粒度专题

事务(ACID)、并发一致性问题(丢失修改、读脏数据、不可重复读、幻影读)、封锁(封锁粒度、类型、协议、MySQL 隐式与显示锁定)
1. 事务 1.1 概念 事务指的是满足 ACID 特性的一组操作,可以通过 Commit 提交一个事务,也可以使用 Rollback 进行回滚。 1.2 ACID 1.2.1 原子性(Atomicity) 事务被视为不可分割的最小单元,事务的所有操作要么全部提交成功,要么全部失败回滚。 回滚可以用日志来实现,日志记录着事务所执行的修改操作,在回滚时反向执行这些修改操作即可。 1.2.

微服务架构 (八): 业务驱动与团队协作微服务粒度设计: 微服务内部的世界
2016.8.20, 深圳, Ken Fang 在“微服务架构設計 (七): 微服务粒度设计上的核心设计原则与思考的面向” 的一文中, 探讨了从微服务外部的世界驱动微服务粒度的设计。如文中所描述, 为了保障微服务整体的性能与可靠度, 可能会设计出粒度较大的微服务, 而降低了微服务持续部署的速度。 然而, 架构师也不能光只看到微服务外部的世界, 而轻忽或完全忽略了微服务内部的世界。因为,

多粒度特征融合(细粒度图像分类)
多粒度特征融合(细粒度图像分类) 摘要Abstract1. 多粒度特征融合1.1 文献摘要1.2 研究背景1.3 创新点1.4 模型方法1.4.1 Swin-Transformer1.4.2 多粒度特征融合模块1.4.3 自注意力1.4.4 通道注意力1.4.5 图卷积网络1.4.6 基于Vision-Transformer的两阶段分类 1.5 实验1.5.1 数据集1.5.2 实施细节1.

