本文主要是介绍基于深度学习检测恶意流量识别框架(80+特征/99%识别率),希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
基于深度学习检测恶意流量识别框架
目录
- 基于深度学习检测恶意流量识别框架
- 简要
- 示例
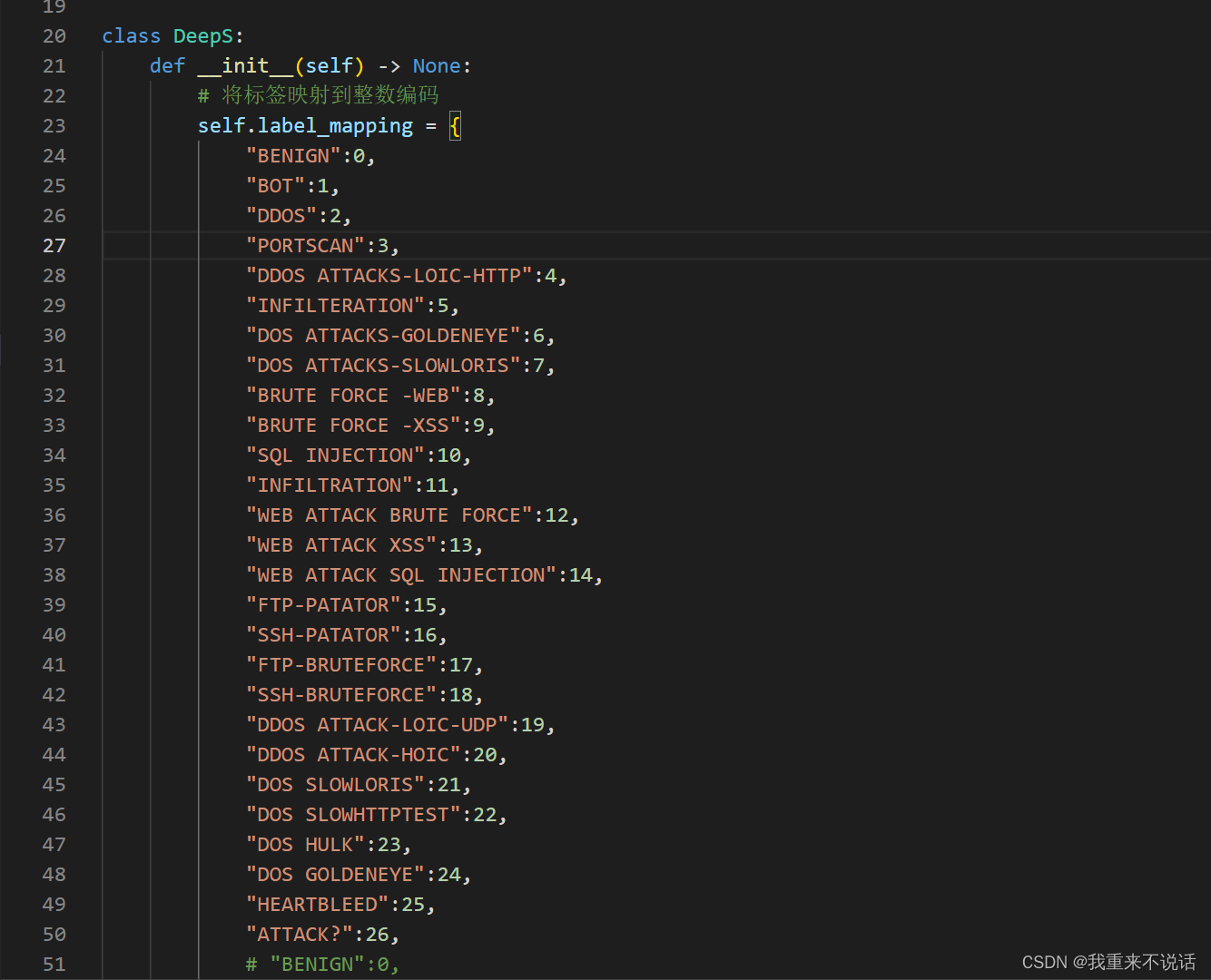
- a.检测攻击类别
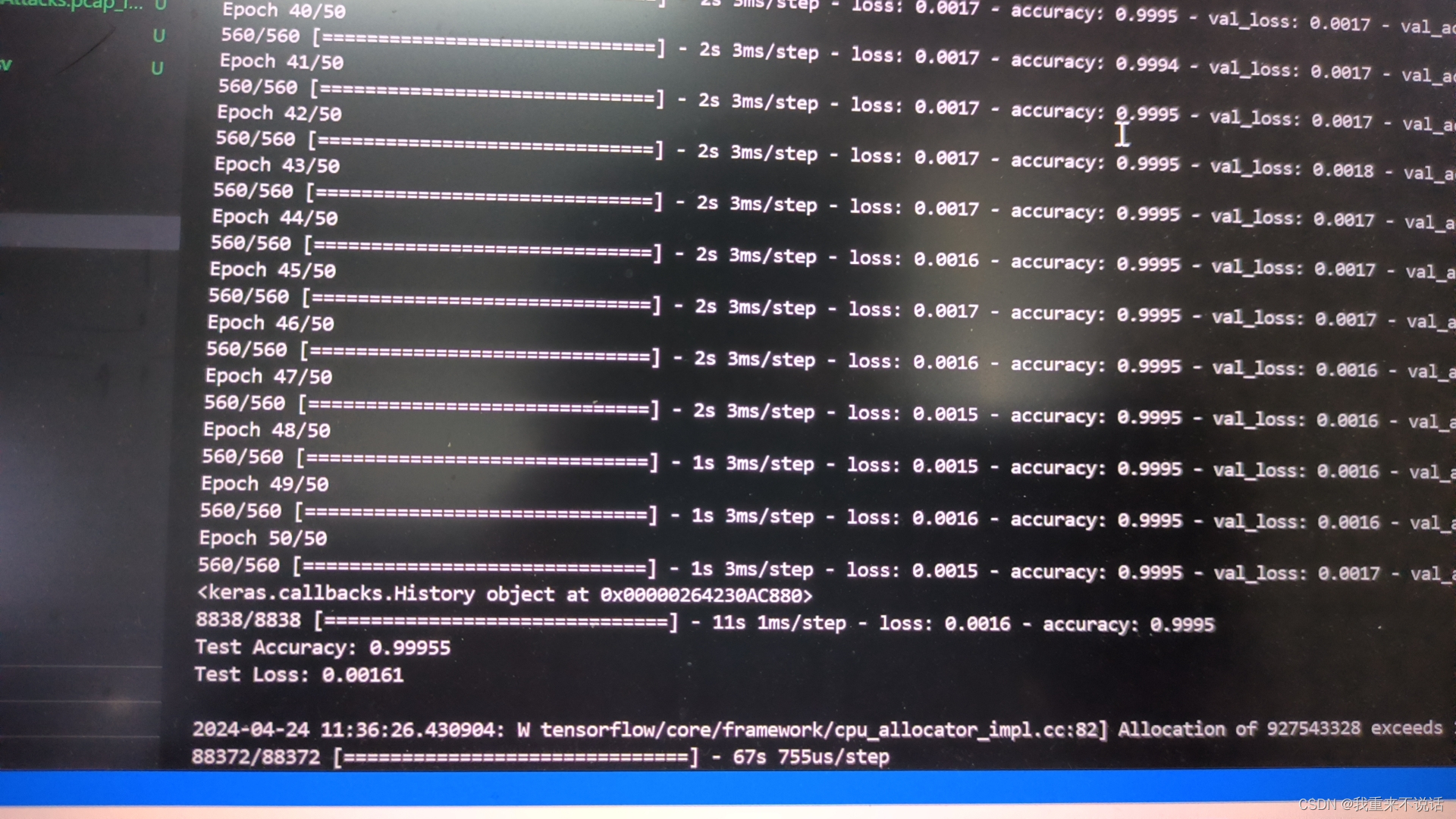
- b.模型训练结果输出参数
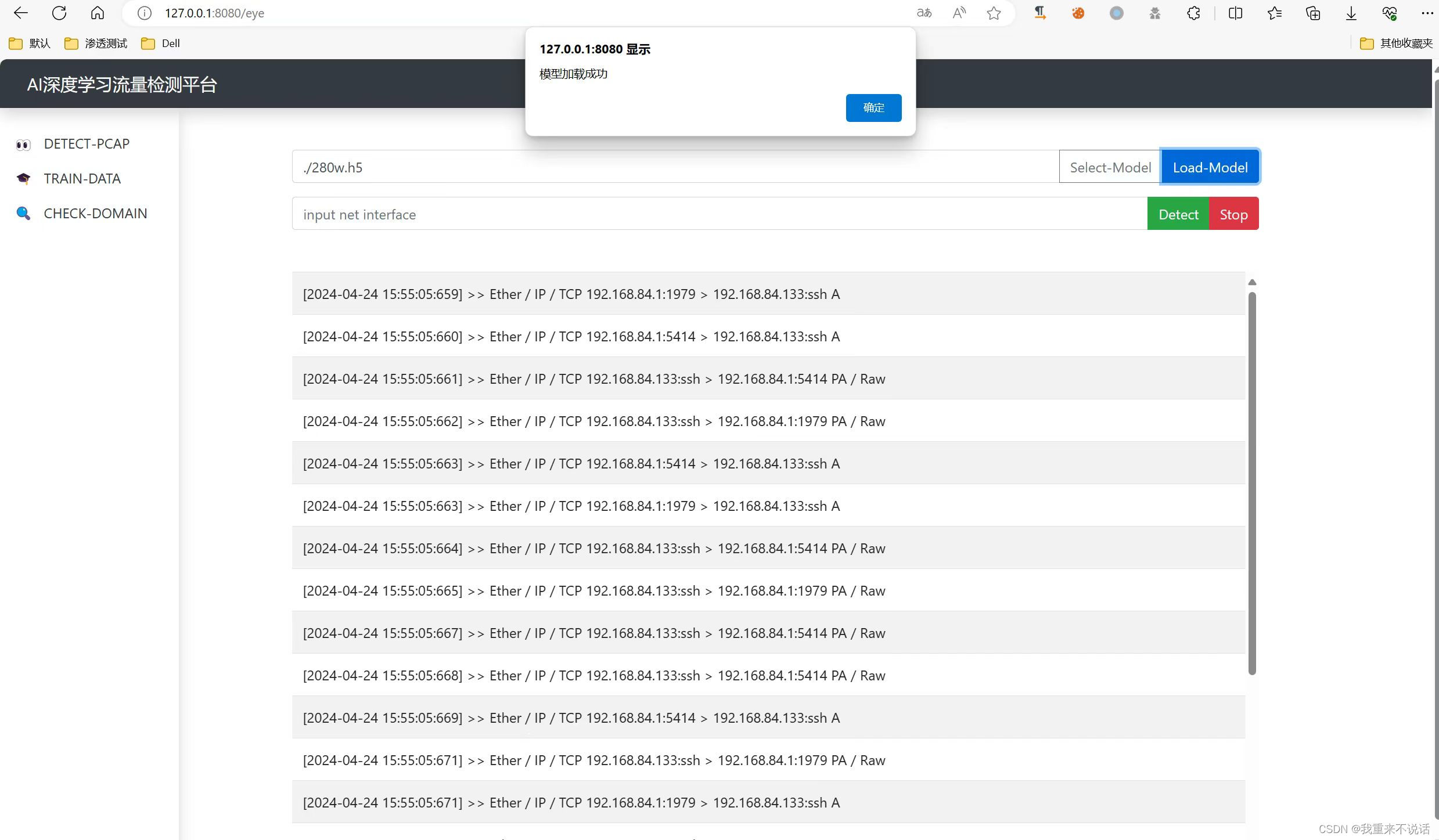
- c.前端检测页面
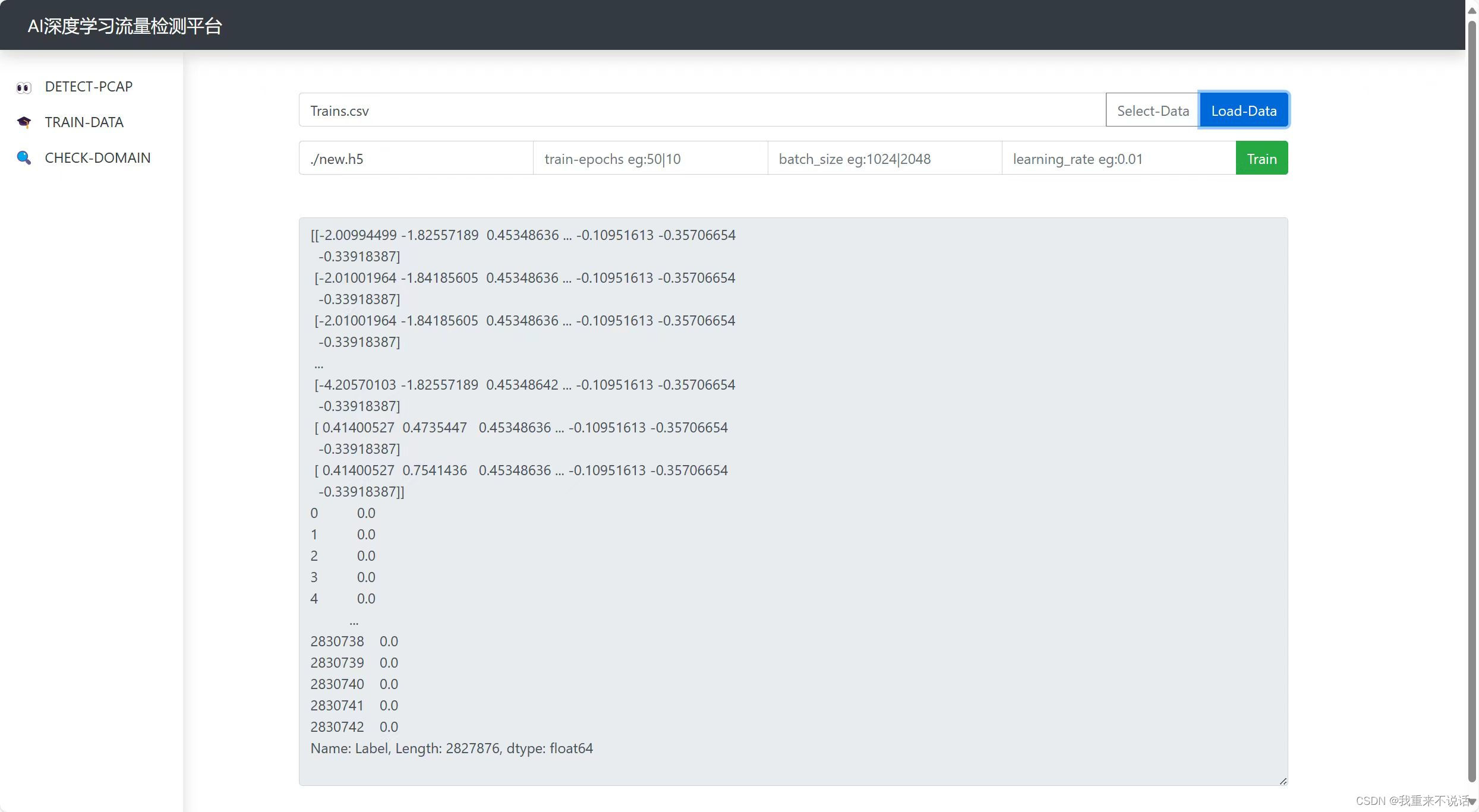
- d.前端训练界面
- e.前端审计界面(后续更新了)
- f.前端自学习界面(自学习模式转换)
- f1.自学习模式
- 核心代码示例
- a.代码结构
- b.数据预处理
- c.抓包模块
- d.数据库操作
- e.全局变量实现
简要
| 内容 | 说明 |
|---|---|
| 使用语言 | Python |
| 训练数据 | 2800w |
| 支持检测攻击方式 | 26种 |
| 深度学习库 | keras |
| Loss值 | 0.0023 |
| 准确值 | 99.9% |
| 检测方式 | 实时检测 |
| 数据库 | Sqlite |
| 呈现方式 | CS架构/web页面 |
| 附加功能 | 流量自学习训练模式(工作模式:对应正常流量,攻击模式:对应?ATTACK) |
示例
a.检测攻击类别
b.模型训练结果输出参数
