本文主要是介绍ICME2024 | 基于半监督对比学习的表现力语音合成,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
人类的语音极富表现力,不仅包括语调和重读,还包括风格和情感等多种元素。表现力语音合成的目标是要精准捕捉并再现这些元素。先前表现力语音合成方面的研究通常将表现力视为单一维度,如风格或情感。但实际上,风格可以随着文本和场景变化而变化,情感也可以根据态度和意图而有所不同。此外,还可能根据需要切换不同语种。因此,在表现力语音合成中,对风格、情感、音色和语种进行独立建模和控制,是一个极具研究价值的方向。
最近,西北工业大学音频语音与语言处理研究组(ASLP@NPU)发表的论文Boosting Multi-Speaker Expressive Speech Synthesis with Semi-supervised Contrastive Learning被2024年国际多媒体展览会(ICME 2024)接收。该论文提出了一种新颖的半监督对比学习方法,用于表现力语音合成。该方法能够解耦并重组风格、情感、音色和语种,生成极具表现力的语音。以下是对该论文的简要解读和分享。

论文题目:Boosting Multi-Speaker Expressive Speech Synthesis with Semi-supervised Contrastive Learning
作者列表:朱新发,李玉珂,雷怡,蒋宁,赵国庆,谢磊
合作单位:马上消费
论文原文:https://arxiv.org/abs/2310.17101

发表论文截图

扫码直接看论文
背景动机
在神经网络文语转换(Neural TTS)技术迅猛发展的今天,合成语音的质量和自然度取得了巨大的飞跃。TTS技术在有声读物、配音和AI数字人等领域的应用越来越广泛,对合成语音的表现力要求也越来越高。为了实现多说话人、多风格、多情感、多语种的表现力语音合成,迁移学习已成为主流方法[1,2,3]。而在迁移学习中,核心问题是如何解耦语音中的风格、情感、音色、语种等多个因素并在重组时保持语音的表现力。
在ICASSP 2023上,我们提出了一种创新的两阶段表现力语音合成方案[4],通过不同说话人的表现力数据,实现了说话人、风格和情感的多因素解耦;即使在目标说话人没有表现力标注训练数据的情况下,也能合成具有风格和情感的语音。系统包括一个文本到风格和情感(Text2SE)模块和一个风格和情感到波形(SE2Wave)模块,通过神经网络瓶颈(BN)特征连接两者。为了解决多因素解耦问题,我们采用多标签二进制向量(MBV)和互信息(MI)最小化技术,离散化并解耦提取的语音表征。此外,我们引入了一种半监督训练策略,利用来自多个发音人的表现力数据,包括情感标注数据、风格标注数据和无标注数据。为了消除非并行迁移中的不匹配问题,我们通过引入参考候选池,提出了一种基于注意力机制的参考音频选择方法。
ICASSP2023 | 基于多因素解耦的高表现力语音合成
