本文主要是介绍数据库系统期末复习III: 并发控制基础、多粒度两阶段封锁 2PL、幻读解决方案,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
并发控制的重点是三个级别的封锁,2PL 以及 MVCC。本文属于第一部分,复习除了 MVCC 之外的。
基本操作
- Commit:一旦 commit 了,就无法再 Rollback。
- Rollback:再 begin transaction 到 commit 之间使用
- Abort:和 rollback 是同一个术语。
- 一个 txn 的生命周期是从 begin txn 开始,到 commit/abort(rollback) 结束。
Conflict Searializable
- 冲突的依赖:必须是 RW、WR、WW 的依赖关系。
- Dependency Graph:画图,把 W 到 R 连一条有向边,如果有环就是不可 Conflict Searializable(conflict equivalent?)。
- 实际程序和人工都不会做这件事。
- 是可串行调度的充分条件(不是必要的)
所有问题
- 事务 ACID:原子性、一致性、隔离、持久性
- Lost Update:丢失更改。后来者 Abort 后把我的给丢失。
- Non-Repeatable read:不可重复读,中途数据被修改,不是原子性。
- Dirty-Read:读到别人的无效中间状态。未 commit、abort 数据。
- Phantom Read:指 insert 和 delete 的不可重复读。
所有解决方案
- 封锁 Locking 与 2PL
- 时间戳 Timestamp
- 乐观控制 Optimistic Scheduler
- 多版本 MVCC
封锁
- X 锁和 S 锁。
- 一级封锁:只用 X 锁。X 锁只有 commit 或 Roll back 可以释放。解决了 Lost Update,使多修改者完全互斥。
- 二级封锁:X + S。S 锁用完就能释放。解决了 dirty read,因为 S 锁取到的时候,保证了没有人半途修改中。
- 三级封锁:二级基础上,但是 S 锁要事务结束才能释放。解决了不可重复读。
- 一二三级锁无法解决幻读:,除非 insert 和 delete 的时候直接给大表上锁,基本没有并发。
- 无法解决可串行调度:一二三级封锁是针对某个修改和某个操作的锁方案。
2PL (InnoDB 把他和 MVCC 一起用)
- 2PL 基于二级封锁:现在针对一个事务内的所有操作都规定,每个事务只能有两个阶段,一个获取锁一个释放锁。grow phase 和 shrink phase。
- 三级封锁是充分的 2PL:事务结束才能释放锁,就是 strict 2PL。
- 是可串行调度的充分条件。
- Cascading Abortion:一个 Abort (后来者),中间的全部 Abort。(需要 Abort 管理器和链表数据结构)。
- 不要并发:自己再同一个互斥数据三搞出并发来然后脱裤子放屁地再用锁来同步,简直是乱来。
- Strict 2PL(三级封锁),限定只有 commit 才能释放锁。从而用锁限制了同一个数据的并发,只能支持没有数据冲突的 interleaving。
死锁:
- 你不知道你什么时候会以什么方式访问哪些数据。abort,然后 restart。
- 死锁 Abort 的价值衡量:age,已进行的 progress,锁的数量,rollback 难度,restart 了多少次(什么半途匹配)。Postgres 采用 timestamp 技术,总是杀死最老的或者最年轻的。
- 避免方法:总是杀死某些事务。
多粒度封锁
- 效率问题:如果要修改很多 tuple,实际锁的 acquiring 就很浪费时间。为了解决这个问题,提供表级锁用来方便一次获取多个的锁。轻松方便。
- 表级别锁互斥性:(SIX意思是表加 S + IX) 只需要注意这些都是表级别的锁。
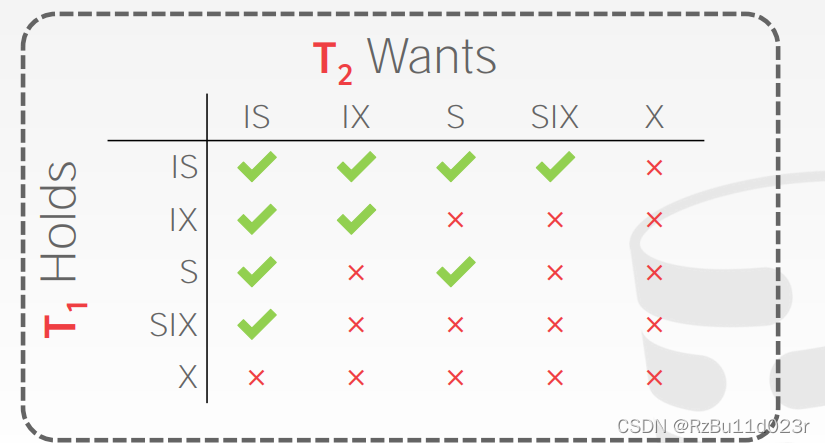
- 2PL 是悲观算法,搞到没有并行度了。
Timestamp Ordering (Nobody use this)
