本文主要是介绍多器官和多模态图像的通用异常检测模型-不受特定模型约束,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
文章目录
- A Model-Agnostic Framework for Universal Anomaly Detection of Multi-organ and Multi-modal Images
- 摘要
- 方法
- 实验结果
A Model-Agnostic Framework for Universal Anomaly Detection of Multi-organ and Multi-modal Images
摘要
-
背景与挑战:深度学习在医学图像分析中取得了巨大成功,但手动标记症状性医学图像费时费力。相比之下,获取无症状健康受试者的正常图像更容易。先前的工作通常为每个器官和模态单独设计网络,忽略了医学图像之间的固有相似性。
-
提出的解决方案:本文提出了一种模型无关的框架,可以使用单个网络进行各种器官和模态的异常检测。通过对潜在表示施加器官和模态分类约束以及中心约束,提高了网络的泛化能力和性能。
-
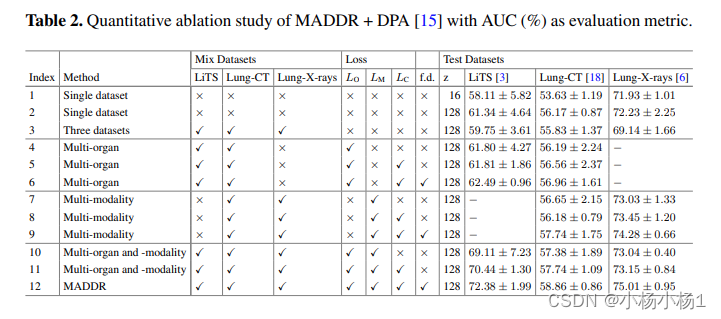
关键贡献:该框架不仅提高了网络对各种器官和模态的异常检测的泛化能力,还改善了单个器官和模态的性能。通过在三个公共数据集上进行大量实验,证明了该框架的优越性和每个组件的有效性。
-
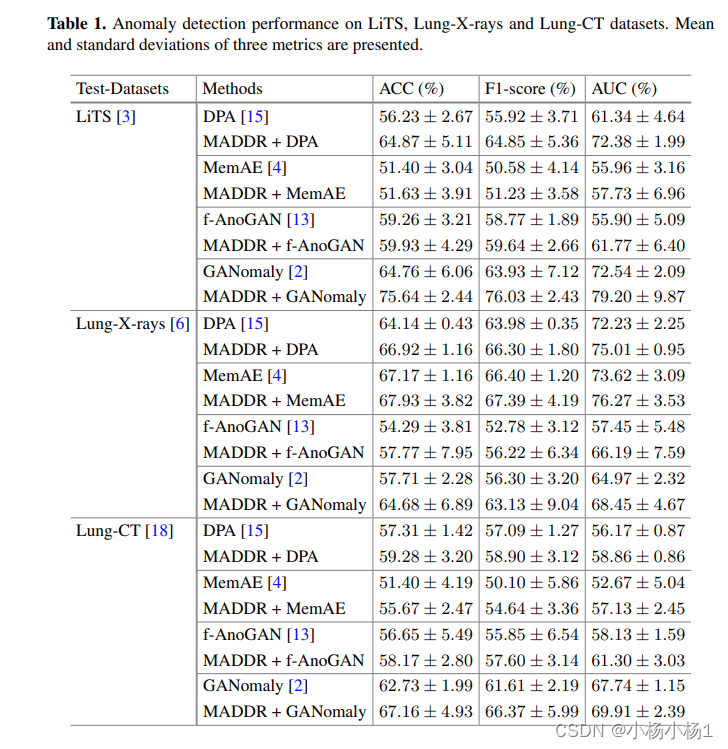
实验结果:使用四种不同的基线模型进行实验,结果表明提出的框架在各个方面都表现出明显的优势,有效应对了医学图像分析中的挑战。
-
结论与展望:本文的工作为医学图像异常检测提供了一种新的模型无关的解决方案,为未来深度学习在医学图像分析领域的应用提供了有益启示。
代码地址
方法
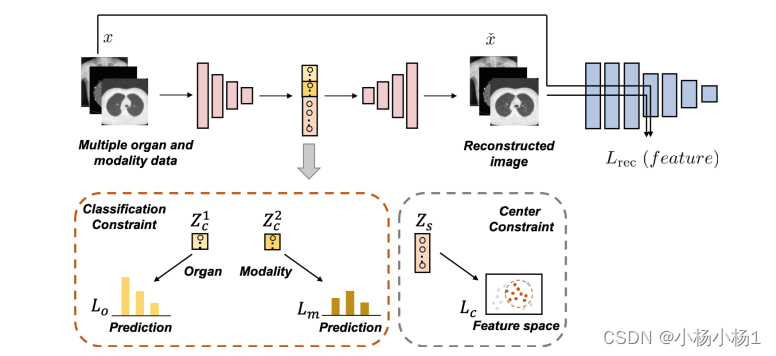
图 1 展示了将提出的框架整合到 DPA 方法中的概述。除了基线模型的原始损失之外,还在解缠的潜在表示上应用了两个分类约束(器官和模态)和一个中心约束。
提出的框架是模型无关的,可以轻松地应用于大多数标准异常检测方法。采用了四种最先进的异常检测方法,即深度感知自编码器(DPA)、记忆增强自编码器(MemAE)、基于生成对抗网络的异常检测(GANomaly)和基于生成对抗网络的快速无监督异常检测(f-AnoGAN)作为基线方法
DPA 的网络由自编码器和预训练特征提取器组成。通过自编码器,图像被编码为潜在表示,然后重构为原始图像空间。他们采用相对感知损失作为自编码器的目标函数,并用于优化自编码器和衡量异常。他们进一步通过在编码的潜在表示上增加额外约束来充分利用各种器官和模态的正常图像中的潜在模式。具体来说,他们的 MADDR 方法鼓励模型将输入图像转换为潜在表示,其中包含解耦的类别和个性信息。通过对编码的潜在表示施加分类和中心约束,他们的方法可以更好地捕获正常图像的潜在分布,并用于异常检测。他们在四种最先进的异常检测方法上评估了提出的模型无关框架,结果表明该框架在多器官和多模态图像的异常检测任务中具有优越性。
实验结果
这篇关于多器官和多模态图像的通用异常检测模型-不受特定模型约束的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!





