本文主要是介绍邻域注意力Transformer,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
邻域注意力(NA),这是第一个高效且可扩展的视觉滑动窗口注意力机制,NA是一种逐像素操作,将自注意力(SA)定位到最近的相邻像素,因此与SA的二次复杂度相比,具有线性时间和空间复杂度。与Swin Transformer的窗口自注意力不同,滑动窗口模式允许NA的感受野增长,而无需额外的像素移位,并保留平移等变性。
Neighborhood Attention Transformer可以自适应地将接收域定位到每个token周围的一个邻域,在不需要额外操作的情况下引入局部归纳偏差;而Swin Transformer则通过Window Self Attention和Shifted Window Self Attention两种自注意力,通过像素移位实现两种划分并降低计算复杂度。
NAT(Neighborhood Attention Transformer)是基于NA的新型分层Transformer设计,提高图像分类性能。在视觉范围内,token的数量通常与图像分辨率呈线性相关。因此,较高的图像分辨率会导致严格使用SA的模型的复杂性和内存使用量呈二次方增加。二次复杂度使得此类模型无法轻松应用于下游视觉任务,例如对象检测和分割,其中图像分辨率通常比分类大得多。
独立自注意力
独立自注意力(SASA)是基于局部窗口的视觉注意力的最早应用之一,其中每个像素关注其周围的一个窗口,其显式滑动窗口模式与相同卷积的模式相同,周围有零填充和简单的二维光栅扫描,因此保持平移等变性。
在计算机图形学中,二维光栅扫描算法主要用于将二维图像转换成三维模型,以便在三维空间中进行处理和分析。
平移等变性是指模型对输入数据的平移不敏感,即无论输入数据如何平移,模型的输出都保持不变。这是卷积神经网络(CNNs)的一个关键属性,而SASA通过其局部注意力机制也保持了这一属性。
随着邻域大小的增加,NA 也接近 SA,并且在最大邻域时相当于 SA。
方法描述
邻域注意力(NA):一种简单而灵活的显式滑动窗口注意力机制,将每个像素的注意力范围定位到其最近邻域,随着其范围的增长而接近自注意力,并保持平移等变性。
单个像素的邻域注意力 (NA) 与自注意力 (SA) 的查询键值结构图如下所示

相关工作
自注意力
将缩放点积注意力定义为对查询和一组键值对的操作;
其中d是嵌入维度(输入向量维度)。
自注意力将点积注意力应用于与查询和键值对相同的输入的线性投影。多头注意力在不同的嵌入上多次应用点积注意力,从而形成注意力头。
给定输入,其中n是token数量,d是嵌入维度,该操作的复杂度为
;注意力权重的空间复杂度为
。
Vision Transformer
Dosovitskiy 等人提出了一种基于 Transformer 的图像分类器,仅由 Transformer 编码器和图像标记器组成,称为 Vision Transformer (ViT)
DETR探索了用于目标检测的CNN-Transformer混合体。另一方面,ViT提出了一种仅依赖于单个非重叠卷积层(修补和嵌入)的模型。
数据高效图像转换器(DeiT)模型通过使用先进的增强和训练技术,以最小的架构变化推动 ViT 取得进展。
局部自注意力
独立自注意力(SASA)是最早的滑动窗口自注意力模式之一,旨在取代现有 CNN 中的卷积。它的操作类似于零填充的卷积,并通过跨过特征图来提取键值对。
