本文主要是介绍GaussianBody:基于3D高斯散射的服装人体重建,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
GaussianBody: Clothed Human Reconstruction via 3d Gaussian Splatting
GaussianBody:基于3D高斯散射的服装人体重建
李梦田 1,2,3 、姚胜祥 1 、谢志峰 1,3, 2 、陈科宇 4, 5#、姜玉刚 2
1Shanghai University, 2Fudan University
1 上海大学 2 复旦大学
3Shanghai Engineering Research Center of Motion Picture Special Effects
3 上海电影特效工程研究中心
4Tavus Inc. Tavus Inc.
{mtli,yaosx033,zhifeng_xie}@shu.edu.cn, keyu@tavus.dev, ygj@fudan.edu.cn
{mtli,yaosx033,zhifeng_xie}@ shu.edu.cn,www.example.com,www.example.com
Abstract 摘要 GaussianBody: Clothed Human Reconstruction via 3d Gaussian Splatting
In this work, we propose a novel clothed human reconstruction method called GaussianBody, based on 3D Gaussian Splatting. Compared with the costly neural radiance-based models, 3D Gaussian Splatting has recently demonstrated great performance in terms of training time and rendering quality. However, applying the static 3D Gaussian Splatting model to the dynamic human reconstruction problem is non-trivial due to complicated non-rigid deformations and rich cloth details. To address these challenges, our method considers explicit pose-guided deformation to associate dynamic Gaussians across the canonical space and the observation space, introducing a physically-based prior with regularized transformations helps mitigate ambiguity between the two spaces. During the training process, we further propose a pose refinement strategy to update the pose regression for compensating the inaccurate initial estimation and a split-with-scale mechanism to enhance the density of regressed point clouds. The experiments validate that our method can achieve state-of-the-art photorealistic novel-view rendering results with high-quality details for dynamic clothed human bodies, along with explicit geometry reconstruction.
在这项工作中,我们提出了一种新的服装人体重建方法称为GaussianBody,基于3D高斯溅射。与昂贵的基于神经辐射的模型相比,3D高斯溅射最近在训练时间和渲染质量方面表现出了出色的性能。然而,由于复杂的非刚性变形和丰富的布料细节,将静态3D高斯溅射模型应用于动态人体重建问题并非易事。为了解决这些挑战,我们的方法考虑了显式的姿势引导变形,以关联规范空间和观察空间中的动态高斯,引入基于物理的先验和正则化变换,有助于减轻两个空间之间的模糊性。在训练过程中,我们进一步提出了一种姿态细化策略来更新姿态回归,以补偿不准确的初始估计,并提出了一种尺度分裂机制来提高回归点云的密度。 实验结果表明,该方法能够在沿着显式几何重建的同时,对动态的穿着人体获得具有高质量细节的真实感新视点绘制效果。
![[Uncaptioned image]](https://img-blog.csdnimg.cn/img_convert/078007e1d90551f4313c9025cf85b98d.jpeg)
Figure 1:GaussianBody takes monocular RGB video as input, reconstructing a clothed human model from 1080×1080 images in around 1 hour on a single 4090 GPU. The resulting human model serves as a tool for simulating human performance in novel views. Furthermore, we offer the point cloud as a mechanism for deformation control.
图1:GaussianBody采用单目RGB视频作为输入,在单个4090 GPU上在大约1小时内从1080 × 1080个图像重建一个穿着衣服的人体模型。由此产生的人体模型作为一种工具,用于模拟人类的表现在新的观点。此外,我们提供点云作为变形控制的机制。
1Introduction 一、导言
Creating high-fidelity clothed human models holds significant applications in virtual reality, telepresence, and movie production. Traditional methods involve either complex capture systems or tedious manual work from 3D artists, making them time-consuming and expensive, thus limiting scalability for novice users. Recently, there has been a growing focus on automatically reconstructing clothed human models from single RGB images or monocular videos.
创建高保真穿着人体模型在虚拟现实,远程呈现和电影制作中具有重要的应用。传统方法涉及复杂的捕获系统或3D艺术家繁琐的手工工作,这使得它们既耗时又昂贵,从而限制了新手用户的可扩展性。最近,人们越来越关注从单个RGB图像或单目视频自动重建穿着衣服的人体模型。
Mesh-based methods [1, 2, 3, 4] are initially introduced to recover human body shapes by regressing on parametric models such as SCAPE [5], SMPL [6], SMPL-X [7], and STAR [8]. While they can achieve fast and robust reconstruction, the regressed polygon meshes struggle to capture variant geometric details and rich clothing features. The addition of vertex offsets becomes an enhancement solution [9, 10] in this context. However, its representation ability is still strictly constrained by mesh resolutions and generally fails in loose-cloth cases.
最初引入基于网格的方法[1,2,3,4],通过对SCAPE [5],SMPL [6],SMPL-X [7]和星星[8]等参数模型进行回归来恢复人体形状。虽然它们可以实现快速和鲁棒的重建,但回归的多边形网格很难捕获变化的几何细节和丰富的服装特征。在这种情况下,顶点偏移的添加成为增强解决方案[9,10]。然而,它的表示能力仍然受到网格分辨率的严格限制,并且通常在松散布的情况下失败。
To overcome the limitations of explicit mesh models, implicit methods based on occupancy fields [11, 12], signed distance fields (SDF) [13], and neural radiance fields (NeRFs) [14, 15, 16, 17, 18, 19, 20, 21] have been developed to learn the clothed human body using volume rendering techniques. These methods are capable of enhancing the reconstruction fidelity and rendering quality of 3D clothed humans, advancing the realistic modeling of geometry and appearance. Despite performance improvements, implicit models still face challenges due to the complex volume rendering process, resulting in long training times and hindering interactive rendering for real-time applications. Most importantly, native implicit approaches lack an efficient deformation scheme to handle complicated body movements in dynamic sequences [18, 19, 20, 21].
为了克服显式网格模型的局限性,已经开发了基于占用场[11,12]、符号距离场(SDF)[13]和神经辐射场(NeRF)[14,15,16,17,18,19,20,21]的隐式方法,以使用体绘制技术来学习穿着衣服的人体。这些方法能够提高三维服装人体的重建逼真度和渲染质量,推进几何和外观的真实感建模。尽管性能有所提高,但由于复杂的体绘制过程,隐式模型仍然面临挑战,导致训练时间长,阻碍了实时应用的交互式绘制。最重要的是,原生隐式方法缺乏有效的变形方案来处理动态序列中的复杂身体运动[18,19,20,21]。
Therefore, combining explicit geometry primitives with implicit models has become a trending idea in recent works. For instance, point-based NeRFs [22, 23] propose controlling volume-based representations with point cloud proxy. Unfortunately, estimating an accurate point cloud from multi-view images is practically challenging as well due to the intrinsic difficulties of the multi-view stereo (MVS) problem.
