本文主要是介绍一种基于YOLOv8改进的高精度红外小目标检测算法 (原创自研),希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
💡💡💡本文摘要:一种基于YOLOv8改进的高精度小目标检测算法, 在红外小目标检测任务中实现暴力涨点;
💡💡💡创新点:
1)SPD-Conv特别是在处理低分辨率图像和小物体等更困难的任务时优势明显;
2)引入Wasserstein Distance Loss提升小目标检测能力;
3)YOLOv8中的Conv用cvpr2024中的DynamicConv代替;
原创组合创新,可直接使用至其他小目标检测任务;
💡💡💡实验结果:在红外小目标检测任务中mAP由原始的0.755 提升至0.901
博主简介
AI小怪兽,YOLO骨灰级玩家,1)YOLOv5、v7、v8、v9优化创新,轻松涨点和模型轻量化;2)目标检测、语义分割、OCR、分类等技术孵化,赋能智能制造,工业项目落地经验丰富;

原创自研系列, 2024年计算机视觉顶会创新点
《YOLOv8原创自研》
《YOLOv5原创自研》
《YOLOv7原创自研》
《YOLOv9魔术师》
23年最火系列,内涵80+优化改进篇,涨点小能手,助力科研,好评率极高
《YOLOv8魔术师》
《YOLOv7魔术师》
《YOLOv5/YOLOv7魔术师》
《RT-DETR魔术师》
应用系列篇:
《YOLO小目标检测》
《深度学习工业缺陷检测》
《YOLOv8-Pose关键点检测》
1.小目标检测介绍
1.1 小目标定义
1)以物体检测领域的通用数据集COCO物体定义为例,小目标是指小于32×32个像素点(中物体是指32*32-96*96,大物体是指大于96*96);
2)在实际应用场景中,通常更倾向于使用相对于原图的比例来定义:物体标注框的长宽乘积,除以整个图像的长宽乘积,再开根号,如果结果小于3%,就称之为小目标;

1.2 难点
1)包含小目标的样本数量较少,这样潜在的让目标检测模型更关注中大目标的检测;
2)由小目标覆盖的区域更小,这样小目标的位置会缺少多样性。我们推测这使得小目标检测的在验证时的通用性变得很难;
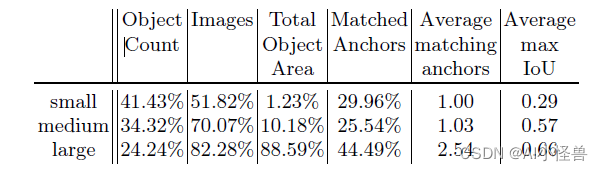
3)anchor难匹配问题。这主要针对anchor-based方法,由于小目标的gt box和anchor都很小,anchor和gt box稍微产生偏移,IoU就变得很低,导致很容易被网络判断为negative sample;
4)它们不仅仅是小,而且是难,存在不同程度的遮挡、模糊、不完整现象;
等等难点
参考论文:小目标检测研究进展
2. 小目标数据集
