本文主要是介绍DIN特征加权、POSO特征增强、SENET特征选择,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
本文转自:DIN、POSO、SENet 聊聊推荐模型中常用的Attention-腾讯云开发者社区-腾讯云
一、前言
聊起模型结构的时候,经常听做推荐的同学说:
"这里加了个self-attention" "类似于一个SENet" "一个魔改的POSO" "DIN就是一个attention" ......
这些常见的模块、模型,听完之后很多时候还是一知半解,看了几篇模型的知乎,感觉长得都挺像的,为了把这些模型都摸清楚,还是把论文都翻出来读了一遍。本文将以推荐系统中的特征选择为例聊聊这几个模型怎么做到模块化使用,并加上一些自己个人的理解,如有不对欢迎评论区指正!
二、推荐系统例子
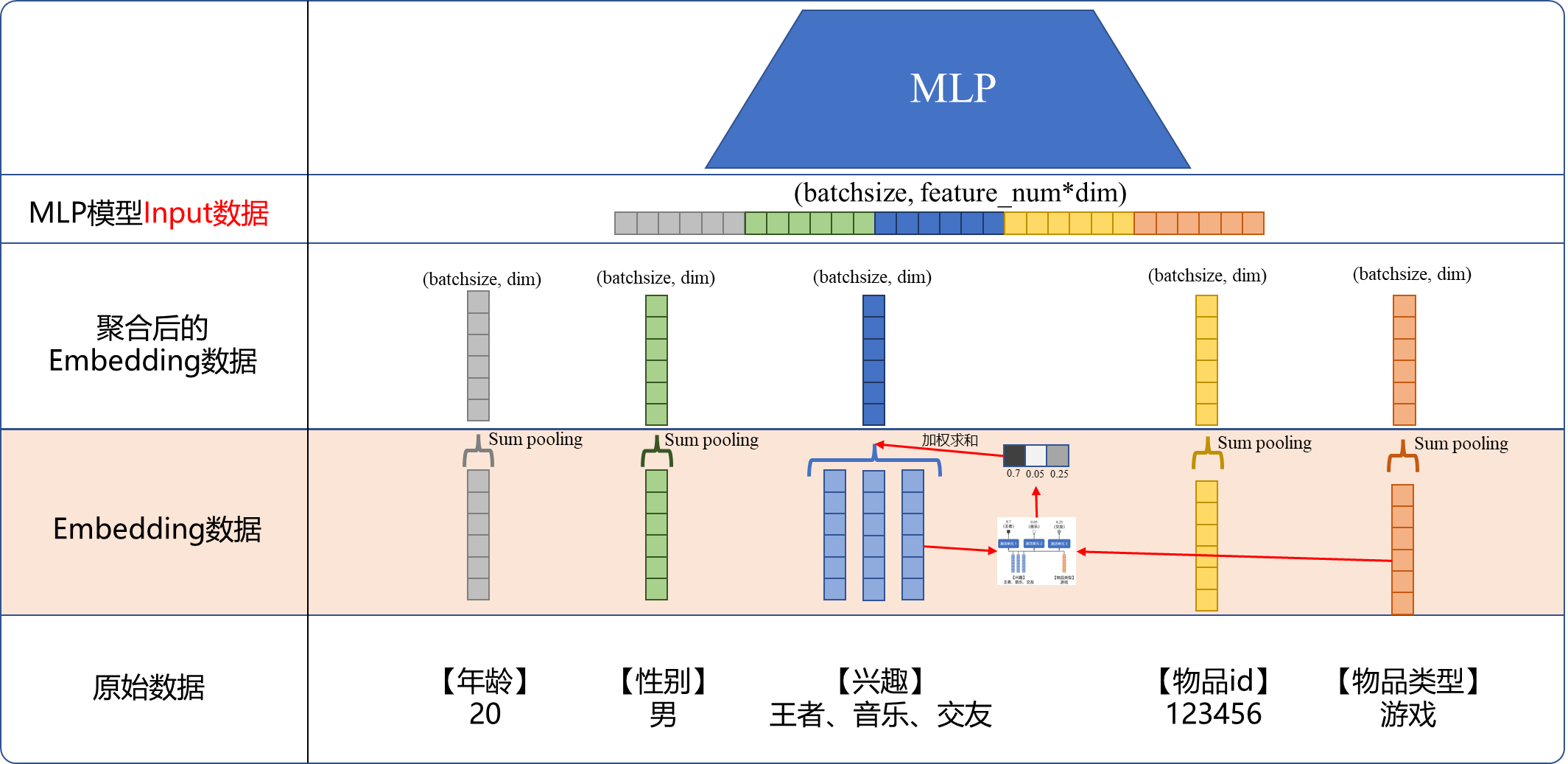
先举一个常见推荐的例子,做推荐模型的大家应该都熟悉,最简单的数据通常包括两方面:用户特征、物品特征,以MLP模型为例,下图展示了基本流程,从数据的角度简单说一下下图,主要分为4部分:
- 原始数据:这里就是我们最原始的数据,字符串形式。
- Embedding数据:通过把原始数据hash成key,再构建一个词典,一个key对应一个初始化的