c.前端检测页面
d.前端训练界面
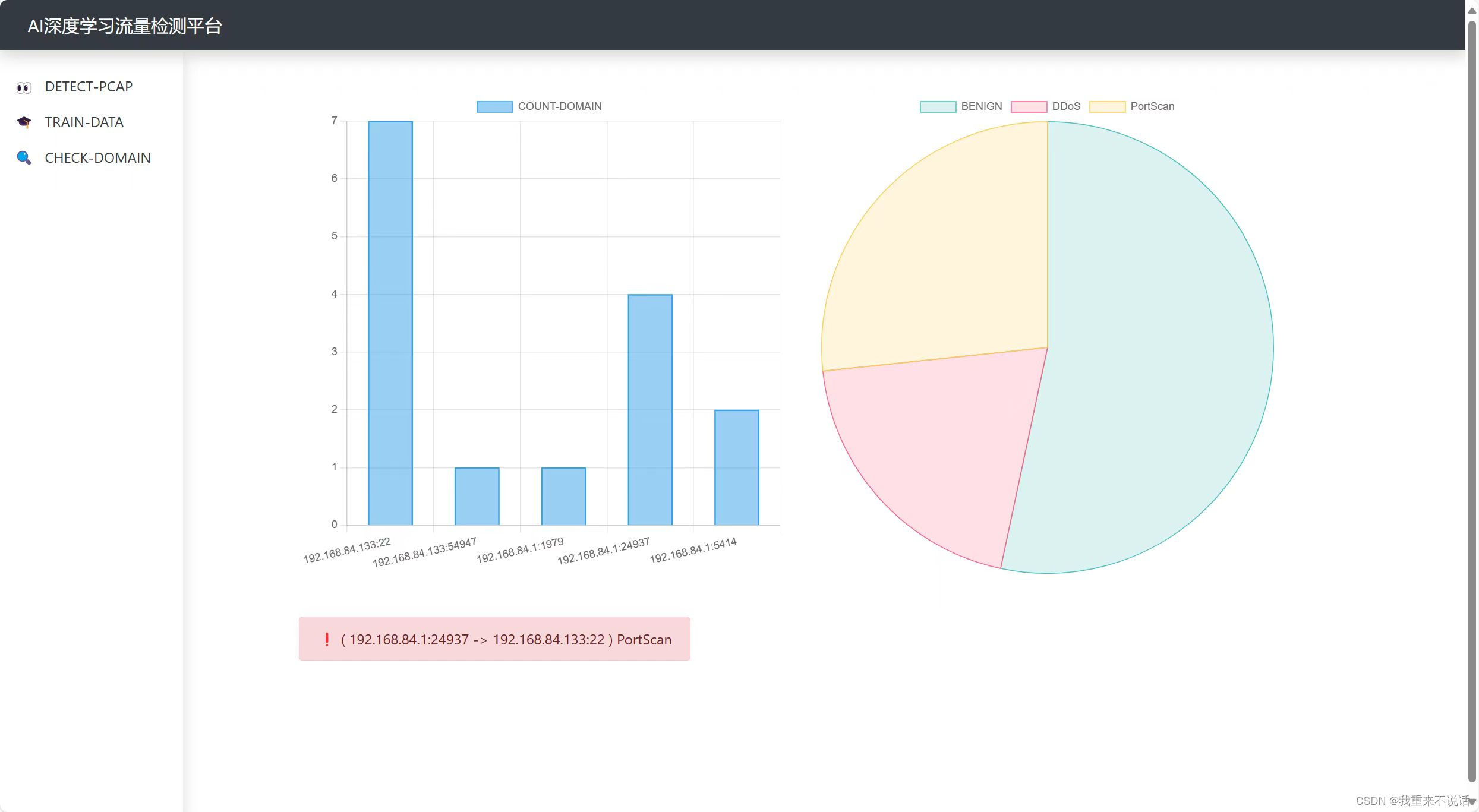
e.前端审计界面(后续更新了)
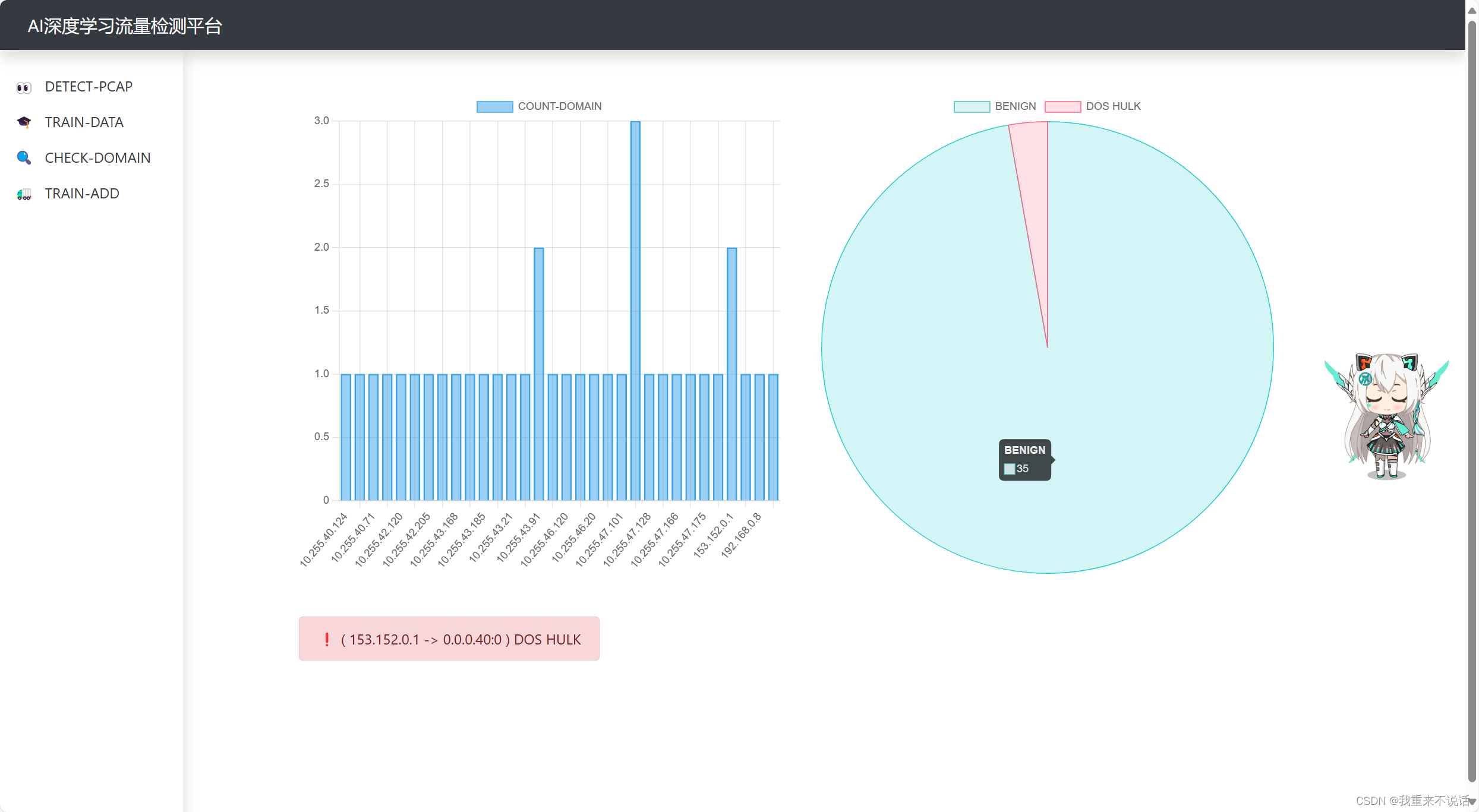
f.前端自学习界面(自学习模式转换)
f1.自学习模式
这里解释下:这里有两个模式,开启工作模式后,确保当前流量为正常流量,系统会自动标记并在达到阈值后进行训练,从而增加泛化能力,反之。
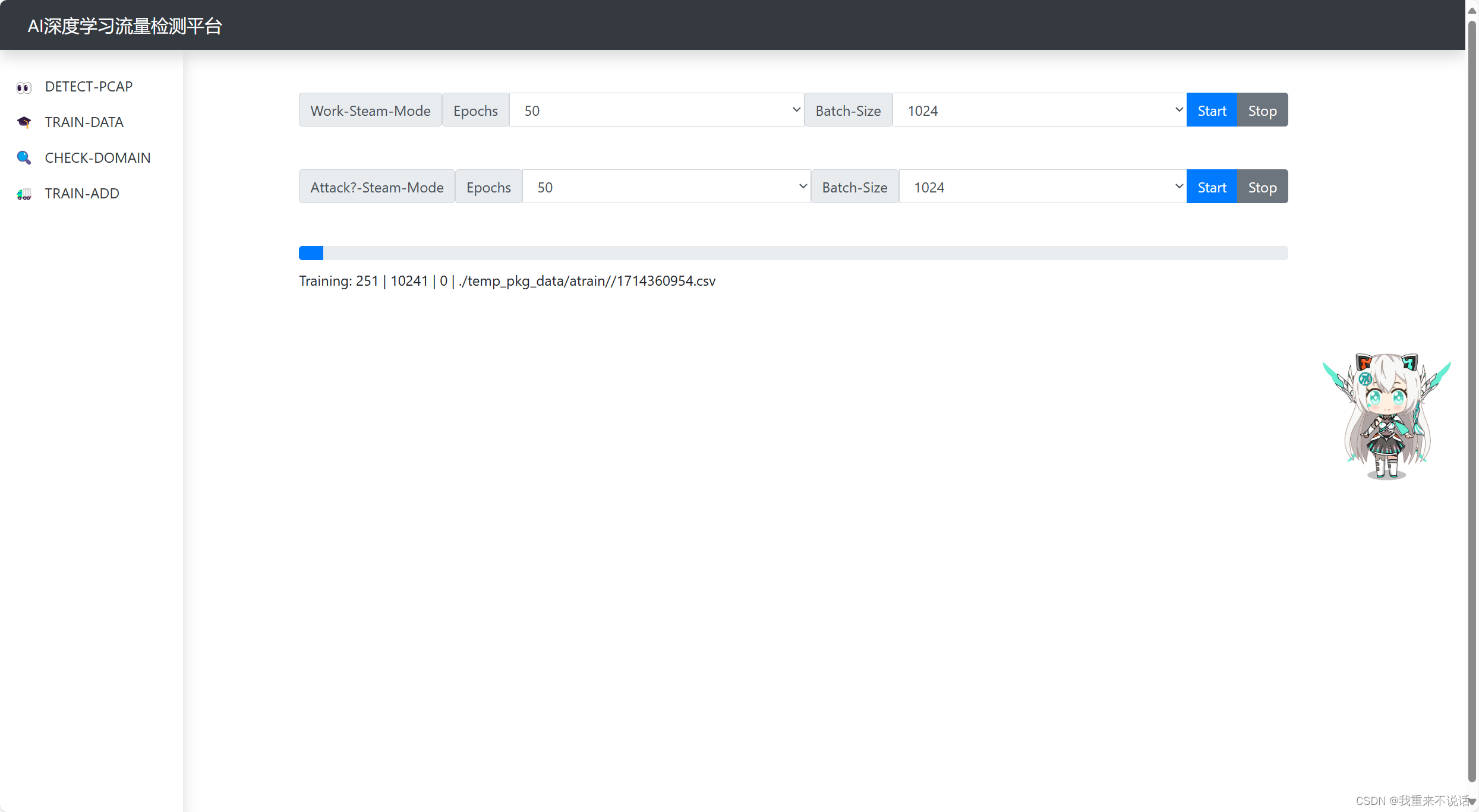
进度条显示内容解释:当前|总进度|训练轮数|源数据
核心代码示例
a.代码结构
b.数据预处理
def __serial(self,debug=0):self.data['Timestamp'] = self.data['Timestamp'].apply(lambda x: self.__timestamp_to_float(x))self.data['Dst_IP'] = self.data['Dst_IP'].apply(self.__ip_to_float)self.data['Src_IP'] = self.data['Src_IP'].apply(self.__ip_to_float)if debug:self.__pull(self.data,"d1.txt")self.data["Label"] = self.data["Label"].apply(self.