因此,将显式几何图元与隐式模型相结合已成为近年来研究的一个趋势。例如,基于点的NeRF [22,23]提出使用点云代理控制基于体积的表示。不幸的是,估计一个准确的点云从多视图图像实际上是具有挑战性的,以及由于多视图立体(MVS)问题的内在困难。
In this work, we address the mentioned issues by incorporating 3D Gaussian Splatting (3D-GS) [24] into the dynamic clothed human reconstruction framework. 3D-GS establishes a differential rendering pipeline to facilitate scene modeling, notably reducing a significant amount of training time. It learns the explicit point-based model while rendering high-quality results with spherical harmonics (SH) representation. The application of 3D-GS to present 4D scenes has demonstrated superior results [25, 26, 27], motivating our endeavor to integrate 3D-GS into human body reconstruction. However, learning dynamic clothed body reconstruction is more challenging than other use cases, primarily due to non-rigid deformations of body parts and the need to capture accurate details of the human body and clothing, especially for loose outfits like skirts.
在这项工作中,我们通过将3D高斯飞溅(3D-GS)[24]纳入动态穿衣人体重建框架来解决上述问题。3D-GS建立了一个差分渲染管道来促进场景建模,显著减少了大量的训练时间。它学习显式的基于点的模型,同时使用球面谐波(SH)表示渲染高质量的结果。3D-GS应用于呈现4D场景已经证明了上级结果[25,26,27],激励我们奋进将3D-GS集成到人体重建中。然而,学习动态穿衣身体重建比其他用例更具挑战性,主要是由于身体部位的非刚性变形以及需要捕捉人体和衣服的准确细节,特别是对于裙子等宽松服装。
Firstly, we extended the 3D-GS representation to clothed human reconstruction by utilizing an articulated human model for guidance. Specifically, we use forward linear blend skinning (LBS) to deform the Gaussians from the canonical space to each observation space per frame. Secondly, we optimize a physically-based prior for the Gaussians in the observation space to mitigate the risk of overfitting Gaussian parameters. We transform the local rigidity loss [28] to regularize over-rotation across the canonical and observation space. Finally, we propose a split-with-scale strategy to enhance point cloud density and a pose refinement approach to address the texture blurring issue.
首先,我们扩展了3D-GS表示的服装人体重建,利用关节的人模型的指导。具体来说,我们使用前向线性混合蒙皮(LBS)将高斯从规范空间变形到每帧的每个观察空间。其次,我们优化了观测空间中高斯的基于物理的先验,以减轻过拟合高斯参数的风险。我们将局部刚性损失[28]转化为正则化正则和观测空间中的过度旋转。最后,我们提出了一个分裂与规模的战略,以提高点云密度和姿势细化的方法来解决纹理模糊的问题。
We evaluate our proposed framework on monocular videos of dynamic clothed humans. By comparing it with baseline approaches and other works, our method achieves superior reconstruction quality in rendering details and geometry recovery, while requiring much less training time (approximately one hour) and almost real-time rendering speed. We also conduct ablation studies to validate the effectiveness of each component in our method.
我们评估我们提出的框架上的动态穿着人类的单眼视频。通过与基线方法和其他工作的比较,我们的方法实现了上级重建质量的渲染细节和几何恢复,同时需要更少的训练时间(约一个小时)和几乎实时的渲染速度。我们还进行消融研究,以验证我们方法中每个组件的有效性。
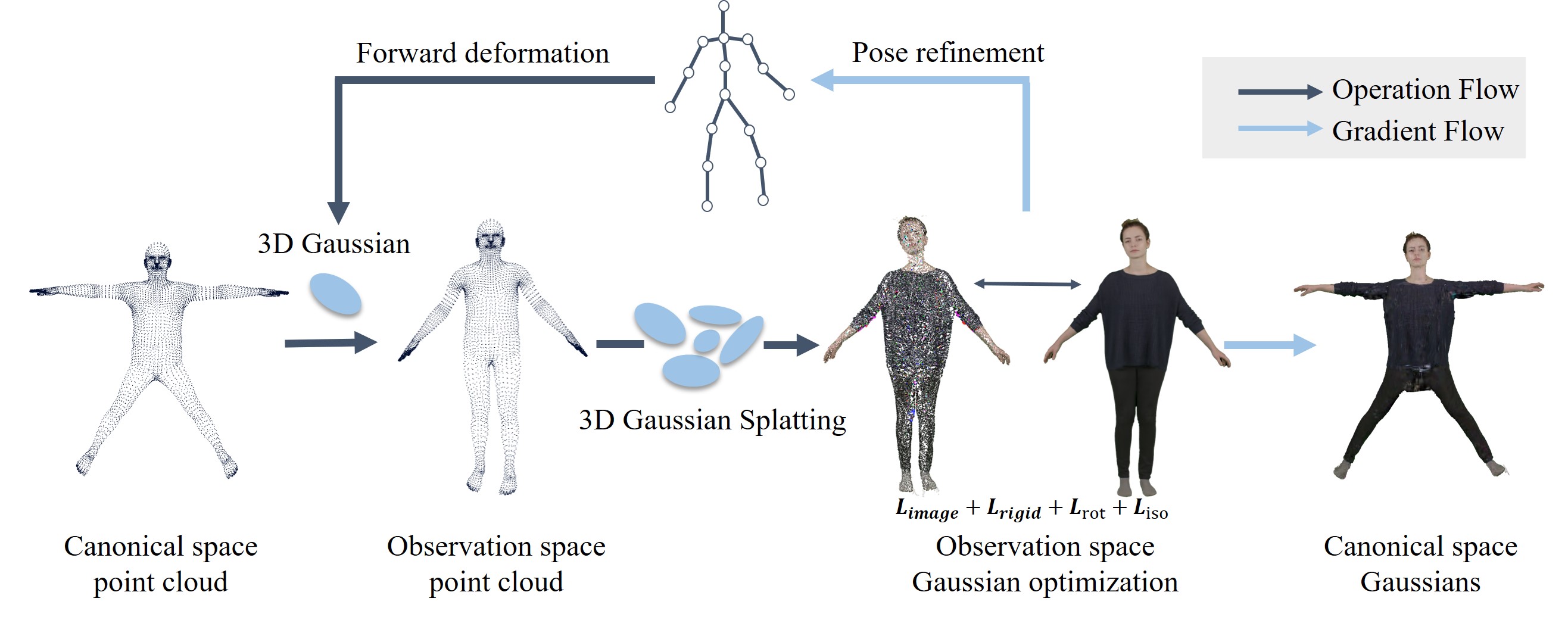
Figure 2:Overview of our pipeline. We initialize the point cloud using SMPL vertices, deforming the position and rotation parameters of Gaussians through SMPL forward linear blend skinning (LBS) to transform them into the observation space. The canonical model is then optimized, taking into account the physically-based prior ℒ𝑟𝑖𝑔𝑖𝑑,ℒ𝑟𝑜𝑡,ℒ𝑖𝑠𝑜. To address image blurriness, we optimize the pose parameters. The output includes both the point cloud and the appearance of the reconstructed human.
