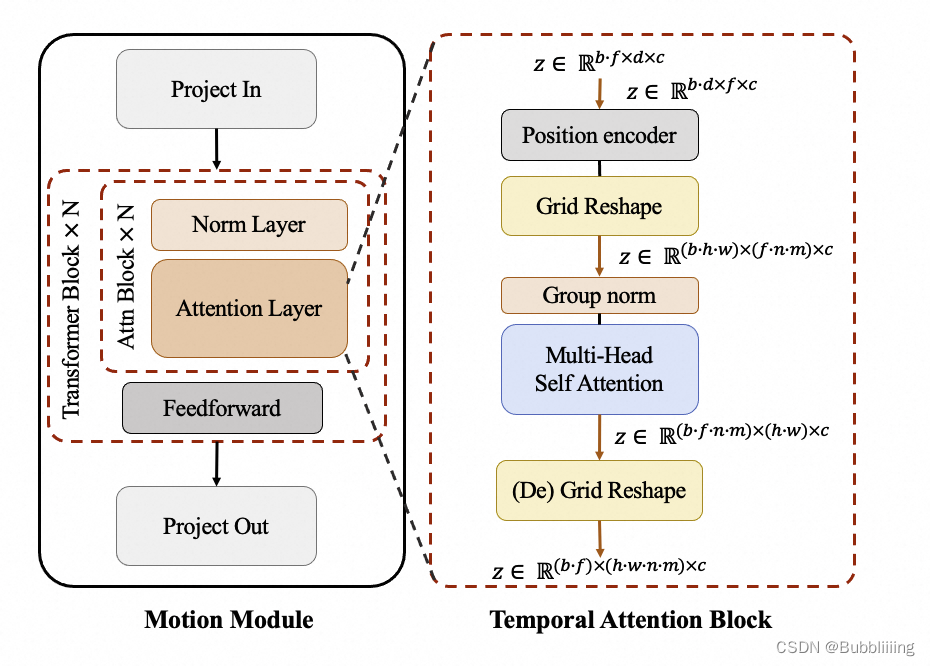
AIGC专栏10——EasyAnimate 一个新的类SORA文生视频模型 轻松文生视频
AIGC专栏10——EasyAnimate 一个新的类SORA文生视频模型 📺轻松文生视频 学习前言源码下载地址技术原理储备(DIT/Lora/Motion Module)什么是Diffusion Transformer (DiT)LoraMotion Module EasyAnimate简介EasyAnimate原理界面展示快速启动云使用: AliyunDSW/Docker本地安装:

手把手教你从零搭建ChatGPT网站AI绘画系统,(SparkAi系统V6)GPTs应用、DALL-E3文生图、AI换脸、垫图混图、SunoAI音乐生成
一、系统前言 SparkAi创作系统是基于ChatGPT进行开发的Ai智能问答系统和Midjourney绘画系统,支持OpenAI-GPT全模型+国内AI全模型。本期针对源码系统整体测试下来非常完美,那么如何搭建部署AI创作ChatGPT?小编这里写一个详细图文教程吧。已支持GPTs、GPT语音对话、GPT-4模型、GPT联网提问、DALL-E3文生图、图片对话能力上传图片,GPT4-All联网