达梦大表更新速度和更新粒度测试(单机环境测试)
### Code Reference DESC:dameng大表更新速度测试Last Update:2020-7-13 10:32 创建测试数据(1000W) drop table rede."个人信息";create table rede."个人信息" as select rownum as id,to_char(sysdate + rownum / 24 / 3600, 'y
mybatis拦截器-对查询结果进行字段粒度的权限控制
// 拦截 Executor 类的 query 方法(args 为 query 方法的参数类型)// 可拦截的类型: Executor、StatementHandler、ParameterHandler 和 ResultSetHandler // 不同类型拦截器的顺序: Executor -> ParameterHandler -> StatementHandler -> ResultSet
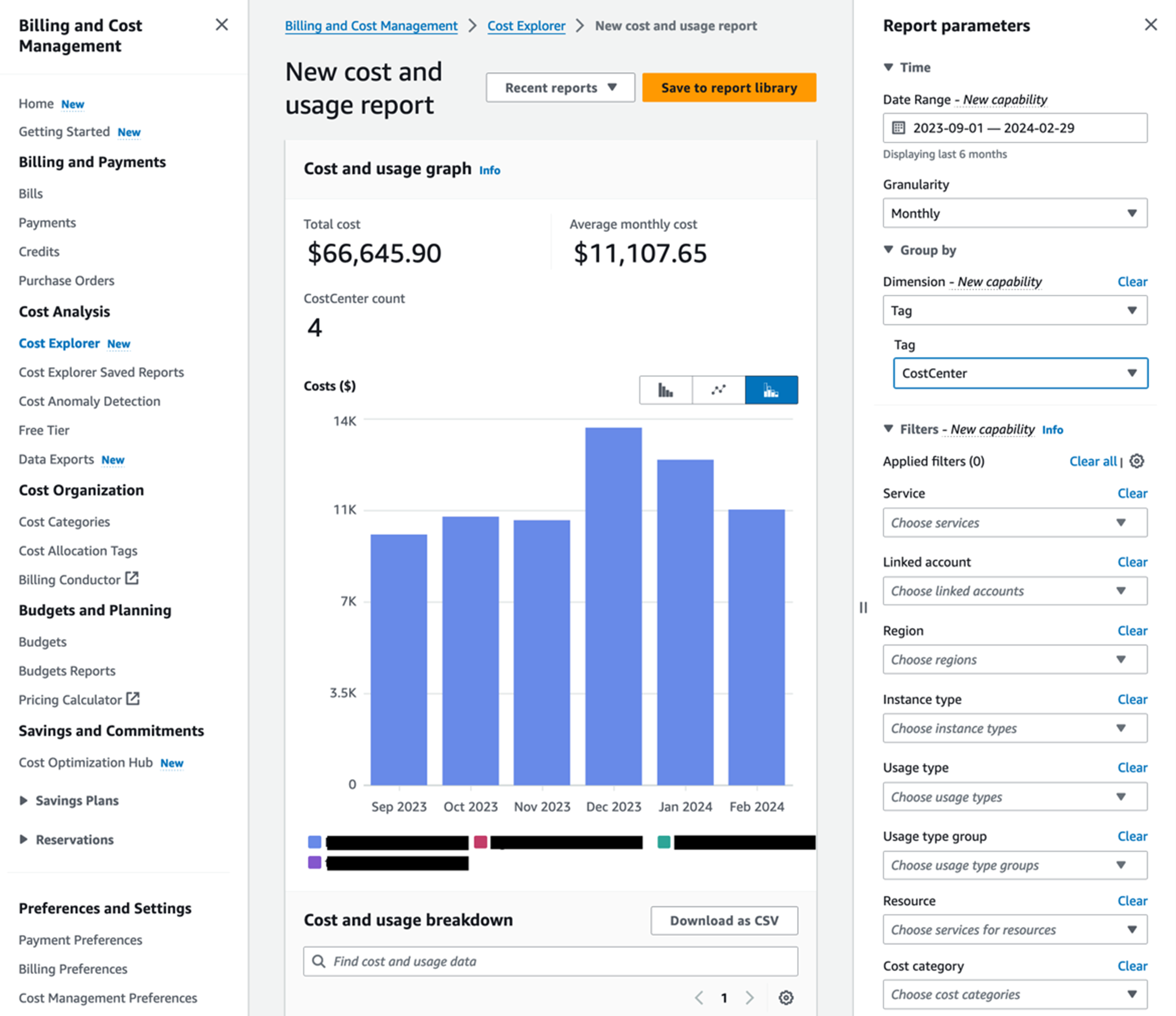
构建无服务器数仓(二)Apache DolphinScheduler 集成以及 LOB 粒度资源消费分析
引言 在数据驱动的世界中,企业正在寻求可靠且高性能的解决方案来管理其不断增长的数据需求。本系列博客从一个重视数据安全和合规性的 B2C 金融科技客户的角度来讨论云上云下混合部署的情况下如何利用亚马逊云科技云原生服务、开源社区产品以及第三方工具构建无服务器数据仓库的解耦方法。 Apache DolphinScheduler 是一种与 EMR Serverless 解耦部署的多功能工作流调度程

数据库系统期末复习III: 并发控制基础、多粒度两阶段封锁 2PL、幻读解决方案
并发控制的重点是三个级别的封锁,2PL 以及 MVCC。本文属于第一部分,复习除了 MVCC 之外的。 基本操作 Commit:一旦 commit 了,就无法再 Rollback。Rollback:再 begin transaction 到 commit 之间使用Abort:和 rollback 是同一个术语。一个 txn 的生命周期是从 begin txn 开始,到 commit/abor

网页栅格系统研究(3):粒度问题
研究(2)中讨论了栅格系统的基础知识。这一篇将集中探讨栅格系统的粒度问题。(注:如非特别指明,栅格系统均指24列960栅格系统) 淘宝的首页(截图)目前尚未严格遵守栅格系统,如果重构的话,宽度方向可以考虑采用下面的栅格布局(只考虑页面主体部分,忽略高度的比例):(图1) 纷乱的高度世界 我们来看下图1左上角。左上角部分目前的宽度为256px, 重构的话可以将宽度缩小到230px以符合栅格(不

MySQL中的并发控制,读写锁,和锁的粒度
MySQL中的并发控制,读写锁,和锁的粒度 并发控制的概述 在数据库系统中,并发控制是一种用于确保当多个用户同时访问数据库时,系统能够提供数据的一致性和隔离性的机制。MySQL支持多种并发控制技术,其中包括锁机制、多版本并发控制(MVCC)等。这些技术帮助数据库处理诸如更新冲突、数据一致性问题以及读写操作的协调等问题。 读写锁 读锁(共享锁) 读锁允许多个事务同时读取同一数据项,但在读锁

