本文主要是介绍本地CPU搭建知识库大模型来体验学习Prompt Engineering/RAG/Agent/Text2sql,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
目录
1.环境
2.效果
3.概念解析
4.架构图
5. AI畅想
6.涉及到的技术方案
7. db-gpt的提示词
1.环境
基于一台16c 32G的纯CPU的机器来搭建
纯docker 打造
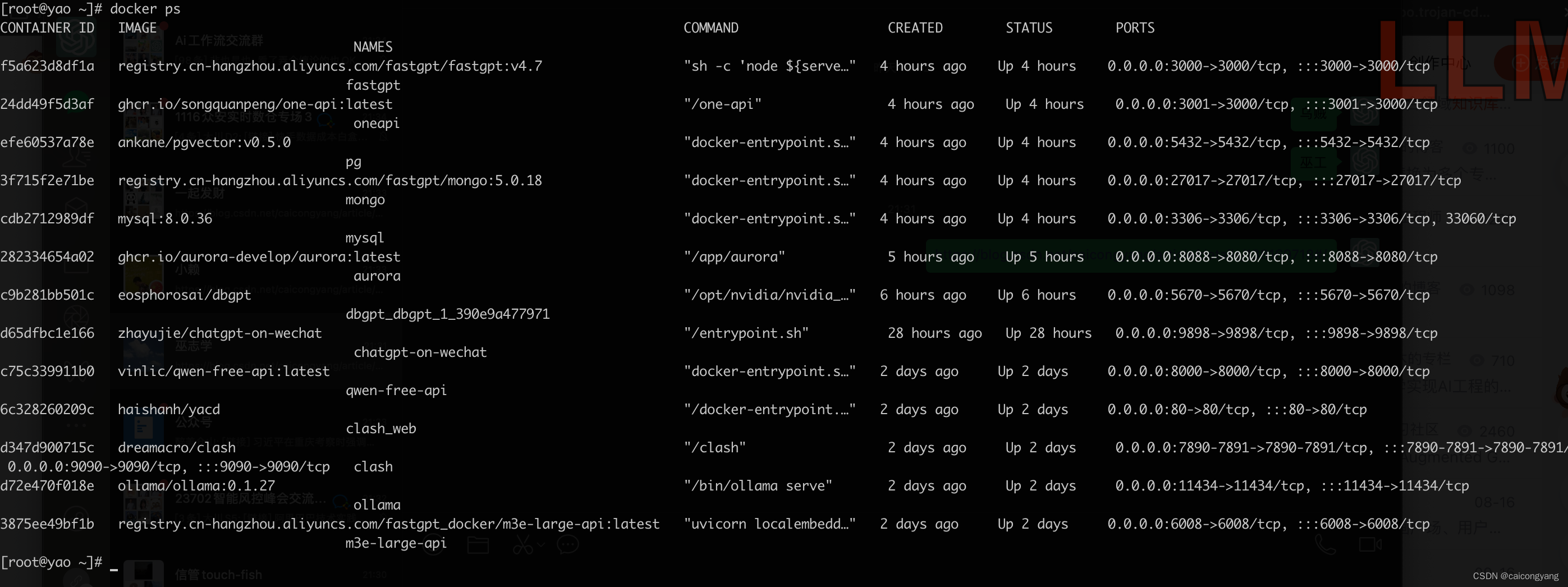
2.效果



3.概念解析
Prompt Engineering : 提示词工程
RAG: 检索增强生成; 知识库的构建+知识检索+大模型生成
Agent:通过工具来增强LLM的能力实现与现实世界的交互; Agent =LLM+Planning+FeedBack+Tool use
Text2sql: 将文本翻译成sql
4.架构图