dim维度的向量。此时注意,像【兴趣】这种特征,由于这个用户有3种,这里需要embedding成3个独立的向量,也就是"王者"、"音乐"、"交友"各一个向量。 - 聚合后的Embedding数据:聚合通常使用sum pooling(对应元素相加),也可以使用avg pooling(对应元素取均值)。这么做默认就是每个特征同样重要,比如【兴趣】里面,"音乐"和"交友"是相同权重的。如果一个特征里只有一个key,比如【年龄】、【性别】,那聚合之后相当于没有任何变化;如果是多个key,比如【兴趣】,那就会将多个key的Embedding聚合。
- MLP模型的Input数据:将上一步获得的5个向量按"头接屁股"的方式拼成一个长长的向量。
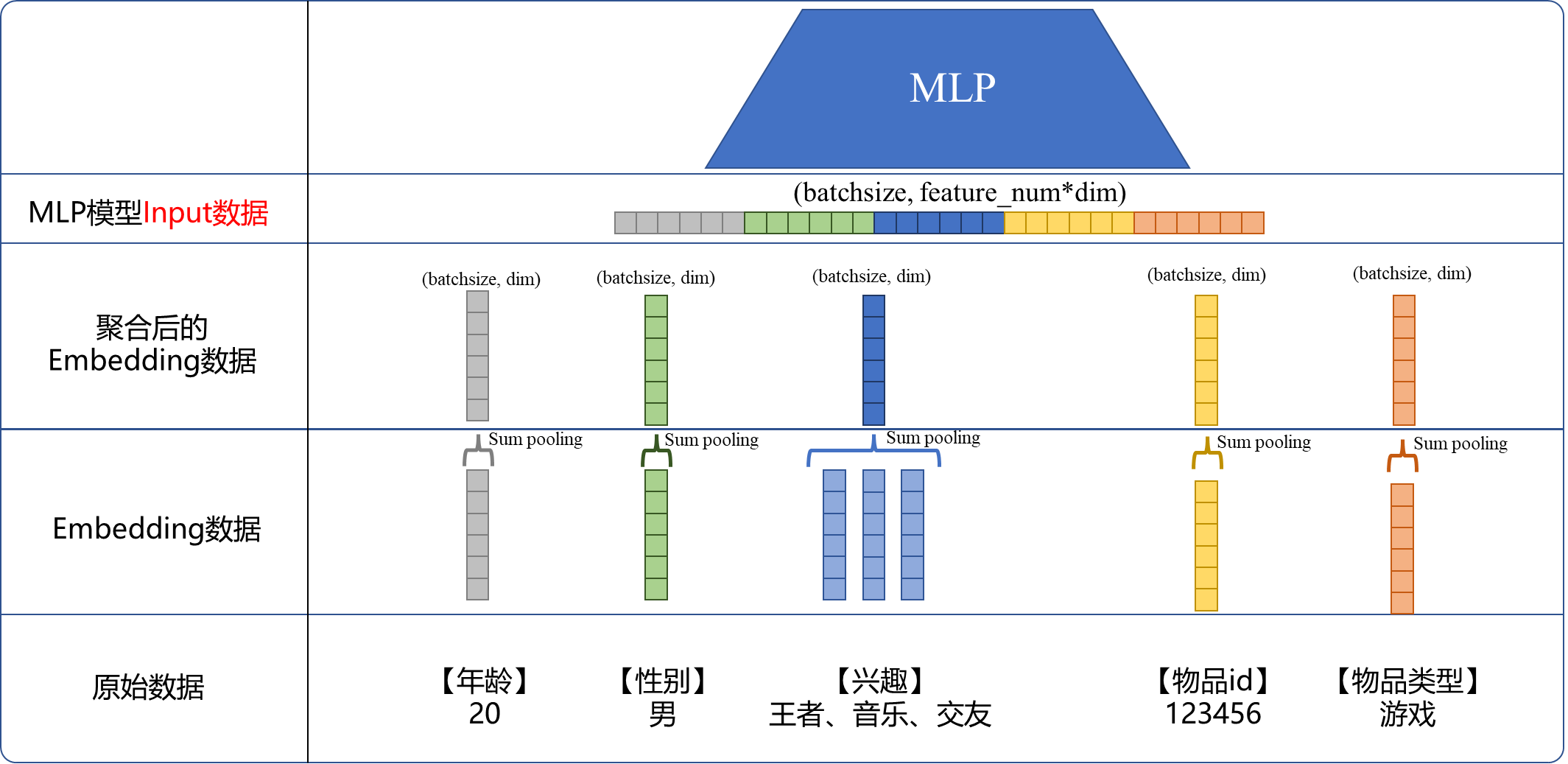
通过上面一通操作可以把:年龄:20,性别:……的数据转换成模型所需要的tensor。此时通常是(batchsize, feature_num, dim)的形式:
batchsize是批大小,比如512;feature_num是特征数量,在上图中就是5;dim是每一个特征的维度,比如16。
为啥要把最基础的数据输入说这么清楚呢,因为后面要说的POSO、SENet、DIN进行特征选择,本质上就是在这个基础上改变的,下面分别解释这些模型(模块)。
3. SENet
先说说SENet,最初提出是在CV领域,模型目的按照作者的原话是:
Our goal is to ensure that the network is able to increase its sensitivity to informative features so that they can be exploited by subsequent transformations, and to suppress less useful ones. (目的是希望提高网络对特征的敏感性,更好的利用特征并抑制不太有用的特征)