尽管之前的方案在中文上为目标说话人合成了极具表现力的语音,但它在英文上的表现不佳,发音错误较多,且两阶段的系统存在级联误差,影响了合成语音的自然度。针对这些问题,在本文中,我们进一步简化了框架,提出了一种基于半监督对比学习的表现力语音合成新方案。具体地,我们设计了一个语音表征提取模块,在不同层级进行对比学习,从而从语音中提取解耦的风格、情感、音色表征。此外,我们将半监督思想融入对比学习中,利用大量单一标注甚至无标注的数据来提升模型的表现。进一步地,我们将提取的语音表征嵌入到改进的VITS模型中,控制生成语音中的风格、情感与音色特征。在单一语种的中文数据集以及多语种的中英混合的数据集上,大量实验表明我们提出的方法可以实现语音中风格、情感、音色、语种的解耦与重组,为目标说话人合成自然、高表现力的双语多风格多情感语音。
提出的方案
本文方案主要由语音表征学习模块和表现力VITS模块组成。语音表征学习模块基于不同层级的对比学习从语音中提取解耦的风格、情感、音色表征。表现力VITS模块负责从文本中合成语音并受到语音表征的控制。
正负样例对构建: 本文从两个层级构建正负样例。在句子层面,同一句语音前后的不同语音切片互为正样例。在类别层面,相同类别互为正样例、不同类别互为负样例。依据上述规则,标签数据在句子和类别层面构建正负样例对;而无标注数据可以在句子层面构造正样例,它与其他数据的关系定义为不可知。
表征学习模块: 如图1所示,本文对一组语音用随机切片形成两个语音片段集合;表征学习模块用Hubert [5] 提取语音片段的隐层表征;之后送入到解码器中提取全局的语音表征。本文计算两个集合的语音表征余弦相似度矩阵,然后使正样例关系的余弦值向1靠近、负样例关系的余弦值向0靠近;对于不可知关系不做约束。此外,为了提升解耦能力,表现学习模块采用了互信息最小化来约束语音表征。
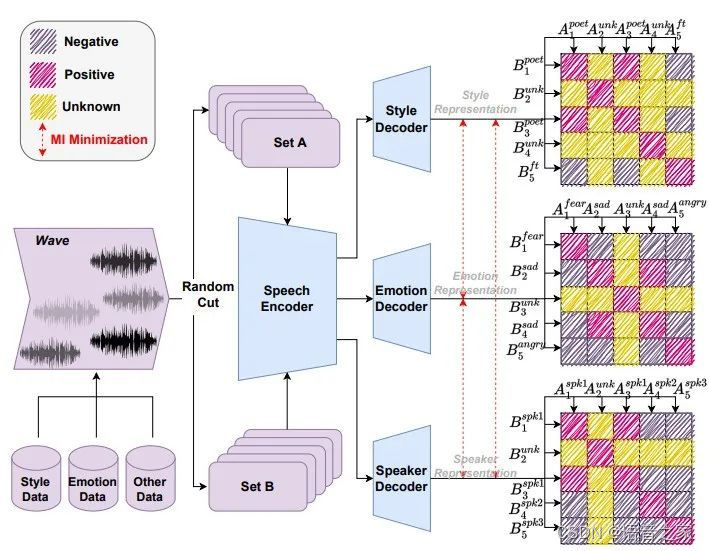
图1 表征学习模型结构
表现力VITS模块: 如图2所示,本文按照“先建模风格和情感再建模音色”的思想在指定位置嵌入表征学习模块提取的风格、情感、音色表征。为了提升可控性,本文用强制时长对齐和时长预测器替换了原始VITS的单调对齐搜索和随机时长预测器。此外,本文引入流模块的韵律适配器,提升合成语音的表现力细节。
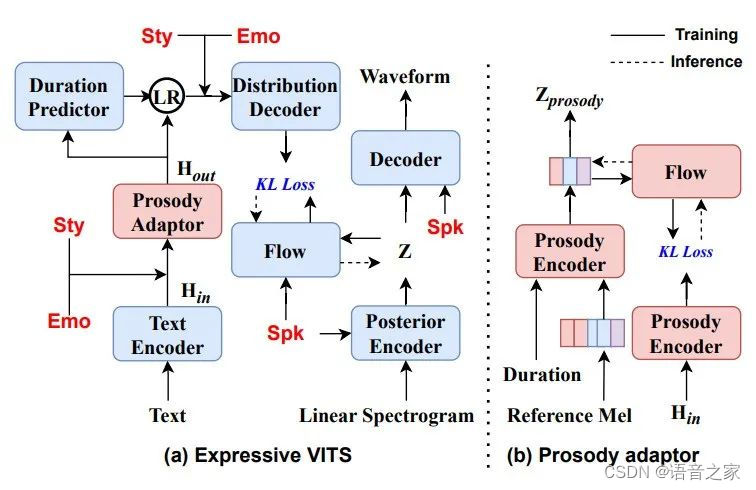
图2 表现力VITS结构
实验验证
实验数据:实验数据来自五个数据集。1)CN30S3共有30位说话人,3种风格(诗歌朗诵、童话故事、小说),总计18.5小时中文语音。2)CN3E6共有3位中文说话人,六种情感(愤怒、害怕、高兴、悲伤、惊喜、中性),总计21.1小时。3)CN5U共有5位说话人,无风格情感标注,总计5.8小时中文语音。4)EN5U共有5位说话人,无风格情感标注,总计31.3小时英文语音。5)MIXU,爬取的900小时中英混合数据,无标签也无转录文本。
对比系统: 对比方案包括两个,一个是TESW[3],两阶段表现力语音合成框架。另外一个是SCVITS[6],采用对比学习的语音合成系统。