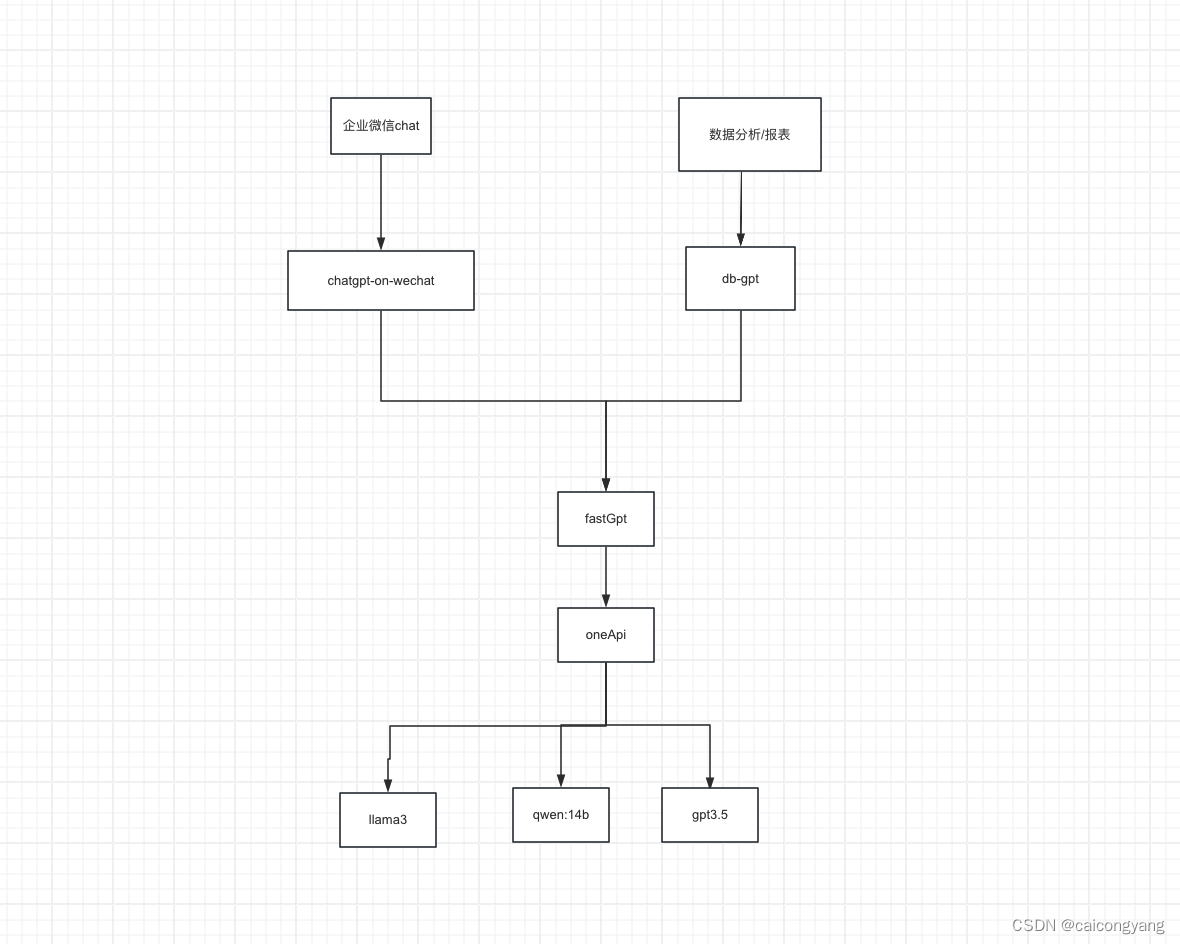

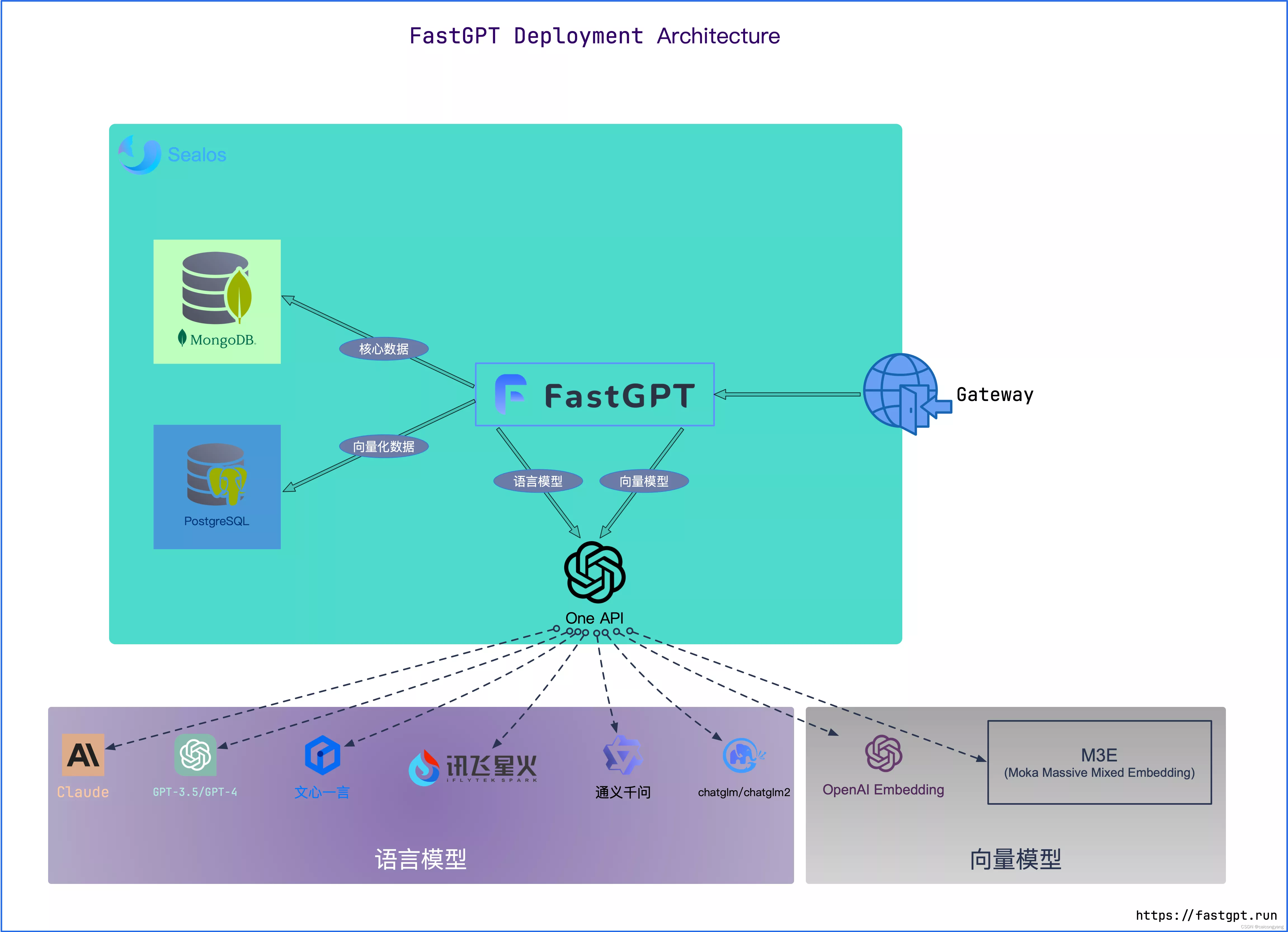
5. AI畅想
a.LLM最快落地的两个实施路径;本地知识库 + Text2sql
b.本地模型的意义: 安全自助可控,成本
未来的发展方向:
1.本地大模型&小模型
2.AIPC
3.AIPhone
4.面向agent开发
5.面向chat的交互
前阿里巴巴张勇:所有应用都值得基于大模型所有的重新做一遍
6.涉及到的技术方案
chatgpt-on-wechat: GitHub - zhayujie/chatgpt-on-wechat: 基于大模型搭建的聊天机器人,同时支持 企业微信、微信 公众号、飞书、钉钉 等接入,可选择GPT3.5/GPT4.0/Claude/文心一言/讯飞星火/通义千问/Gemini/GLM-4/Claude/LinkAI,能处理文本、语音和图片,访问操作系统和互联网,支持基于自有知识库进行定制企业智能客服。
db-gpt: https://github.com/eosphoros-ai/DB-GPT
fastgpt: 快速了解 FastGPT | FastGPT
ollama: library
chatglt.cpp : GitHub - li-plus/chatglm.cpp: C++ implementation of ChatGLM-6B & ChatGLM2-6B & ChatGLM3 & more LLMs
llama-gpt : GitHub - getumbrel/llama-gpt: A self-hosted, offline, ChatGPT-like chatbot. Powered by Llama 2. 100% private, with no data leaving your device. New: Code Llama support!