论文笔记:基于多粒度信息融合的社交媒体多模态假新闻检测
整理了ICMR2023 Multi-modal Fake News Detection on Social Media via Multi-grained Information Fusion)论文的阅读笔记 背景模型实验 背景 在假新闻检测领域,目前的方法主要集中在文本和视觉特征的集成上,但不能有效地利用细粒度和粗粒度级别的多模态信息。此外,由于模态之间缺乏相关性或每个模态

【成为架构师3-2】服务化:微服务的粒度,究竟要细到什么程度
系列文章是博主对沈剑的《架构师训练营》分享内容的个人笔记总结,原内容公众号“成为架构师”。 目录 统一服务层子业务服务一个数据库一个服务一个接口一个服务常用的最佳实践 统一服务层 最开始,也是最简单的,仅是抽象出一个服务层,所有的服务都是在一起的,全局只有一个服务的概念,这一服务满足上游的所有调用,并对下游进行操作 子业务服务 统一的服务层不利于扩展部署和维护
Windows环境是使用C语言计算程序或算法执行时间的不同粒度实现
运行环境:Windows,VC++6.0 需要微妙级别的童鞋直接看第三种!!! 1.精确到秒,计时单位为秒 头函数: #include<time.h> 开始时间: /* 长整形数据,time_t为time.h 中的宏定义,原型为 #define long time_t */time_t start_time,end_time;/*记录程序开始的时间*/start_time=ti

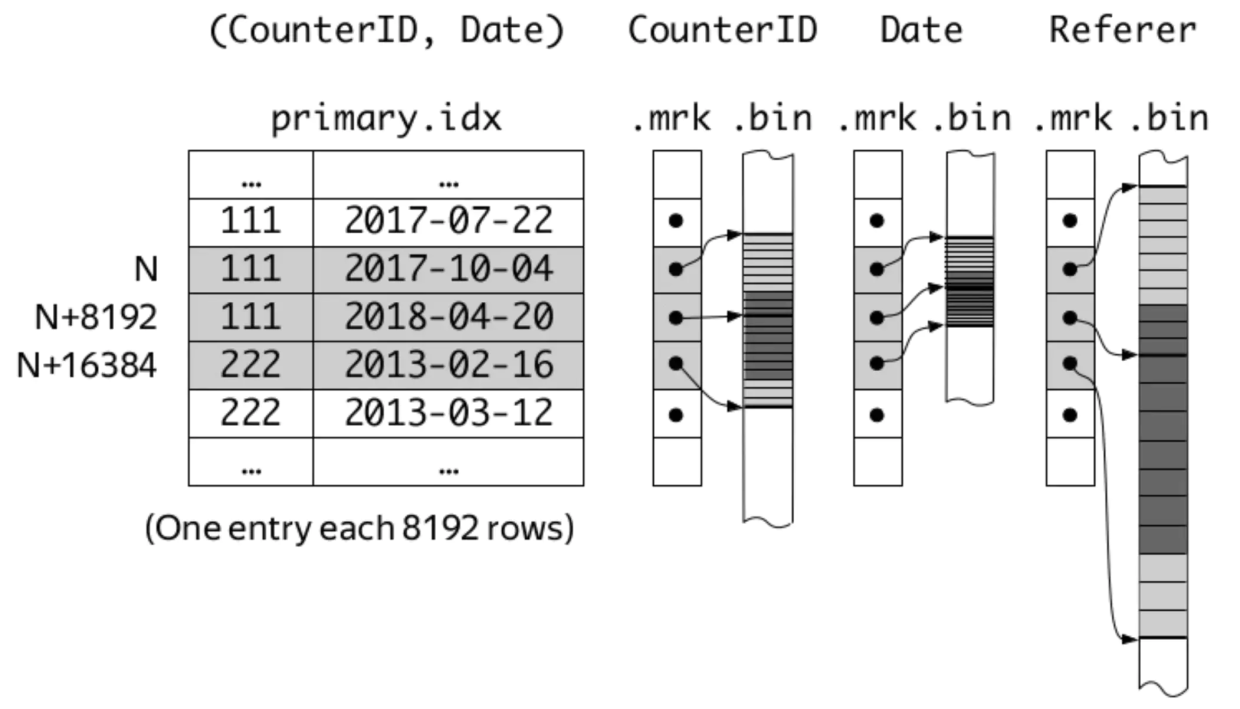
聊聊ClickHouse MergeTree引擎的固定/自适应索引粒度
前言 我们在刚开始学习ClickHouse的MergeTree引擎时,就会发现建表语句的末尾总会有SETTINGS index_granularity = 8192这句话(其实不写也可以),表示索引粒度为8192。在每个data part中,索引粒度参数的含义有二: 每隔index_granularity行对主键组的数据进行采样,形成稀疏索引,并存储在primary.idx文件中; 每隔i

