本文主要是介绍Faster R-CNN: Towards Real-Time Object Detection with Region Proposal Networks论文笔记,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
http://blog.csdn.net/bailufeiyan/article/details/50575150(感谢大神们)
Faster R-CNN: Towards Real-Time Object Detection with Region Proposal Networks
这篇文章讲述了 Faster R-CNN,介绍了 RPN、Translation-Invariant Anchors、loss-function 等概念。实现了 RPN 网络和 Fast-RCNN 网络的融合,即,在提取 OP 的同时进行物体检测。
Abstract
依赖 op 的 object detection 网络取得了目前最优的性能。SPPnet 和 Fast RCNN 网络,都降低了检测时间,同时,OP 也成为了计算瓶颈。在本文的工作中,介绍了 Region proposal Network(RPN),可以得到 cost-free 的 op。RPN 网络是全卷积网络,同时预测出 object 的 边界以及 object 的分数。*RPN 可以端到端的生成高质量的 OP,之后使用 Fast-RCNN 进行检 测。使用简单的交替优化,RPN 和 Fast R-CNN 可以分享卷积特征。使用 VGG-16 网络,检测 系统使用 GPU 可以达到 5fps,同时,每张图像仅仅使用 300 个 op,*在 PASCAL VOC2007 数 据集 map73.2%,2012 的数据集上 map 为 70.4%,都取得了目前最好的性能。
内容整理
Faster R-CNN 可以看做是对 Fast R-CNN 的进一步加速,可以快速获得 proposal。一般 的做法都是利用显著性目标检测(如 Selective search)过一遍待检测图,得到 proposal。基 于区域的深度卷积网络虽然使用了 GPU 进行加速,但是 op 的提取却都是在 CPU 上实现 的,这就大大地拖慢了整个系统的速度。然后作者提出,卷积后的特征图也可以用来生成 regionproposals 的。通过增加两个卷积层来实现 RegionProposalNetworks(RPNs), 其中一 个用于编码每一个卷积,将其生成低维特征;另一个,对于每一个卷积输出分数和边界(分 数是 2k 个,包含了 object 和 non-object 两个分数)。
Region Proposal Networks
RPNs 从任意尺寸的图片中得到一系列的带有分数的objectproposals。具体流程是:使 用一个小的网络在最后卷积得到的特征图上进行滑动扫描,这个滑动的网络每次与特征图上 n*n 的窗口全连接(这里 n=3),然后映射到一个低维向量,例如 256D 或 512D, 最后将这个
低维向量送入到两个全连接层,即 box 回归层(box-regression layer (reg))和 box 分类层(box- regression layer (reg))。
RPNs 是全卷积网络,为了与 Fast R-CNN 共享卷积,作者给出了一种简单的训练方法:通 过交替优化来学习共享的特征,主要有 4 步:1. 使用前面的方法训练一个 RPN。用 ImageNet 的 model 初始化,然后针对 region proposal task 进行微调。2. 利用第一步得到 的 proposals 使用 Fast R-CNN 来训练另一一个单独的 detection network, 到这里两个网 络还是分开的,没有 share conv layers 。3. 利用第二部训练好的 detection network 来初始 化 RPN , 然后训练,这里训练的时候固定 conv layers ,只微调 RPN 那一部分的网络 层。4. 再固定 conv layers ,只微调 Fast R-CNN 的 fc 层。也就是交替微调 rpn 和 fast- rcnn 网络。
