本文主要是介绍YOLOv9改进策略 | 添加注意力篇 | 利用ILSVRC冠军得主SENetV1改善网络模型特征提取能力,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
一、本文介绍
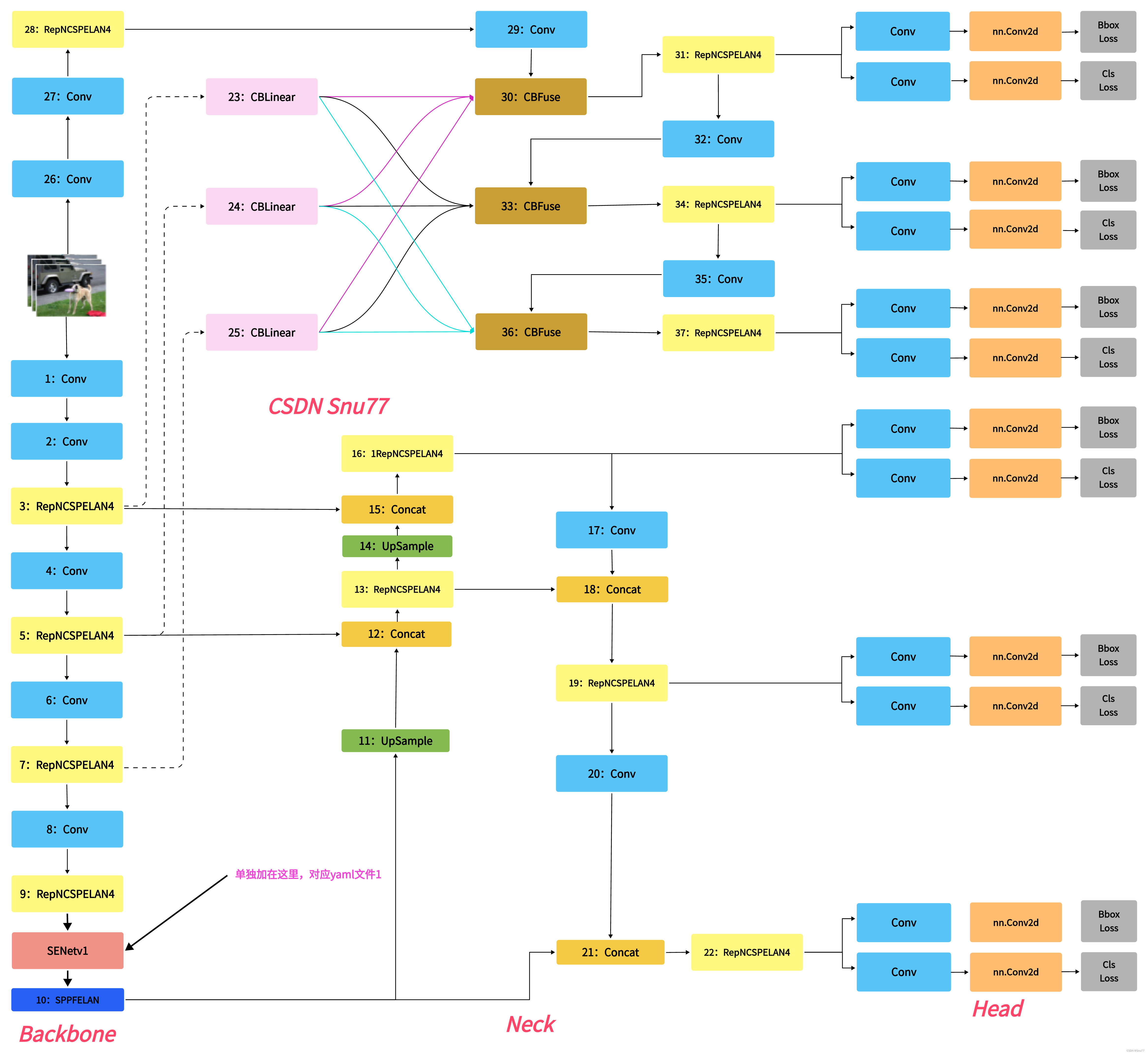
本文给大家带来的改进机制是SENet(Squeeze-and-Excitation Networks)其是一种通过调整卷积网络中的通道关系来提升性能的网络结构。SENet并不是一个独立的网络模型,而是一个可以和现有的任何一个模型相结合的模块(可以看作是一种通道型的注意力机制)。在SENet中,所谓的挤压和激励(Squeeze-and-Excitation)操作是作为一个单元添加到传统的卷积网络结构中。这样可以增强模型对通道间关系的捕获,提升整体的特征表达能力,而不需要从头开始设计一个全新的网络架构。因此,SENet可以看作是对现有网络模型的一种改进和增强,本文提供三种使用方式,下面图片为yaml1对应的结构图。。
欢迎大家订阅我的专栏一起学习YOLO!
