收集专题

【编程底层思考】垃圾收集机制,GC算法,垃圾收集器类型概述
Java的垃圾收集(Garbage Collection,GC)机制是Java语言的一大特色,它负责自动管理内存的回收,释放不再使用的对象所占用的内存。以下是对Java垃圾收集机制的详细介绍: 一、垃圾收集机制概述: 对象存活判断:垃圾收集器定期检查堆内存中的对象,判断哪些对象是“垃圾”,即不再被任何引用链直接或间接引用的对象。内存回收:将判断为垃圾的对象占用的内存进行回收,以便重新使用。

理解java虚拟机内存收集
学习《深入理解Java虚拟机》时个人的理解笔记 1、为什么要去了解垃圾收集和内存回收技术? 当需要排查各种内存溢出、内存泄漏问题时,当垃圾收集成为系统达到更高并发量的瓶颈时,我们就必须对这些“自动化”的技术实施必要的监控和调节。 2、“哲学三问”内存收集 what?when?how? 那些内存需要回收?什么时候回收?如何回收? 这是一个整体的问题,确定了什么状态的内存可以
Linux使用收集--持续更新
linux查看目录文件数》》》 查看当前目录大小: [root@xker.com]# du -sh 查看指定目录大小: [root@xker.com]# du -sh /www/xker.com 查看当前目录文件总数: [root@xker.com]# find . -type f |wc -l 查看指定目录文件总数: [root@xker.com]# fi
后台开发 知识点收集
原知识点总结连接,由于有些问题比较熟悉,所以就没有在自己文章中再列出来了 计算机网络 tcp/udp区别http状态码http协议报头字段osi模型、tcp/ip模型以及各层对应的协议session机制、cookie机制tcp三次握手,四次挥手打开网页到页面显示之间的过程https和http的区别post和get的区别ip子网划分两个网络MTU不同时如何通信 数据库 常见问题mysql的两

prometheus删除指定metrics下收集的值
Prometheus 删除指定 Metric 官方文档: - https://prometheus.io/docs/prometheus/latest/querying/api/#tsdb-admin-apis Prometheus 的管理 API 接口,官方到现在一共提供了三个接口,对应的分别是快照功能、数据删除功能、数据清理功能,想要使用 API 需要先添加启动参数 --web.en

复杂SQL集合(不断收集中)
1.一道SQL语句面试题,关于group by 表内容: 2005-05-09 胜 2005-05-09 胜 2005-05-09 负 2005-05-09 负 2005-05-10 胜 2005-05-10 负 2005-05-10 负 如果要生成下列结果, 该如何写sql语句? 胜 负 2005-05-09 2 2 2005-05-10 1 2 --------

ELK系列之四---如何通过Filebeat和Logstash优化K8S集群的日志收集和展示
前 言 上一篇文章《日志不再乱: 如何使用Logstash进行高效日志收集与存储》介绍了使用ELK收集通用应用的日志,在目前大多应用都已运行在K8S集群上的环境,需要考虑怎么收集K8S上的日志,本篇就介绍一下如何使用现有的ELK平台收集K8S集群上POD的日志。 K8S日志文件说明 一般情况下,容器中的日志在输出到标准输出(stdout)时,会以.log的命名方式保存在/var/log/po

97.WEB渗透测试-信息收集-Google语法(11)
免责声明:内容仅供学习参考,请合法利用知识,禁止进行违法犯罪活动! 内容参考于: 易锦网校会员专享课 上一个内容:96.WEB渗透测试-信息收集-Google语法(10) 2 、找上传类漏洞地址: • site:xxx.com inurl:file 打开搜索引擎搜索 site:qimai.cn inurl:file 搜索不到就是不存在 • site:xxx.com in
收集几种解决:The absolute uri: http://java.sun.com/jsp/jstl/core cannot be resolved in either web.xml or t
1、web项目出现如上问题,可能是版本问题: JSTL 1.0 的声明是: <%@ taglib prefix="c" uri="http://java.sun.com/jstl/core " %> JSTL1.1 的声明是: <%@ taglib prefix="c" uri=http://Java.sun.com/jsp/jstl/core %> 目前项目版本为Java

Vue——day08之收集表单数据
目录 代码讲解 HTML结构 表单部分 Vue.js部分 总结 整体代码 效果展示 总结 代码讲解 HTML结构 DOCTYPE声明和基础设置: 声明HTML文档的类型为HTML5,并设置字符编码为UTF-8,确保页面内容可以正确显示。<meta name="viewport" content="width=device-width, initial-sca
SourceCode杂论-收集
序号模型题目代码1EfficientNet 3D- - -Keras2EfficientNet-PyTorch_3DConv- - -PyTorch3EfficientUNetClassification and understanding of cloud structures via satellite images with EfficientUNetKeras
SCI写作句型整理收集
covering aforementioned steps respectively 分别介绍上述步骤To give an additional insight regarding the performance of proposed networks 关于我们提出的网络性能做进一步的分析High interest in automatic segmentation methods manife
【react】常用插件收集
Redux状态管理 - @reduxjs/toolkit 、 react-redux react-router-dom: 路由 antd-mobile: 移动端组件库 axios:请求插件 dayjs: 时间处理 classnames: class类名处理 Lodash:遍历数据等 地址→ CRACO:配置别名路径等,下载后添加craco.config.js文件,类似VUE的vue