数据集下载地址:GitHub - YimianDai/sirst: A dataset constructed for single-frame infrared small target detection
Single-frame InfraRed Small Target
数据集大小:427张,进行3倍数据增强得到1708张,最终训练集验证集测试集随机分配为8:1:1

3.一种基于YOLOv8改进的高精度小目标检测算法
1)SPD-Conv特别是在处理低分辨率图像和小物体等更困难的任务时优势明显
2)引入Wasserstein Distance Loss提升小目标检测能力
3)YOLOv8中的Conv用cvpr2024中的DynamicConv代替
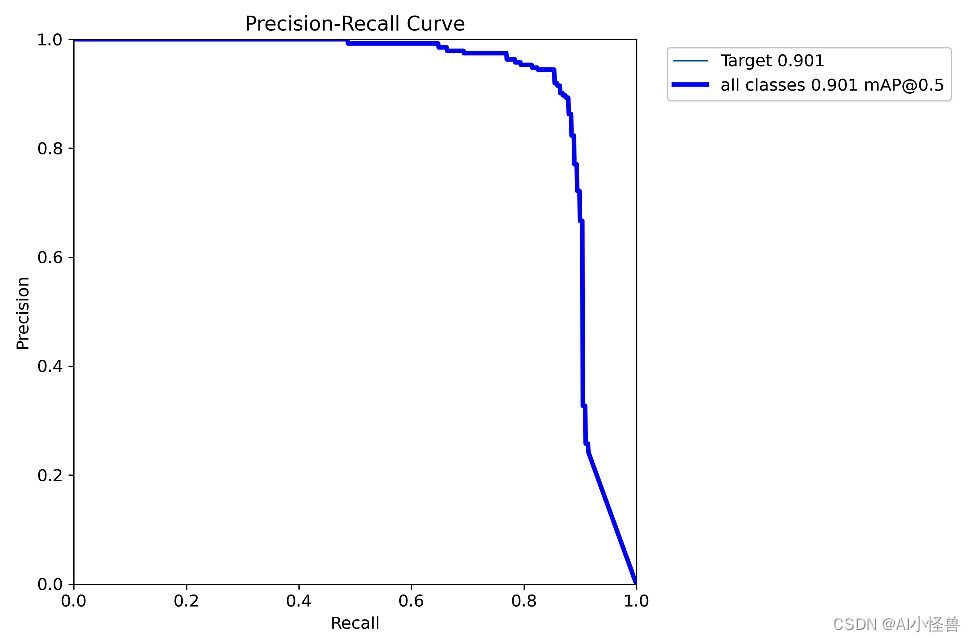
YOLOv8_SPD-DynamicConv summary (fused): 199 layers, 5181707 parameters, 0 gradients, 32.2 GFLOPsClass Images Instances Box(P R mAP50 mAP50-95): 100%|██████████| 6/6 [00:15<00:00, 2.58s/it]all 171 199 0.929 0.854 0.901 0.6233.1 loss优化
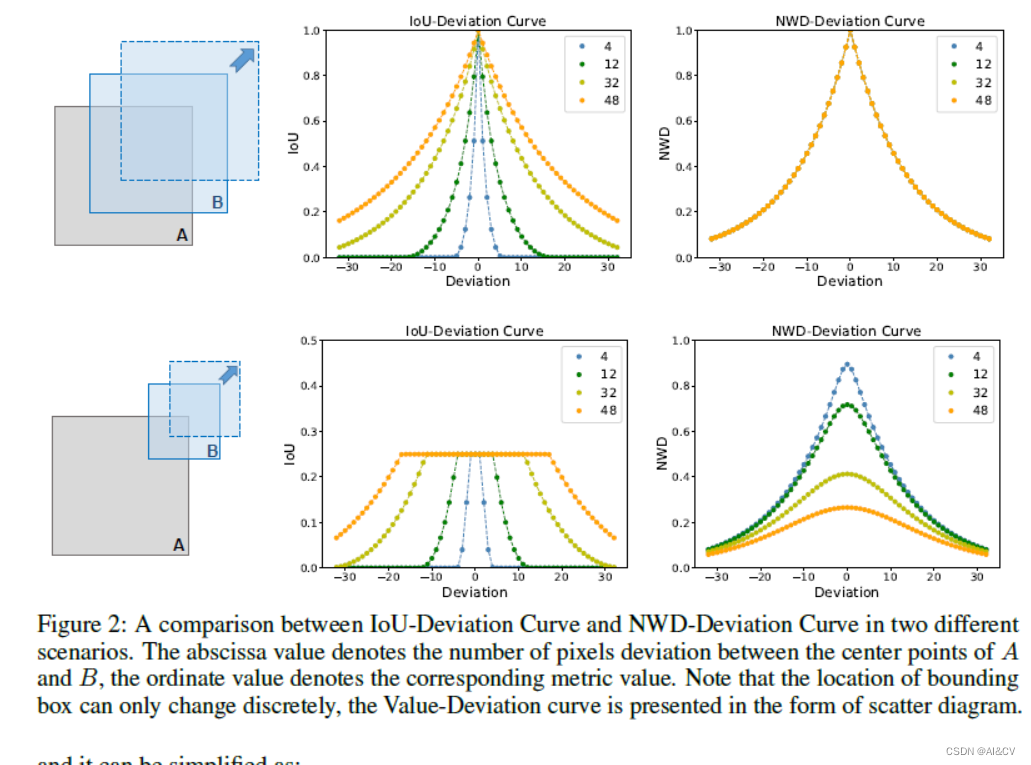
Wasserstein Distance Loss
1)分析了 IoU 对微小物体位置偏差的敏感性,并提出 NWD 作为衡量两个边界框之间相似性的更好指标;
2)通过将NWD 应用于基于锚的检测器中的标签分配、NMS 和损失函数来设计强大的微小物体检测器;
3)提出的 NWD 可以显着提高流行的基于锚的检测器的 TOD 性能,它在 AI-TOD 数据集上的 Faster R-CNN 上实现了从 11.1% 到 17.6% 的性能提升;
Wasserstein Distance Loss | 亲测在红外弱小目标检测涨点明显,map@0.5 从0.755提升至0.784
Yolov8红外弱小目标检测(2):Wasserstein Distance Loss,助力小目标涨点_AI小怪兽的博客-CSDN博客
| layers | parameters | GFLOPs | kb | mAP50 | |
| yolov8 | 168 | 3005843 | 8.1 | 6103 | 0.755 |
| Wasserstein loss | 168 | 3005843 | 8.1 | 6103 | 0.784 |
3.2 SPD-Conv