推荐指数:⭐⭐⭐⭐⭐
涨点效果:⭐⭐⭐⭐⭐
专栏地址:YOLOv9有效涨点专栏-持续复现各种顶会内容-有效涨点-全网改进最全的专栏
目录
一、本文介绍
二、SENetV1框架原理
三、SENetV1核心代码
四、手把手教你添加SENetV1网络结构
4.1 细节修改教程
4.1.1 修改一
4.1.2 修改二
4.1.3 修改三
4.1.4 修改四
4.2 SENetV1的yaml文件
4.2.1 SENetV1的yaml文件一
4.2.2 SENetV1的yaml文件二
4.2.3 SENetV1的yaml文件三
4.3 SENetV1运行成功截图
五、本文总结
二、SENetV1框架原理

论文地址:官方论文地址
代码地址:官方代码地址

SENet(Squeeze-and-Excitation Networks)的主要思想在于通过挤压-激励(SE)块强化了网络对通道间依赖性的建模。这一创新的核心在于自适应地重新校准每个通道的特征响应,显著提升了网络对特征的表示能力。SE块的叠加构成了SENet架构,有效提高了模型在不同数据集上的泛化性。SENet的创新点包括其独特的结构设计,它在增加极少计算成本的情况下,为现有CNN模型带来了显著的性能提升,并在国际图像识别竞赛ILSVRC 2017中取得了突破性的成果
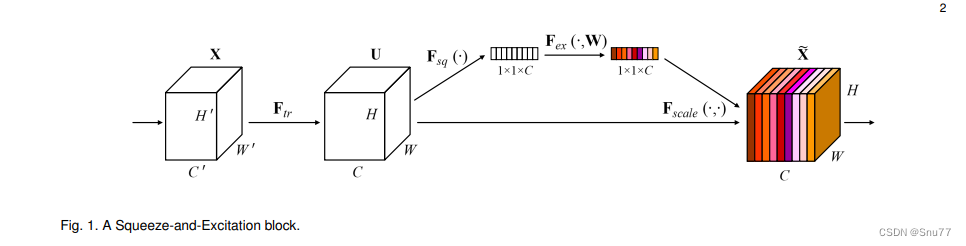
上图展示了一个挤压-激励(Squeeze-and-Excitation, SE)块的结构。输入特征图 经过一个变换
后产生特征图
。然后,特征图
被压缩成一个全局描述子,这是通过全局平均池化
实现的,产生一个通道描述子。这个描述子经过两个全连接层
,第一个是降维,第二个是升维,并通过激活函数如ReLU和Sigmoid激活。最后,原始特征图
与学习到的通道权重
相乘,得到重新校准的特征图
。这种结构有助于网络通过学习通道间的依赖性,自适应地强化或抑制某些特征通道。
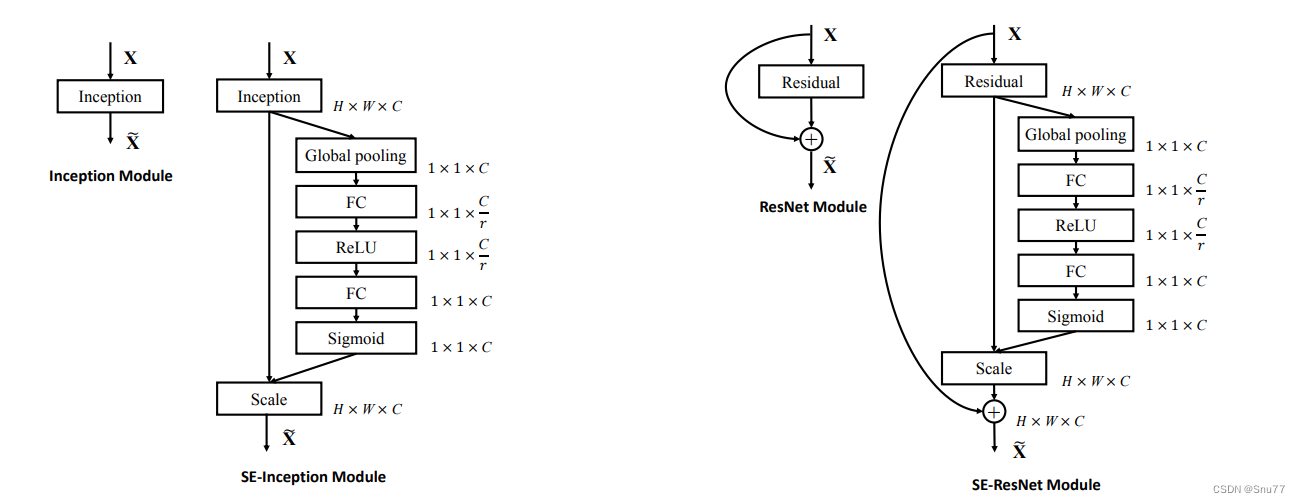
上面的图片展示了两种神经网络模块的结构图:Inception模块和残差(ResNet)模块。每个模块都有其标准形式和一个修改形式,对比图融入了Squeeze-and-Excitation (SE)块来提升性能。
左面的部分是原始Inception模块(左)和SE-Inception模块(右)。SE-Inception模块通过全局平均池化和两个全连接层(第一个使用ReLU激活函数,第二个使用Sigmoid函数)来生成通道级权重,然后对输入特征图进行缩放。
右面的部分展示了原始残差模块(左)和SE-ResNet模块(右)。SE-ResNet模块在传统的残差连接之后添加了SE块,同样使用全局平均池化和全连接层来获得通道级权重,并对残差模块的输出进行缩放。
这两个修改版模块都旨在增强网络对特征的重要性评估能力,从而提升整体模型的性能。
三、SENetV1核心代码
下面的代码是MSDA的核心代码,我们将其复制导'ultralytics/nn/modules'目录下,在其中创建一个文件,我这里起名为Dilation然后粘贴进去,其余使用方式看章节四。
import torch
