本文主要是介绍书生·浦语大模型实战营(第二期):XTuner 微调 LLM,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
目录
- Finetune简介
- 两种Finetune范式
- 一条数据的一生
- 标准格式数据
- 添加对话模板
- 两种finetune的loss计算
- LoRA&QLoRA
- XTuner
- XTuner简介
- XTuner快速上手
- 安装&训练
- 配置模板
- 对话
- 工具
- 数据处理
- 数据集映射函数
- InternLM2 1.8B模型
- 多模态LLM
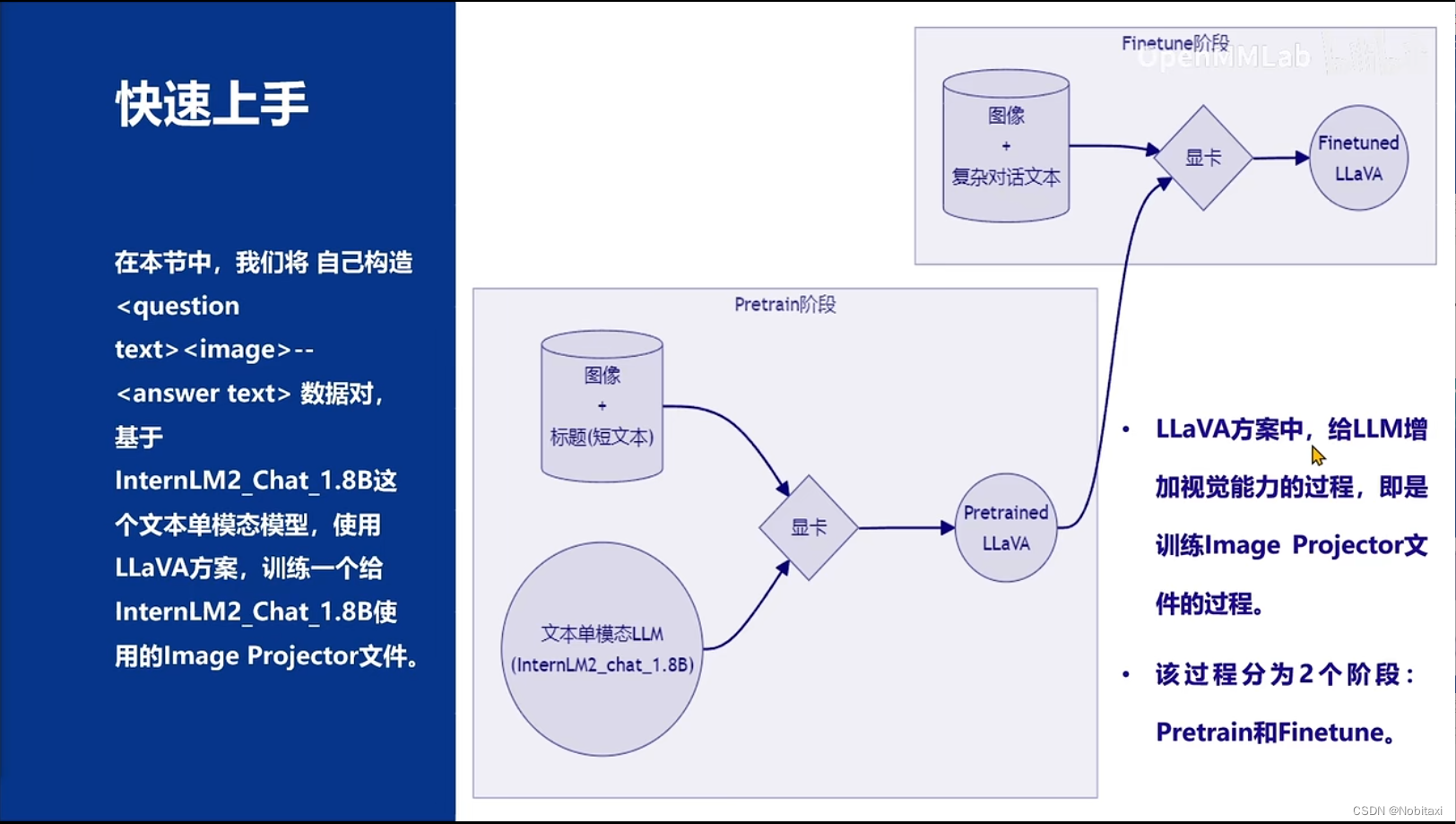
- 给LLM装上电子眼:多模态LLM原理简介
- 什么型号的电子眼:LLaVA方案简介
