本文主要是介绍#####带时间衰减因子#####应用实战: 如何利用Spark集群计算物品相似度,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
本文是Spark调研笔记的最后一篇,以代码实例说明如何借助Spark平台高效地实现推荐系统CF算法中的物品相似度计算。
在推荐系统中,最经典的推荐算法无疑是协同过滤(Collaborative Filtering, CF),而item-cf又是CF算法中一个实现简单且效果不错的算法。
在item-cf算法中,最关键的步骤是计算物品之间的相似度。本文以代码实例来说明如何利用Spark平台快速计算物品间的余弦相似度。
Cosine Similarity是相似度的一种常用度量,根据《推荐系统实践》一书第2.4.2节关于Item-CF算法部分的说明,其计算公式如下:
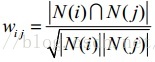
举个例子,若对item1有过行为的用户集合为{u1, u2, u3},对item2有过行为的用户集合为{u1, u3, u4, u5},则根据上面的式子,item1和item2间的相似度为2/(3*4),其中分子的2是因为item1的user_list与item2的user_list的交集长度为2,即item1和item2的共现(co-occurence)次数是2。
在工程实现上,根据论文"Empirical Analysis of Predictive Algorithms for Collaborative Filtering"的分析,为对活跃用户做惩罚,引入了IUF (Inverse User Frequency)的概念(与TF-IDF算法引入IDF的思路类似:活跃用户对物品相似度的贡献应该小于不活跃的用户),因此,对余弦相似度做改进后相似度计算公式如下:
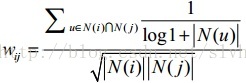
可以看到,上式分子部分的1/log(1 + N(u))体现了对活跃用户的惩罚。
此外,通常认为用户在相隔很短的时间内喜欢的物品具有更高相似度。因此,工程实现上,还会考虑时间衰减效应。一种典型的时间衰减函数如下所示:
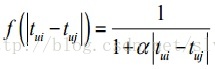
最终,时间上下文相关的Item-CF算法中的相似度计算公式如下:
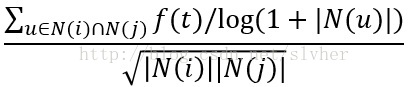
上式中,分母部分与标准的相似度公式分母保持一致;分子部分参与运算的是item_i和item_j的共现用户集合,其中,f(t)是时间衰减效应的体现,N(u)对活跃用户做了惩罚。
下面的Python代码是计算物品相似度的Spark任务的代码片段(从HDFS加载用户历史行为日志,计算物品相似度,相似列表取TopN,将相似度计算结果写会HDFS),供大家参考:
-
-
-
- import pyspark as ps
- import math
- import datetime as dt
- import util
-
-
- def generate_item_pair(x):
-
-
-
-
- items = x[1]
- item_cnt = len(items)
- alpha = 1
- for i in items:
- item1 = i[0]
- ts1 = i[1]
- for j in items:
- item2 = j[0]
- ts2 = j[1]
- if item1 != item2:
-
- ft = 1.0 / (1 + alpha * abs(ts1 - ts2))
- yield ((item1, item2), (ft / math.log(1 + item_cnt)))
-
-
- def compute_item_similarity(x):
- items = x[0]
- cooccurrence = float(x[1])
- item_dict = g_item_freq_d
- norm_factor = 5
- if items[0] in item_dict and items[1] in item_dict:
- freq_0 = item_dict[items[0]]
- freq_1 = item_dict[items[1]]
-
- sim = cooccurrence / math.sqrt(freq_0 * freq_1)
-
- norm_sim = (cooccurrence / (cooccurrence + norm_factor)) * sim
- yield (items[0], (items[1], norm_sim))
-
-
- def sort_items(x):
-
-
-
-
- similar_items = list(x[1])
- if len(similar_items) > 0:
-
- similar_items.sort(key=lambda x: x[1], reverse=True)
-
- similar_items_str = ",".join(["$".join(map(str,item)) for item in similar_items[0:50]])
- yield "\t".join([str(x[0]), similar_items_str])
-
-
- def main():
- base_hdfs_uri = "hdfs://to/user/behavior/log"
- today = dt.date.today()
- knn_similarity_file = '%s/%s/knn_sim' % (base_hdfs_uri, today.strftime('%Y%m%d'))
-
- sc = ps.SparkContext()
-
-
-
- history_s = (today - dt.timedelta(8)).strftime('%Y%m%d')
- history_e = (today - dt.timedelta(2)).strftime('%Y%m%d')
- input_files = util.get_input_files(action='play', start=history_s, end=history_e)
- user_item = sc.textFile(",".join(input_files))\
- .mapPartitions(util.parse_user_item) \
- .map(lambda x: (x[0], (x[1], x[2]))) \
- .distinct() \
- .cache()
-
-
- item_freq = user_item.map(lambda x: (x[1][0], 1)) \
- .reduceByKey(lambda x, y: x + y) \
- .collect()
- global g_item_freq_d
- g_item_freq_d = dict()
- for x in item_freq:
- g_item_freq_d[x[0]] = x[1]
-
-
- item_pair_sim = user_item.groupByKey() \
- .flatMap(generate_item_pair) \
- .reduceByKey(lambda x, y: x + y) \
- .flatMap(compute_item_similarity) \
- .groupByKey() \
- .flatMap(sort_items) \
- .cache()
-
-
- item_pair_sim.repartition(1).saveAsTextFile(knn_similarity_file)
-
-
- if __name__ == '__main__':
- main()
上面的代码中,import util中引入的util只是负责从HDFS获取用户历史日志的文件名列表,非常简单,实现细节这里不赘述。
【参考资料】
1. wikipedia: Collaborative filtering
2. 推荐系统实践(项亮著)第2.4.2节: 基于物品的协同过滤算法
3. Paper: Empirical Analysis of Predictive Algorithms for Collaborative Filtering
4. 推荐系统实践(项亮著)第5.1.6节: 时间上下文相关的ItemCF算法
5.
Spark Programming Guide
========================== EOF ===========================
这篇关于#####带时间衰减因子#####应用实战: 如何利用Spark集群计算物品相似度的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!