以上在官方文档都提供了docker或者docker-compose 的快速部署,方便大家学习;
7. db-gpt的提示词
问题:查询ouser.u_user表告诉我今天新增了多少用户
下面是db-gpt autogen的过程可以让我们学下
2024-04-24 13:24:10 c9b281bb501c dbgpt.app.openapi.api_v1.api_v1[1] INFO get_chat_instance:conv_uid='e1844e5c-023d-11ef-9e5a-0242c0a80002' user_input='查询ouser.u_user表告诉我今天新增了多少用户' user_name=None chat_mode='chat_with_db_qa' select_param='ouser' model_name='gpt-3.5-turbo-0301' incremental=False sys_code=None
2024-04-24 13:24:10 c9b281bb501c dbgpt.datasource.manages.connect_config_db[1] INFO Result: <sqlalchemy.engine.cursor.CursorResult object at 0x7fc4306ec6a0>
chat_completions:chat_with_db_qa,ouser,gpt-3.5-turbo-0301
Get prompt template of scene_name: chat_with_db_qa with model_name: gpt-3.5-turbo-0301, proxyllm_backend: None, language: zh
<class 'dbgpt.storage.vector_store.chroma_store.ChromaStore'>
INFO: 10.1.195.47:54748 - "POST /api/v1/chat/completions HTTP/1.1" 200 OK
2024-04-24 13:24:14 c9b281bb501c dbgpt.storage.vector_store.chroma_store[1] INFO ChromaStore similar search
Batches: 100%|██████████| 1/1 [00:01<00:00, 1.11s/it]
2024-04-24 13:24:15 c9b281bb501c dbgpt.core.awel.runner.local_runner[1] INFO Begin run workflow from end operator, id: d4a6e059-67db-4f74-ad9f-80155dffc91f, runner: <dbgpt.core.awel.runner.local_runner.DefaultWorkflowRunner object at 0x7fc469fa3670>
2024-04-24 13:24:15 c9b281bb501c dbgpt.core.awel.runner.local_runner[1] INFO Begin run workflow from end operator, id: 64590fab-5ef8-4c5f-a47c-20a80f8d2bb6, runner: <dbgpt.core.awel.runner.local_runner.DefaultWorkflowRunner object at 0x7fc469fa3670>
2024-04-24 13:24:15 c9b281bb501c dbgpt.app.scene.base_chat[1] INFO payload request:
ModelRequest(model='gpt-3.5-turbo-0301', messages=[ModelMessage(role='system', content="\n根据要求和问题,提供专业的答案。如果无法从提供的内容中获取答案,请说:“知识库中提供的信息不足以回答此问题。” 禁止随意捏造信息。\n\n使用以下表结构信息: \n['update_username (更新用户名), update_userip (更新用户ip), update_usermac (更新用户MAC), update_time (更新时间), update_time_db (更新时间 数据库), client_versionno (客户端版本号), company_id (公司ID), channel_code (渠道编码)), and index keys: idx_user_id(`user_id`) , and table comment: 用户操作日志表', 'update_username (最后修改人姓名), update_time (最后修改时间), update_time_db, company_id (公司id)), and index keys: entity_id(`entity_id`) , process_type(`process_type`) , unique_identification(`unique_identification, user_account_id, process_type`) , and table comment: 用户账户人工作业表', 'create_userid (创建人ID), create_username (创建人姓名), create_time (创建时间-应用操作时间), create_time_db (创建时间-数据库操作时间), server_ip (服务器IP), update_userid (最后修改人ID), update_username (最后修改人姓名), update_time (最后修改时间), update_time_db, company_id (公司id)), and index keys: entity_id(`entity_id, type, sub_type, entity_type, rel_id, year, month, day`) , type(`type`) , and table comment: 月度账户汇总表', '(最后修改人姓名), update_user_ip (最后修改人IP), update_user_mac (最后修改人MAC), update_time (更新时间), update_time_db (更新时间 数据库), server_ip (服务器ip), company_id (公司ID), client_versionno (客户端版本号), create_userid (创建用户ID), create_username (创建用户名), create_userip (创建用户IP), create_usermac (创建用户MAC), update_userid (更新用户ID), update_username (更新用户名), update_userip (更新用户ip), update_usermac (更新用户MAC)), and table comment: 渠道表', 'u_user_action_log(id, type (1. 注册, 2. 登录, 3. 修改密码, 4. 