本文主要是介绍Python语言在地球科学中地理、气象、气候变化、水文、生态、传感器等数据可视化到常见数据分析方法的使用,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
Python是功能强大、免费、开源,实现面向对象的编程语言,Python能够运行在Linux、Windows、Macintosh、AIX操作系统上及不同平台(x86和arm),Python简洁的语法和对动态输入的支持,再加上解释性语言的本质,使得它在大多数平台上的许多领域都是一个理想的脚本语言,特别适用于快速的应用程序开发。Python具有丰富和强大的库,能够把用其他语言制作的各种模块(尤其是C/C++)很轻松地联结在一起。除了Python标准库,几乎所有行业领域都有相应的Python软件库,随着NumPy、SciPy、Matplotlib和Pandas等众多Python应用程序库的开发,Python在科学和工程领域地位日益重要,在数据处理、科学计算、数学建模、数据挖掘和数据可视化方面的优异性能使得Python在地球科学中地理、气象、气候变化、水文、生态、传感器等领域的学术研究和工程项目中得到广泛应用并高效解决各种数据分析问题,可以预见未来Python将成为科学和工程领域的主流程序设计语言。
1、提供虚拟机(Virtual Box)文件(预装好Anaconda环境,可直接使用)
2、提供原始数据和中间临时文件
专题一 Python重点工具讲解【打好基础】
Numpy:科学计算
Scipy:科学计算
Sklearn:机器学习
Matplotlib:可视化
Cartopy:地理数据可视化
GeoPandas:地理数据分析

专题二 常见地球科学数据讲解【掌握数据的特点】
1、站点数据
GSOD
GHCN
ISMN:国际土壤湿度测量网络数据

FLUXNET:全球通量观测网络数据

2、格点观测数据
CRU

CN05.1
OISST、HadSST
3、再分析
ERA5
GLDAS

4、遥感数据
GLEAM

Landsat

MODIS

TRMM

SMAP:土壤湿度主动被动遥感数据

专题三 使用Xarray处理netCDF和Geotiff数据
Xarray 读取&写入 netCDF文件
Groupby & resample 对时间、空间信息进行操作
Rasterio & rioxarray
专题四 使用Pysat进行大空间分析
1. 空间自相关分析
分析干旱事件发生的空间聚集性
2. 空间回归模型
建模气温与地形因素的空间关系
GWR模型评估地形对降水分布的局部影响
3. 空间点模式分析
探测极端天气事件的热点区域
4. 时空数据分析
评估城市热岛效应的时空演化
专题五 使用Dask进行大数据并行计算
使用Dask进行大数据并行计算
Arrays、DataFrames
无结构数据的并行处理
延迟计算
案例一:并行处理长时间序列的TRMM降水数据,识别极端降水事件的时空分布特征
案例二:利用Dask并行计算,快速监测全球范围内干旱的发生、发展和持续时间
专题六 使用Pandas分析时间序列数据-1
案例一:时间序列填补
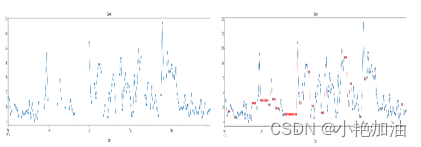
案例二:极端风速重现期分析

案例三:台风个数统计
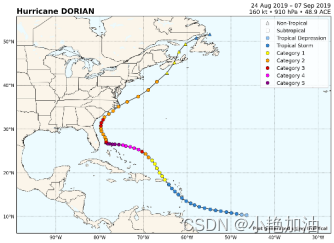
专题七 使用Pandas分析时间序列数据-2
1、环流指数与温度、降水变化的关联性
各环流指数对全球及区域温度变化的影响
环流指数与极端高温/低温事件的联系
环流指数与干旱/洪水事件的关联
环流指数对季风系统的影响
2、空间插值
使用Kriging进行站点数据插值
使用IDW插值生成高分辨率气温场

3、缺测数据插补
针对地面站点数据中的缺失值进行插补
利用机器学习算法插补遥感数据中的缺测像元
结合空间插值和时间插值等多种方法提高数据质量
专题八 使用Python处理遥感数据1以Landsat数据为例
1、大数据的可视化
GB级数据可视化
2、植被指数计算

3、裁剪区域
使用mask掩膜文件裁剪
使用shapefile文件裁剪
专题九 使用Python处理遥感数据2—以MODIS数据为例
1、预备工作:
Python读取HDF4-EOS数据
使用GDAL库预处理
转投影为wgs84+lonlat
拼接多景影像
2、案例一:土地利用分析(MOD12C1)
2000-2020年青藏高原土地利用分析
分析不同土地利用分类上气温和降水的变化

3、案例二:生态系统生产力分析(MOD17A2)
青藏高原草场上土地利用GPP变化
分析草场GPP与降水之间关系(ERA5再分析数据)

4、案例三:分析积雪覆盖时间(MOD10A2)
2000-2020年间青藏高原积雪时间统计
分析祁连山不同高程带积雪时间统计(DEM:GTOP30S)

5、案例四:积雪与生产力之间的关系(MOD10A2和MOD17A2)
分析新疆北疆积雪覆盖时间与春季GPP的变化
专题十 使用Python处理站点数据以GSOD和气象共享网数据为例
1、数据的读取
读取美国NOAA的GSOD日值数据
读取气象共享网日值数据
2、数据清洗:
数据整理
异常值检测
阈值法
模型法
孤立森林
3、多时间尺度的统计:
年尺度统计
季尺度统计
4、站点插值:(随机森林树)
利用高程、经纬度插值气温数据
专题十一 使用Python处理遥感水文数据以TRMM遥感降水数据和GLEAM数据等为例
案例一:空间降尺度
使用NDVI、DEM和机器学习算法对TRMM降水数据降尺度
案例二:分析蒸散数据的年际变化
读取GLEAM数据,并分析蒸散发的年际变化
比较MODIS ET产品与GLEAM的差异
案例三:使用随机森林算法估算地表蒸散发
GLEAM和ERA5数据建立机器学习估算模型
在区域尺度上进行长时间序列模拟

