本文主要是介绍NASA数据集——TANSO-FTS 运行前 11 年收集的测量数据中得出二氧化碳(CO2)干空气摩尔分数(XCO2)的估计值,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
ACOS GOSAT/TANSO-FTS Level 2 bias-corrected XCO2 and other select fields from the full-physics retrieval aggregated as daily files V7.3 (ACOS_L2_Lite_FP) at GES DISC
简介
ACOS Lite 文件包含经过偏差校正的 XCO2 以及其他选定字段的每日汇总文件。ACOS 2 级标准产品(ACOS_L2S)的轨道颗粒被用作输入。
ACOS "数据集包含所有探测数据的二氧化碳(CO2)柱平均干空气摩尔分数,并尝试对其进行检索。这些是 OCO 项目使用 TANSO-FTS 光谱辐射提供的最高级别产品。
日本宇宙航空研究开发机构的 GOSAT 小组制作 GOSAT TANSO-FTS 1B (L1B) 级数据产品,供内部使用并分发给欧空局和美国航天局等合作伙伴。这些经过校准的产品由 OCO 项目用额外的地理位置信息和进一步的修正进行扩充。这样制作的 1B 级产品(含校准辐射量和地理定位)是 "ACOS "2 级制作过程的输入。
摘要
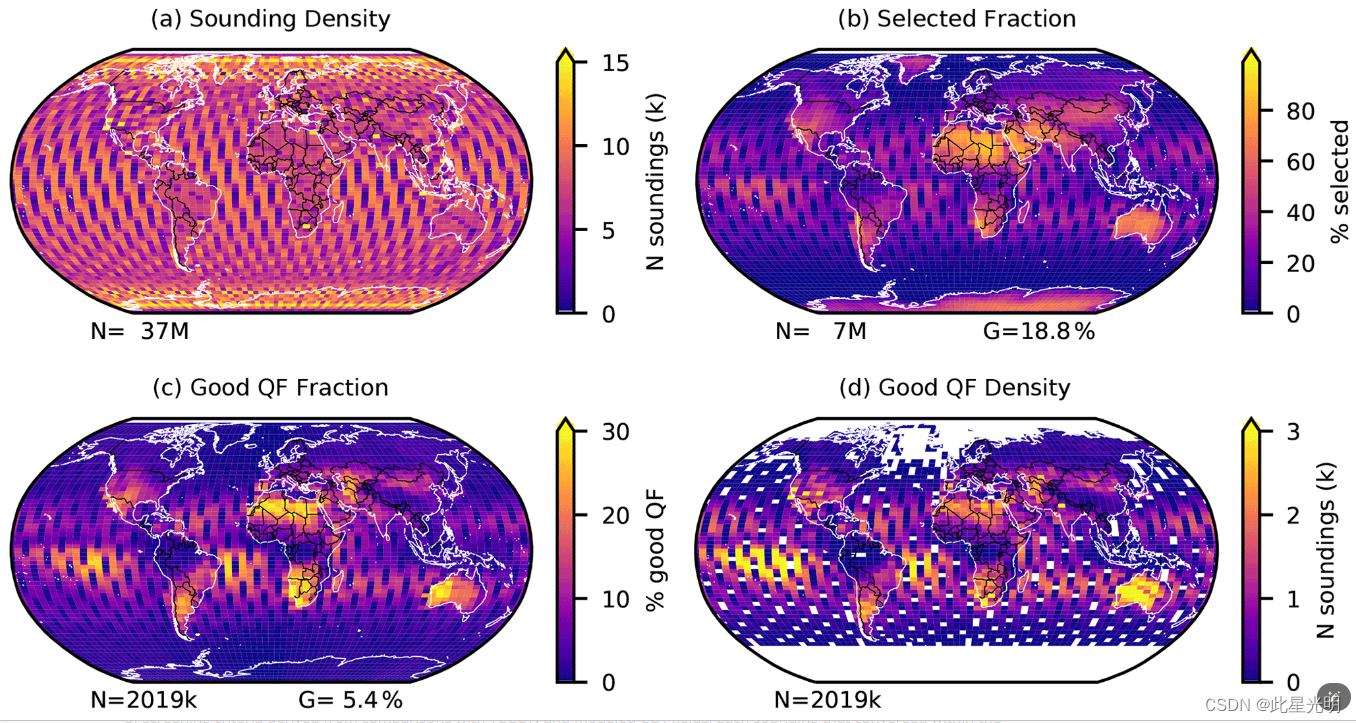
日本温室气体观测卫星(GOSAT)上的碳观测热和近红外传感器-傅立叶变换光谱仪(TANSO-FTS)自 2009 年 4 月以来一直在返回数据。利用第 9 版(v9)空间大气碳观测(ACOS)二级全物理(L2FP)检索算法(Kiel 等人,2019 年),从 TANSO-FTS 运行前 11 年收集的测量数据中得出二氧化碳(CO2)干空气摩尔分数(XCO2)的估计值。利用总碳柱观测网络(TCCON)得出的估算值以及一套不吸收卫星二氧化碳的全球大气反演系统(模式)模拟值,对 L2FP XCO2 产品的偏差校正和质量过滤进行了评估。此外,还将第 9 版 ACOS GOSAT XCO2 结果与 NASA 轨道碳观测站-2(OCO-2)使用第 10 版(v10)ACOS L2FP 算法得出的 XCO2 估算值进行了比较。
这些测试表明,与较早的 v7.3 ACOS GOSAT 产品相比,v9 ACOS GOSAT XCO2 产品在吞吐量、散度和偏差方面都有所改进。在 GOSAT 到 2020 年 6 月收集的 3,700 万个探测数据中,大约 20% 在筛选云层和其他伪影后被选中进行 v9 L2FP 算法处理。经过后处理,5.4%的探测结果(37×106 个中的 2×106)被赋予 "良好 "XCO2 质量标志,而 v7.3 中的比例为 3.9%(24×106 个中的 <1×106 )。经过质量过滤和偏差校正后,ACOS GOSAT v9 与 TCCON 和模式之间的 XCO2 差异(1σ)为:海洋闪烁观测值约为百万分之 1,陆地观测值约为百万分之 1 至 1.5。TCCON 和模式的全球平均偏差小于约 0.2 ppm。与 v10 OCO-2 XCO2 产品相比,陆地观测的季节平均偏差约为 0.1 ppm。然而,对于海洋闪烁观测数据,相对于 OCO-2 的季节平均偏差在 0.2 到 0.6 ppm 之间,且随时间和纬度变化很大。
美国宇航局戈达德地球科学数据和信息服务中心(GES-DISC)提供了 ACOS GOSAT v9 XCO2 数据的每轨道完整格式(https://doi.org/10.5067/OSGTIL9OV0PN,OCO-2 科学小组等,2019b)和每日精简格式(https://doi.org/10.5067/VWSABTO7ZII4,OCO-2 科学小组等,2019a)。此外,还生成了一套新的月度超级精简文件,其中仅包含每次卫星观测的最基本变量,为入门级用户提供了一个轻量级卫星产品,供其进行初步探索(CaltechDATA,https://doi.org/10.22002/D1.2178,Eldering,2021)。v9 ACOS 数据用户指南》(DUG)介绍了 GOSAT 数据的最佳使用方法(O'Dell 等人,2020 年)。GOSAT v9 数据集对于研究跨越整整十年或更长时间的碳循环现象应该特别有用,并可作为 2014 年 9 月开始的较短的 OCO-2 v10 数据集的有益补充。