图2:我们的管道概述。我们使用SMPL顶点初始化点云,通过SMPL前向线性混合蒙皮(LBS)变形高斯的位置和旋转参数,将它们转换到观察空间。然后,考虑到基于物理的先验 ℒ𝑟𝑖𝑔𝑖𝑑,ℒ𝑟𝑜𝑡,ℒ𝑖𝑠𝑜 ,对规范模型进行优化。为了解决图像模糊问题,我们优化了姿态参数。输出包括点云和重建的人的外观。
2Related Work 2相关工作
In this section, we briefly review the related literature with 3D clothed human reconstruction.
在本节中,我们简要回顾了与三维服装人体重建相关的文献。
2.13D Human Reconstruction
2.13D人体重建
Reconstructing 3D humans from images or videos is a challenging task. Recent works [29, 10, 9] use template mesh models like SMPL [6] to reconstruct 3D humans from monocular videos or single images. However, template mesh models have limitations in capturing intricate clothing details. To address these limitations, neural representations have been introduced [11, 12, 30] for 3D human reconstruction. Implicit representations, like those used in PIFU [11] and its variants, achieve impressive results in handling complex details such as hairstyle and clothing. Some methods, like ICON [13] and ECON [31], leverage SMPL as a prior to handle extreme poses. However, most of these methods are designed for static scenes and struggle with dynamic scenarios. Other methods [32, 33, 34] use parametric models to handle dynamic scenes and obtain animatable 3D human models.
从图像或视频重建3D人体是一项具有挑战性的任务。最近的作品[29,10,9]使用模板网格模型,如SMPL [6],从单眼视频或单个图像重建3D人体。然而,模板网格模型在捕捉复杂的服装细节方面有局限性。为了解决这些限制,已经引入了神经表示[11,12,30]用于3D人体重建。隐式表示,如PIFU [11]及其变体中使用的那些,在处理发型和服装等复杂细节方面取得了令人印象深刻的结果。一些方法,如ICON [13]和ECON [31],利用SMPL作为处理极端姿势的优先级。然而,这些方法中的大多数是为静态场景设计的,并且难以处理动态场景。其他方法[32,33,34]使用参数模型来处理动态场景并获得可动画化的3D人体模型。
Recent advancements involve using neural networks for representing dynamic human models. Extensions of NeRF [14] into dynamic scenes [35, 36, 37] and methods for animatable 3D human models in multi-view scenarios [21, 38, 39, 19, 20, 18] or monocular videos [40, 15, 16, 17] have shown promising results. Signal Distance Function (SDF) is also employed [41, 42, 43] to establish a differentiable rendering framework or use NeRF-based volume rendering to estimate the surface. Our method enhances both speed and robustness by incorporating 3D-GS [24].
最近的进展涉及使用神经网络来表示动态人体模型。NeRF [14]扩展到动态场景[35,36,37]和多视图场景[21,38,39,19,20,18]或单目视频[40,15,16,17]中的动画3D人体模型的方法已经显示出有希望的结果。还采用信号距离函数(SDF)[41,42,43]来建立可微分渲染框架或使用基于NeRF的体渲染来估计表面。我们的方法通过结合3D-GS提高了速度和鲁棒性[24]。
2.2Accelerating Neural Rendering
2.2加速神经渲染
Several methods [44, 45, 46, 47] focus on accelerating rendering speed, primarily using explicit representations or baking methods. However, these approaches are tailored for static scenes. Some works [48, 49] aim to accelerate rendering in dynamic scenes, but they often require dense input images or additional geometry priors. InstantAvatar [17], based on instant-NGP [50], combines grid skip rendering and a quick deformation method [51] but relies on accurate pose guidance for articulate weighting training. In contrast, 3D-GS [24] offers fast convergence and easy integration into graphics rendering pipelines, providing a point cloud for explicit deformation. Our method extends 3D-GS for human reconstruction, achieving high-quality results and fast rendering.
有几种方法[44,45,46,47]专注于加速渲染速度,主要使用显式表示或烘焙方法。然而,这些方法是为静态场景定制的。一些作品[48,49]旨在加速动态场景中的渲染,但它们通常需要密集的输入图像或额外的几何先验。InstantAvatar [17]基于instant-NGP [50],结合了网格跳过渲染和快速变形方法[51],但依赖于精确的姿势指导来进行关节加权训练。相比之下,3D-GS [24]提供快速收敛和轻松集成到图形渲染管道中,为显式变形提供点云。我们的方法扩展了3D-GS用于人体重建,实现了高质量的结果和快速渲染。
3GaussianBody
In this section, we first introduce the preliminary method 3D-GS [24] in Section 3.1. Next, we describe our framework pipeline for 3D-GS-based clothed body reconstruction (Section 3.2). We then discuss the application of a physically-based prior to regularize the 3D Gaussians across the canonical and observation spaces (Section 3.3). Finally, we introduce two strategies, split-with-scale and pose refinement, to enhance point cloud density and optimize the SMPL parameters, respectively (Section 3.4).
在本节中,我们首先在第3.1节中介绍初步方法3D-GS [24]。接下来,我们描述了基于3D-GS的穿衣身体重建的框架管道(第3.2节)。然后,我们讨论了基于物理的先验在正则化3D高斯分布时的应用(第3.3节)。最后,我们引入了两种策略,即尺度分割和姿态细化,分别用于增强点云密度和优化SMPL参数(第3.4节)。
3.1Preliminary
3D-GS [24] is an explicit 3D scene reconstruction method designed for multi-view images. The static model comprises a list of Gaussians with a point cloud at its center. Gaussians are defined by a covariance matrix Σ and a center point 𝑋, representing the mean value of the Gaussian:
3D-GS [24]是为多视图图像设计的显式3D场景重建方法。静态模型包括一个高斯列表,其中心是一个点云。高斯由协方差矩阵 Σ 和中心点 𝑋 定义,表示高斯的平均值:
| 𝐺(𝑋)=𝑒−12𝑋𝑇Σ−1𝑋. | (1) |
For differentiable optimization, the covariance matrix Σ can be decomposed into a scaling matrix 𝑆 and a rotation matrix 𝑅:
对于可微优化,协方差矩阵 Σ 可以被分解为缩放矩阵 𝑆 和旋转矩阵 𝑅 :
| Σ=𝑅𝑆𝑆𝑇𝑅𝑇, | (2) |
The gradient flow computation during training is detailed in [24]. To render the scene, the regressed Gaussians can be projected into camera space with the covariance matrix Σ′:
训练过程中的梯度流计算详见[24]。为了渲染场景,可以将回归的高斯投影到具有协方差矩阵 Σ′ 的相机空间中:
| Σ′=𝐽𝑊Σ𝑊𝑇𝐽𝑇, | (3) |
Here, 𝐽 is the Jacobian of the affine approximation of the projective transformation, and 𝑊 is the world-to-camera matrix. To simplify the expression, the matrices 𝑅 and 𝑆 are preserved as rotation parameter 𝑟 and scaling parameter 𝑠. After projecting the 3D Gaussians to 2D, the alpha-blending rendering based on point clouds bears a resemblance to the volumetric rendering equation of NeRF [14] in terms of its formulation. During volume rendering, each Gaussian is defined by an opacity 𝛼 and spherical harmonics coefficients 𝑐 to represent the color. The volumetric rendering equation for each pixel contributed by Gaussians is given by:
这里, 𝐽 是投影变换的仿射近似的雅可比矩阵, 𝑊 是世界到相机矩阵。为了简化表达式,矩阵 𝑅 和 𝑆 被保留为旋转参数 𝑟 和缩放参数 𝑠 。在将3D高斯投影到2D之后,基于点云的alpha混合渲染在其公式方面与NeRF [14]的体积渲染方程相似。在体绘制期间,每个高斯由不透明度 𝛼 和球谐系数 𝑐 定义以表示颜色。由高斯贡献的每个像素的体积渲染方程由下式给出:
| 𝐶=∑𝑖∈𝐍𝑐𝑖𝛼𝑖, | (4) |
Collectively, the 3D Gaussians are denoted as 𝐺(𝑥,𝑟,𝑠,𝛼,𝑐).