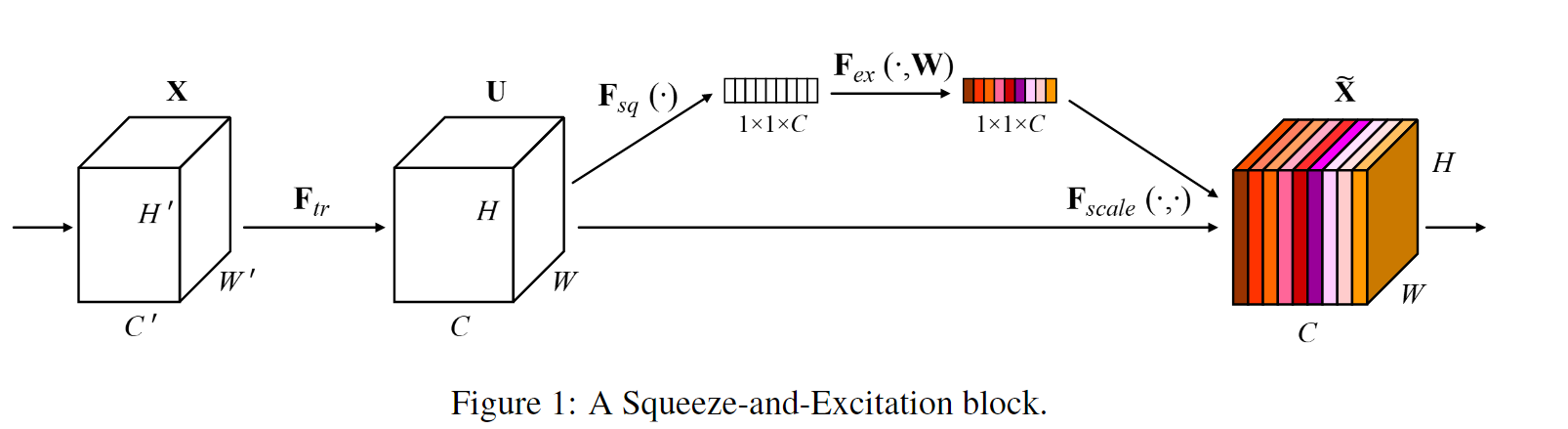
于是便提出了以上的模型,如果放在推荐系统里面呢,上图的一些概念应该被替换:
- H(高)、W(宽)应该被替换成
dim - C(Channel)应该被替换成
feature_num
放在上面的例子里面,整个过程如下:
1. SENet就是把初始数据为(batchsize, feature_num, dim)的特征先压缩成(batchsize, feature_num, 1)接着拿着这个压缩的特征过一个两层MLP,最后用sigmoid输出,得到一个(batchsize, feature_num, 1)形式的权重。

2. 接着拿着这个权重分别乘回每一个聚合后的Embedding,得到新的聚合后的Embedding数据。

如果按照SENet的原文的理解,应当就是这么处理,不难看出来,其实就是给feature_num的每个特征不同的权重。因为在推荐系统中,feature_num可以类比成CV里面的Channel。其实到这里就有一些疑问了:
- 为什么SENet在论文中是压缩两个维度(H、W),而上面的流程只压缩了
dim? 答:因为图片有长宽、相比于推荐系统多一个维度,所以原生的SENet需要压缩两个维度。并且由于是两个维度原文压缩使用是avg pooling,在推荐里面只有一个维度可以使用dense层代替。 - 为什么是给