Liu等人引入了窗口和移位窗口(Swin)注意力作为基于非滑动窗口的自注意力机制,该机制对特征图进行分区并将自注意力分别应用于每个分区。
Swin Transformer产生金字塔的特征图,减少空间维度,同时增加深度。
HaloNet
通过用新的块注意力模式取代它来避免SASA的速度问题。虽然这种变化放宽了平移等变性,但它可以提供速度和内存的合理权衡。
这种模式将输入序列划分为多个块(blocks),并且每个块只关注它自己的块以及相邻的几个块。通过这种方式,每个块只需要计算与其相邻块的注意力权重,而不是整个序列。这大大降低了计算复杂性,并且使得 HaloNet 能够有效地处理长序列。
HaloNet的注意力机制由三个阶段组成:块、haloing和注意力。输入特征图被分为不重叠的子集,这些子集将用作查询。接下来,提取“haloing”相邻块,将其用作键和值。然后将注意力应用于提取的查询和键值对。
HaloNet相比于SASA可以有效降低成本,并且提高性能,特别是与网络中的卷积层结合使用时。
卷积基线
Liu等人提出了一种受Swin等模型影响的新CNN架构,称为ConvNeXt。这些模型不是基于注意力的,并且在不同的视觉任务中都表现优于 Swin。
Neighborhood Attention
将感受野定位到每个查询周围的窗口,因此不需要额外的技术,例如Swin使用的循环移位。此外,Neighborhood Attention保持平移等差性,Neighborhood Attention 可以比 Swin 等方法运行得更快,同时使用更少的内存。我们引入了一种具有这种注意力机制的分层变压器模型,称为 Neighborhood Attention Transformer。
方法
邻域注意力,考虑视觉数据结构的自注意力的本地化。与自注意力相比,不仅降低了计算成本,而且还引入了局部归纳偏差,类似于卷积。
NAT采用多层级联设计,类似于Swin,意味着特征图在不同层级之间进行下采样,而不是一次全部下采样。与Swin不同,NAT使用重叠卷积来对特征图进行下采样,而不是非重叠卷积。
- NAT使用了一个多层级联设计,这与Swin相似。这种设计意味着特征图(feature maps)在不同的层级之间进行了下采样(downsampling),而不是一次性完成所有下采样。
- 在深度学习中,多层级联设计通常用于捕获不同尺度的信息。较低层级的特征图包含更多的细粒度信息,而较高层级的特征图则包含更多的粗粒度或全局信息。
- 重叠的卷积意味着卷积核在特征图上移动时,相邻的卷积操作会有部分重叠。这通常可以增加模型的表达能力,因为它允许模型捕捉更多的局部和全局信息。
- 归纳偏置是机器学习中的一个概念,它指的是模型在学习过程中自动获取的一些有用的假设或约束。这些偏置可以帮助模型更好地泛化到未见过的数据。
Neighborhood Attention
Swin 的 WSA(Window Self Attention) 可以被认为是现有最快的限制自我注意力的方法之一,其目的是降低二次注意力成本。它只是简单地对输入进行分区,并将自注意力分别应用于每个分区。
SWSA会移位这些分区线以允许窗口外交互。对于扩大感受野来说至关重要。然而,局部限制自注意力的最直接方法是允许每个像素关注其相邻像素,这导致大多数像素周围有一个动态移位的窗口,扩大了感受野,因此不需要手动移位。
与Swin不同且类似于卷积,这种受限自注意力的动态形式可以保留平移等差性。
给定输入,它是一个矩阵,其一行是 d 维标记向量,以及X的线性投影Q,K和V以及相对位置偏差
;我们定义注意力权重对于领域大小为 k 的第 i 个输入,
作为第 i 个输入的查询投影与其 k 个最近邻键的点积。

