本文主要是介绍提升文本到图像模型的空间一致性:SPRIGHT数据集与训练技术的新进展,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
当前的T2I模型,如Stable Diffusion和DALL-E,虽然在生成高分辨率、逼真图像方面取得了成功,但在空间一致性方面存在不足。这些模型往往无法精确地按照文本提示中描述的空间关系来生成图像。为了解决这一问题,研究人员进行了深入分析,并提出了创新的解决方案。
识别问题:现有视觉-语言数据集中空间关系的不足
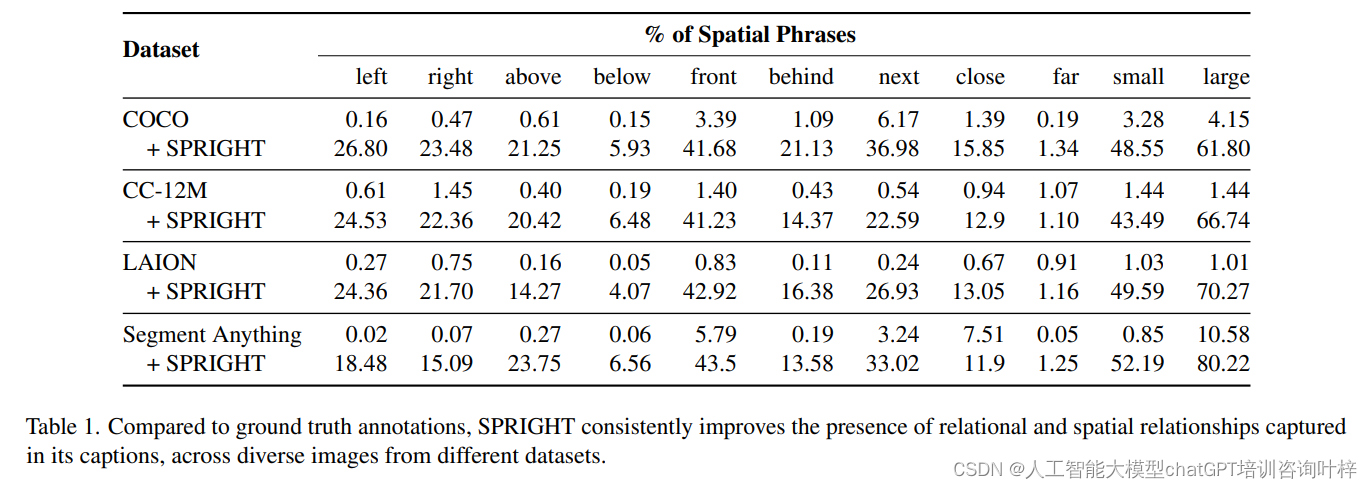
在构建文本到图像模型时,一个核心挑战是确保生成的图像能够精确地反映文本描述中的空间关系。例如,如果文本描述中提到“一只猫坐在垫子上”,理想的图像应该展示猫位于垫子的上方。然而,研究人员发现,现有的视觉-语言数据集在文本描述中对这类空间关系的表达可能非常简单,如 "A cat is on a mat."(一只猫在垫子上。)这种描述没有明确指出猫与垫子的相对位置。理想描述应该包含空间关系,如 "A cat is sitting on top of a mat."(一只猫坐在垫子的上方。)这样的描述为模型提供了更精确的空间信息。总结下来问题主要如下:
空间词汇的稀缺性:描述物体相对位置的词汇,如“左边”、“右边”、“上方”、“下方”等,在数据集的文本描述中出现频率较低。
空间关系的忽视:即使图像中存在明显的空间关系,相应的文本描述也常常没有提及,导致模型无法学习到这些关系。
描述的模糊性:现有的描述往往忽略物体间的精确位置关系,使得模型难以生成具有明确空间布局的图像。

数据集构建:SPRIGHT数据集的创建
为了提升文本到图像(T2I)模型在生成图像时的空间一致性,必须让模型更好地理解和利用空间关系。因此,他们决定构建一个专门的数据集,旨在强化模型对空间词汇和关系的识别与生成能力。
SPRIGHT数据集的核心特点
- 大规模:SPRIGHT数据集包含了约600万张图像,这为训练和评估T2I模型提供了丰富的资源。
- 专注空间关系:与传统数据集相比,SPRIGHT特别强调图像中的空间关系,如物体的相对位置和大小。
构建过程
-
选择基础数据集:研究人员选择了四个广泛使用的VL数据集作为基础,这些数据集包含了多样化的图像和场景。
-
重新标注图像:为了捕捉图像中的空间关系,研究人员对这些图像进行了重新标注。他们使用先进的语言模型生成描述,这些描述详细地表达了图像中的空间布局。
-
生成描述:新的描述使用了一系列空间词汇,如“left”(左边)、“right”(右边)、“above”(上方)、“below”(下方)等,以及描述相对大小的词汇,如“large”(大)和“small”(小)。