__label_to_float)columns_to_convert = [col for col in self.data.columns if col not in ['Timestamp', 'Dst_IP', 'Src_IP',"Label"]]for col_name in columns_to_convert:self.data[col_name] = pd.to_numeric(self.data[col_name], errors='coerce')self.data = self.data.apply(pd.to_numeric, errors='coerce')self.data = self.data.fillna(0)inf_values = ~np.isfinite(self.data.to_numpy())self.data[inf_values] = np.nan # 替换为NaN,您也可以选择替换为其他合理值self.data = self.data.dropna() # 删除包含缺失值的行self.features = self.data.iloc[:, :-1]self.labels = self.data.iloc[:, -1] # 标签if debug:self.__pull(self.data,"d2.txt")self.scaler = StandardScaler()self.features = self.scaler.fit_transform(self.features)c.抓包模块
def packet_to_dict(packet):packet_dict = {}if const.cdist[const.pkg_id] > const.cdist[const.max_pkgn]:const.cdist[const.pkg_id] = 0packet_dict["data"] = packetpacket_dict["id"] = const.cdist[const.pkg_id]const.cdist[const.pkg_id] +=1if IP in packet:packet_dict["src_ip"] = packet[IP].srcpacket_dict["dst_ip"] = packet[IP].dstelse:packet_dict["src_ip"] = ""packet_dict["dst_ip"] = ""return packet_dictdef write_packet_summary(filename, packet_summary):with open(filename, 'a') as file:file.write(packet_summary + '\n')def listen(key,qkey,filename):# 定义回调函数来处理捕获到的数据包def packet_callback(packet):try:packet_info = packet_to_dict(packet)if packet_info != {}:const.cdist[qkey].put(packet_info)except Exception as e:log.Wlog(3,f"listen* {e}")try:timestamp = datetime.now().strftime('%Y-%m-%d %H:%M:%S:%f')[:-3]summary = packet.summary()packet_with_timestamp = f"[{timestamp}] >> {summary}"write_packet_summary(filename, packet_with_timestamp)maintain_packet_summary(filename, max_lines=20)except Exception as e:log.Wlog(3, f"listen* {e}")# return packet.summary()# 定义停止条件函数def stop_condition(packet):# print(const.cdist[key],key)return const.cdist[key]# 开始捕获数据包,使用 stop_filter 参数指定停止条件sniff(iface=const.cdist[const.net_interface],prn=packet_callback,stop_filter=stop_condition)
d.数据库操作
def data_init():# 连接到数据库,如果不存在则创建conn = sqlite3.connect(const.cdist[const.sql_dbp])# 创建游标对象cur = conn.cursor()# 创建数据表cur.execute('''CREATE TABLE IF NOT EXISTS pkg_data (id INTEGER PRIMARY KEY,src_ip TEXT,dst_ip TEXT,data TEXT,time1 INTEGER,label INTEGER)''')cur.close()conn.close()def get_sql_cur():# 连接到数据库,如果不存在则创建conn = sqlite3.connect(const.cdist[const.sql_dbp])# 创建游标对象cur = conn.cursor()return cur,conn
def close_sql(cur,conn):try:cur.close()conn.close()except:pass
# 添加数据pkg_data
def add_data(src_ip, dst_ip, data, time1, label):cur,conn = get_sql_cur()cur.execute("INSERT INTO pkg_data (src_ip, dst_ip, data, time1, label) VALUES (?, ?, ?, ?, ?)", (src_ip, dst_ip, data, time1, label))conn.commit()close_sql(cur,conn )# 删除指定 src_ip 的数据
def delete_data(src_ip):cur,conn = get_sql_cur()cur.execute("DELETE FROM pkg_data WHERE src_ip=?", (src_ip,))conn.commit()close_sql(cur,conn )# 查询指定时间戳范围内的域名及出现次数