数据信息
Shortname:
ACOS_L2_Lite_FP
Longname:
ACOS GOSAT/TANSO-FTS Level 2 bias-corrected XCO2 and other select fields from the full-physics retrieval aggregated as daily files V7.3
Version:
7.3
Format:
netCDF
Spatial Coverage:
-180.0,-90.0,180.0,90.0
Temporal Coverage:
2009-04-21 to 2016-06-02
File Size:
50 MB per file
Data Resolution
Spatial:
10.5 km x 10.5 km
代码
!pip install leafmap
!pip install pandas
!pip install folium
!pip install matplotlib
!pip install mapclassifyimport pandas as pd
import leafmapurl = "https://github.com/opengeos/NASA-Earth-Data/raw/main/nasa_earth_data.tsv"
df = pd.read_csv(url, sep="\t")
dfleafmap.nasa_data_login()results, gdf = leafmap.nasa_data_search(short_name="ACOS_L2_Lite_FP",cloud_hosted=True,bounding_box=(-180, -90, 180, 90),temporal=("2009-04-20", "2020-08-08"),count=-1, # use -1 to return all datasetsreturn_gdf=True,
)gdf.explore()#leafmap.nasa_data_download(results[:5], out_dir="data")引用
OCO-2 Science Team/Michael Gunson, Annmarie Eldering (2016), ACOS GOSAT/TANSO-FTS Level 2 bias-corrected XCO2 and other select fields from the full-physics retrieval aggregated as daily files V7.3, Greenbelt, MD, USA, Goddard Earth Sciences Data and Information Services Center (GES DISC), Accessed: [Data Access Date], GES DISC
GES DISC
网址推荐
0代码在线构建地图应用
https://sso.mapmost.com/#/login?source_inviter=nClSZANO
机器学习
https://www.cbedai.net/xg
这篇关于NASA数据集——TANSO-FTS 运行前 11 年收集的测量数据中得出二氧化碳(CO2)干空气摩尔分数(XCO2)的估计值的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!