from torch import nndef autopad(k, p=None, d=1): # kernel, padding, dilation# Pad to 'same' shape outputsif d > 1:k = d * (k - 1) + 1 if isinstance(k, int) else [d * (x - 1) + 1 for x in k] # actual kernel-sizeif p is None:p = k // 2 if isinstance(k, int) else [x // 2 for x in k] # auto-padreturn pclass Conv(nn.Module):# Standard convolution with args(ch_in, ch_out, kernel, stride, padding, groups, dilation, activation)default_act = nn.SiLU() # default activationdef __init__(self, c1, c2, k=1, s=1, p=None, g=1, d=1, act=True):super().__init__()self.conv = nn.Conv2d(c1, c2, k, s, autopad(k, p, d), groups=g, dilation=d, bias=False)self.bn = nn.BatchNorm2d(c2)self.act = self.default_act if act is True else act if isinstance(act, nn.Module) else nn.Identity()def forward(self, x):return self.act(self.bn(self.conv(x)))def forward_fuse(self, x):return self.act(self.conv(x))class SELayerV1(nn.Module):def __init__(self, channel, reduction=16):super(SELayerV1, self).__init__()self.avg_pool = nn.AdaptiveAvgPool2d(1)self.fc = nn.Sequential(nn.Linear(channel, channel // reduction, bias=False),nn.ReLU(inplace=True),nn.Linear(channel // reduction, channel, bias=False),nn.Sigmoid())def forward(self, x):b, c, _, _ = x.size()y = self.avg_pool(x).view(b, c)y = self.fc(y).view(b, c, 1, 1)return x * y.expand_as(x)class Bottleneck(nn.Module):"""Standard bottleneck."""def __init__(self, c1, c2, shortcut=True, g=1, k=(3, 3), e=0.5):"""Initializes a bottleneck module with given input/output channels, shortcut option, group, kernels, andexpansion."""super().