深入理解 JVM垃圾收集算法和垃圾收集器(一篇就够)
一、概述 在Java中内存是由JVM虚拟机自动管理的,JVM在内存中划出一片区域,作为满足程序内存分配请求的空间。内存的创建仍然是由程序猿来显示指定的,但是对象的释放却对程序猿是透明的。就是解放了程序猿手动回收内存的工作,交给垃圾回收器来自动回收。 在JVM虚拟机中,释放哪些不再被使用的对象所占空间的过程称为垃圾收集(Garbage Collection,GC)。负责垃圾收集的程序模块被称为垃

Unity 性能优化工具收集
本文地址:https://blog.csdn.net/t163361/article/details/141809415 Unity原始工具 UPR 官方 UPR UPR桌面端解决方案,减轻测试设备性能压力,使测试过程更加顺畅。提供CLI用于自动化测试系统对接。 PerformanceBenchmarkReporter Unity 性能基准测试工具使合作伙伴和开发人员能够使用性能测试包建立

新手必看 | 信息收集打点篇
0x1 前言 本篇文章主要是汇总自己在以往的信息收集打点中的一些总结,然后给师傅们分享下个人信息打点的各种方式,以及使用工具的快、准、狠的重要性。让师傅们在后面的一些红队和众测包括src的项目中可以拿到一个不错的结果。 0x2 信息打点方向 探讨下师傅们在红队渗透拿到一个目标名或者刷src和在众测的时候,怎么快速信息收集和批量检测来打到一个点,总的来讲往往在实际项目中就是拼手速。 1、目标
菜鸟黑客入门命令收集(转)
转自《我和黑客有个约会》 1、NET 只要你拥有某IP的用户名和密码,那就用IPC$做连接吧! 这里我们假如你得到的用户是hbx,密码是123456。假设对方IP为127.0.0.1 net use \\127.0.0.1\ipc$ 123456 /user:hbx 退出的命令是 net use \\127.0.0.1\ipc$ /delte
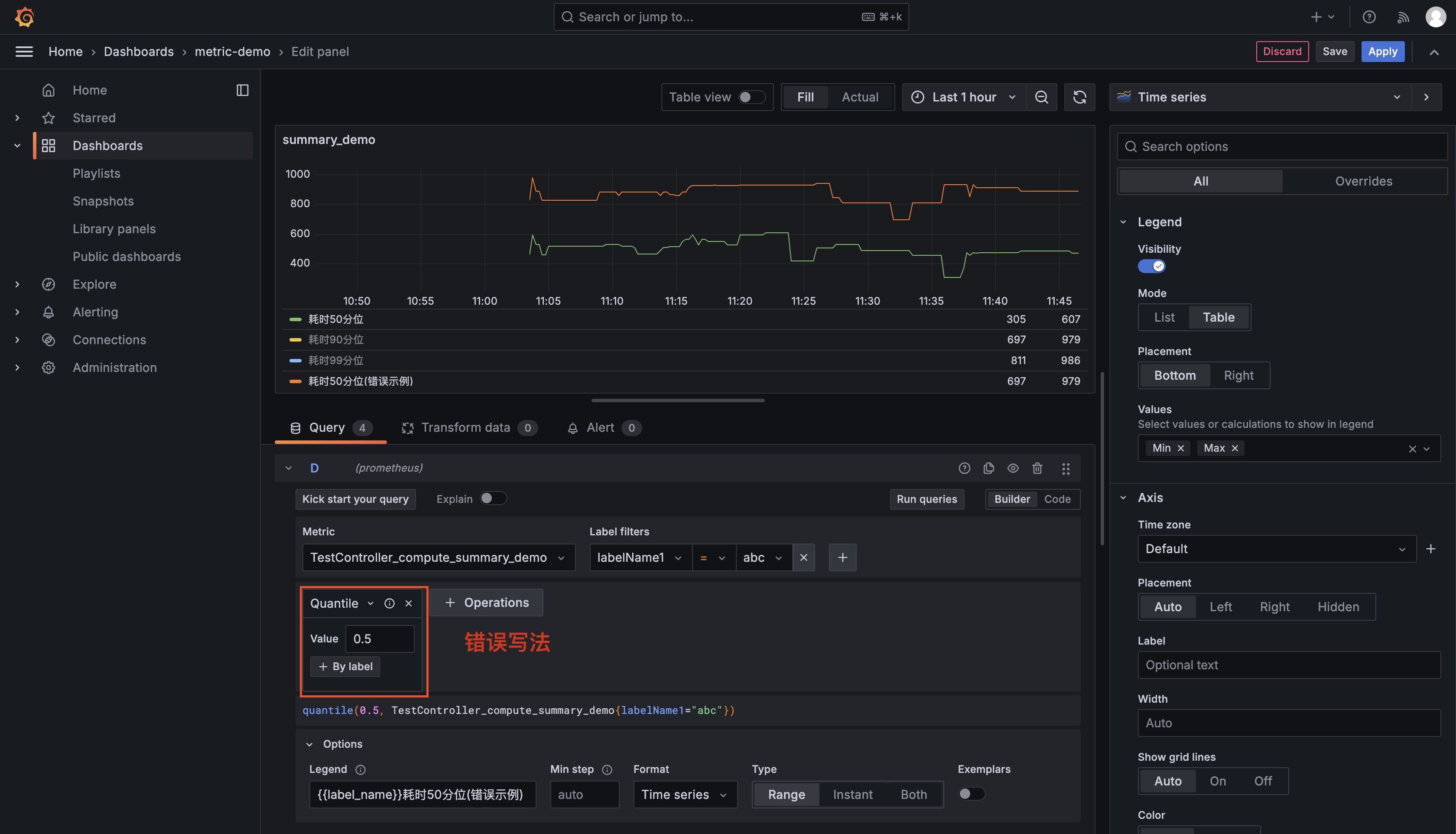
spring boot 项目 prometheus 自定义指标收集区分应用环境集群实例ip,使用 grafana 查询--方法耗时分位数指标
spring boot 项目 prometheus 自定义指标收集 auth @author JellyfishMIX - github / blog.jellyfishmix.comLICENSE LICENSE-2.0 说明 网上有很多 promehteus 和 grafana 配置,本文不再重复,只介绍自定义部分。目前只介绍了分位数指标的收集和查询,常用于方法耗时的指标监控。 自定
深度学习包,工具的收集
imgaug :进行图像augmentation的python库,支持关键点(keypoint)和bounding box一起变换。 https://blog.csdn.net/u012897374/article/details/80142744 在mask rcnn中 使用了 docker 很强大的虚拟实验环境搭建。可以当成不浪费资源的虚拟机。并且由专业人士配置环境内容。可以分享环境
.NET 一款支持收集6种浏览器数据的工具
01阅读须知 此文所提供的信息只为网络安全人员对自己所负责的网站、服务器等(包括但不限于)进行检测或维护参考,未经授权请勿利用文章中的技术资料对任何计算机系统进行入侵操作。利用此文所提供的信息而造成的直接或间接后果和损失,均由使用者本人负责。本文所提供的工具仅用于学习,禁止用于其他方面 02基本介绍 Sharp4BrowserData 是一款专门用于从各类浏览器中解密并导出数据的工具。这些数