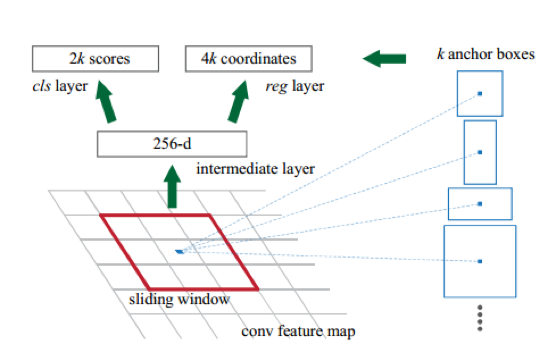
Translation-Invariant Anchors
在每一个滑动窗口,可以预测出 k 的 proposal,对应着是 4k 个坐标(x,y,w,h)以 及 2k 个分数(object/not-object)。这里引入了 anchor(锚点),我理解的是,为了保证平移 不变性,需要确定锚点(这里好像是窗口中心),之后以锚点为中心进行多个尺度、宽高比
的采样。如上图右边,文中使用了 3 个尺度( 128, 256, and 512)以及 3 个比例(1:1,1:2,2:1), 也就是这里 k 为 9。
A Loss Function for Learning Region Proposals
为了训练网络,作者使用二分类的标签(0,1)。只有符合以下两点才被认为是正样本: 与 ground-truth box 有最高的 IoU 或与任意一个 ground-truth box 的 IoU 大于 0.7 的 anchor。如果与所有 ground-truth box 的 IoU 都小于 0.3 的 anchor 都标为 negative label。 其余非正非负的被丢掉。
对于每一个 anchor box i, 其 loss function 定义为:
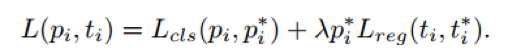
其中,pi 是预测其是一个 object 的 probability ,当其 label 为 positive 时,pi为 1,否则为0。ti={tx,ty,tw,th}是预测的 boundingbox, ti是与这个 anchor 相对应的 ground-truth box 。 classification loss Lcls 是一个二分类(是或者不是 object)的 softmax loss 。
Optimization
使用 back-propagation and stochastic gradient descent (SGD) 对这个 RPN 进行训练,每 张图片随机采样了 256 个 anchors , 这里作者认为如果使用所有的 anchors 来训练的话,会 使得负样本占据主要地位。所以这里作者将采样的正负比例为 1:1. 新增的两层使用高斯来 初始化,其余使用 ImageNet 的 model 初始化。
Experiment
在 FasterRCNN 中,OP 的个数大大减少,在网络 forward 的过程中,一张图像只生成约 300 个 OP 的框,同时由于 OP 在网络中通过 GPU 生成,计算的时间约 10ms,Cost 非常小,常规方法主要是通过 CPU 计算,耗时都在 500MS 以上
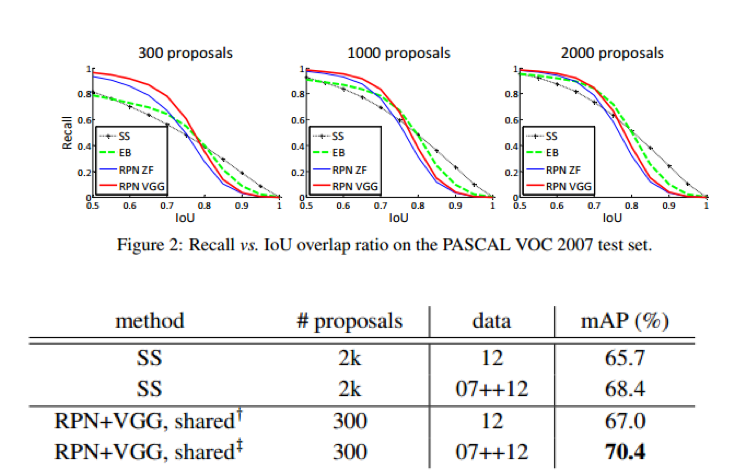
FasterRCNN 的 RPN 网络中,其实单纯的 RPN 网络对于 OP 指标的提升并不明显,但是 将 OP 融入到网络中去是其最大的亮点,同时可以达到实时,在 OP 的性能提升上相比较传 统的方法大约提高 1.5 个百分点
思考与讨论
- 这篇文章的主要贡献是,实现了 OP 提取和检测的卷积数据共享,做到了 OP cost-free, 并且,只使用 300 个 OP 就可以达到很好的性能,在这里 OP 性能提升了 1.5 个点,检测提 升了 8 个点。
- 在训练时,RPN 网络在 PASCAL VOC 上 op 的 ground-truth,是使用 selective search 方法获取的 op,将其作为 GT 是否合适?
- 另一方面,加入 RPN 网络,训练时间明显增加,fast-rcnn 只需要进行 40000 次迭代, 使用 faster-rcnn,在四个阶段分别进行 RCN 网络 80000 次迭代,fast-rcnn 网络 40000 次迭 代,RCN 80000 次迭代,fast-rcnn40000 次迭代。
这篇关于Faster R-CNN: Towards Real-Time Object Detection with Region Proposal Networks论文笔记的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!