其中表示 i 的第 j 个最近邻。然后,我们将邻近值
定义为一个矩阵,其行是第 i 个输入的 k个最近邻值投影。

邻域大小为 k 的第 i 个标记的邻域注意力

其中是缩放参数,对特征图中的每个像素重复此操作。
随着k的增长,接近自注意力权重,
接近
本身。因此邻域注意力接近自注意力。每个像素都关注其周围的窗口,并在输入周围进行填充以处理边缘情况,正是由于这种差异,随着窗口大小的增加,NA逐渐接近自注意力,但由于输入周围的零填充,在SASA(独立自注意力)中并不适用。
平铺领域注意力和NATTEN(Neighborhood Attention Extension)
以像素方式限制自注意力,被认为是一种成本高昂的操作,需要较低级别的重新实现。因为自注意力本身被分解为矩阵乘法,这是一种可以在加速器上轻松并行化的操作,并且为计算软件中的不同用例定义了无数高效的算法(LAPACK、cuBLAS、CUTLASS)
由于像素级结构NA以及NA中邻域定义的新颖性,使用这些平台实现NA的唯一方法是堆叠许多低效操作来提取邻域,将它们存储为中间张量,然后计算注意力。这会导致操作速度明显变慢,并且内存使用量呈指数级增长。
NATTEN包括半精度支持、对1D和2D数据的支持以及与PyTorch的autograd兼容集成。
用户可以简单地将NA作为PyTorch模块导入并将其集成到现有管道中。
平铺NA算法:通过将不重叠的查询平铺加载到共享内存中去计算邻域注意力权重,以最大程度地减少全局内存读取。与简单的实现相比,平铺NA可以将延迟降低一个数量级。
Neighborhood Attention Transformer
NAT使用两个连续的3*3卷积(步幅为2)的嵌入输入,从而产生输入大小的输出。这类似于使用补丁和具有
补丁的嵌入层,但它利用重叠卷积来引入有用的归纳偏差。使用重叠卷积会增加成本,并且两个卷积会产生更多参数。然而,我们通过重新配置模型来处理这个问题,从而实现更好的权衡。
NAT 由 4 个级别组成,每个级别后面都有一个下采样器(最后一个除外)。
下采样器将空间大小减少一半,同时通道数量增加一倍。我们使用步长为 2 × 2 的 3 × 3 卷积,而不是 Swin 使用的 2 × 2 非重叠卷积(补丁合并)。
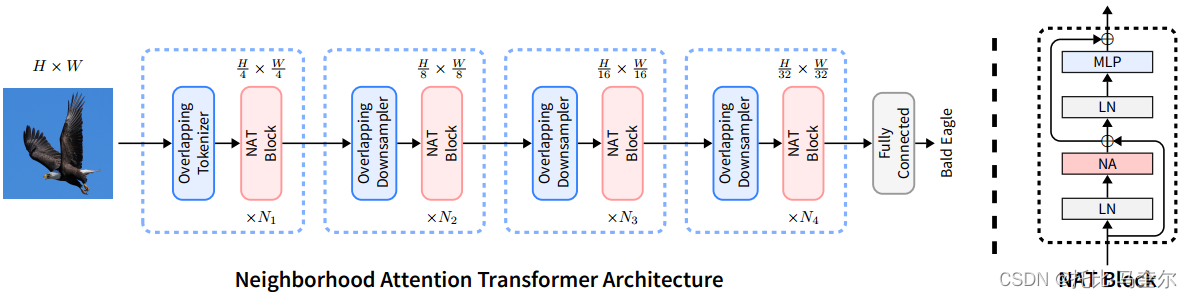
“Overlapping Tokenizer” 指的是一种分词器(Tokenizer)的设计方法,它在将文本切分为词或标记(tokens)时,允许词与词之间有重叠的部分。这与传统的分词器不同,传统的分词器通常会将文本切分为不重叠的词或标记。
复杂性分析
给定形状为 h × w × d 的输入特征图,其中 d 是通道数,h 和 w 分别是特征图的高度和宽度。
深度学习中的FLOPs是指模型中的浮点运算操作总数
QKV的线性变换的浮点运算次数是 FLOPs;
SA(自注意力)计算复杂度与输入大小的平方成正比,因为计算注意力权重和输出的浮点运算总数是 FLOPs;并且注意力权重的形状为
;
Swin的WSA(基于窗口的自注意力机制)将查询、键、值划分为个形状为
的窗口,然后对每个窗口应用自注意力,即
FLOPs。由于其注意力权重的形状为
,WSA的内存消耗为
。
在NA中,的大小为
,计算它的成本为
。
的形状为
,对其应用注意力权重的成本为
。内存使用量为
。
这篇关于邻域注意力Transformer的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!