单语种测试:本文首先在CN30S3,CN3E6,和CN5U进行单语种实验。如表1所示,提出的方法取得了最优的自然度,最高的情感、音色、风格相似度,反映出其有效地解耦了情感、音色、风格,并实现了重组。此外,在移除表征学习模块最小化互信息结构,提取的方法仍然由于对比模型,验证了不同层级对比学习的优势。
表1 中文语音自然度、情感相似度、说话人相似度、风格相似度、字错误率、余弦相似度测试结果

多语种测试:本文其次在CN30S3,CN3E6,CN5U和EN5U上进行多语种实验。相比于表1,表2中的结果显示所有模型的性能都有所下降。TSEW由于中间表征是由中文预训练模型提取的,因此多语种自然度下降严重;SCVITS只能在有标注的中文数据上训练表征提取模型,因此合成的英文语音表现力较弱。提出的系统整体表现接近单语种的表现,验证了其可以有效地合成多语种表现力语音。此外,本文将大量无标注数据MIXU添加到表征学习阶段的训练集中,结果显示可以进一步提升模型表现,验证了半监督思想的有效性。
表2 双语语音自然度、情感相似度、说话人相似度、风格相似度、字错误率、词错误率、余弦相似度测试结果

可视化分析:本文对表征学习模块提取的风格、情感表征进行了聚类分析。单语种聚类分析如图3所示,虽然没有显式的分类约束,但风格、情感聚类良好,且无法按说话人属性聚类;这证明了表征学习模块可以有效地提取解耦的风格、情感表征。进一步的,为了探讨风格、情感表征与语种之间的关系,本文进行了多语种聚类分析。如图4所示,风格呈现语种区分的状态,而情感呈现语音无关的状态。本文分析基本情感表达比如高兴、悲伤每个语种都会有,而每个语种的发音习惯不同导致说话风格又有区分,从而造就了这种分布。
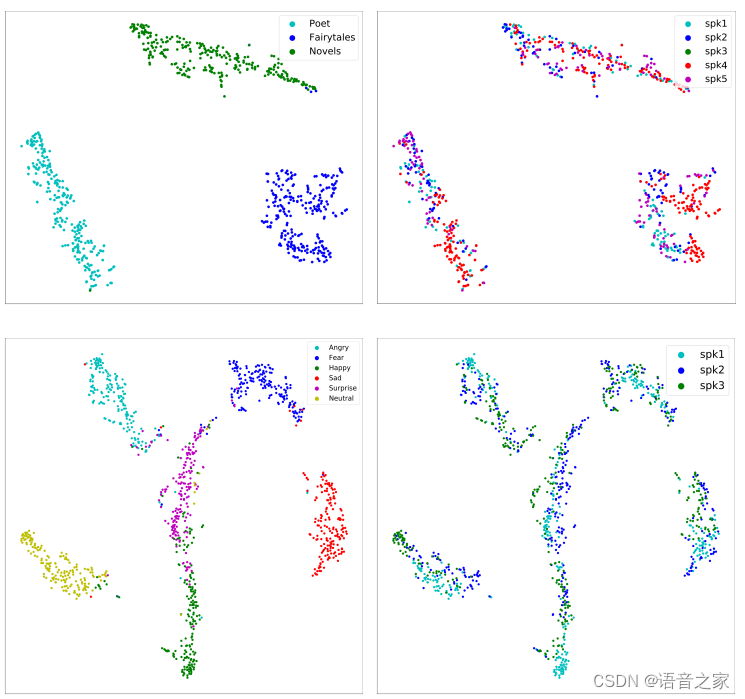
图3 单语种聚类分析——T-SNE可视化结果,上半子图为风格表征,下半子图为情感表征
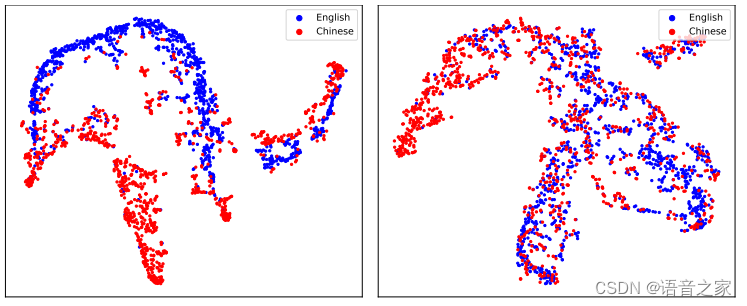
图4 多语种聚类分析——T-SNE可视化结果,左子图为风格表征,右子图为情感表征
样例展示
第一组:“君不见,高堂明镜悲白发,朝如青丝暮成雪”。
目标风格:诗歌,目标情感:悲伤
目标说话人语音
论文结果
第二组:“山不厌高,海不厌深。周公吐哺,天下归心”。
目标风格:诗歌,目标情感:害怕
目标说话人语音
第三组:“I'll build a house out of candy and gingerbread!”
目标风格:英文,目标情感:高兴
目标说话人语音
第四组:“Hope is the thing with feathers that perches in the soul.”
目标风格:英文,目标情感:悲伤
目标说话人语音
参考文献
[1] Yi Lei, Shan Yang, Xinsheng Wang, and Lei Xie, “Msemotts: Multi-scale emotion transfer, prediction, and control for emotional speech synthesis,” IEEE ACM Trans. Audio Speech Lang. Process., vol. 30, pp. 853–864, 2022