- 2PL缺点:前面说了 Strict 2PL 基本没有并行性。就是为了让重叠的数据完全没有并发(多核 interleaving)了。
- 2PL 缺点2:就算有了多 grained 锁机制,say that 两个事务,一个要读几百万个数据,然后对一个数据写,另一个事务读几百万个数据,其中读了那个被写的,2PL 直接让他们不用做了,直接串行调度。
- 2Pl 缺点例子:T1 grow 时候成功拿到了tuple X 锁,因此也拿了表 IX,T2 可以拿 IS 进去到了那个 tuple 之后,尝试拿 S(行级)拿不到。当然,因为 grow 阶段可以连续来,所以其实几百万不冲突的数据还是能正常读写的。say that 这个冲突的数据在双方的第一个呢?那就不行了。
- TO 顺序 Convention:如果一个 txn TS 更小,那么必须等价于他先发生,别人后发生。
- Local Copy 机制:timestamp 用的是 local copy 机制,只有这样才能保证不会互相影响。之后要解决的问题其实就是 rollback 和覆盖更新的事情了。就比如说一个中途 commit 了,那么另一个要串行,就一定要仿佛他完全发生在 commit 的那个的后面,所以他的 local copy 就会是错的。
- 比如下图:这个 interleaving 正确的前提是,他们有先后依赖关系的必须是都是 happen before 的。
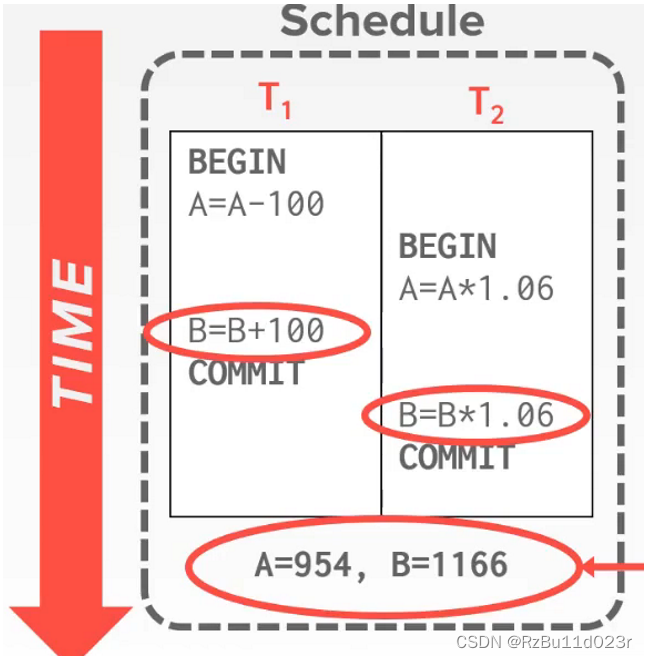
- 解决思路:如果有一个事务 commit 了,那么他的 local copy 会 reflex 到 global,此时为了防止不可重复读,一个拥有 older timestamp 的 txn 将会被 abort 掉。记录这些东西的需要一个表,表可以分 fine grained 或者 coarse grained 的,每个操作的 DB Object(say 一个 tuple 或者一整个表)都要有一个 Timestamp 表。
- 读:不能读到未来的写,TS < W-TS(X)
- 写:不能写未来的读或未来的写。
- Thomas write rule:允许未来的写存在,这样当前事务就别写,当成被未来覆盖了。
- Timestamp 没有死锁,可能有 starvation,持续新短 txn 倒挂老长 transaction
- 未 Commit:如果一个 txn 写了 Obj,那么就直接反映到全局上(不用 commit)。common sense 是 commit 了才更新 TS 啊。所以会有 unrecoverable 的问题。性能问题,ts 太麻烦了,时空都差。
乐观并发控制(OOC)
- 完全的 local copy
- Read + Validation + Write 三阶段
- 仍然是很垃圾的,没有人用。还不如 2PL。
Phantom Problem 解决方案
- Re-Execute Scans:commit 的时候检查是否发生了 Update 和 Insertion/ deletion. 太麻烦
- Predicate Locking:(从未实现) 给 select 语句加 S 锁,给 insert update delete 加 X 锁。
- Index Locking(实际用这个):如果有 index,那么 select 和 delete 都会走 index,所以直接给 index 包含那个关键字的页面加锁。如果 index 没有这个字段,锁页面禁止插入。如果没有 index,锁所有页面禁止更新,锁表禁止插入删除。算是 Coarse grained 的。
- next-key locking(InnoDB):通过 index row locking (innoDB 里面 index row 就是表行)和 gap locking。gap 是避免插入,index row 是避免修改。
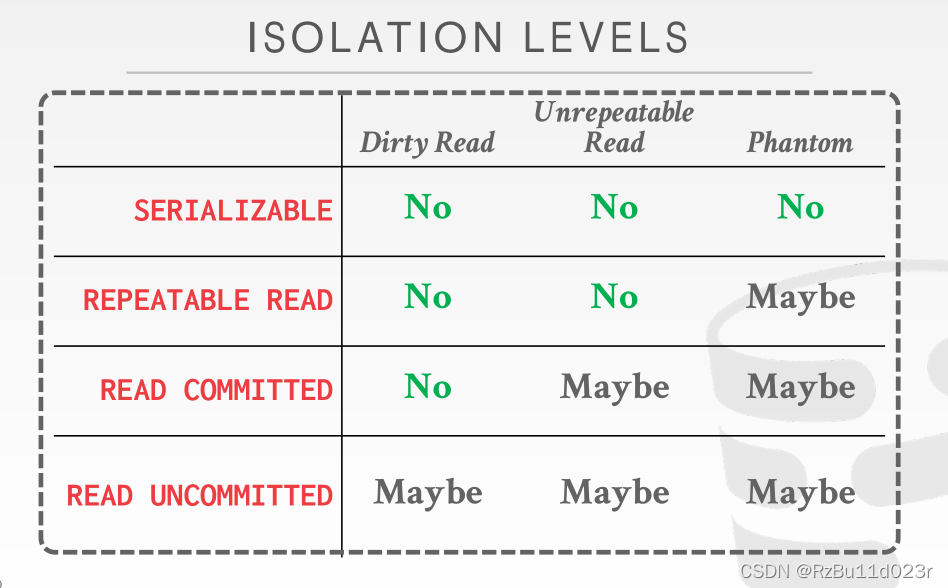
级别(InnoDB 是 repeatable read)
- 商业大部分是 READ commited

这篇关于数据库系统期末复习III: 并发控制基础、多粒度两阶段封锁 2PL、幻读解决方案的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!






