本文主要是介绍Neighbourhood Consensus Networks,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
原因是选择一个特定匹配的步骤对于所有可能的特征集是不可微的。此外,在特征重复的情况下,将匹配分配给第一个最近邻可能导致不正确的匹配,在这种情况下,硬分配将丢失关于随后最近邻的有价值信息。这也是经典的匹配难题
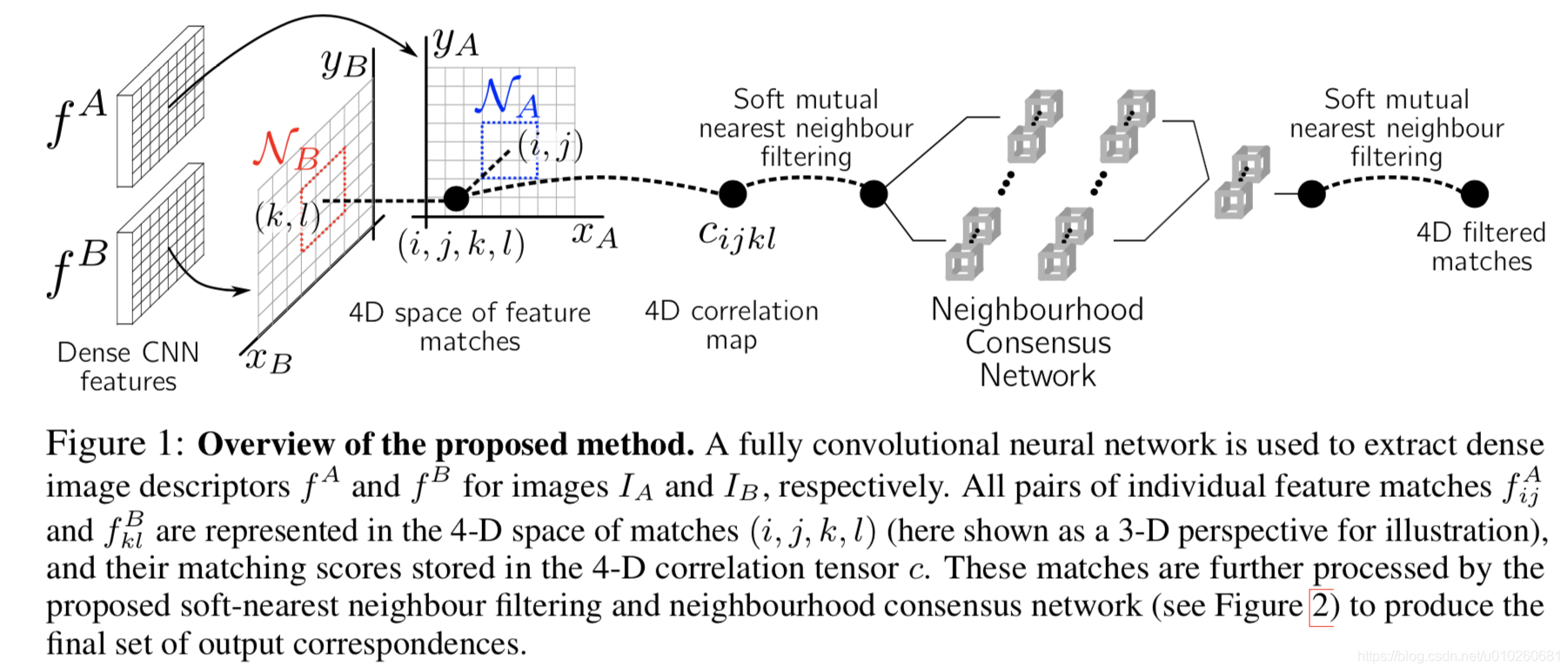
首先计算dense feature: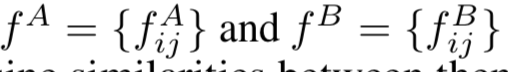
然后计算两两之间的相似性: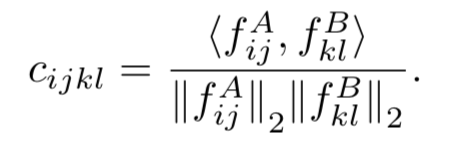 -》构造一个四维度的tensor,这样存储有一个好处是可以方便计算邻域信息
-》构造一个四维度的tensor,这样存储有一个好处是可以方便计算邻域信息
输入的大小是固定的h*w。在这里有两个先验:1>正确的匹配具有一定的一致性2>正确匹配的周围匹配相互支持(邻域一致性)
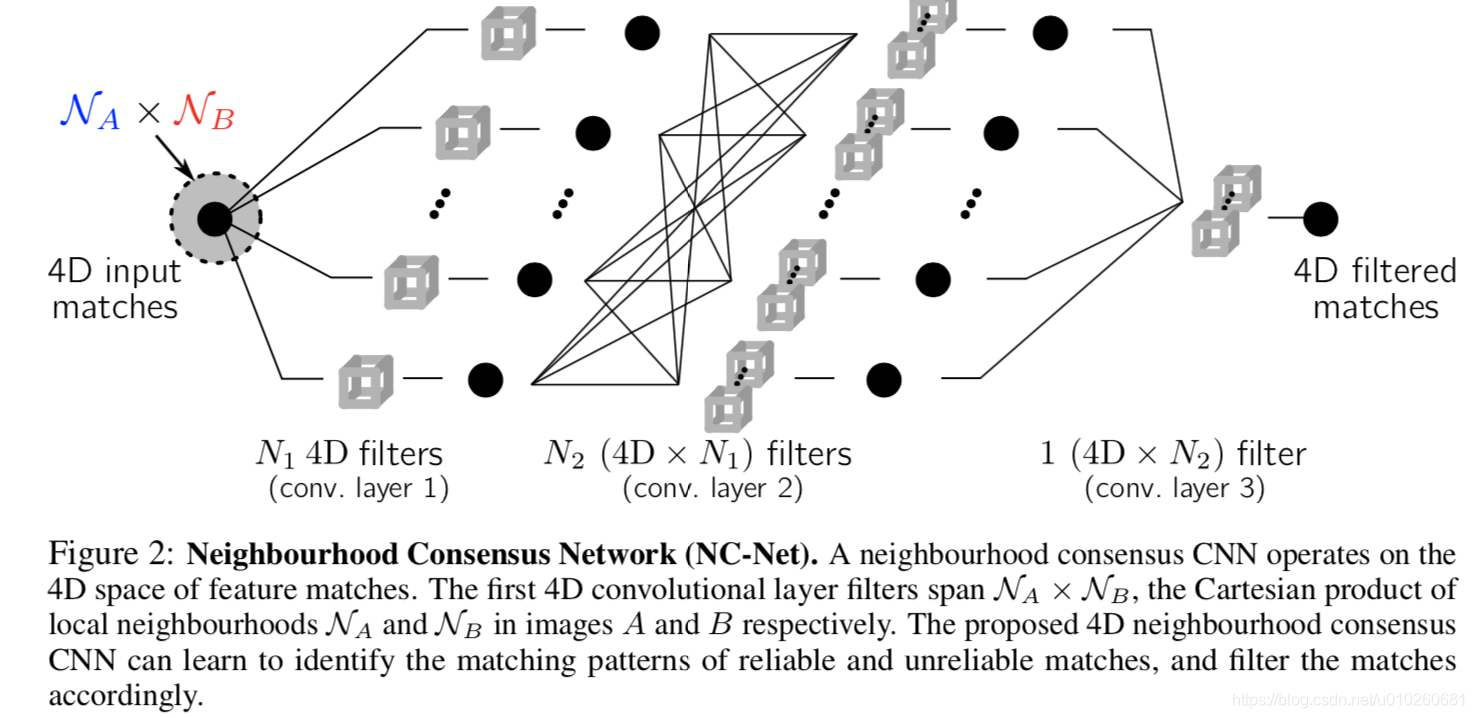