- 快速上手
- 作业一:训练自己的小助手认知
- 环境安装
- 前期准备
- 数据集准备
- 模型准备
- 配置文件选择
- 配置文件修改
- 模型训练
- 模型转换、整合、测试及部署
- 模型转换
- 模型转换
- 对话测试
- Web demo部署
Finetune简介
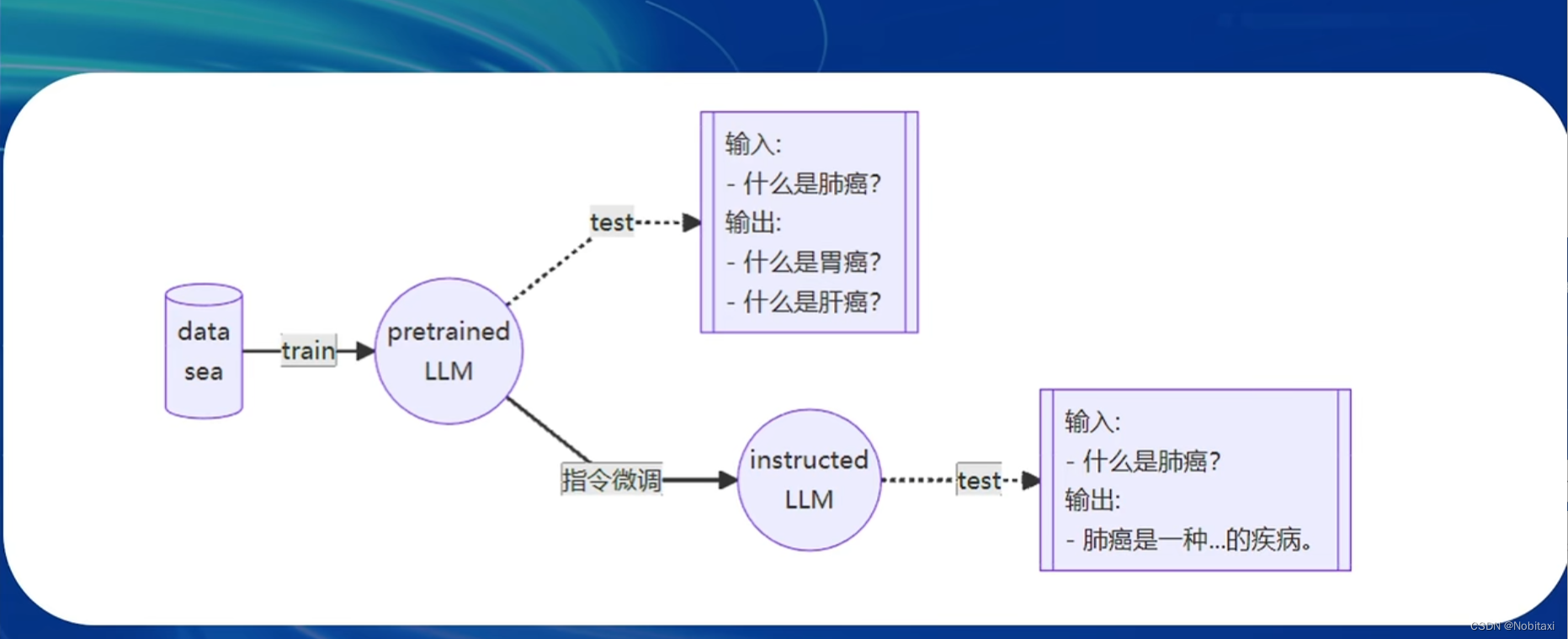
两种Finetune范式