案例四:比较多套土壤湿度产品
比较GLDAS、GLEAM和CCI SM
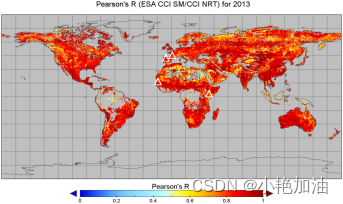
案例五:分析降水~蒸散发-土壤湿度关系
分析降水~蒸散发-土壤湿度的年际变化
专题十二 使用Python处理遥感和模式数据以PKU GIMMS NDVI遥感降水数据和GLDAS数据为例
案例一:结合GIMMS NDVI和陆面模式数据分析干旱影响
获取陆面模式模拟的土壤湿度数据
建立植被生产力与干旱的响应关系
评估不同地区的干旱敏感性
案例二:青藏高原地区干旱对高寒草地生态系统的影响
基于NDVI识别青藏高原历史干旱年份
结合GLDAS模拟的土壤温湿度等数据,分析干旱对植被的影响机制
专题十三 使用Python处理气候变化数据1观测数据
案例一:百年气温趋势:CRU数据

案例二:百年海温趋势:HadSST
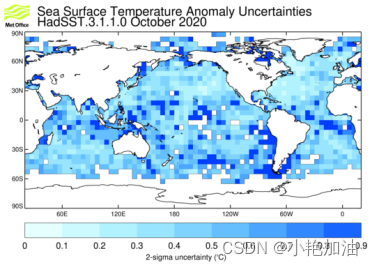
案例三:再分析数据处理
ERA5数据气温评估
专题十四 使用Python进行气候诊断分析
在GHCN站点数据基础上
使用Mann-Kendall趋势检验
使用Mann-Kendall突变分析
和Sen's slope估计气候变化趋势
使用小波分析等分析周期
专题十五 使用Python处理气候变化数据2 以CMIP6数据为例
降尺度
Delta方法
百分位校正方法
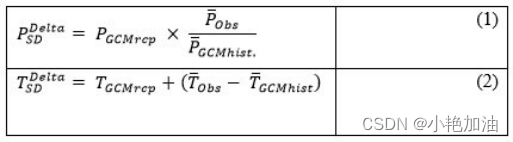
案例一:计算极端气候指数
案例二:未来气候变化背景下中国地区GPP变化(CMIP6+MOD17+机器学习)
案例三:未来气候变化背景下中国地区土地利用变化

专题十六 使用Python对WRF模式数据后处理
案例一:空间坐标重采样
案例二:风速垂直高度插值
获取风机70和100m高度的风速和风向

专题十七 使用Python运行生态模型 以CN05.1数据和Biome-BGC生态模型为例
1、模型讲解
2、气象数据的准备
3、控制文件生成
4、模式的运行
Muliprocesing 并行运行
5、模式后处理
结果统计
结果可视化(NPP)
注:请提前自备电脑及安装所需软件
更多应用
ArcGIS+ChatGPT双剑合璧:从数据读取到空间分析,一站式掌握GIS与AI融合的前沿科技!-CSDN博客文章浏览阅读908次,点赞18次,收藏10次。结合ArcGIS和GPT的优势,本教程将重点讲解AI大模型应用、ArcGIS工作流程及功能、Prompt使用技巧、AI助力工作流程、AI助力数据读取与处理、AI助力空间分析、AI助力遥感分析、AI助力二次开发、AI助力科研绘图以及ArcGIS与AI的综合应用。https://blog.csdn.net/WangYan2022/article/details/138335545?spm=1001.2014.3001.5502ChatGPT深度科研应用、数据分析及机器学习、AI绘图与高效论文撰写-CSDN博客文章浏览阅读865次,点赞25次,收藏26次。掌握ChatGPT4.0在科研工作中的各种使用方法与技巧,以及人工智能领域经典机器学习算法(BP神经网络、支持向量机、决策树、随机森林、变量降维与特征选择、群优化算法等)和热门深度学习方法(卷积神经网络、迁移学习、RNN与LSTM神经网络、YOLO目标检测、自编码器等)的基本原理及Python、PyTorch代码实现方法。
https://blog.csdn.net/WangYan2022/article/details/137681275?spm=1001.2014.3001.5502AI大模型与ChatGPT的碰撞,在GIS、生物、地球、农业、气象、生态、环境科学领域案例应用-CSDN博客文章浏览阅读833次,点赞17次,收藏19次。AI大语言模型带来了新一波人工智能浪潮,可以面向科研选题、思维导图、数据清洗、统计分析、高级编程、代码调试、算法学习、机器/深度学习、大尺度模拟、论文检索、写作、翻译、润色、文献辅助阅读、文献信息提取、辅助论文审稿、新闻撰写、科技绘图、地学绘图(GIS地图绘制)、概念图生成、图像识别、教学课件、教学案例生成、基金润色、专业咨询、文件上传和处理、机器/深度学习训练与模拟、大模型API二次开发等特定任务,生成文本、图片、代码、语音、视频等不同形式的数据、模式和内容,成为不少科研工作者的第二大脑。
https://blog.csdn.net/WangYan2022/article/details/137669575?spm=1001.2014.3001.5502★点 击 关 注,获取海量教程和资源
这篇关于Python语言在地球科学中地理、气象、气候变化、水文、生态、传感器等数据可视化到常见数据分析方法的使用的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!






