本文主要是介绍【LLM 论文】UPRISE:使用 prompt retriever 检索 prompt 来让 LLM 实现 zero-shot 解决 task,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
论文:UPRISE: Universal Prompt Retrieval for Improving Zero-Shot Evaluation
⭐⭐⭐⭐
EMNLP 2023, Microsoft
Code:https://github.com/microsoft/LMOps
一、论文速读
这篇论文提出了 UPRISE,其思路是:训练一个 prompt retriever,面对一个 task 的 input 时,可以通过 prompt retriever 从 prompt pool 中检索到一个最合适的 prompt 作为 in-context learning 中的 exemplars,然后把这些 exemplars + task input 一起输入给 LLM,从而得到 answer。
下图是一个 case:(下半部分是 UPRISE 改进后的)

二、Prompt Retriever
2.1 Prompt Retriever 是什么
prompt retriever 是这篇论文的关键创新点,它的提出思路是这样的:以往 prompt engineering 方法中,使用 LLM 解决每一个 downstream task 都需要预先设定一个对应的 prompt。但也有可能为某个 task 设定的 prompt 也能够泛化到其他未见过的 task 上,于是,这篇论文的工作首先构建了一个 prompt pool,里面存储了很多用于解决 downstream tasks 的 prompts,然后当一个 test input 到来时,prompt retriever 可以从中检索出最适合这个 task 的 prompt,然后把 retrieved prompt + task input 输入给 LLM 来得到 answer。
论文的关键是训练出能够满足要求的 prompt retriever,并期待它面对没有见过的 task(prompt pool 中也没有这个 task 的 prompt),也可以检索出一个合适的 prompt 并让 LLM 来回复这个 input,这也就是论文提出的 Cross-task retrieval。另外也期待这个 prompt retriever 可以用于多个不同系列的 LLM,这也是论文提出的 Cross-model retrieval。
2.2 Prompt Retriever 的训练和 inference
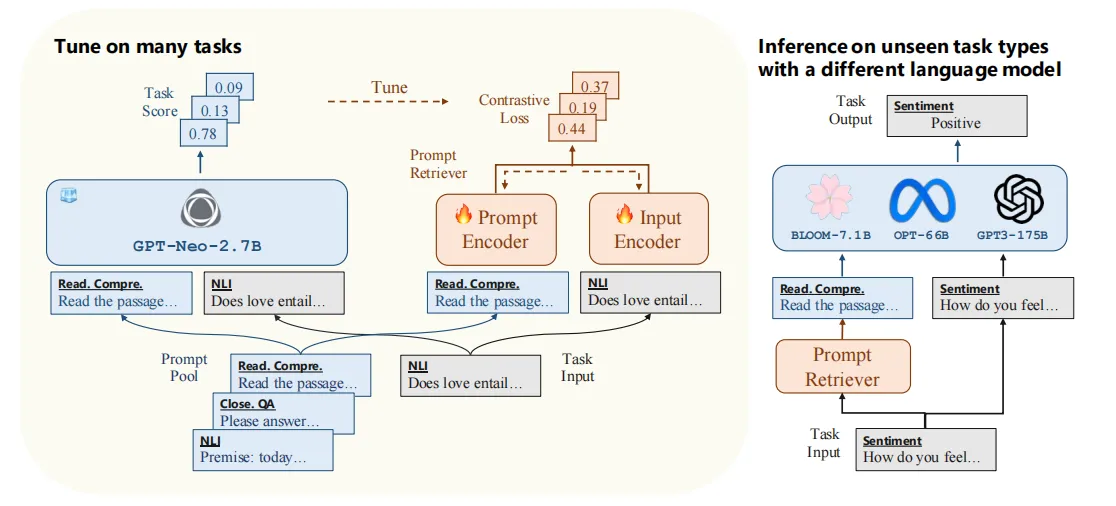
分别介绍 prompt retriever 的训练和推理思路。
retriever 的训练
这里会使用一个 frozen LLM 用于 prompt retriever 的监督微调。
对于一个 prompt-input 的 pair,会将其视为 positive pair,然后更换其中的 prompt 制作出一些 negative pairs,之后:
- 把一个 pair 给 retriever,retriever 是一个 bi-encoder 模型,prompt encoder 和 input encoder 分别对 prompt 和 input 进行编码
- 把一个 pair 和 negative pairs 给 frozen LLM,让其输出一个 task score 来评估 prompt 的有效性
对 positive pair 和 negative pairs 都循环上述过程,并使用对比学习来训练 prompt retriever,损失函数使用的 InfoNCE 这样的对比损失函数。
inference 阶段
预先使用 prompt encoder 对所有 prompt 进行编码,存入 prompt pool 中。
在 inference 时,对于 task input x t e s t x_{test} xtest,对其使用 input encoder 进行编码,然后从 prompt pool 中检索出最相似的 K 个 prompts 并降序排列: P + = ( p 1 , … , p K ) P^+ = (p_1, \dots, p_K) P+=(p1,…,pK),然后把这个些 prompts 和 input 连接在一起,形成 p k ⊕ ⋯ ⊕ p 1 ⊕ x t e s t p_k \oplus \dots \oplus p_1 \oplus x_{test} pk⊕⋯⊕p1⊕xtest作为给 LLM 的输入。
同时神奇的是,在多个 downstream tasks 上训练出来的 retriever,能够很不错的应对未见过的任务,并从 prompt pool 选出相对来说比较合适的 prompts 来与 input 组装从而输入给 LLM 获得好的 answer。
三、总结
总的来说,这篇论文提出了一个很新颖的思路:prompt retriever,从而提高 LLM 的 zero-shot 的能力。
同时还研究了 prompt retriever 从训练的任务类型推广到其他未见过的任务类型,以及从小的 LLM 推广到更大规模的
这篇关于【LLM 论文】UPRISE:使用 prompt retriever 检索 prompt 来让 LLM 实现 zero-shot 解决 task的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!