__init__()c_ = int(c2 * e) # hidden channelsself.cv1 = Conv(c1, c_, k[0], 1)self.cv2 = Conv(c_, c2, k[1], 1, g=g)self.SE = SELayerV1(c2)self.add = shortcut and c1 == c2def forward(self, x):"""'forward()' applies the YOLO FPN to input data."""return x + self.SE(self.cv2(self.cv1(x))) if self.add else self.SE(self.cv2(self.cv1(x)))class C3_SENetV1(nn.Module):# CSP Bottleneck with 3 convolutionsdef __init__(self, c1, c2, n=1, shortcut=True, g=1, e=0.5): # ch_in, ch_out, number, shortcut, groups, expansionsuper().__init__()c_ = int(c2 * e) # hidden channelsself.cv1 = Conv(c1, c_, 1, 1)self.cv2 = Conv(c1, c_, 1, 1)self.cv3 = Conv(2 * c_, c2, 1) # optional act=FReLU(c2)self.m = nn.Sequential(*(Bottleneck(c_, c_, shortcut, g, e=1.0) for _ in range(n)))def forward(self, x):return self.cv3(torch.cat((self.m(self.cv1(x)), self.cv2(x)), 1))四、手把手教你添加SENetV1网络结构
4.1 细节修改教程
4.1.1 修改一
我们找到如下的目录'yolov9-main/models'在这个目录下创建一个文件目录(注意是目录,因为我这个专栏会出很多的更新,这里用一种一劳永逸的方法)文件目录起名modules,然后在下面新建一个文件,将我们的代码复制粘贴进去。
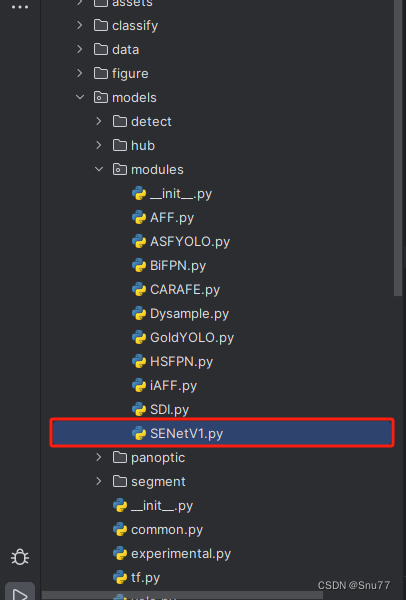
4.1.2 修改二
然后新建一个__init__.py文件,然后我们在里面添加一行代码。注意标记一个'.'其作用是标记当前目录。
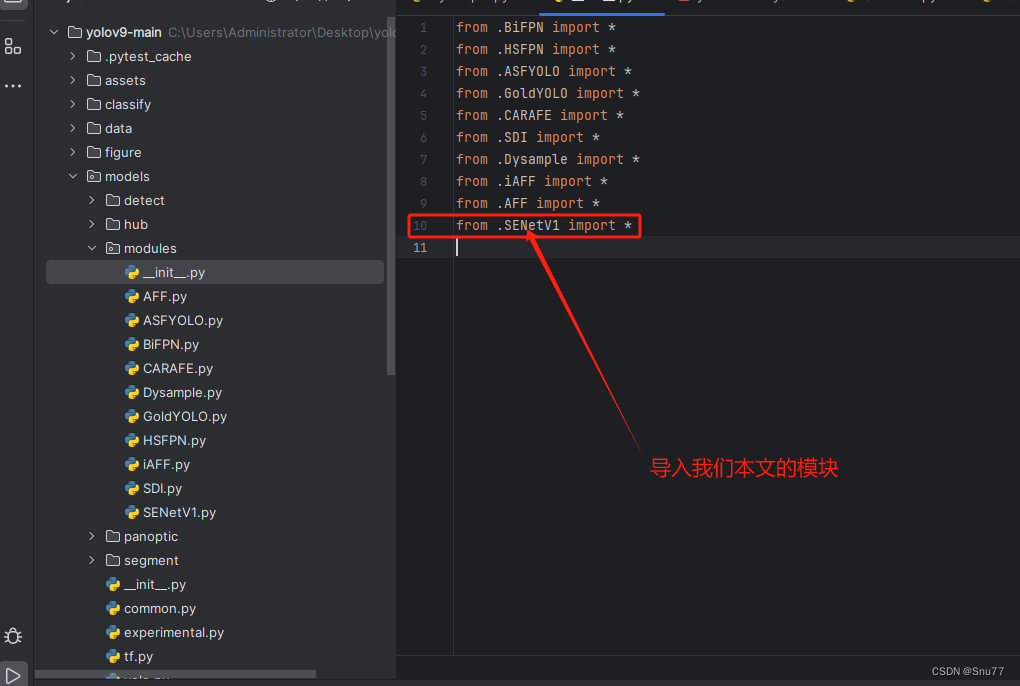
4.1.3 修改三
然后我们找到如下文件''models/yolo.py''在开头的地方导入我们的模块按照如下修改->
(如果你看了我多个改进机制此处只需要添加一个即可,无需重复添加)
注意的添加位置要放在common的导入上面!!!!!