feature_num的每个特征不同的权重,而不是dim?不能做成给不同元素不同的权重吗? 答:原生SENet目的是“解决卷积神经网络在处理图像时对于通道相关特征的建模能力不强的问题”,因此照搬过来的话就是给feature_num不同的权重。如果非要做成给不同元素不同的权重,即压缩成(batchsize, 1, dim)的形式,再做加权,个人认为也可以完全没有问题的。相当于是给不同的元素不同的权重。当然如果想做成gate net的形式也可以,那就是生成(batchsize, feature_num, dim)的tensor再做加权。 - 既然只加权不求和,理论上是不是可以在MLP里面就学习到这个信息,这么做会不会多余? 答:理论上来说确实可以在MLP里面学习到这个权重信息。就像万能近似定理一样,你不能说MLP理论上什么都能做我就只用MLP,别的啥都不加。毕竟在有限的数据情况下,人为先验增加一些复杂的模型结构可以帮助模型更好的拟合。所以这么做多不多余,还得试了看有没有效果再说。不排除在某些场景下加了跟没加一样,没有什么区别(狗头)。
最后总结一下,SENet的样式可以加在任何一个网络里面,只要你想给某一个维度下不同元素不同的权重。值得注意的是这里只加权,不求和。至于选哪个维度(feature_num还是dim)下的元素给不同权重,根据具体的业务理解来选择。
4. DIN
