本文主要是介绍【Hadoop】-拓展:蒙特卡罗算法求PI的基础原理[10],希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
Monte Carlo蒙特卡罗算法(统计模拟法)
Monte Carlo算法的基本思想是:以模拟的“实验”形式、以大量随机样本的统计形式,来得到问题的求解。比如,求圆周率,以数学的方式是非常复杂的,但是我们可以以简单的形式去求解:
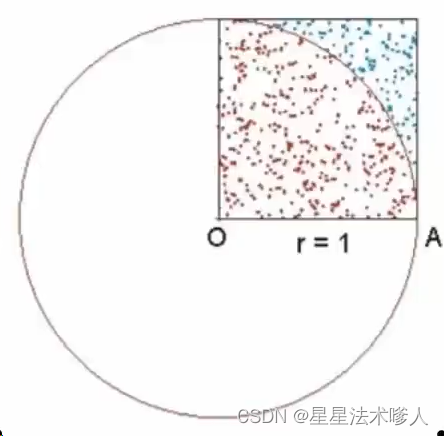
如图,我们在正方形内,随机落点,统计落在1/4圆内的点和总店数量的比例即可得到1/4的PI,最终乘以4即可得到PI。比如,红色点的数量比全部点的数量,结果是0.756,那么乘以4就可以得到3.06,3.06就是求得的PI。
- 所以,此方法,需要大量的样本(落点),样本越多越精准。
示例代码
如下,以python语言实现的蒙特卡罗求PI
import random
sample_num = int(input("请输入样本数:"))
inner_point = 0
pi = 0
for i in range(sample_num):a = random.uniform(0,1)b = random.uniform(0,1)if a*a + b*b <= 1:inner_point = inner_point + 1
pi = (inner_point / sample_num) * 4
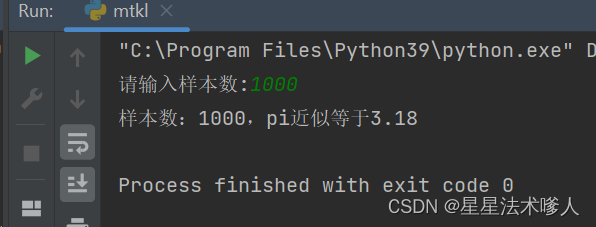
print(f"样本数:{sample_num},pi近似等于{pi}")运行结果:
这篇关于【Hadoop】-拓展:蒙特卡罗算法求PI的基础原理[10]的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!