4.1.4 修改四
然后我们找到parse_model方法,按照如下修改->
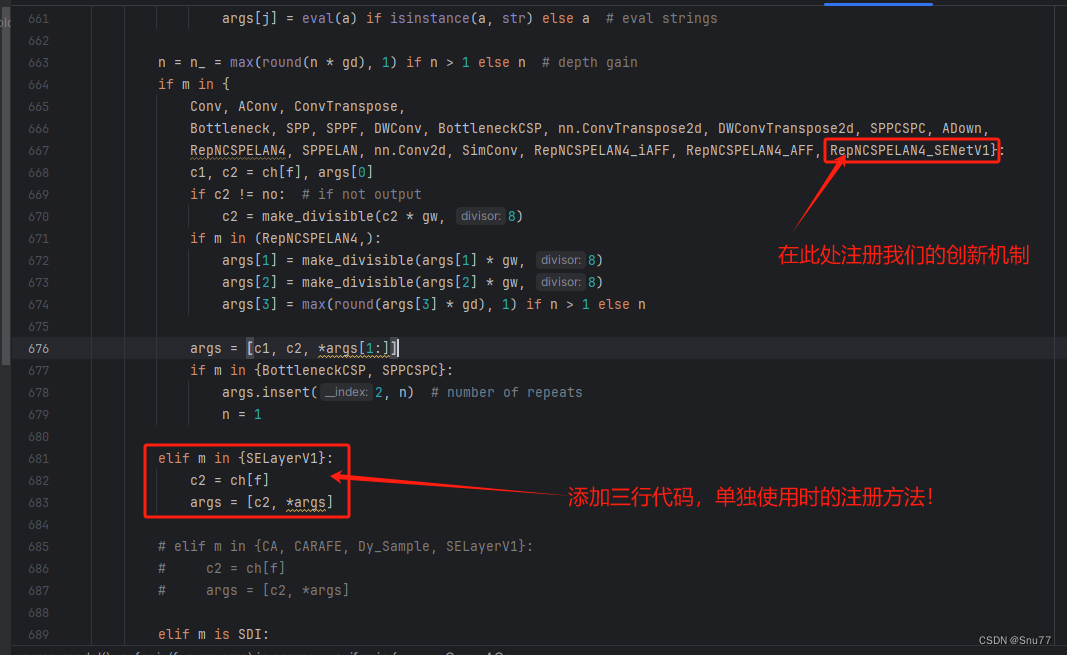
到此就修改完成了,复制下面的ymal文件即可运行。
4.2 SENetV1的yaml文件
4.2.1 SENetV1的yaml文件一
下面的配置文件为我修改的SENetV1的位置,参数的位置里面什么都不用添加空着就行,大家复制粘贴我的就可以运行,同时我提供多个版本给大家,根据我的经验可能涨点的位置。
# YOLOv9# parameters
nc: 80 # number of classes
depth_multiple: 1 # model depth multiple
width_multiple: 1 # layer channel multiple
#activation: nn.LeakyReLU(0.1)
#activation: nn.ReLU()# anchors
anchors: 3# YOLOv9 backbone
backbone:[[-1, 1, Silence, []],# conv down[-1, 1, Conv, [64, 3, 2]], # 1-P1/2# conv down[-1, 1, Conv, [128, 3, 2]], # 2-P2/4# elan-1 block[-1, 1, RepNCSPELAN4, [256, 128, 64, 1]], # 3# conv down[-1, 1, Conv, [256, 3, 2]], # 4-P3/8# elan-2 block[-1, 1, RepNCSPELAN4, [512, 256, 128, 1]], # 5# conv down[-1, 1, Conv, [512, 3, 2]], # 6-P4/16# elan-2 block[-1, 1, RepNCSPELAN4, [512, 512, 256, 1]], # 7# conv down[-1, 1, Conv, [512, 3, 2]], # 8-P5/32# elan-2 block[-1, 1, RepNCSPELAN4, [512, 512, 256, 1]], # 9]# YOLOv9 head
head:[[-1, 1, SELayerV1, []], # 添加一行我们的改进机制# elan-spp block[-1, 1, SPPELAN, [512, 256]], # 11# up-concat merge[-1, 1, nn.Upsample, [None, 2, 'nearest']],[[-1, 7], 1, Concat, [1]], # cat backbone P4# elan-2 block[-1, 1, RepNCSPELAN4, [512, 512, 256, 1]], # 14# up-concat merge[-1, 1, nn.Upsample, [None, 2, 'nearest']],[[-1, 5], 1, Concat, [1]], # cat backbone P3# elan-2 block[-1, 1, RepNCSPELAN4, [256, 256, 128, 1]], # 17 (P3/8-small)# conv-down merge[-1, 1, Conv, [256, 3, 2]],[[-1, 14], 1, Concat, [1]], # cat head P4# elan-2 block[-1, 1, RepNCSPELAN4, [512, 512, 256, 1]], # 20 (P4/16-medium)# conv-down merge[-1, 1, Conv, [512, 3, 2]],[[-1, 11], 1, Concat, [1]], # cat head P5# elan-2 block[-1, 1, RepNCSPELAN4, [512, 512, 256, 1]], # 23 (P5/32-large)# routing[5, 1, CBLinear, [[256]]], # 24[7, 1, CBLinear, [[256, 512]]], # 25[9, 1, CBLinear, [[256, 512, 512]]], # 26# conv down[0, 1, Conv, [64, 3, 2]], # 27-P1/2# conv down[-1, 1, Conv, [128, 3, 2]], # 28-P2/4# elan-1 block[-1, 1, RepNCSPELAN4, [256, 128, 64, 1]], # 29# conv