-
确保多样性:为了确保数据集的多样性,研究人员从不同的数据集中选取图像,包括室内场景、户外景观、物体集合等。
-
评估与验证:生成的描述经过了自动化和人工的评估,以确保它们在描述空间关系方面的准确性和可靠性。
假设场景一只猫坐在垫子上,垫子在房间的角落里。
- 传统描述:可能只是简单地说,“A cat is on a mat.”(一只猫在垫子上。)
- SPRIGHT描述:会明确空间关系,如 “A cat is sitting on a mat located in the corner of the room.”(一只猫坐在房间角落里的垫子上。)
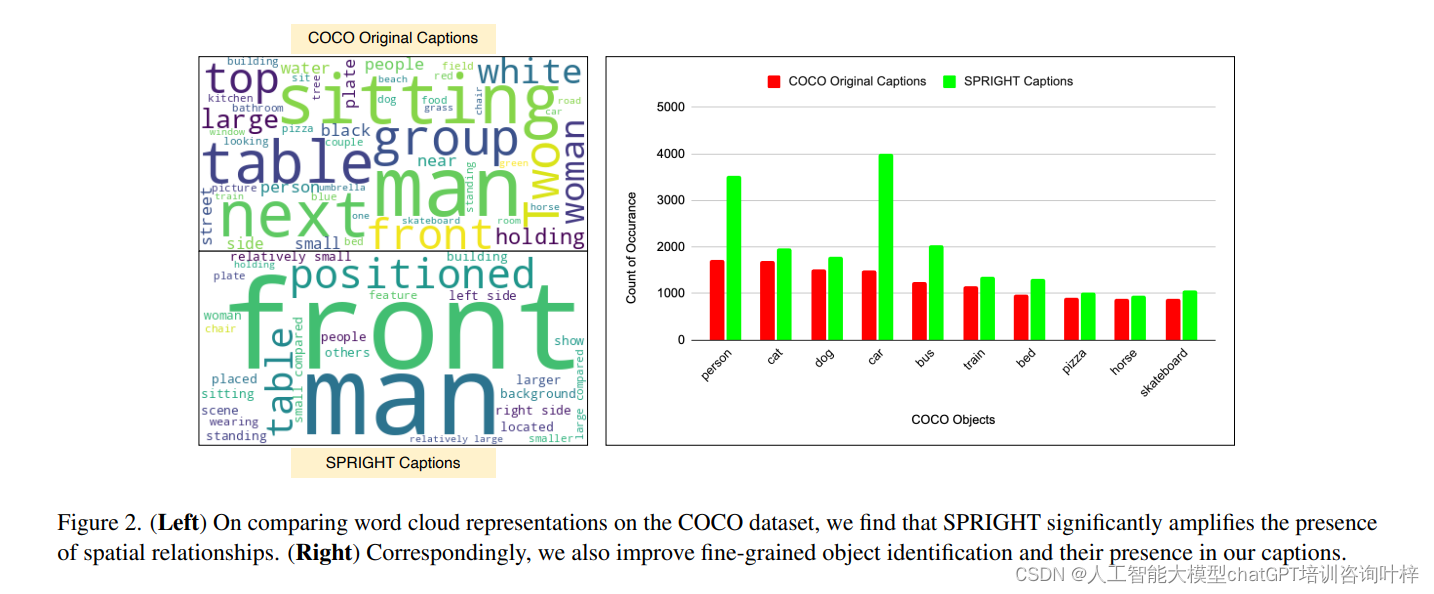
通过这种方式,SPRIGHT数据集为研究人员提供了一个强大的工具,用于训练和评估T2I模型,特别是在生成具有精确空间关系的图像方面。这不仅提高了模型的性能,还推动了对空间关系在视觉-语言任务中作用的更深入理解。
研究人员从四个广泛使用的VL数据集中选取了约600万张图像作为基础,这些数据集包含了多样化的场景和对象。
为了生成新的图像描述,研究人员采用了先进的语言模型,例如LLaVA-1.5-13B。LLaVA(Large Language-Vision Artificial intelligence Agent)是一个大型的多模态模型,能够理解和生成文本,同时处理视觉信息。
利用LLaVA模型,研究人员生成了新的图像描述,这些描述专注于图像中的空间关系。这一过程涉及以下几个关键步骤:
-
定义提示(Prompting):为语言模型提供明确的指示,要求其生成包含特定空间关系的描述。例如,提示可能要求模型使用“left/right”、“above/below”、“front/behind”等词汇。
-
模型生成描述:LLaVA模型接收图像和提示,生成描述图像的文本。这些描述特别强调物体的相对位置和大小,如“一个球在盒子的左边”,“一只猫坐在垫子的上方”,“树在房子的后面”。
-
描述的多样性:为了捕获不同的空间关系,研究人员可能使用了多个不同的提示,以产生多样化的描述。
经过评估和可能的迭代优化后,研究人员得到了一组高质量的、具有空间关注点的图像描述。这些描述被用来构建SPRIGHT数据集,它包含了原始图像和它们对应的、关注空间关系的文本描述。
训练技术的创新:利用SPRIGHT数据集提升空间一致性
SPRIGHT数据集的应用
在文本到图像(T2I)模型的训练中,精确的空间描述对于模型学习如何将文本提示转换为具有相应空间布局的图像至关重要。传统的数据集往往忽略了这一点,而SPRIGHT数据集正是为了填补这一空白而创建的。