4D-CNN,使用cnn模版可以考虑到局部邻域信息,
尽管提议的邻里共识网络可以基于邻里的支持证据(即在半本地级别)抑制和放大匹配,但它不能对匹配实施全局约束,例如相互匹配,其中匹配的特征要求是相互最近的邻里
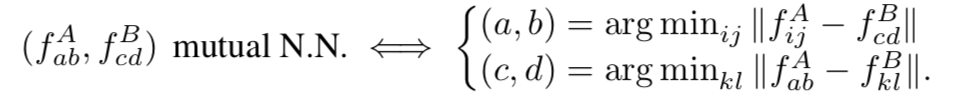
通过施加上述所表示的硬相互最近邻条件来过滤匹配将消除绝大多数候选匹配,这使得它不适合用于端到端可训练方法,因为这种硬决策是不可微的。
因此,我们提出了一种更软的互最近邻滤波(M(·))方法,它既具有更软的决策意义,又具有更好的可微性,可以应用于稠密的四维匹配:

因为每个图像上都存在(x y)特征,因此Cijkl的每一层都表示图像A中的(i,j)和图像B中的每一个k,l的匹配score,因此可以使用raio 增大feature距离最近的匹配,抑制feature 距离相对教远的匹配
这篇关于Neighbourhood Consensus Networks的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!