完善信息), remark (备注), channel (渠道), user_id (操作用户ID), msg_send_flag (消息发送标志), point_send_flag (消息发送标志), deal_flag (0=未处理 1=处理), is_available (是否可用,0-不可用,1可用), is_deleted (逻辑删除字段 0 正常 1 已删除), version_no (版本号), create_userid (创建用户ID), create_username (创建用户名), create_userip (创建用户IP), create_usermac (创建用户MAC), create_time (创建日期), create_time_db (创建日期 数据库), server_ip (服务器ip), update_userid (更新用户ID), update_username (更新用户名), update_userip (更新用户ip),']\n\n问题:\n查询ouser.u_user表告诉我今天新增了多少用户\n一步步思考。\n", round_index=0), ModelMessage(role='human', content='查询ouser.u_user表告诉我今天新增了多少用户', round_index=0)], temperature=0.6, max_new_tokens=1024, stop=None, stop_token_ids=None, context_len=None, echo=False, span_id='7b731a8a-614d-492d-ad8e-40b98b7ed46a:8b12ee06-3290-4784-85cc-a238c050b474', context=ModelRequestContext(stream=True, cache_enable=False, user_name=None, sys_code=None, conv_uid=None, span_id='7b731a8a-614d-492d-ad8e-40b98b7ed46a:8b12ee06-3290-4784-85cc-a238c050b474', chat_mode='chat_with_db_qa', chat_param=None, extra={}, request_id=None))
2024-04-24 13:24:15 c9b281bb501c dbgpt.core.awel.runner.local_runner[1] INFO Begin run workflow from end operator, id: 9fe07ac3-2522-4e75-829b-cdd2c00bbb48, runner: <dbgpt.core.awel.runner.local_runner.DefaultWorkflowRunner object at 0x7fc469fa3670>
2024-04-24 13:24:15 c9b281bb501c dbgpt.core.awel.operators.common_operator[1] INFO branch_input_ctxs 0 result None, is_empty: False
2024-04-24 13:24:15 c9b281bb501c dbgpt.core.awel.operators.common_operator[1] INFO Skip node name llm_model_cache_node
2024-04-24 13:24:15 c9b281bb501c dbgpt.core.awel.operators.common_operator[1] INFO branch_input_ctxs 1 result True, is_empty: False
2024-04-24 13:24:15 c9b281bb501c dbgpt.core.awel.runner.local_runner[1] INFO Skip node name llm_model_cache_node, node id 85304c88-6a77-478c-a32c-765a9287a367
2024-04-24 13:24:15 c9b281bb501c dbgpt.model.adapter.base[1] INFO Message version is v2
2024-04-24 13:24:15 c9b281bb501c dbgpt.model.cluster.worker.default_worker[1] INFO current generate stream function is asynchronous stream function
2024-04-24 13:24:15 c9b281bb501c dbgpt.model.proxy.llms.chatgpt[1] INFO Send request to openai(1.17.0), payload: {'stream': True, 'model': 'gpt-3.5-turbo', 'temperature': 0.6, 'max_tokens': 1024}messages:
[{'role': 'system', 'content': "\n根据要求和问题,提供专业的答案。如果无法从提供的内容中获取答案,请说:“知识库中提供的信息不足以回答此问题。” 禁止随意捏造信息。\n\n使用以下表结构信息: \n['update_username (更新用户名), update_userip (更新用户ip), update_usermac (更新用户MAC), update_time (更新时间), update_time_db (更新时间 数据库), client_versionno (客户端版本号), company_id (公司ID), channel_code (渠道编码)), and index keys: idx_user_id(`user_id`) , and table comment: 用户操作日志表', 'update_username (最后修改人姓名), update_time (最后修改时间), update_time_db, company_id (公司id)), and index keys: entity_id(`entity_id`) , process_type(`process_type`) , unique_identification(`unique_identification, user_account_id, process_type`) , and table comment: 用户账户人工作业表', 'create_userid (创建人ID), create_username (创建人姓名), create_time (创建时间-应用操作时间), create_time_db (创建时间-数据库操作时间), server_ip (服务器IP), update_userid (最后修改人ID), update_username (最后修改人姓名), update_time (最后修改时间), update_time_db, company_id (公司id)), and index keys: entity_id(`entity_id, type, sub_type, entity_type, rel_id, year, month, day`) , type(`type`) , and table comment: 月度账户汇总表', '(最后修改人姓名), update_user_ip (最后修改人IP), update_user_mac (最后修改人MAC), update_time (更新时间), update_time_db (更新时间 数据库), server_ip (服务器ip), company_id (公司ID), client_versionno (客户端版本号), create_userid (创建用户ID), create_username (创建用户名), create_userip (创建用户IP), create_usermac (创建用户MAC), update_userid (更新用户ID), update_username (更新用户名), update_userip (更新用户ip), update_usermac (更新用户MAC)), and table comment: 渠道表', 'u_user_action_log(id, type (1. 