DIN是阿里针对用户行为特征所构建的模型。即当用户的的行为序列(比如点击序列)有多个itemid的时候,如果直接用sum pooling聚合,则默认这几个点击的item的权重是一样的。类比在第二章的图可以看出来,当一个特征域(比如【兴趣】)有多个特征的时候,常规的做法是sum pooling或者avg pooling。这样就会默认这几个特征的权重是一样的,DIN便是针对此问题,认为不同的特征应该有不同的权重,而这个权重就是用户的兴趣。
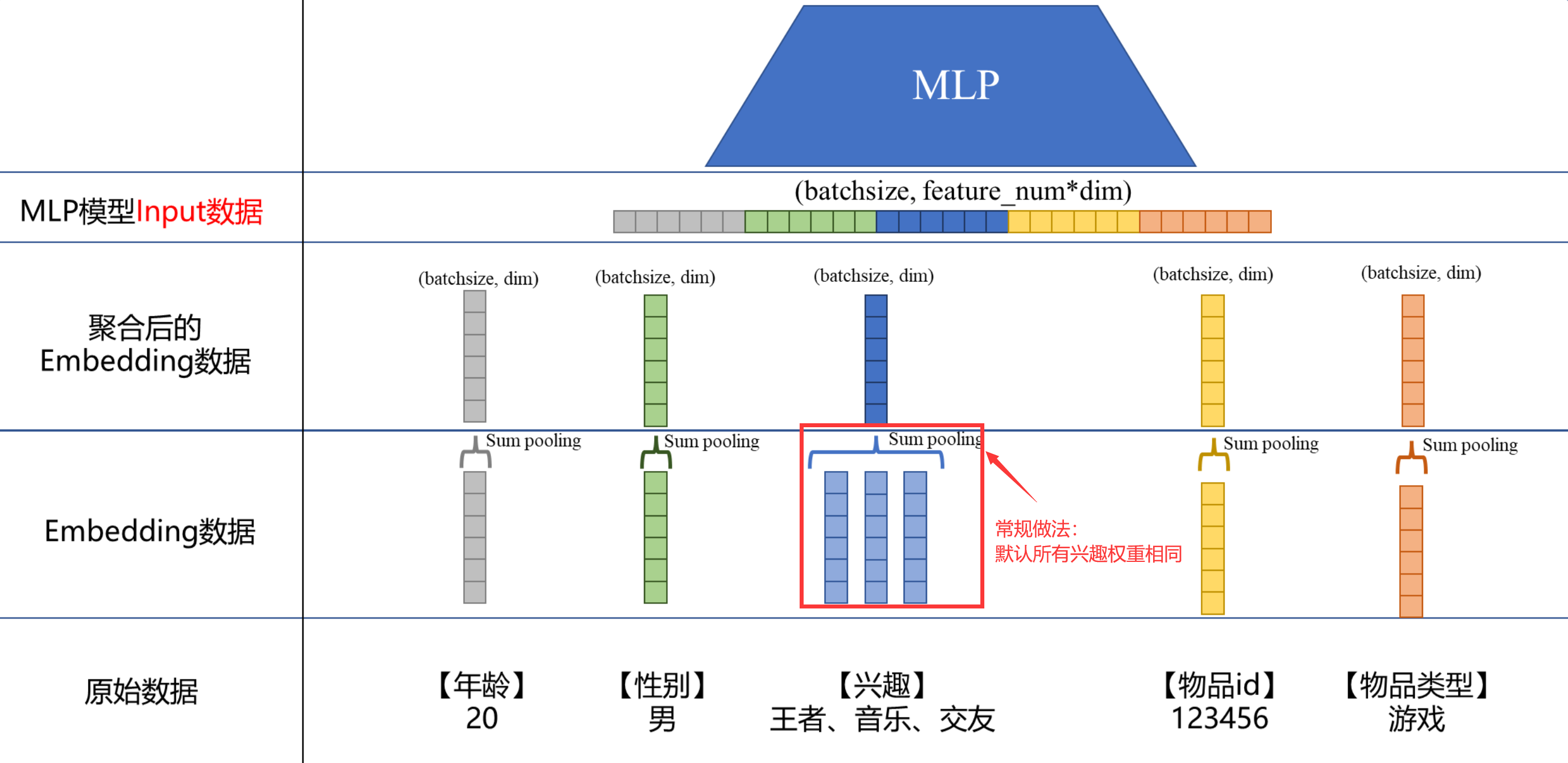
因此将DIN套在我们的例子上,过程如下:
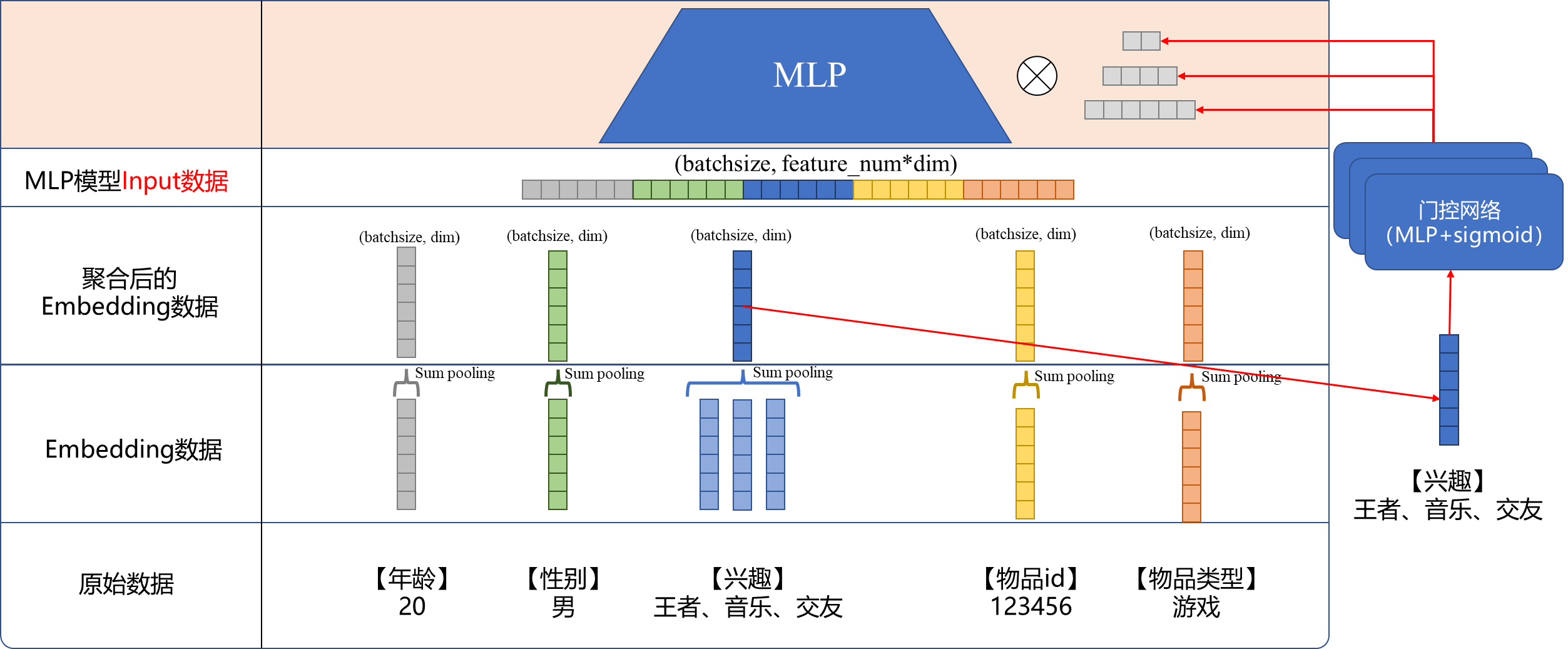
- 选择一个有多个特征的特征域,比如【兴趣】,在选择一个与之对应或关联的特征,比如【物品类型】。接着用游戏的embedding
(batchsize, 1, dim),和每一个兴趣的embedding(batchsize, 3, dim)进“激活单元”得到一个权重值(batchsize, 3, 1),代表Attention权重。至于“激活单元”是啥,可以参考DIN的论文,就是一个小门控网络,当然思路打开这里具体怎么实现激活单元可以各种尝试,论文的结构也不是一定的。
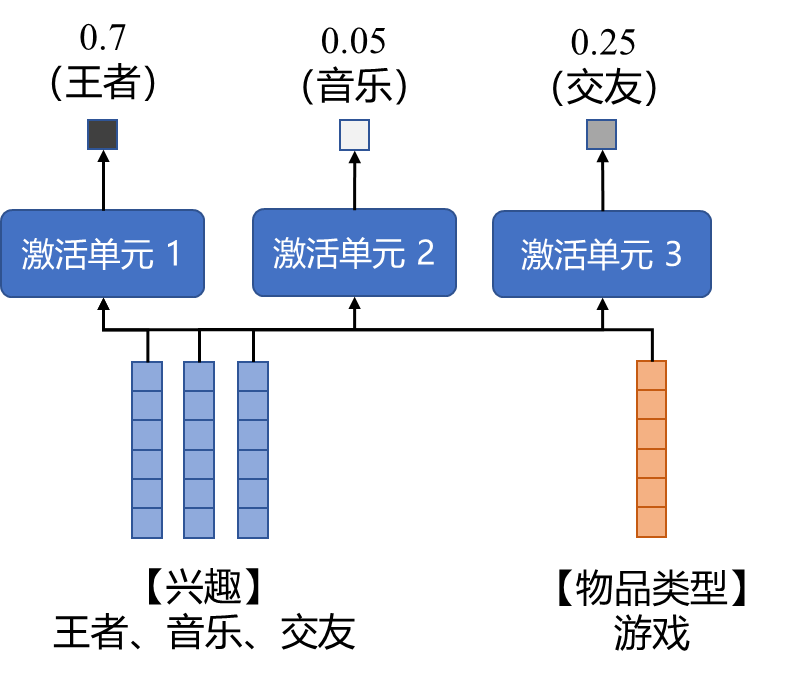
2. 接着把得到的权重替换之前的sum pooling,改成加权求和生成聚合Embedding,放回整个框架里面大致如下图所示。如果用算式表示大概就是: a+b+c升级成了(0.7×a)+(0.05×b)+(0.25×c) 相比之下后者显然优雅一些,而且这些权重是模型自动计算获得。