大一新生入学证件照采集,手机拍照轻松搞定收集
又到了一年一度大中专院校新生入学的时候了,在开学时很重要的一项工作就是新生照片采集。证件照采集是为了建立学生学籍档案、校园门禁系统登记、校园卡制发、大学四级英语考试报名等,往往要求全校新生使用统一的证件照尺寸、颜色背景,甚至是头部位置和比例。可以看出,这是一项耗时的工作,而且很难保证学生照片质量的统一,那么有没有简单的工具可以帮助我们学籍管理员和信息员们完成这项工作呢?答案是肯定是,下面就来具体介

Nest.js 实战 (十):使用 winston 打印和收集日志记录
前言 日志记录在后台服务的重要性不言而喻,它可以帮助开发者调试和故障排查、性能监控、审计和安全、监控和警报等。 Nest 附带一个默认的内部日志记录器实现,它在实例化过程中以及在一些不同的情况下使用,比如发生异常等等(例如系统记录)。这由 @nestjs/common 包中的 Logger 类实现。你可以全面控制如下的日志系统的行为: 完全禁用日志指定日志系统详细水平(例如,展示错误,警告,

【Java设计模式】收集参数模式:掌握高效参数处理
文章目录 【Java设计模式】收集参数模式:掌握高效参数处理一、概述二、收集参数设计模式的别名三、收集参数设计模式的意图四、收集参数模式的详细解释及实际示例五、Java中收集参数模式的编程示例六、何时在Java中使用收集参数模式七、收集参数模式在Java中的实际应用八、收集参数模式的优点和权衡九、源码下载 【Java设计模式】收集参数模式:掌握高效参数处理 一、概述 在Jav