SPD-Conv由一个空间到深度(SPD)层和一个无卷积步长(Conv)层组成,可以应用于大多数CNN体系结构。我们从两个最具代表性的计算即使觉任务:目标检测和图像分类来解释这个新设计。然后,我们将SPD-Conv应用于YOLOv5和ResNet,创建了新的CNN架构,并通过经验证明,我们的方法明显优于最先进的深度学习模型,特别是在处理低分辨率图像和小物体等更困难的任务时。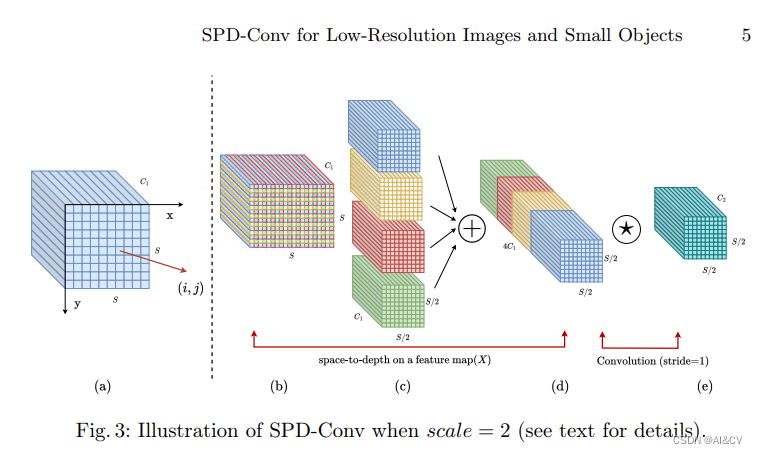
Yolov8红外弱小目标检测(4):SPD-Conv,低分辨率图像和小物体涨点明显_AI小怪兽的博客-CSDN博客
SPD-Conv | 亲测在红外弱小目标检测涨点明显,map@0.5 从0.755提升至0.875
| layers | parameters | GFLOPs | kb | mAP50 | |
| yolov8 | 168 | 3005843 | 8.1 | 6103 | 0.755 |
| yolov8_SPD | 174 | 3598739 | 49.2 | 7394 | 0.875 |
3.3 DynamicConv

论文: https://arxiv.org/pdf/2306.14525v2.pdf
摘要:大规模视觉预训练显著提高了大型视觉模型的性能。然而,我们观察到低FLOPs的缺陷,即现有的低FLOPs模型不能从大规模的预训练中获益。在本文中,我们引入了一种新的设计原则,称为ParameterNet,旨在增加大规模视觉预训练模型中的参数数量,同时最小化FLOPs的增加。我们利用动态卷积将额外的参数合并到网络中,而FLOPs仅略有上升。ParameterNet方法允许低flops网络利用大规模视觉预训练。此外,我们将参数网的概念扩展到语言领域,在保持推理速度的同时增强推理结果。在大规模ImageNet-22K上的实验证明了该方案的优越性。例如ParameterNet-600M可以在ImageNet上实现比广泛使用的Swin Transformer更高的精度(81.6%对80.9%),并且具有更低的FLOPs (0.6G对4.5G)。在语言领域,使用ParameterNet增强的LLaMA- 1b比普通LLaMA准确率提高了2%
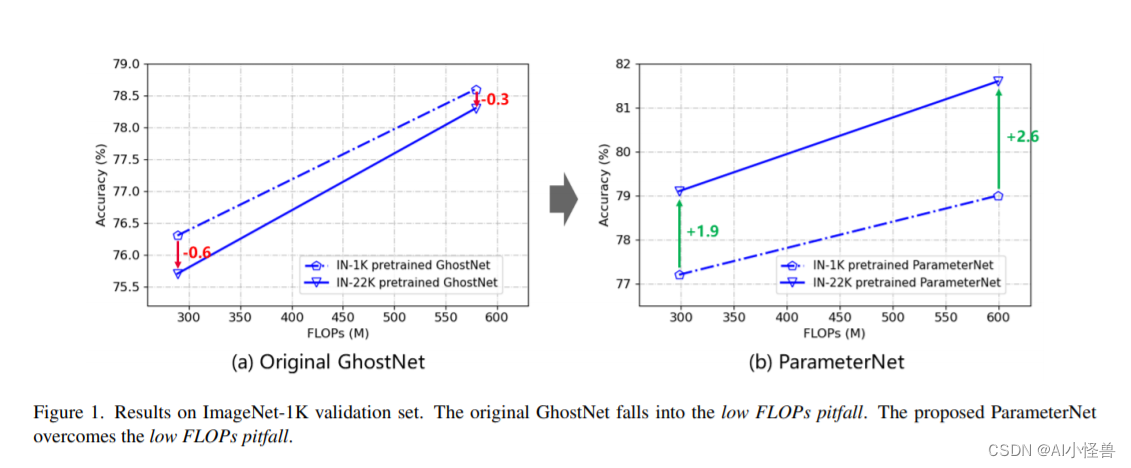
YOLOv8轻量化涨点改进: 卷积魔改 | DynamicConv | CVPR2024 ParameterNet,低计算量小模型也能从视觉大规模预训练中获益-CSDN博客
4.源码获取
关注下方名片点击关注,即可源码获取途径。
这篇关于一种基于YOLOv8改进的高精度红外小目标检测算法 (原创自研)的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!