最后总结一下,简单的说完DIN的结构可以发现,和SENet比,DIN的Attention作用于“Embedding数据”这一层,也就是图中从下往上的第二层。所以从业务理解上面来说,DIN的Attention不是在做“特征选择”,而是对sum pooling的一个小小的升级,让特征表达的更准确。这里是加权、求和的。
5. POSO
最后说一下POSO的结构,相比于前面两个,POSO的出名程度可能要低一些。《POSO: Personalized Cold Start Modules for Large-scale Recommender Systems》,是快手在21年提出的论文,其主要是针对冷启动中的特征淹没的问题而在模型层面上提出的改进。以MLP为例,若MLP的尺寸是512 * 256 * 256的。即选一个人为认为比较重要的特征xpc去生成512、256、256三种不同的权值去乘进MLP网络内。
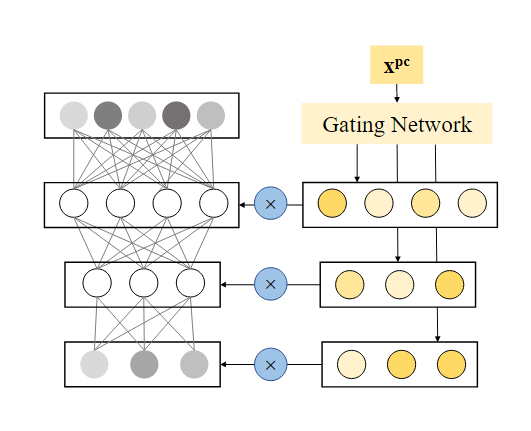
若放在我们的例子里,大致如下图所示,若MLP的尺寸是512 * 256 * 128的。取一个我认为比较重要的特征,比如【兴趣】作为xpc,然后过3个门控网络生成3个tensor,分别是(batchsize, 512, 1)、(batchsize, 256, 1)、(batchsize, 128, 1)。这里的门控网络可以是MLP+sigmoid的形式。当然也可以自己发挥魔改。最后将得到的三个tensor以乘法的形式乘进MLP网络里面,以实现对不同神经元的attention。
最后总结一下,POSO虽然看起来也是在做一种attention,但是它是对神经元来做,和以上两种又有所不同。POSO严格意义上来说不算一种特征选择,而是一种特征增强的策略。因此只要你觉得某个特征很重要,就把他拎出来整一下,说不定就有提升了呢~
6. 总结
以上三种模型结构都用到了类似attention的思想,所以attention是个啥呢?引用SENet原文的一句话:
Attention can be viewed, broadly, as a tool to bias the allocation of available processing resources towards the most informative components of an input signal. (从广义上讲,注意力可以看作是一种工具,用于将可用处理资源的分配偏向于输入信号信息量最大的组件。)
我个人理解就是“物尽其用”。网上也就很多说法,比如一种常见的说法就是attention就是加权求和的行业黑话,这么理解也未尝不可。至于怎么说,怎么做,无论学术界还是工业界都倾向于结果导向,有了好效果才是王道!
参考文献
SENet:http://dx.doi.org/10.1109/tpami.2019.2913372
DIN:http://dx.doi.org/10.1145/3219819.3219823
POSO:https://readpaper.com/paper/3190143440
这篇关于DIN特征加权、POSO特征增强、SENET特征选择的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!