注册, 2. 登录, 3. 修改密码, 4. 完善信息), remark (备注), channel (渠道), user_id (操作用户ID), msg_send_flag (消息发送标志), point_send_flag (消息发送标志), deal_flag (0=未处理 1=处理), is_available (是否可用,0-不可用,1可用), is_deleted (逻辑删除字段 0 正常 1 已删除), version_no (版本号), create_userid (创建用户ID), create_username (创建用户名), create_userip (创建用户IP), create_usermac (创建用户MAC), create_time (创建日期), create_time_db (创建日期 数据库), server_ip (服务器ip), update_userid (更新用户ID), update_username (更新用户名), update_userip (更新用户ip),']\n\n问题:\n查询ouser.u_user表告诉我今天新增了多少用户\n一步步思考。\n"}, {'role': 'user', 'content': '查询ouser.u_user表告诉我今天新增了多少用户'}]
llm_adapter: <OpenAIProxyLLMModelAdapter model_name=gpt-3.5-turbo-0301 model_path=chatgpt_proxyllm>model prompt:system:
根据要求和问题,提供专业的答案。如果无法从提供的内容中获取答案,请说:“知识库中提供的信息不足以回答此问题。” 禁止随意捏造信息。使用以下表结构信息:
['update_username (更新用户名), update_userip (更新用户ip), update_usermac (更新用户MAC), update_time (更新时间), update_time_db (更新时间 数据库), client_versionno (客户端版本号), company_id (公司ID), channel_code (渠道编码)), and index keys: idx_user_id(`user_id`) , and table comment: 用户操作日志表', 'update_username (最后修改人姓名), update_time (最后修改时间), update_time_db, company_id (公司id)), and index keys: entity_id(`entity_id`) , process_type(`process_type`) , unique_identification(`unique_identification, user_account_id, process_type`) , and table comment: 用户账户人工作业表', 'create_userid (创建人ID), create_username (创建人姓名), create_time (创建时间-应用操作时间), create_time_db (创建时间-数据库操作时间), server_ip (服务器IP), update_userid (最后修改人ID), update_username (最后修改人姓名), update_time (最后修改时间), update_time_db, company_id (公司id)), and index keys: entity_id(`entity_id, type, sub_type, entity_type, rel_id, year, month, day`) , type(`type`) , and table comment: 月度账户汇总表', '(最后修改人姓名), update_user_ip (最后修改人IP), update_user_mac (最后修改人MAC), update_time (更新时间), update_time_db (更新时间 数据库), server_ip (服务器ip), company_id (公司ID), client_versionno (客户端版本号), create_userid (创建用户ID), create_username (创建用户名), create_userip (创建用户IP), create_usermac (创建用户MAC), update_userid (更新用户ID), update_username (更新用户名), update_userip (更新用户ip), update_usermac (更新用户MAC)), and table comment: 渠道表', 'u_user_action_log(id, type (1. 注册, 2. 登录, 3. 修改密码, 4. 完善信息), remark (备注), channel (渠道), user_id (操作用户ID), msg_send_flag (消息发送标志), point_send_flag (消息发送标志), deal_flag (0=未处理 1=处理), is_available (是否可用,0-不可用,1可用), is_deleted (逻辑删除字段 0 正常 1 已删除), version_no (版本号), create_userid (创建用户ID), create_username (创建用户名), create_userip (创建用户IP), create_usermac (创建用户MAC), create_time (创建日期), create_time_db (创建日期 数据库), server_ip (服务器ip), update_userid (更新用户ID), update_username (更新用户名), update_userip (更新用户ip),']问题:
查询ouser.u_user表告诉我今天新增了多少用户
一步步思考。human: 查询ouser.u_user表告诉我今天新增了多少用户async stream output:2024-04-24 13:24:18 c9b281bb501c dbgpt.model.cluster.worker.default_worker[1] INFO is_first_generate, usage: None
首先,我们需要确定如何识别 "今天"。一般来说,这涉及到当前日期的过滤。然后,我们需要找到 "新增用户" 的标志。假设 "新增用户" 是指在今天创建的用户记录。下面是一系列步骤来查询这个信息:1. 确定今天的日期。
2. 使用SQL查询语句筛选出今天创建的用户记录。
3. 计算符合条件的记录数量。以下是相应的SQL查询:```sql
SELECT COUNT(*) AS new_users_count
FROM ouser.u_user
WHERE DATE(create_time) = CURDATE();这篇关于本地CPU搭建知识库大模型来体验学习Prompt Engineering/RAG/Agent/Text2sql的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!