总体上,3D高斯表示为 𝐺(𝑥,𝑟,𝑠,𝛼,𝑐) 。
3.2Framework
In our framework, we decompose the dynamic clothed human modeling problem into the canonical space and the motion space. First, We define the template 3D Gaussians in the canonical space as 𝐺(𝑥¯,𝑟¯,𝑠¯,𝛼¯,𝑐¯). To learn the template 3D Gaussians, we employ pose-guidance deformation fields to transform them into the observation space and render the scene using differentiable rendering. The gradients of the pose transformation are recorded for each time and used for backward optimization in the canonical space.
在我们的框架中,我们将动态服装人体建模问题分解到规范空间和运动空间。首先,我们定义模板3D高斯在规范空间为 𝐺(𝑥¯,𝑟¯,𝑠¯,𝛼¯,𝑐¯) 。为了学习模板3D高斯,我们采用姿势指导变形场将它们转换到观察空间,并使用可微分渲染渲染场景。姿态变换的梯度每次被记录,并用于规范空间中的向后优化。
Specifically, we utilize the parametric body model SMPL [6] as pose guidance. The articulated SMPL model 𝑀(𝛽,𝜃) is defined with pose parameters 𝜃∈𝑅3𝑛𝑘+3 and shape parameters 𝛽∈𝑅10. The transformation of each point is calculated with the skinning weight field 𝑤(𝛽) and the target bone transformation 𝐵(𝜃)={𝐵1(𝜃),…,𝐵𝑛(𝜃)}. To mitigate computational costs, we adopt the approach from InstantAvatar [17], which diffuses the skinning weight of the SMPL [6] model vertex into a voxel grid. The weight of each point is then obtained through trilinear interpolation from the grid weighting, denoted as 𝑤(𝑥¯),𝛽. The transformation of the canonical points to deform space via forward linear blend skinning is expressed as:
具体来说,我们利用参数化身体模型SMPL [6]作为姿势指导。用姿态参数 𝜃∈𝑅3𝑛𝑘+3 和形状参数 𝛽∈𝑅10 来定义铰接SMPL模型 𝑀(𝛽,𝜃) 。使用蒙皮权重字段 𝑤(𝛽) 和目标骨骼变换 𝐵(𝜃)={𝐵1(𝜃),…,𝐵𝑛(𝜃)} 计算每个点的变换。为了降低计算成本,我们采用了InstantAvatar [17]的方法,该方法将SMPL [6]模型顶点的蒙皮权重扩散到体素网格中。然后通过三线性插值从网格加权获得每个点的权重,表示为 𝑤(𝑥¯),𝛽 。通过前向线性混合蒙皮将规范点变换为变形空间表示为:
| 𝒟(𝑥¯,𝜃,𝛽)=∑𝑖=1𝑛𝑤𝑖(𝑥¯,𝛽)𝐵𝑖(𝜃). | (5) |
With the requirements of the 3D-GS[24] initial setting, we initialize the point cloud with the template SMPL[6] model vertex in the canonical pose(as shown in Figure.2). For each frame, we deform the position 𝑥¯ and rotation 𝑟¯ of the canonical Gaussians 𝐺(𝑥¯,𝑟¯,𝑠¯,𝛼¯,𝑐¯) with the pose parameter 𝜃𝑡 of current frame and the global shape parameter 𝛽 to the observation space :
根据3D-GS[24]初始设置的要求,我们使用模板SMPL[6]模型顶点以规范姿势初始化点云(如图2所示)。对于每个帧,我们将具有当前帧的姿态参数 𝜃𝑡 和全局形状参数 𝛽 的规范高斯 𝐺(𝑥¯,𝑟¯,𝑠¯,𝛼¯,𝑐¯) 的位置 𝑥¯ 和旋转 𝑟¯ 变形到观察空间:
| 𝑥=𝒟(𝑥¯,𝜃𝑡,𝛽)𝑥¯,𝑟=𝒟(𝑥¯,𝜃𝑡,𝛽)𝑟¯ | (6) |
where 𝒟 is the deformation function defined in Eq.5.
其中 𝒟 是在等式5中定义的变形函数。
In this way, we obtain the deformed Gaussians in the observation space. After differentiable rendering and image loss calculation, the gradients will be passed through the inverse of the deformation field 𝒟 and optimized for the canonical Gaussians.