SPRIGHT数据集的特点在于其描述中对空间关系的细致表达,这些描述不仅包含基本的空间词汇,如“left/right”(左/右)、“above/below”(上/下)、“front/behind”(前/后),还可能包括对物体相对大小的描述,如“large”(大)和“small”(小),以及其他描述物体间关系的词汇。
应用SPRIGHT数据集的训练技术如下:
-
数据集的整合:将SPRIGHT数据集与模型的训练过程紧密结合,确保模型在训练时能够接触到大量包含丰富空间信息的样本。
-
描述的生成:使用高级语言模型,如LLaVA-1.5-13B,生成包含空间词汇的描述。这些描述不仅指出了物体的位置,还描述了它们之间的相对位置和大小关系。
-
模型训练:在训练T2I模型时,将这些描述作为输入,模型需要学习如何根据这些描述生成图像。训练过程中,模型会逐渐学会将文本中的空间词汇与图像中的视觉元素相匹配。
-
空间关系的捕捉:通过在SPRIGHT数据集上的训练,模型能够更好地理解和捕捉文本描述中的空间关系,从而在生成图像时重现这些关系。
-
性能提升:由于SPRIGHT数据集中的描述被设计为强调空间关系,因此使用该数据集训练的模型在生成具有精确空间布局的图像方面表现出色。
-
多样性和复杂性:SPRIGHT数据集的多样性和复杂性促使模型学习到更广泛和更细微的空间关系,这在传统的数据集上是难以实现的。
SPRIGHT数据集的应用显著提升了T2I模型在空间一致性方面的表现。通过在包含精确空间描述的数据集上进行训练,模型能够更好地理解和生成具有复杂空间关系的图像,这对于各种视觉-语言任务来说是一个重要的进步。

训练技术的核心创新
- 对象数量的考量:
研究人员意识到,图像中对象的数量直接影响到空间关系的复杂性。因此,他们采取了一种有针对性的方法来选择训练数据。具体来说,他们筛选出那些包含多个对象的图像,因为这些图像提供了更多的空间关系来让模型学习。例如,一个包含多个物体的房间场景将比一个只有单一物体的简单背景提供更多的空间关系信息。
在实际操作中,研究人员可能使用了图像标注模型或对象检测算法来识别图像中的对象数量,并将这些图像分为不同的组。然后,他们可能采用了分层训练策略,首先在对象数量较少的图像上训练模型,逐渐过渡到对象数量更多的图像,以此来逐步提升模型的空间推理能力。
- 空间描述的多样性:
除了考虑对象数量外,研究人员还深入研究了空间描述的多样性对模型性能的影响。他们认识到,不同长度和类型的空间描述可能会对模型的学习能力产生不同的影响。为了探索这一点,研究人员可能设计了多种类型的描述,包括:
简短描述:只包含最基本的空间关系信息,例如“猫在垫子上”。
