本文主要是介绍基于残差神经网络的汉字识别系统+pyqt前段界面设计,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
研究内容:
中文汉字识别是一项具有挑战性的任务,涉及到对中文字符的准确分类。在这个项目中,目标是构建一个能够准确识别中文汉字的系统。这个任务涉及到数据集的收集、预处理、模型训练和评估等步骤。尝试了使用残差神经网络(ResNet)、VGG和AlexNet等经典模型来解决中文汉字识别任务。这些模型都在图像识别领域取得了显著的成就,但各自具有不同的架构和特点。
研究成果:
成功构建了一个中文汉字识别系统,可以识别中文汉字。
借助QT实现了一个具有良好用户体验的前端界面,使得用户可以轻松地使用识别系统
主要内容:
项目分为三个文件:
运行process.py可以将data文件下的图片数据集保存成txt格式记录。
运行modeltrain.py可以读取txt记录的图片数据进行训练,训练的模型保存在本地,其中提供了10多种的模型可以任意的切换。包括:efficientnet、Alexnet、DenseNet、DLA、GoogleNet、Mobilenet、ResNet、ResNext、ShuffleNet、Swin_transformer、VGG等。训练结束后保存评价指标图在result文件下:
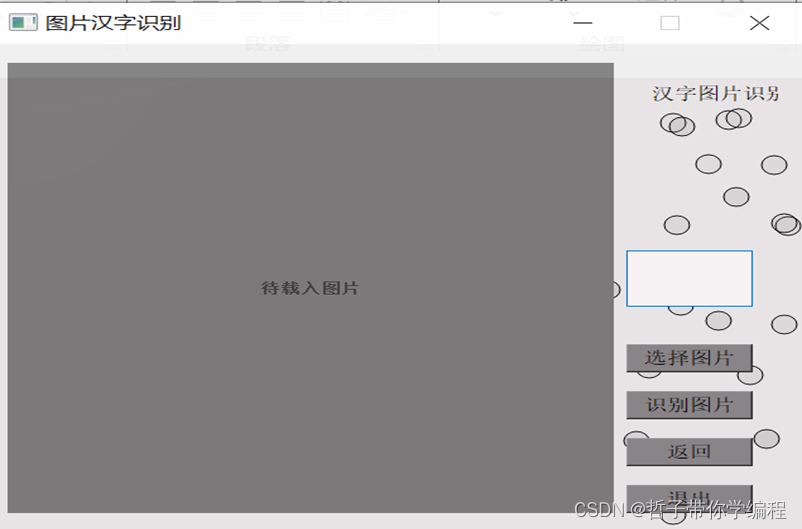
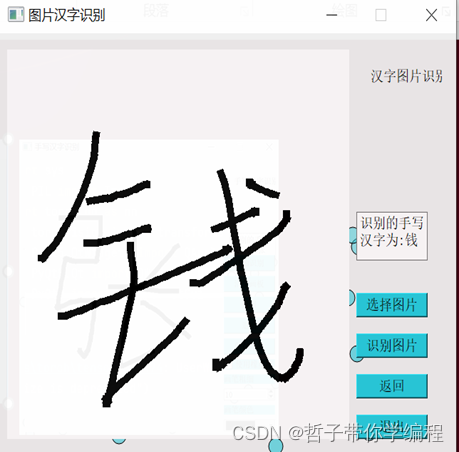
最后运行presentation.py可以展示一个可视化的交互界面,通过点击按钮来识别,这里弹出的界面上提供了第一个按钮为在画板上控制鼠标写出汉字识别。
第二个按钮为加载汉字图片进行识别。先是第一个按钮点击后,左侧为鼠标手写汉字界面,右侧为预测结果和控制按钮。第二个按钮和第一个按钮界面展示一样,只不过手写变成了加载本地图片来识别。
项目总体思路:

项目各项指标图



创新点 idea:
1,深度学习模型选择与优化:
采用了残差神经网络(ResNet)作为其中一个尝试的模型。相比于传统的卷积神经网络,ResNet引入了残差连接,可以更深地训练网络而不会出现梯度消失或梯度爆炸的问题,从而提高了模型的性能。
对选择的模型进行了优化和调参,尝试了不同的网络深度、学习率、批量大小等超参数的组合,以获得最佳的识别性能。
2,中文汉字识别任务的定制化处理:
针对中文汉字的特点,进行了相应的数据预处理和特征提取工作。可能包括字符分割、尺寸标准化、灰度处理等,以确保输入模型的数据质量和一致性。
对于汉字字符的识别,需要考虑到汉字的复杂结构和多样性,因此可能采用了适合处理复杂结构的模型结构或特征提取方法。
3,前端界面设计的创新:
使用PyQt构建了前端界面,为用户提供了直观友好的交互体验。PyQt是一个功能强大的Python框架,能够快速构建跨平台的图形用户界面。
前端界面的设计可能包括了图像上传功能、识别结果展示、反馈机制等,以提升用户的使用便捷性和体验感。
4,项目整合与应用实践:
将深度学习模型与前端界面有机地结合在一起,构建了一个完整的中文汉字识别系统。这种整合将模型的研究与应用实践相结合,使得研究成果更具实用性和可操作性。
项目在实践中对深度学习模型和前端界面的结合方式进行了探索和实践,积累了相关经验和教训,为类似领域的研究和应用提供了有益的参考。
应用价值:
教育领域:
该系统可以应用于教育领域,帮助学生学习汉字识别和书写。学生可以通过输入手写或印刷
的汉字图片,快速获取识别结果,从而加强对汉字形状和结构的理解,提高汉字识别能力。
文档处理与数字化:
在文档处理领域,该系统可以用于自动识别扫描或拍摄的文档中的汉字内容,实现文档的快速数字化和文字提取。这对于图书馆、档案馆等机构的文献数字化工作具有重要意义。
智能设备交互:
该系统可以集成到智能设备中,用于识别用户手写输入的汉字,从而实现智能设备与用户的交互。例如,在智能手机、平板电脑等设备上集成该系统,可以为用户提供更便捷的手写输入方式。
跨文化交流与翻译:
对于非汉字母母语国家的人士,该系统可以用于帮助他们识别汉字并理解汉字文本内容,促进跨文化交流与理解。
此外,该系统也可以作为汉字翻译工具的一部分,为汉字文本提供自动识别和翻译的功能,方便非汉字母母语国家的用户阅读汉字文本。
辅助工具与辅助技术:
该系统可以作为辅助工具,帮助视力受损或有阅读障碍的人士识别汉字文本,提高其阅读和生活质量。
在特定行业中,如医学、法律等领域,该系统也可以作为辅助技术,帮助专业人士处理和理解汉字文本。
项目链接:https://pan.baidu.com/s/1Whp88J4q7RGWRpeFtOHu0A
提取码需要可以私信作者
所尝试过的模型:(压缩包里都有,可以随意自己选择运行哪一个模型)

运行效果





这篇关于基于残差神经网络的汉字识别系统+pyqt前段界面设计的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!