这样,我们就得到了观测空间中的变形高斯分布。在可微分渲染和图像损失计算之后,梯度将通过变形场 𝒟 的逆并针对规范高斯进行优化。
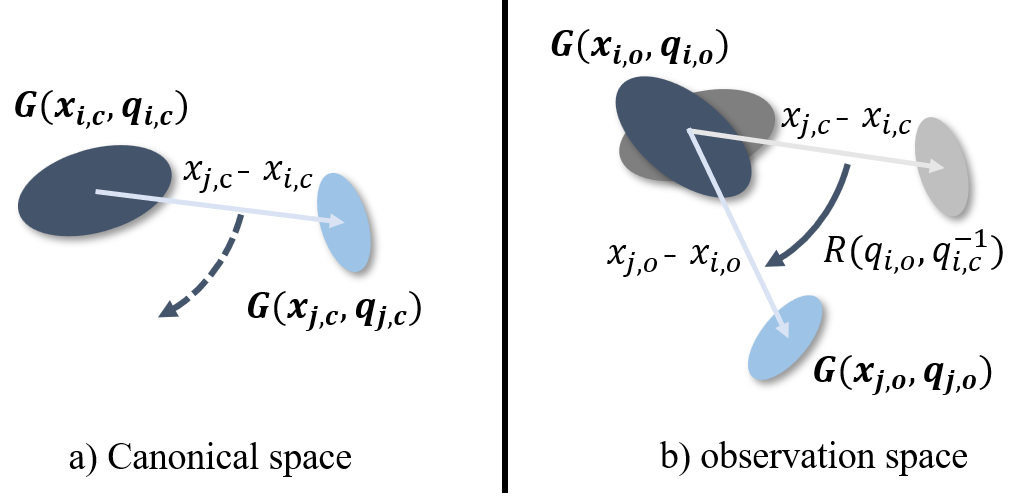
Figure 3:Local-rigidity loss. With the Gaussians 𝑖 rotating between the two spaces, the neighbour Gaussians 𝑗 should move to follow the rigid-transform in the coordinate system of Gaussians 𝑖
图3:局部刚度损失。随着高斯 𝑖 在两个空间之间旋转,相邻的高斯 𝑗 应该移动以遵循高斯 𝑖 的坐标系中的刚性变换
3.3Physically-Based Prior
3.3基于物理的先验
Although we define the canonical Gaussians and explicitly deform them to the observation space for differentiable rendering, the optimization is still an ill-posed problem because there could be multiple canonical positions mapped to the same observation position, leading to overfitting in the observation space and visual artifacts in the canonical space. In the experiment, we also observed that this optimization approach might easily result in the novel view synthesis showcasing numerous Gaussians in incorrect rotations, consequently generating unexpected glitches. Thus we follow [28] to regularize the movement of 3D Gaussians by their local information. Particularly we employ three regularization losses to maintain the local geometry property of the deformed 3D Gaussians, including local-rigidity loss ℒ𝑟𝑖𝑔𝑖𝑑, local-rotation loss ℒ𝑟𝑜𝑡 losses and a local-isometry loss ℒ𝑖𝑠𝑜. Different from [28] that attempts to track the Gaussians frame by frame, we regularize the Gaussian transformation from the canonical space to the observation space.
虽然我们定义了规范高斯并将其显式变形到观察空间以进行可微渲染,但优化仍然是一个不适定问题,因为可能有多个规范位置映射到同一个观察位置,导致观察空间中的过拟合和规范空间中的视觉伪影。在实验中,我们还观察到,这种优化方法可能很容易导致新的视图合成显示许多高斯在不正确的旋转,从而产生意想不到的毛刺。因此,我们遵循[28]通过局部信息来正则化3D高斯的运动。特别地,我们采用三种正则化损失来保持变形的3D高斯的局部几何性质,包括局部刚性损失 ℒ𝑟𝑖𝑔𝑖𝑑 、局部旋转损失 ℒ𝑟𝑜𝑡 损失和局部等距损失 ℒ𝑖𝑠𝑜 。 与[28]试图逐帧跟踪高斯不同,我们将高斯变换从正则空间正则化到观察空间。
Given the set of Gaussians 𝑗 with the k-nearest-neighbors of 𝑖 in canonical space (k=20), the isotropic weighting factor between the nearby Gaussians is calculated as:
给定正则空间(k = 20)中具有 𝑖 的k个最近邻的高斯集合 𝑗 ,相邻高斯之间的各向同性加权因子被计算为:
| 𝑤𝑖,𝑗=𝑒𝑥𝑝(−𝜆𝑤‖𝑥𝑗,𝑐−𝑥𝑖,𝑐‖22), | (7) |
where ‖𝑥𝑗,𝑐−𝑥𝑖,𝑐‖ is the distance between the Gasussians 𝑖 and Gasussians 𝑗 in canonical space, set 𝜆𝑤=2000 that gives a standard deviation. Such weight ensures that rigidity loss is enforced locally and still allows global non-rigid reconstruction. The local rigidity loss is defined as:
其中 ‖𝑥𝑗,𝑐−𝑥𝑖,𝑐‖ 是规范空间中Gasussians 𝑖 和Gasussians 𝑗 之间的距离,集合 𝜆𝑤=2000 给出标准差。这样的权重确保刚性损失被局部地实施,并且仍然允许全局非刚性重建。局部刚度损失定义为:
| ℒ𝑖,𝑗𝑟𝑖𝑔𝑖𝑑=𝑤𝑖,𝑗‖(𝑥𝑗,𝑜−𝑥𝑖,𝑜−𝑅𝑖,𝑜𝑅𝑖,𝑐−1(𝑥𝑗,𝑐−𝑥𝑖,𝑐))‖2, | (8) |
| ℒ𝑟𝑖𝑔𝑖𝑑=1𝑘|𝒮|∑𝑖∈𝒮∑𝑗∈𝑘𝑛𝑛𝑖;𝑘ℒ𝑖,𝑗𝑟𝑖𝑔𝑖𝑑, | (9) |
when the Gaussians 𝑖 transform from canonical space to observation space, the nearby Gaussians 𝑗 should move in a similar way that follows the rigid-body transform of the coordinate system of the Gaussians 𝑖 between two spaces. The visual explanation is shown in Figure.6.
当高斯体 𝑖 从规范空间变换到观测空间时,附近的高斯体 𝑗 应当以遵循高斯体 𝑖 的坐标系在两个空间之间的刚体变换的类似方式移动。可视化的解释如图6所示。
While the rigid loss ensures that Gaussians 𝑖 and Gaussians 𝑗 share the same rotation, the rotation loss could enhance convergence to explicitly enforce identical rotations among neighboring Gaussians in both spaces:
虽然刚性损失确保高斯 𝑖 和高斯 𝑗 共享相同的旋转,但旋转损失可以增强收敛,以在两个空间中的相邻高斯之间显式地强制相同的旋转:
| ℒ𝑟𝑜𝑡=1𝑘|𝒮|∑𝑖∈𝒮∑𝑗∈𝑘𝑛𝑛𝑖;𝑘𝑤𝑖,𝑗‖𝑞𝑗,𝑜𝑞𝑗,𝑐−1−𝑞𝑖,𝑜𝑞𝑖,𝑐−1‖2, | (10) |
where 𝑞 is the normalized Quaternion representation of each Gaussian’s rotation, the 𝑞𝑜𝑞𝑐−1 demonstrates the rotation of the Gaussians with the deformation. We use the same Gaussian pair sets and weighting function as before.
