本文主要是介绍上下文注意力 CoT Attention | Contextual Transformer Networks for Visual Recognition,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!

论文名称:《Contextual Transformer Networks for Visual Recognition》
论文地址:https://arxiv.org/pdf/2107.12292.pdf
代码地址:https://github.com/JDAI-CV/CoTNet
具备自注意力机制的 Transformer 已经引领了自然语言处理领域的革命,并且最近也在许多计算机视觉任务中以出色的结果启发了类似 Transformer 风格的架构设计的出现。然而,大多数现有设计直接在二维特征图上使用自注意力来基于每个空间位置的孤立查询和键对获取注意力矩阵,但却未充分利用相邻键之间的丰富上下文信息。在这项工作中,我们设计了一种新颖的 Transformer 风格模块,即上下文 Transformer (CoT)块,用于视觉识别。这种设计充分利用了输入键之间的上下文信息,以引导动态注意力矩阵的学习,从而增强了视觉表示的能力。在技术上,CoT块首先通过3×3卷积对输入键进行上下文编码,从而得到输入的静态上下文表示。我们进一步将编码的键与输入查询连接起来,通过两个连续的 1×1 卷积学习动态多头注意力矩阵。学得的注意力矩阵与输入值相乘,以实现输入的动态上下文表示。最终将静态和动态上下文表示的融合作为输出。从视角上看,我们的 CoT 块具有吸引力,因为它可以很容易地替换ResNet架构中的每个 3×3 卷积,从而得到一个名为上下文Transformer网络(CoT-Net)的Transformer风格主干。通过广泛的实验证明了CoT-Net作为更强大主干网络的优越性,涵盖了各种应用领域(例如图像识别、目标检测和实例分割)。
问题背景
传统的自注意力机制在视觉识别任务中表现良好,但在二维特征图上通常忽视了相邻键之间的丰富上下文。这可能导致特征表示不够丰富,尤其是对于需要长距离交互的任务。因此,为了解决这个问题,Contextual Transformer (CoT) 提出了一种新的变压器模块,旨在充分利用输入键之间的上下文信息来指导动态注意力矩阵的学习。
核心概念
CoT 模块的核心理念是结合卷积和自注意力机制,利用3×3卷积在输入键中提取静态上下文信息,然后通过两个连续的1×1卷积在动态多头自注意力矩阵上进行操作。这种方法融合了静态和动态的上下文信息,使得注意力矩阵更能适应输入特征图中的各种模式,从而增强特征表示能力。
模块的操作步骤
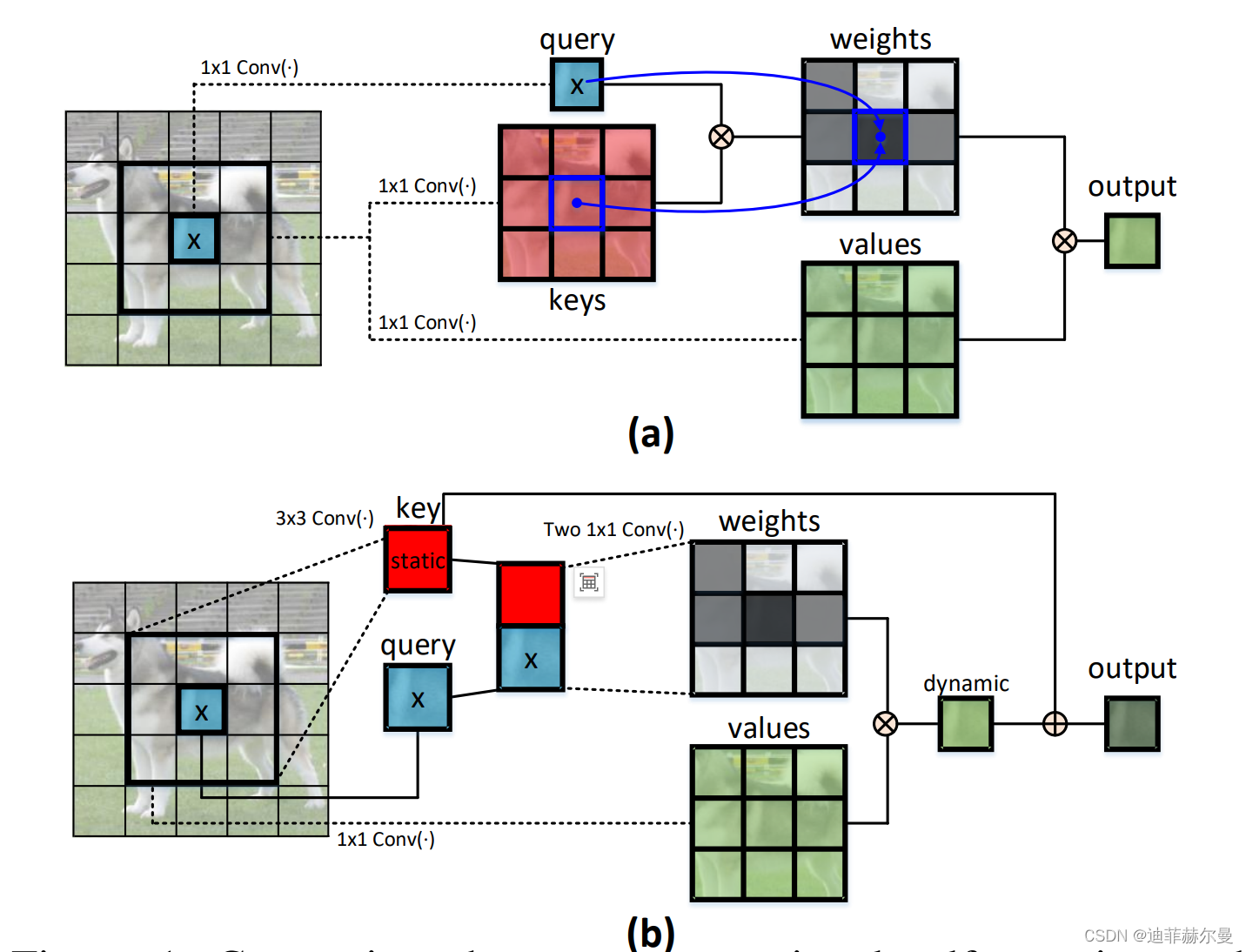
传统自注意力机制与我们的上下文变换器 (CoT) 模块的比较:(a) 传统的自注意力机制仅利用孤立的查询-键值对来计算注意力矩阵,忽略了键值之间丰富的上下文关系。相比之下,(b) CoT 模块首先通过 3×3 卷积挖掘键值之间的静态上下文。接着,基于查询和上下文化的键值,利用两个连续的 1×1 卷积来执行自注意力,产生动态上下文。静态和动态上下文最终融合为输出。
CoT模块的操作步骤包括以下几个关键环节:
- 上下文编码:使用
3×3卷积在输入键上提取静态上下文,生成静态上下文表示。 - 动态多头注意力:将上下文编码后的键与输入查询连接,然后使用两个连续的
1×1卷积来学习动态多头注意力矩阵。 - 上下文融合:将动态多头注意力矩阵与输入值相乘,以获得动态上下文表示。最后,将静态和动态上下文融合以作为最终输出。
文章贡献
本文的主要贡献在于提出了一种新的Transformer模块,称为Contextual Transformer (CoT),它可以通过上下文信息来指导自注意力的学习。这种模块在不增加参数和计算负担的情况下,可以增强视觉表示能力。CoT模块可以轻松替换ResNet架构中的3×3卷积,从而创建一种新的Contextual Transformer Networks (CoTNet)。实验结果表明,这种模块在图像识别、目标检测和实例分割等任务中表现出色。