down fuse[-1, 1, Conv, [256, 3, 2]], # 30-P3/8[[24, 25, 26, -1], 1, CBFuse, [[0, 0, 0]]], # 31# elan-2 block[-1, 1, RepNCSPELAN4, [512, 256, 128, 1]], # 32# conv down fuse[-1, 1, Conv, [512, 3, 2]], # 33-P4/16[[25, 26, -1], 1, CBFuse, [[1, 1]]], # 34# elan-2 block[-1, 1, RepNCSPELAN4, [512, 512, 256, 1]], # 35# conv down fuse[-1, 1, Conv, [512, 3, 2]], # 36-P5/32[[26, -1], 1, CBFuse, [[2]]], # 37# elan-2 block[-1, 1, RepNCSPELAN4, [512, 512, 256, 1]], # 38# detect[[32, 35, 38, 17, 20, 23], 1, DualDDetect, [nc]], # DualDDetect(A3, A4, A5, P3, P4, P5)]
4.2.2 SENetV1的yaml文件二
# YOLOv9# parameters
nc: 80 # number of classes
depth_multiple: 1 # model depth multiple
width_multiple: 1 # layer channel multiple
#activation: nn.LeakyReLU(0.1)
#activation: nn.ReLU()# anchors
anchors: 3# YOLOv9 backbone
backbone:[[-1, 1, Silence, []],# conv down[-1, 1, Conv, [64, 3, 2]], # 1-P1/2# conv down[-1, 1, Conv, [128, 3, 2]], # 2-P2/4# elan-1 block[-1, 1, RepNCSPELAN4, [256, 128, 64, 1]], # 3# conv down[-1, 1, Conv, [256, 3, 2]], # 4-P3/8# elan-2 block[-1, 1, RepNCSPELAN4, [512, 256, 128, 1]], # 5# conv down[-1, 1, Conv, [512, 3, 2]], # 6-P4/16# elan-2 block[-1, 1, RepNCSPELAN4, [512, 512, 256, 1]], # 7# conv down[-1, 1, Conv, [512, 3, 2]], # 8-P5/32# elan-2 block[-1, 1, RepNCSPELAN4, [512, 512, 256, 1]], # 9]# YOLOv9 head
head:[# elan-spp block[-1, 1, SPPELAN, [512, 256]], # 10# up-concat merge[-1, 1, nn.Upsample, [None, 2, 'nearest']],[[-1, 7], 1, Concat, [1]], # cat backbone P4# elan-2 block[-1, 1, RepNCSPELAN4, [512, 512, 256, 1]], # 13# up-concat merge[-1, 1, nn.Upsample, [None, 2, 'nearest']],[[-1, 5], 1, Concat, [1]], # cat backbone P3# elan-2 block[-1, 1, RepNCSPELAN4, [256, 256, 128, 1]], # 16 (P3/8-small)[-1, 1, SELayerV1, []], # 17 添加一行我们的改进机制# conv-down merge[-1, 1, Conv, [256, 3, 2]],[[-1, 13], 1, Concat, [1]], # cat head P4# elan-2 block[-1, 1, RepNCSPELAN4, [512, 512, 256, 1]], # 20 (P4/16-medium)[-1, 1, SELayerV1, []], # 21 添加一行我们的改进机制# conv-down merge[-1, 1, Conv, [512, 3, 