其中 𝑞 是每个高斯旋转的归一化四元数表示, 𝑞𝑜𝑞𝑐−1 演示了高斯旋转与变形。我们使用与前面相同的高斯对集和加权函数。
Finally, we use a weaker constraint than ℒ𝑟𝑖𝑔𝑖𝑑 to make two Gaussians in different space to be the same one, which only enforces the distances between their neighbors:
最后,我们使用一个比 ℒ𝑟𝑖𝑔𝑖𝑑 更弱的约束,使不同空间中的两个高斯成为同一个高斯,这只会强制它们的邻居之间的距离:
| ℒ𝑖𝑠𝑜=1𝑘|𝒮|∑𝑖∈𝒮∑𝑗∈𝑘𝑛𝑛𝑖;𝑘𝑤𝑖,𝑗{‖𝑥𝑗,𝑜−𝑥𝑖,𝑜‖2−‖𝑥𝑗,𝑐−𝑥𝑖,𝑐‖2}, | (11) |
after adding the above objectives, our objective is :
加上上述目标后,我们的目标是:
| ℒ=ℒ𝑖𝑚𝑎𝑔𝑒+𝜆𝑟𝑖𝑔𝑖𝑑ℒ𝑟𝑖𝑔𝑖𝑑+𝜆𝑟𝑜𝑡ℒ𝑟𝑜𝑡+𝜆𝑖𝑠𝑜ℒ𝑖𝑠𝑜. | (12) |
3.4Refinement Strategy 3.4细化策略
Split-with-scale. Because the monocular video input for 3D-GS [24] lacks multi-view supervision, a portion of the reconstructed point cloud (3D Gaussians) may become excessively sparse, leading to oversized Gaussians or blurring artifacts. To address this, we propose a strategy to split large Gaussians using a scale threshold 𝜖𝑠𝑐𝑎𝑙𝑒. If a Gaussian has a size 𝑠 larger than 𝜖𝑠𝑐𝑎𝑙𝑒, we decompose it into two identical Gaussians, each with half the size.
按比例分割。由于3D-GS [24]的单目视频输入缺乏多视图监督,因此重建点云(3D高斯)的一部分可能变得过于稀疏,导致过大的高斯或模糊伪影。为了解决这个问题,我们提出了一种使用尺度阈值 𝜖𝑠𝑐𝑎𝑙𝑒 来分割大高斯的策略。如果一个高斯的大小 𝑠 大于 𝜖𝑠𝑐𝑎𝑙𝑒 ,我们将其分解为两个相同的高斯,每个高斯的大小是其一半。
Pose refinement. Despite the robust performance of 3D-GS [24] in the presence of inaccurate SMPL parameters, there is a risk of generating a high-fidelity point cloud with inaccuracies. The inaccurate SMPL parameters may impact the model’s alignment with the images, leading to blurred textures. To address this issue, we propose an optimization approach for the SMPL parameters. Specifically, we designate the SMPL pose parameters 𝜃 as the optimized parameter and refine them through the optimization process, guided by the defined losses.
动作要优雅。尽管3D—GS [24]在存在不准确SMPL参数的情况下具有稳健的性能,但存在生成具有不准确性的高保真点云的风险。不准确的SMPL参数可能会影响模型与图像的对齐,导致纹理模糊。为了解决这个问题,我们提出了一种SMPL参数的优化方法。具体而言,我们将SMPL姿态参数 𝜃 指定为优化参数,并通过优化过程在定义的损失的指导下对其进行细化。
| male-3-casual | male-4-casual | female-3-casual | female-4-casual | |||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| PSNR↑ PSNR ↑ | SSIM↑ SSIM ↑ | LPIPS↓ LPIPS ↓ | PSNR↑ PSNR ↑ | SSIM↑ SSIM ↑ | LPIPS↓ LPIPS ↓ | PSNR↑ PSNR ↑ | SSIM↑ SSIM ↑ | LPIPS↓ LPIPS ↓ | PSNR↑ PSNR ↑ | SSIM↑ SSIM ↑ | LPIPS↓ LPIPS ↓ | |
| 3D-GS[24] 3D—GS [24] | 26.60 | 0.9393 | 0.082 | 24.54 | 0.9469 | 0.088 | 24.73 | 0.9297 | 0.093 | 25.74 | 0.9364 | 0.075 |
| NeuralBody[15] NeuralBody [15] | 24.94 | 0.9428 | 0.033 | 24.71 | 0.9469 | 0.042 | 23.87 | 0.9504 | 0.035 | 24.37 | 0.9451 | 0.038 |
| Anim-NeRF[16] [16]第十六话 | 29.37 | 0.9703 | 0.017 | 28.37 | 0.9605 | 0.027 | 28.91 | 0.9743 | 0.022 | 28.90 | 0.9678 | 0.017 |
| InstantAvatar[17] [17]第十七话 | 29.64 | 0.9719 | 0.019 | 28.03 | 0.9647 | 0.038 | 28.27 | 0.9723 | 0.025 | 29.58 | 0.9713 | 0.020 |
| Ours 我们 | 35.66 | 0.9753 | 0.021 | 32.65 | 0.9769 | 0.049 | 33.22 | 0.9701 | 0.037 | 31.43 | 0.9630 | 0.040 |
Table 1:Quantitative comparison of novel view synthesis on PeopleSnapshot dataset. Our approach exhibits a significant advantage in metric comparisons, showing substantial improvements in PSNR and SSIM metrics due to its superior restoration of image details.
表1:PeopleSnapshot数据集上新视图合成的定量比较。我们的方法在度量比较中表现出显着的优势,由于其对图像细节的上级恢复,PSNR和SSIM度量得到了实质性的改善。
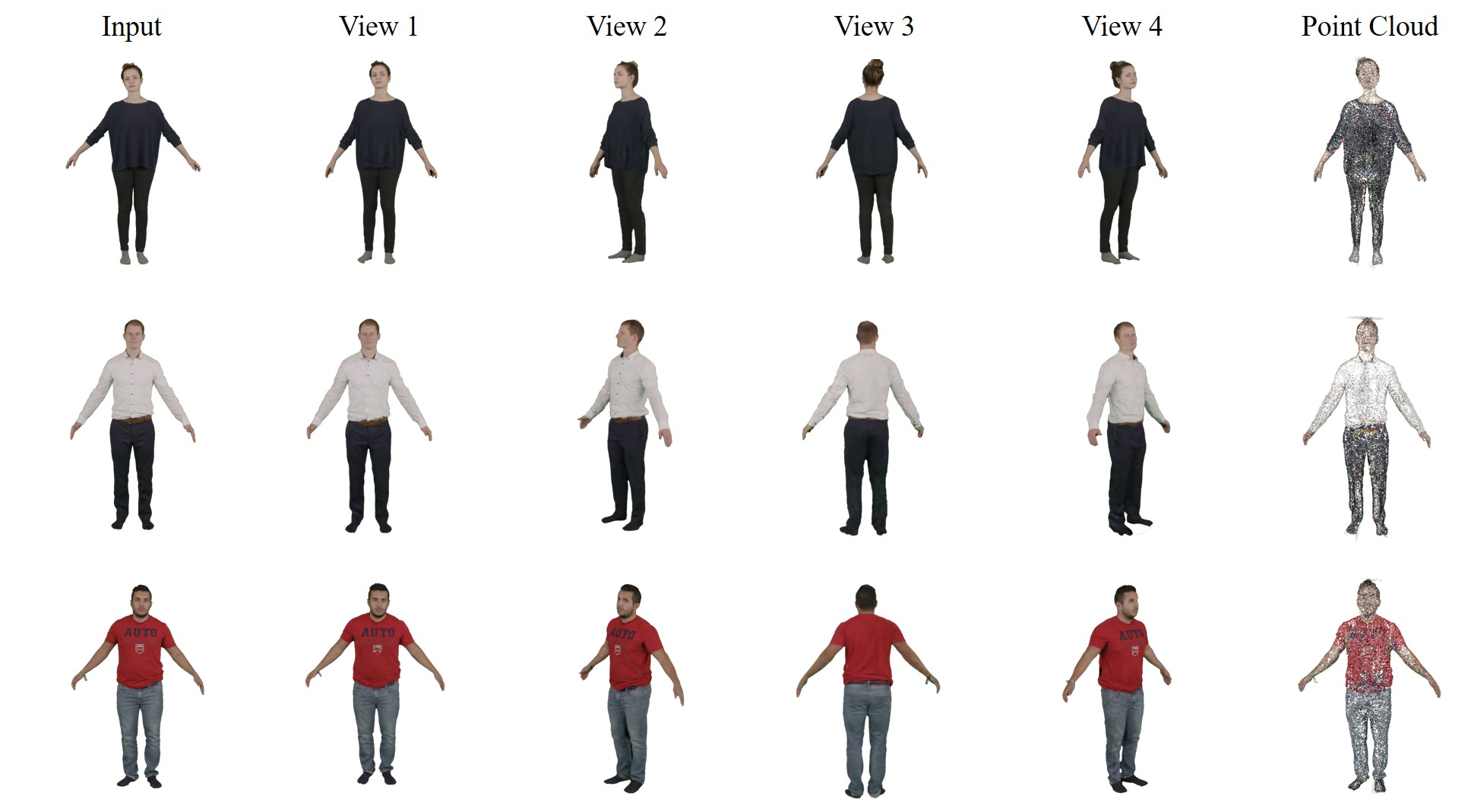
Figure 4:Results of novel view synthesis and point cloud on PeopleSnapshot [10] dataset. Our method effectively restores details on the human body, including intricate details in the hair and folds on the clothes. Moreover, the generated point cloud faithfully captures geometric details on the clothing, demonstrating a commendable separation between geometry and texture.