def query_data_k1(start_timestamp, end_timestamp):cur,conn = get_sql_cur()cur.execute("SELECT src_ip, COUNT(*) FROM pkg_data WHERE time1 BETWEEN ? AND ? GROUP BY src_ip", (start_timestamp, end_timestamp))rows = cur.fetchall()close_sql(cur,conn )return rowse.全局变量实现
# const.py
cdist = {}
def _const_key_(key, value):cdist[key] = value# run.py
def init():odir = os.getcwd()signal.signal(signal.SIGINT, quit) signal.signal(signal.SIGTERM, quit)const._const_key_(const.log_path, f"{odir}/plug/utils.log")const._const_key_(const.temp_pkg, f"{odir}/plug/temp.pkg")const._const_key_(const.out_csv_d, f"./temp_pkg_data/csv/")const._const_key_(const.out_pcap_d, f"./temp_pkg_data/pcap/")const._const_key_(const.train_info,f"{odir}/plug/train.info")const._const_key_(const.sql_dbp,f"{odir}/plug/pkg_data.db")const._const_key_(const.out_atrain_d,f"./temp_pkg_data/atrain/")const._const_key_(const.Base_h5,f"{odir}/2800w-base.h5")const._const_key_(const.deeps,deep_s.DeepS())const._const_key_(const.AddTrain_Stream_Mode,{"mode":0,"args":"","key":"","label":"","csvp":"","echo":0}) # 0不进行模式,1进行正常流量训练const._const_key_(const.Pkg_DATA_List,[])const._const_key_(const.max_pkgn,2000)const._const_key_(const.MAX_ADDTrain_n,10241)const._const_key_(const.pkg_id,0)const._const_key_(const.log_level, 3)const._const_key_(const.queue1, Queue(maxsize=65535)) # 创建队列data.data_init()f= open(const.cdist[const.train_info], 'w')f.close()CronWork(100,odir)
这篇关于基于深度学习检测恶意流量识别框架(80+特征/99%识别率)的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!