2]],[[-1, 10], 1, Concat, [1]], # cat head P5# elan-2 block[-1, 1, RepNCSPELAN4, [512, 512, 256, 1]], # 24 (P5/32-large)[-1, 1, SELayerV1, []], # 25 添加一行我们的改进机制# routing[5, 1, CBLinear, [[256]]], # 26[7, 1, CBLinear, [[256, 512]]], # 27[9, 1, CBLinear, [[256, 512, 512]]], # 28# conv down[0, 1, Conv, [64, 3, 2]], # 29-P1/2# conv down[-1, 1, Conv, [128, 3, 2]], # 30-P2/4# elan-1 block[-1, 1, RepNCSPELAN4, [256, 128, 64, 1]], # 31# conv down fuse[-1, 1, Conv, [256, 3, 2]], # 32-P3/8[[26, 27, 28, -1], 1, CBFuse, [[0, 0, 0]]], # 33# elan-2 block[-1, 1, RepNCSPELAN4, [512, 256, 128, 1]], # 34[-1, 1, SELayerV1, []], # 35 添加一行我们的改进机制# conv down fuse[-1, 1, Conv, [512, 3, 2]], # 36-P4/16[[27, 28, -1], 1, CBFuse, [[1, 1]]], # 37# elan-2 block[-1, 1, RepNCSPELAN4, [512, 512, 256, 1]], # 38[-1, 1, SELayerV1, []], # 39 添加一行我们的改进机制# conv down fuse[-1, 1, Conv, [512, 3, 2]], # 40-P5/32[[28, -1], 1, CBFuse, [[2]]], # 41# elan-2 block[-1, 1, RepNCSPELAN4, [512, 512, 256, 1]], # 42[-1, 1, SELayerV1, []], # 43 添加一行我们的改进机制# detect[[35, 39, 43, 17, 21, 25], 1, DualDDetect, [nc]], # DualDDetect(A3, A4, A5, P3, P4, P5)]
4.2.3 SENetV1的yaml文件三
注意此版本的我再大目标,小目标,中目标三个曾的后面添加了一个注意力机制,此版本需要显存较大,可以根据自己的需求增删,如果修改大家要注意修改Detect里面的检测层数。
# YOLOv9# parameters
nc: 80 # number of classes
depth_multiple: 1 # model depth multiple
width_multiple: 1 # layer channel multiple
#activation: nn.LeakyReLU(0.1)
#activation: nn.ReLU()# anchors
anchors: 3# YOLOv9 backbone
backbone:[[-1, 1, Silence, []],# conv down[-1, 1, Conv, [64, 3, 2]], # 1-P1/2# conv down[-1, 1, Conv, [128, 3, 2]], # 2-P2/4# elan-1 block[-1, 1, RepNCSPELAN4_SENetV1, [256, 128, 64, 1]], # 3# conv down[-1, 1, Conv, [256, 3, 2]], # 4-P3/8# elan-2 block[-1, 1, RepNCSPELAN4_SENetV1, [512, 256, 128, 1]], # 5# conv down[-1, 1, Conv, [512, 3, 2]], # 6-P4/16# elan-2 block[-1, 1, RepNCSPELAN4_SENetV1, [512, 512, 256, 1]], # 7# conv down[-1, 1, Conv, [512, 3, 2]], # 8-P5/32# elan-2 block[-1, 1, RepNCSPELAN4_SENetV1, [512, 512, 256, 1]], # 9]# YOLOv9 head