图4:PeopleSnapshot [10]数据集上的新视图合成和点云结果。我们的方法有效地恢复了人体的细节,包括头发和衣服上的褶皱的复杂细节。此外,生成的点云忠实地捕捉服装上的几何细节,展示了几何和纹理之间值得称赞的分离。

Figure 5:Visual comparison of different methods about novel view synthesis on PeopleSnapshot[10](column 1&2) and iPER[52](column 3&4). 3D-GS[24] rely on multi-view consistency to gain center subjection which failed to handle dynamic scenes. InstantAvatar[17] trade the quality and robust for time, might gain blur result on inaccurate parameters. Our method gains high-fidelity results, especially on the cloth texture and the robustness.
图5:PeopleSnapshot[10](列1&2)和iPER[52](列3&4)上关于新视图合成的不同方法的视觉比较。3D-GS[24]依赖于多视图一致性来获得中心从属,这无法处理动态场景。InstantAvatar[17]用质量和鲁棒性换取时间,可能会在不准确的参数上获得模糊结果。我们的方法获得了高保真的结果,特别是在布料纹理和鲁棒性。
4Experiment 4实验
In this section, we evaluate our method on monocular training videos and compare it with the other baselines and state-of-the-art works. We also conduct ablation studies to verify the effectiveness of each component in our method.
在本节中,我们将在单眼训练视频上评估我们的方法,并将其与其他基线和最先进的作品进行比较。我们还进行消融研究,以验证我们方法中每个组件的有效性。
4.1Datasets and Baseline 4.1数据集和基线
PeopleSnapshot. PeopleSnapshot [10] dataset contains eight sequences of dynamic humans wearing different outfits. The actors rotate in front of a fixed camera, maintaining an A-pose during the recording. We train the model with the frames of the human rotating in the first two circles and test with the resting frames. The dataset also provides inaccurate shape and pose parameters. So we first process both the train dataset and test dataset to get the accurate pose parameters. Note that the coefficients of the Gaussians remain fixed. We evaluate the novel view synthesis quality with frame size in 540×540 with the quantitative metrics including peak signal-to-noise ratio (PSNR), structural similarity index (SSIM), and learned perceptual image patch similarity (LPIPS), and train our model and other baselines in 1080×1080 for visual comparison. The PeopleSnapshot dataset doesn’t have the corresponding ground truth point cloud, we only provide qualitative results.
PeopleSnapshot。PeopleSnapshot [10]数据集包含八个穿着不同服装的动态人类序列。演员们在固定的摄像机前旋转,在录制过程中保持A姿势。我们用人类在前两个圆圈中旋转的帧来训练模型,并用静止的帧来测试。数据集还提供不准确的形状和姿势参数。因此,我们首先处理训练数据集和测试数据集,以获得准确的姿态参数。注意,高斯的系数保持固定。我们使用峰值信噪比(PSNR),结构相似性指数(SSIM)和学习的感知图像块相似性(LPIPS)等定量指标评估 540×540 中帧大小的新视图合成质量,并在 1080×1080 中训练我们的模型和其他基线进行视觉比较。PeopleSnapshot数据集没有相应的地面实况点云,我们只提供定性结果。
iPER. iPER [52] dataset consists of two sets of monocular RGB videos depicting humans rotating in an A-pose or engaging in random motions before a static camera. In the experiment, we leverage the A-pose series, adopting a similar setting to PeopleSnapshot. Subsequently, we visualize novel views and compare them with baselines to demonstrate the robustness of our method.
iPER。iPER [52]数据集由两组单目RGB视频组成,描述了人类在静态相机前以A姿势旋转或进行随机运动。在实验中,我们利用A-pose系列,采用与PeopleSnapshot类似的设置。随后,我们可视化新的视图,并将其与基线进行比较,以证明我们的方法的鲁棒性。
Baselines. We compare our method with original 3D-GS [24], Neural body[15], Anim-NeRF [16] and InstantAvatar [17]. Neural body[15] adopts the SMPL vertexes as the set of latent code to record the local feature and reconstruct humans in NeRF. Anim-nerf [16] uses the explicit pose-guidance deformation that deforms the query point in observation space to canonical space with inverse linear blend skinning. InstantAvatar [17] builds the hash grid to restore the feature of NeRF and control the query points with Fast-SNARF [51], which uses the root-finding way to find the corresponding points and transform it to the observation space to optimize the articulate weighting.