[2] Tao Li, Xinsheng Wang, Qicong Xie, Zhichao Wang, and Lei Xie, “Cross-speaker emotion disentangling and transfer for end-to-end speech synthesis,” IEEE ACM Trans. Audio Speech Lang. Process., vol. 30, pp. 1448–1460, 2022.
[3] Xinfa Zhu, Yi Lei, Kun Song, Yongmao Zhang, Tao Li, and Lei Xie, “Multi-speaker expressive speech synthesis via multiple factors decoupling,” in Proc. ICASSP, 2023, pp. 1–5.
[4] Jaehyeon Kim, Jungil Kong, and Juhee Son, “Conditional variational autoencoder with adversarial learning for end-to-end text-to-speech,” in Proc. ICML. 2021, pp. 5530–5540, PMLR.
[5] Wei-Ning Hsu, Benjamin Bolte, Yao-Hung Hubert Tsai, Kushal Lakhotia, Ruslan Salakhutdinov, and Abdelrahman Mohamed, “Hubert: Self-supervised speech representation learning by masked prediction of hidden units,” IEEE ACM Trans. Audio Speech Lang. Process., vol. 29, pp. 3451–3460, 2021.
[6] Varun Sai Alaparthi, Tejeswara Reddy Pasam, Deepak Abhiram Inagandla, Jay Prakash, and Pramod Kumar Singh, “Scser: Supervised contrastive learning for speech emotion recognition using transformers,” in Proc. HSI. 2022, pp. 1–7, IEEE.
这篇关于ICME2024 | 基于半监督对比学习的表现力语音合成的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!