5年经验之谈 —— 探索自动化测试用例设计粒度!
自动化测试用例的粒度指的是测试用例的细致程度,即每个测试用例检查的功能点的数量和范围。 通常,根据测试用例的粒度,可以被分为3种不同的层次,从更低层次的细粒度到更高层次的粗粒度。 第一种:单元测试 - 细粒度 单元测试是测试金字塔的基础,聚焦于程序的最小单元,例如个别函数或方法。 单元测试是开发阶段的核心,目的在于保证代码的每一部分都能按照预期工作。 关键点: 高频率执行:每

laydate根据时间粒度自由控制组件显示查询
laydate根据时间粒度控制组件年月日显示,前端效果如下: 选择粒度月份: 选择粒度年份: 代码如下: <script> $(function () {//常规用法laydate.render({elem: '#startTime',theme: '#0099FF',trigger: 'click'});laydate.render({elem: '#endTime

《论文阅读》DIFFUSEMP:一种基于扩散模型的多粒度控制共情回复生成框架 2023 IEEE TAC
《论文阅读》DIFFUSEMP:一种基于扩散模型的多粒度控制共情回复生成框架 前言简介相关知识Diffusion Model 模型架构整体流程Acquisition of Control SignalsDiffusion Model with Control-Range Masking 损失函数实验结果问题 前言 今天为大家带来的是《DIFFUSEMP: A Diffusio
关于锁的粒度问题——面试
锁的粒度划分主要有三种:表级锁、页级锁和行锁 1.表级锁: 对整张表加锁,粒度最大,加锁的并发度最低,会导致其他事务无法访问该表,只有当前事务提交或者回滚后才能释放锁。表级锁适用于对表进行全表操作的场景,如表的重建、初始化等。 mysql5.5之前默认使用MYISAM引擎 2.页级锁: 对数据表中的一页加锁,粒度介于表级锁和行锁之间,可以提高并发度,但是会导致锁冲突的概率增加。页级

构建高性能服务(二)减小锁粒度 提高Java并发吞吐实例
提高系统并发吞吐能力是构建高性能服务的重点和难点。通常review代码时看到synchronized是我都会想一想,这个地方可不可以优化。使用synchronized使得并发的线程变成顺序执行,对系统并发吞吐能力有极大影响,我的博文 http://maoyidao.iteye.com/blog/1149015 介绍了可以从理论上估算系统并发处理能力的方法。 那么对于必须使用synchron
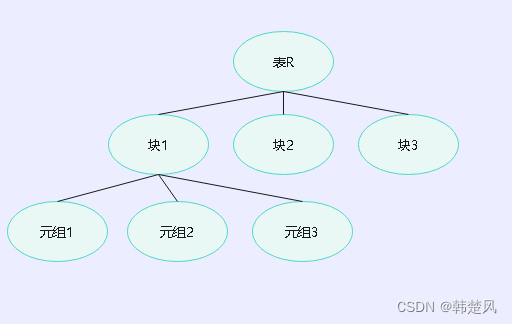
【数据库】数据库元素的层次,树形结构的下的多粒度加锁,以及幻象的正确处理
数据库元素的层次 专栏内容: 手写数据库toadb 本专栏主要介绍如何从零开发,开发的步骤,以及开发过程中的涉及的原理,遇到的问题等,让大家能跟上并且可以一起开发,让每个需要的人成为参与者。 本专栏会定期更新,对应的代码也会定期更新,每个阶段的代码会打上tag,方便阶段学习。 开源贡献: toadb开源库 个人主页:我的主页 管理社区:开源数据库 座右铭:天行健,君子以自强不息;地