基线。我们将我们的方法与原始3D-GS [24],Neural body[15],Anim-NeRF [16]和InstantAvatar [17]进行了比较。Neural body[15]采用SMPL顶点作为潜在代码集,以记录局部特征并在NeRF中重建人类。Anim-nerf [16]使用显式姿势指导变形,将观察空间中的查询点变形为具有逆线性混合蒙皮的规范空间。InstantAvatar [17]构建哈希网格来恢复NeRF的特征,并使用Fast-SNARF [51]控制查询点,该方法使用寻根的方式找到对应的点并将其转换到观察空间以优化铰接权重。
4.2Implementation Details
4.2实现细节
GaussianBody is implemented in PyTorch and optimized with the Adam [53]. We optimize the full model in 30k steps following the learning rate setting of official implementation, while the learning rate of position is initial in 6𝑒−6 and the learning rate of pose parameters is 1𝑒−3. We set the hyper-parameters as 𝜆𝑟𝑖𝑔𝑖𝑑=4𝑒−2, 𝜆𝑟𝑜𝑡=4𝑒−2, 𝜆𝑖𝑠𝑜=4𝑒−2. For training the model, it takes about 1 hour on a single RTX 4090.
GaussianBody在PyTorch中实现,并使用Adam进行了优化[53]。我们按照官方实现的学习率设置,在30k步中优化了完整模型,而位置的学习率是 6𝑒−6 中的初始值,姿势参数的学习率是 1𝑒−3 。我们将超参数设置为 𝜆𝑟𝑖𝑔𝑖𝑑=4𝑒−2 、 𝜆𝑟𝑜𝑡=4𝑒−2 、 𝜆𝑖𝑠𝑜=4𝑒−2 。为了训练模型,在单个RTX 4090上大约需要1小时。
4.3Results
Novel view synthesis. In Table 1, our method consistently outperforms other approaches in various metrics, highlighting its superior performance in capturing detailed reconstructions. This indicates that our method excels in reconstructing intricate cloth textures and human body details.
新颖的视图合成。在表1中,我们的方法在各种指标上始终优于其他方法,突出了其在捕获详细重建方面的上级性能。这表明我们的方法在重建复杂的布料纹理和人体细节方面表现出色。
Figure 5 visually compares the results of our method with others. 3D-GS [24] struggles with dynamic scenes due to violations of multi-view consistency, resulting in partial and blurred reconstructions. Our method surpasses InstantAvatar in cloth texture details, such as sweater knit patterns and facial features. Even with inaccurate pose parameters on iPER [52], our method demonstrates robust results. InstantAvatar’s results, on the other hand, are less satisfactory, with inaccuracies in pose parameters leading to deformation artifacts.
图5直观地比较了我们的方法与其他方法的结果。3D-GS [24]由于违反多视图一致性而难以处理动态场景,导致部分和模糊的重建。我们的方法在布料纹理细节上优于InstantAvatar,例如毛衣针织图案和面部特征。即使iPER [52]上的姿态参数不准确,我们的方法也显示出稳健的结果。另一方面,InstantAvatar的结果不太令人满意,姿势参数的不准确导致变形伪影。
Figure 4 showcases realistic rendering results from different views, featuring individuals with diverse clothing and hairstyles. These results underscore the applicability and robustness of our method in real-world scenarios.
图4展示了来自不同视图的逼真渲染结果,展示了具有不同服装和发型的个人。这些结果强调了我们的方法在现实世界中的适用性和鲁棒性。
3D reconstruction. 三维重建。
In Figure 4, the qualitative results of our method are visually compelling. The generated point clouds exhibit sufficient details to accurately represent the human body and clothing. Examples include the organic wrinkles in the shirt, intricate facial details, and well-defined palms with distinctly separated fingers. This level of detail in the point cloud provides a solid foundation for handling non-rigid deformations of the human body more accurately.
在图4中,我们的方法的定性结果在视觉上引人注目。生成的点云显示出足够的细节,以准确地表示人体和服装。例子包括衬衫上的有机皱纹,复杂的面部细节,以及清晰的手掌和明显分开的手指。点云中的这种细节水平为更准确地处理人体的非刚性变形提供了坚实的基础。
4.4Ablation Study 4.4消融研究
Physically-based prior. 身体上的优势。
To evaluate the impact of the physically-based prior, we conducted experiments by training models with and without the inclusion of both part-specific and holistic physically-based priors. Additionally, we visualized the model in the canonical space with the specified configurations.
为了评估基于物理的先验知识的影响,我们通过训练模型进行了实验,其中包括和不包括部分特定的和整体的基于物理的先验知识。此外,我们在规范空间中可视化了具有指定配置的模型。
Figure 6 illustrates the results. In the absence of the physically-based prior, the model tends to produce numerous glitches, especially leading to blurred facial features. Specifically, the exclusion of the rigid loss contributes to facial blurring. On the other hand, without the rotational loss, the model generates fewer glitches, although artifacts may still be present. The absence of the isometric loss introduces artifacts stemming from unexpected transformations.
图6显示了结果。在没有基于物理的先验知识的情况下,模型往往会产生许多小故障,特别是导致模糊的面部特征。具体地,刚性损失的排除有助于面部模糊。另一方面,在没有旋转损失的情况下,模型生成较少的毛刺,尽管伪影可能仍然存在。没有等距损失会引入源于意外变换的伪影。
Only when incorporating all components of the physically-based prior, the appearance details are faithfully reconstructed without significant artifacts or blurring.
只有当合并基于物理的先验的所有分量时,外观细节才能被忠实地重建,而没有显著的伪影或模糊。
Pose refinement. 动作要优雅。
We utilize SMPL parameters for explicit deformation, but inaccurate SMPL estimation can lead to incorrect Gaussian parameters, resulting in blurred textures and artifacts. Therefore, we introduce pose refinement, aiming to generate more accurate pose parameters, as depicted in Figure 7. This refinement helps mitigate issues related to blurred textures caused by misalignment in the observation space and avoids the need for the deformation MLP to fine-tune in each frame, as illustrated in Figure 9.
我们利用SMPL参数进行显式变形,但不准确的SMPL估计会导致不正确的高斯参数,从而导致模糊的纹理和伪影。因此,我们引入姿态细化,旨在生成更准确的姿态参数,如图7所示。这种细化有助于缓解与由观察空间中的未对准引起的模糊纹理相关的问题,并且避免了对变形MLP在每个帧中进行微调的需要,如图9所示。
Split-with-scale. 按比例分割。
Given the divergence in our input compared to the original Gaussian input, especially the absence of part perspectives, the optimization process tends to yield a relatively sparse point cloud. This sparsity affects the representation of certain details during pose changes. As shown in Figure 8, we address this issue by enhancing point cloud density through a scaling-based splitting approach.
考虑到我们的输入与原始高斯输入相比的发散性,特别是缺少部分透视图,优化过程往往会产生相对稀疏的点云。这种稀疏性会影响姿势更改期间某些细节的表示。如图8所示,我们通过基于缩放的拆分方法增强点云密度来解决这个问题。

Figure 6:Effect of physically-based prior. This figure demonstrates what would be influenced without different losses. Each loss influences different parts of the canonical model, the rigid loss regularizes a part of the wired rotation, the rot loss mainly reduces the glitch, and the iso loss reduces the unexpected transformation.
这篇关于GaussianBody:基于3D高斯散射的服装人体重建的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!