详细描述:提供更丰富的空间细节,如“猫坐在房间角落里的垫子上,垫子在桌子的左边”。
复杂描述:可能包含多个空间关系和更复杂的语言表达,例如“猫坐在垫子上,垫子在房间的角落里,而房间的另一边有一张桌子,桌子上方挂着一盏灯”。
实验结果
-
基准方法的改进:
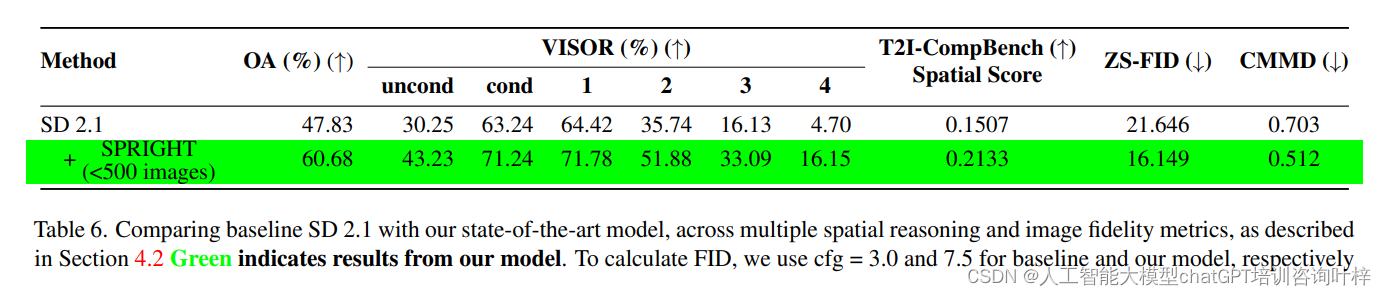
- 通过在少量SPRIGHT数据(约0.25%)上微调,模型在生成空间一致图像方面取得了22%的性能提升。
- 在T2I-CompBench基准测试中,使用SPRIGHT数据集微调的模型在空间分数、FID(Fréchet Inception Distance)和CMMD(Complementary Maximum Mean Discrepancy)得分上均取得了显著改进。
-
高效训练方法:
- 通过在包含大量对象的图像上进行微调,研究人员实现了在T2I-CompBench上的空间分数0.2133,这是通过在少于500张图像上进行微调实现的。
- 与基线模型相比,这种方法在空间关系方面取得了41%的性能提升。
-
消融研究:
- 研究人员通过改变空间描述的比例(25%、50%、75%、100%)来训练不同的模型,并发现使用50%的空间描述可以获得最佳的T2I-CompBench空间分数。
- 对于长描述和短描述的比较表明,长描述在提升空间一致性方面更为有效。
-
CLIP文本编码器的调查:
- 通过中心核对齐(Centered Kernel Alignment, CKA)度量,研究人员发现微调后的CLIP在空间描述上学习到了不同的层次表示,特别是在输出注意力投影层和多层感知机(MLP)层。
-
训练与否定:
- 在训练中引入否定表达(如“不是在...的左边”代替“在...的右边”)后,模型在处理包含否定的空间关系时表现出了一定的改进。
-
注意力图的改进:
- 通过可视化注意力相关性图,研究人员发现微调后的模型能够更好地定位和生成预期的对象,并且在空间定位上也更为准确。
实验结果表明,SPRIGHT数据集和相应的训练技术能够显著提高T2I模型在生成具有精确空间关系的图像方面的能力。这些发现不仅证明了SPRIGHT数据集的有效性,也为未来的研究提供了新的方向,特别是在探索如何进一步提升模型对复杂空间关系的理解和生成能力方面。
论文链接:https://arxiv.org/abs/2404.01197
项目地址:https://spright-t2i.github.io/
这篇关于提升文本到图像模型的空间一致性:SPRIGHT数据集与训练技术的新进展的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!