head:[# elan-spp block[-1, 1, SPPELAN, [512, 256]], # 10# up-concat merge[-1, 1, nn.Upsample, [None, 2, 'nearest']],[[-1, 7], 1, Concat, [1]], # cat backbone P4# elan-2 block[-1, 1, RepNCSPELAN4, [512, 512, 256, 1]], # 13# up-concat merge[-1, 1, nn.Upsample, [None, 2, 'nearest']],[[-1, 5], 1, Concat, [1]], # cat backbone P3# elan-2 block[-1, 1, RepNCSPELAN4_SENetV1, [256, 256, 128, 1]], # 16 (P3/8-small)# conv-down merge[-1, 1, Conv, [256, 3, 2]],[[-1, 13], 1, Concat, [1]], # cat head P4# elan-2 block[-1, 1, RepNCSPELAN4_SENetV1, [512, 512, 256, 1]], # 19 (P4/16-medium)# conv-down merge[-1, 1, Conv, [512, 3, 2]],[[-1, 10], 1, Concat, [1]], # cat head P5# elan-2 block[-1, 1, RepNCSPELAN4_SENetV1, [512, 512, 256, 1]], # 22 (P5/32-large)# routing[5, 1, CBLinear, [[256]]], # 23[7, 1, CBLinear, [[256, 512]]], # 24[9, 1, CBLinear, [[256, 512, 512]]], # 25# conv down[0, 1, Conv, [64, 3, 2]], # 26-P1/2# conv down[-1, 1, Conv, [128, 3, 2]], # 27-P2/4# elan-1 block[-1, 1, RepNCSPELAN4_SENetV1, [256, 128, 64, 1]], # 28# conv down fuse[-1, 1, Conv, [256, 3, 2]], # 29-P3/8[[23, 24, 25, -1], 1, CBFuse, [[0, 0, 0]]], # 30 # elan-2 block[-1, 1, RepNCSPELAN4_SENetV1, [512, 256, 128, 1]], # 31# conv down fuse[-1, 1, Conv, [512, 3, 2]], # 32-P4/16[[24, 25, -1], 1, CBFuse, [[1, 1]]], # 33 # elan-2 block[-1, 1, RepNCSPELAN4_SENetV1, [512, 512, 256, 1]], # 34# conv down fuse[-1, 1, Conv, [512, 3, 2]], # 35-P5/32[[25, -1], 1, CBFuse, [[2]]], # 36# elan-2 block[-1, 1, RepNCSPELAN4_SENetV1, [512, 512, 256, 1]], # 37# detect[[31, 34, 37, 16, 19, 22], 1, DualDDetect, [nc]], # DualDDetect(A3, A4, A5, P3, P4, P5)]
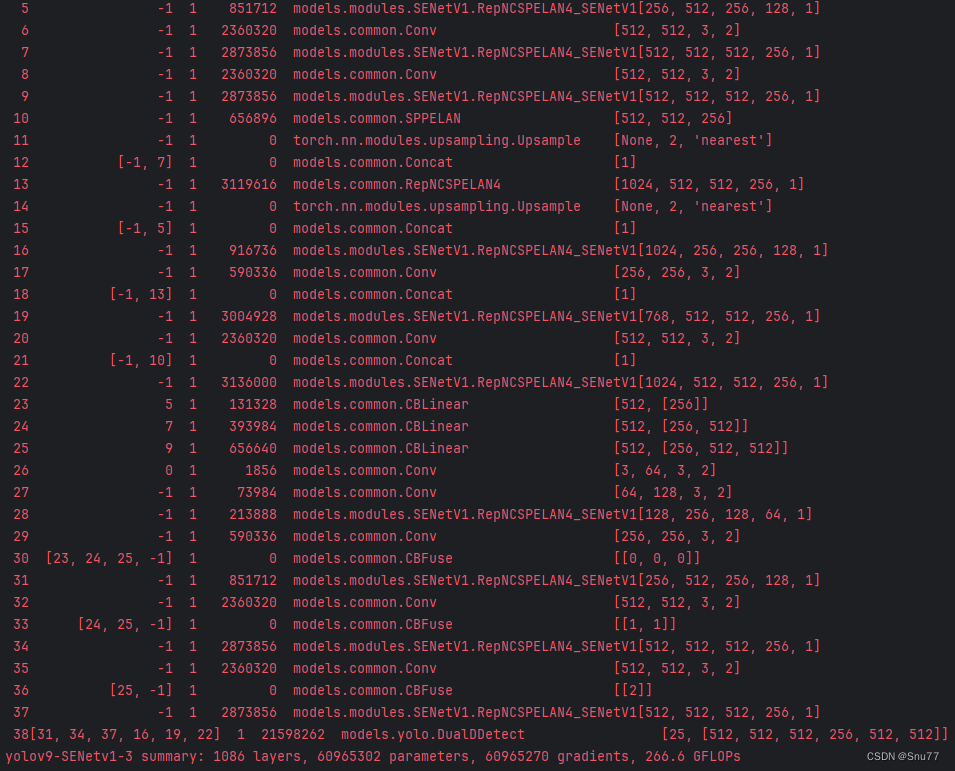
4.3 SENetV1运行成功截图
附上我的运行记录确保我的教程是可用的。
五、本文总结
到此本文的正式分享内容就结束了,在这里给大家推荐我的YOLOv9改进有效涨点专栏,本专栏目前为新开的平均质量分98分,后期我会根据各种最新的前沿顶会进行论文复现,也会对一些老的改进机制进行补充,目前本专栏免费阅读(暂时,大家尽早关注不迷路~),如果大家觉得本文帮助到你了,订阅本专栏,关注后续更多的更新~
专栏地址:YOLOv9有效涨点专栏-持续复现各种顶会内容-有效涨点-全网改进最全的专栏

这篇关于YOLOv9改进策略 | 添加注意力篇 | 利用ILSVRC冠军得主SENetV1改善网络模型特征提取能力的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!