数据库设计实践:粒度的理解与应用示例
粒度是描述数据存储和表示的详细程度。在数据库设计中,理解和正确选择粒度是非常重要的,因为它直接影响到数据的存储效率、查询性能和数据分析的灵活性。 文章目录 粒度的类型:案例粒度选择的考虑因素实际应用 粒度的类型: 细粒度(Fine-Grained): 数据存储在非常详细的层面。这意味着记录的每个小部分都被单独存储和管理。粗粒度(Coarse-Grained): 数据存储在较高
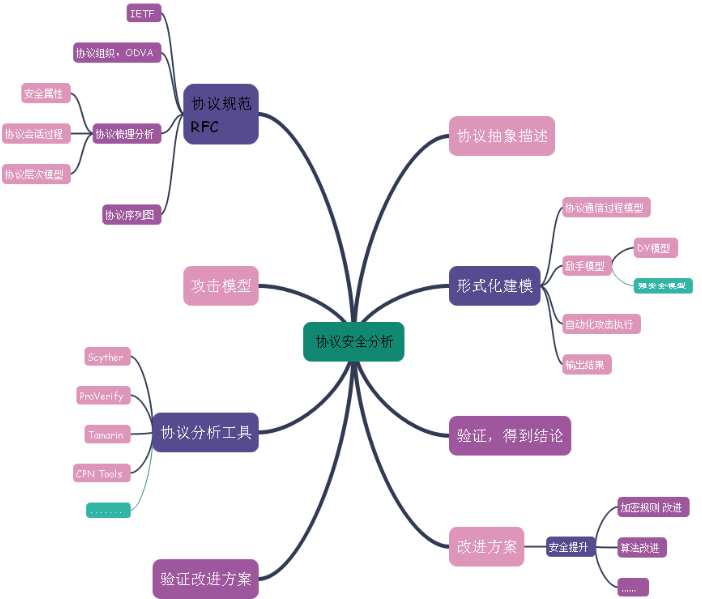
工业协议安全分析中形式化粒度问题分析
1、协议形式化安全分析的总体框架 综合了多种协议形式化分析的案例,对协议的在形式化安全分析的必要准备的条件画了脑图,没有使用顺序图或者层次图,是因为对一个协议的分析从多方面是齐头并进,但是协议的安全分析的工作重点还是协议自身的协议规范分析。这是协议分析的基础,没有正确无误的协议规范分析,得到后续的协议通信会话过程也是错误的。那么后续的工作将没有意义。 任何协议都有自己的协议规

X-VLM:多粒度视觉语言预训练方法
原文:Zeng, Yan, Xinsong Zhang and Hang Li. “Multi-Grained Vision Language Pre-Training: Aligning Texts with Visual Concepts.” ArXiv abs/2111.08276 (2021). 源码:https://github.com/zengyan-97/x-vlm 现有的视

Spring Security 中如何细化权限粒度?
有小伙伴表示微人事(https://github.com/lenve/vhr)的权限粒度不够细。不过松哥想说的是,技术都是相通的,明白了 vhr 中权限管理的原理,在此基础上就可以去细化权限管理粒度,细化过程和还是用的 vhr 中用的技术,只不过设计层面重新规划而已。 当然今天我想说的并不是这个话题,主要是想和大家聊一聊 Spring Security 中权限管理粒度细化的问题。因为这个问题会涉
单一世界架构初探之世界粒度
对服务器来说,没有什么粒度的概念,世界粒度主要还是从客户端的角度来看的。其实这个也好理解,你坐狮鹫从空中看到的地狱火跟面对面看到的地狱火完 全是2个概念。虽然说,其实地狱火完全是一样的,可是因为观察粒度的不同,看到就是2个东西。另外一个例子,应该举个现在多数游戏都有的小地图来说。小地 图,我最早见于《暗黑破坏神》,当然,现在魔兽世界也有。 3维如何实现不同粒度的显示,不是我所长,我就不探讨了,只

Mysql数据库不同时间粒度下的分组统计—按时间粒度:秒、分钟、小时、天、周、月、年进行分组统计
在Mysql数据库中按照不同时间粒度进行分组统计 最近遇到的需求,在Mysql数据库中按照不同时间粒度进行分组统计,返回的数据用做画echarts图使用。下面介绍以:秒、分钟、小时、天、周(本周,上周,最近7天)、月、年进行分组统计,仅以此做个人笔记和分享,粒度不够的评论后补。 一、演示数据 现在开始介绍,以下是的我用来做演示的部分测试数据 我们以统计未恢复和已恢复的告警状态为例,那首先说明