实验结果与应用
实验结果显示,CoTNet在多种计算机视觉任务中取得了优异的性能。在ImageNet图像识别任务中,CoTNet在top-1和top-5准确率上超过了许多其他骨干网络。对于目标检测和实例分割任务,CoTNet在COCO数据集上的表现也非常出色,进一步验证了这种模块的通用性和有效性。
对未来工作的启示
CoT模块的成功展示了通过上下文信息来增强自注意力的潜力。未来的研究可以进一步探索在不同的网络架构中应用这种机制,或者将其与其他注意力机制相结合。此外,研究人员还可以考虑将这种方法应用于其他领域,如自然语言处理和音频分析,以进一步拓展其应用范围。
代码
import numpy as np
import torch
from torch import flatten, nn
from torch.nn import init
from torch.nn.modules.activation import ReLU
from torch.nn.modules.batchnorm import BatchNorm2d
from torch.nn import functional as Fclass CoTAttention(nn.Module):def __init__(self, dim=512, kernel_size=3):super().__init__()self.dim = dimself.kernel_size = kernel_sizeself.key_embed = nn.Sequential(nn.Conv2d(dim,dim,kernel_size=kernel_size,padding=kernel_size // 2,groups=4,bias=False,),nn.BatchNorm2d(dim),nn.ReLU(),)self.value_embed = nn.Sequential(nn.Conv2d(dim, dim, 1, bias=False), nn.BatchNorm2d(dim))factor = 4self.attention_embed = nn.Sequential(nn.Conv2d(2 * dim, 2 * dim // factor, 1, bias=False),nn.BatchNorm2d(2 * dim // factor),nn.ReLU(),nn.Conv2d(2 * dim // factor, kernel_size * kernel_size * dim, 1),)def forward(self, x):bs, c, h, w = x.shapek1 = self.key_embed(x) # bs,c,h,wv = self.value_embed(x).view(bs, c, -1) # bs,c,h,wy = torch.cat([k1, x], dim=1) # bs,2c,h,watt = self.attention_embed(y) # bs,c*k*k,h,watt = att.reshape(bs, c, self.kernel_size * self.kernel_size, h, w)att = att.mean(2, keepdim=False).view(bs, c, -1) # bs,c,h*wk2 = F.softmax(att, dim=-1) * vk2 = k2.view(bs, c, h, w)return k1 + k2if __name__ == "__main__":input = torch.randn(64, 256, 8, 8)model = CoTAttention(dim=256, kernel_size=3)output = model(input)print(output.shape)这篇关于上下文注意力 CoT Attention | Contextual Transformer Networks for Visual Recognition的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!