- 增量预训练微调
- 指令跟随微调

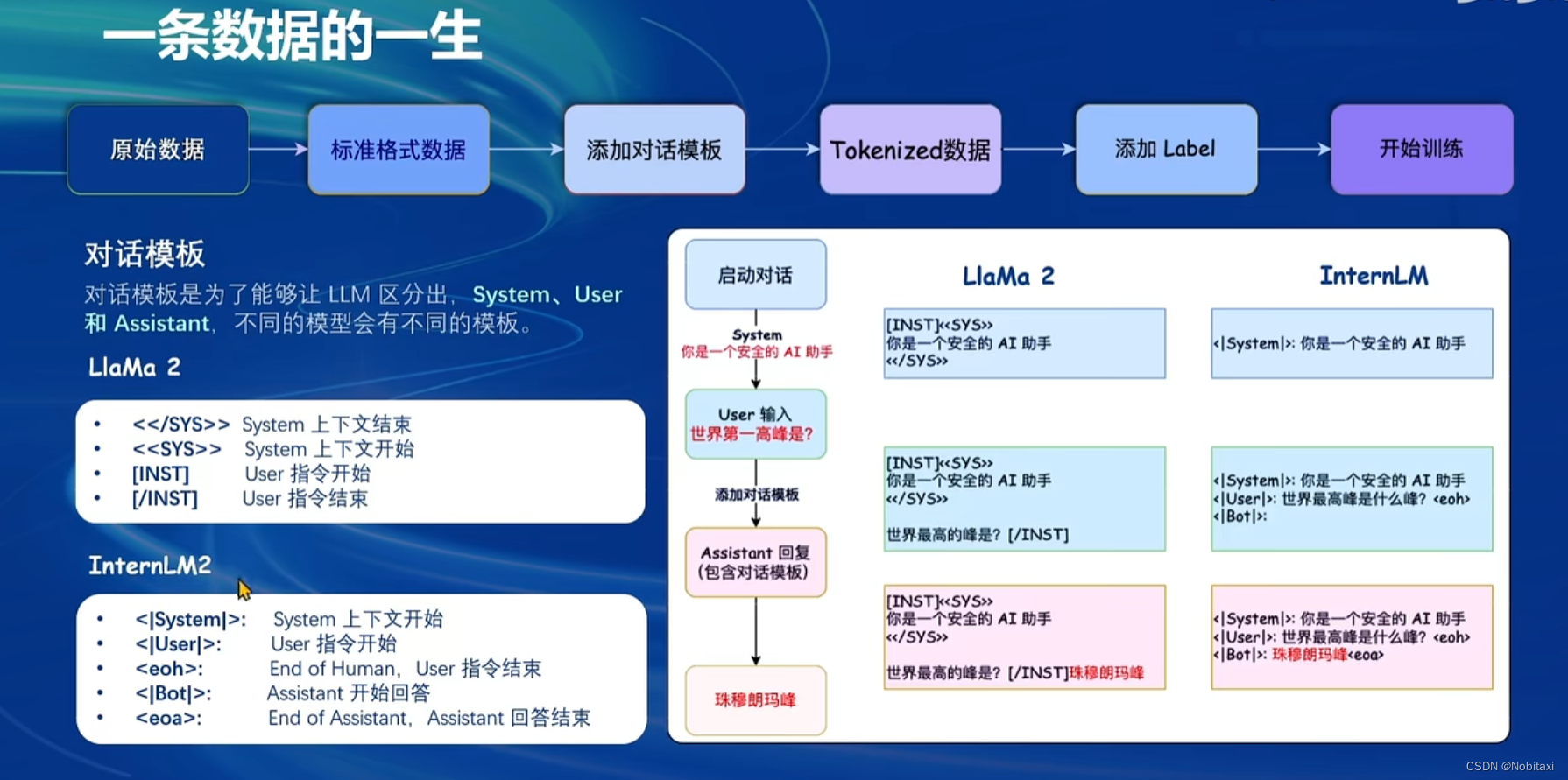
一条数据的一生
标准格式数据

添加对话模板
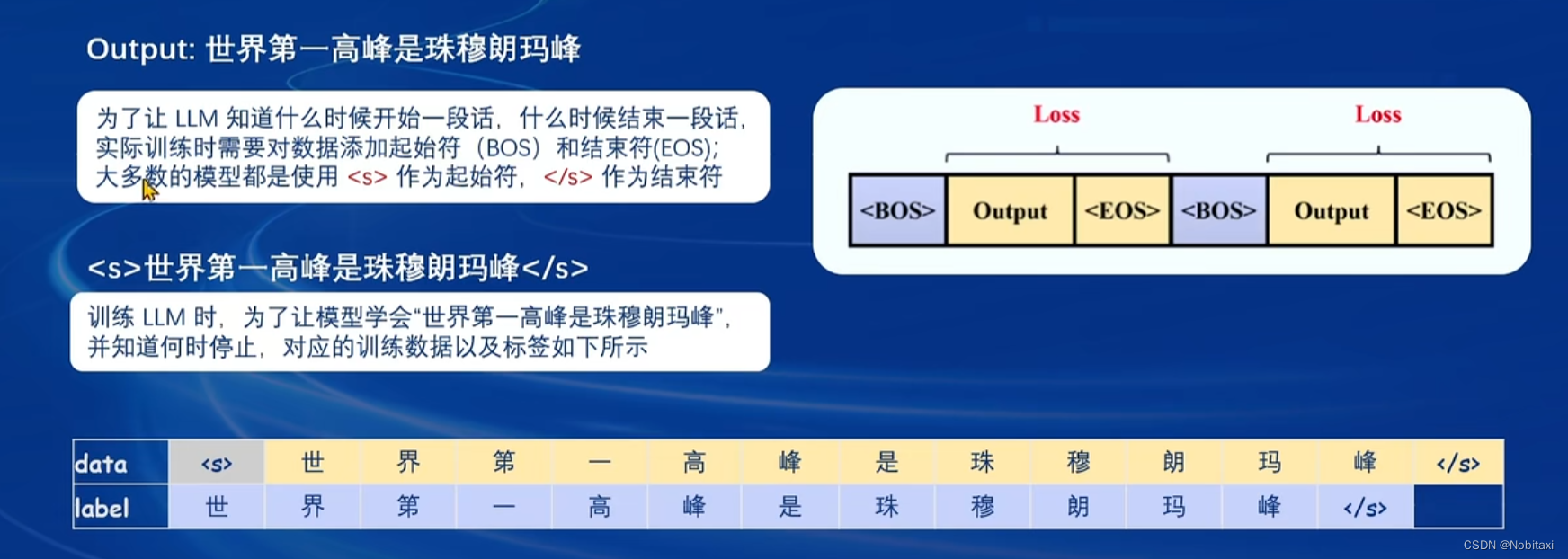
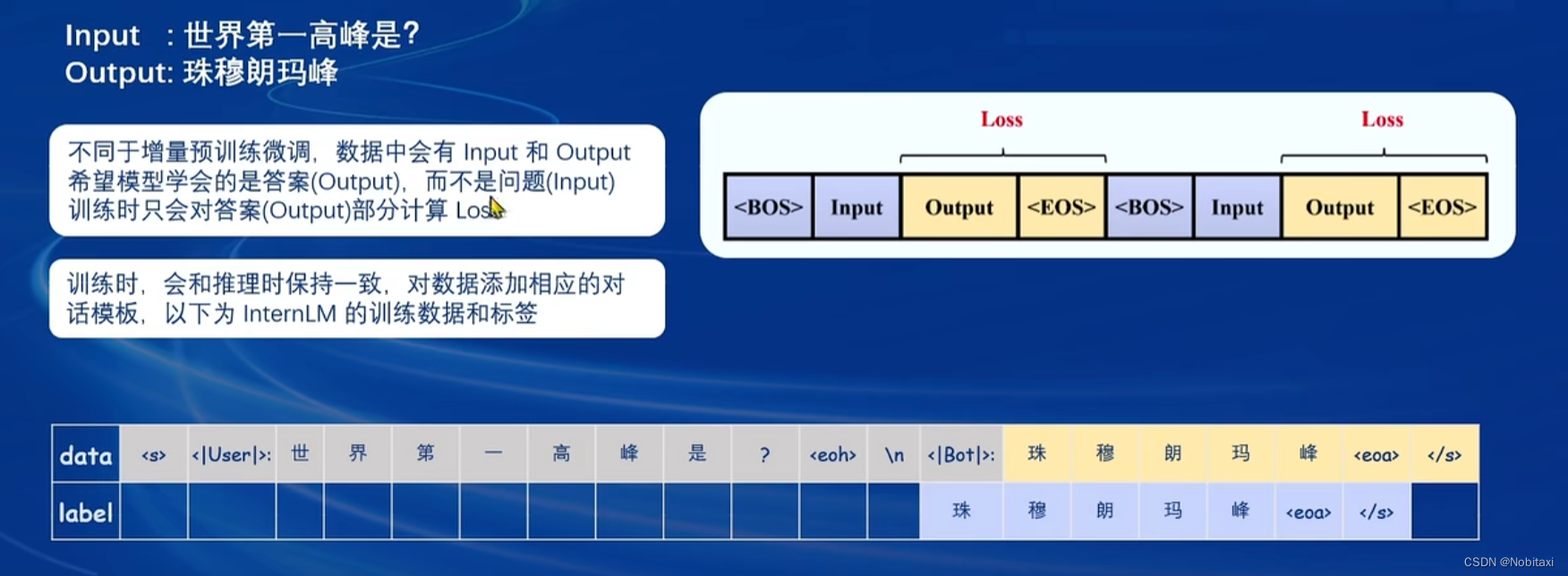
两种finetune的loss计算
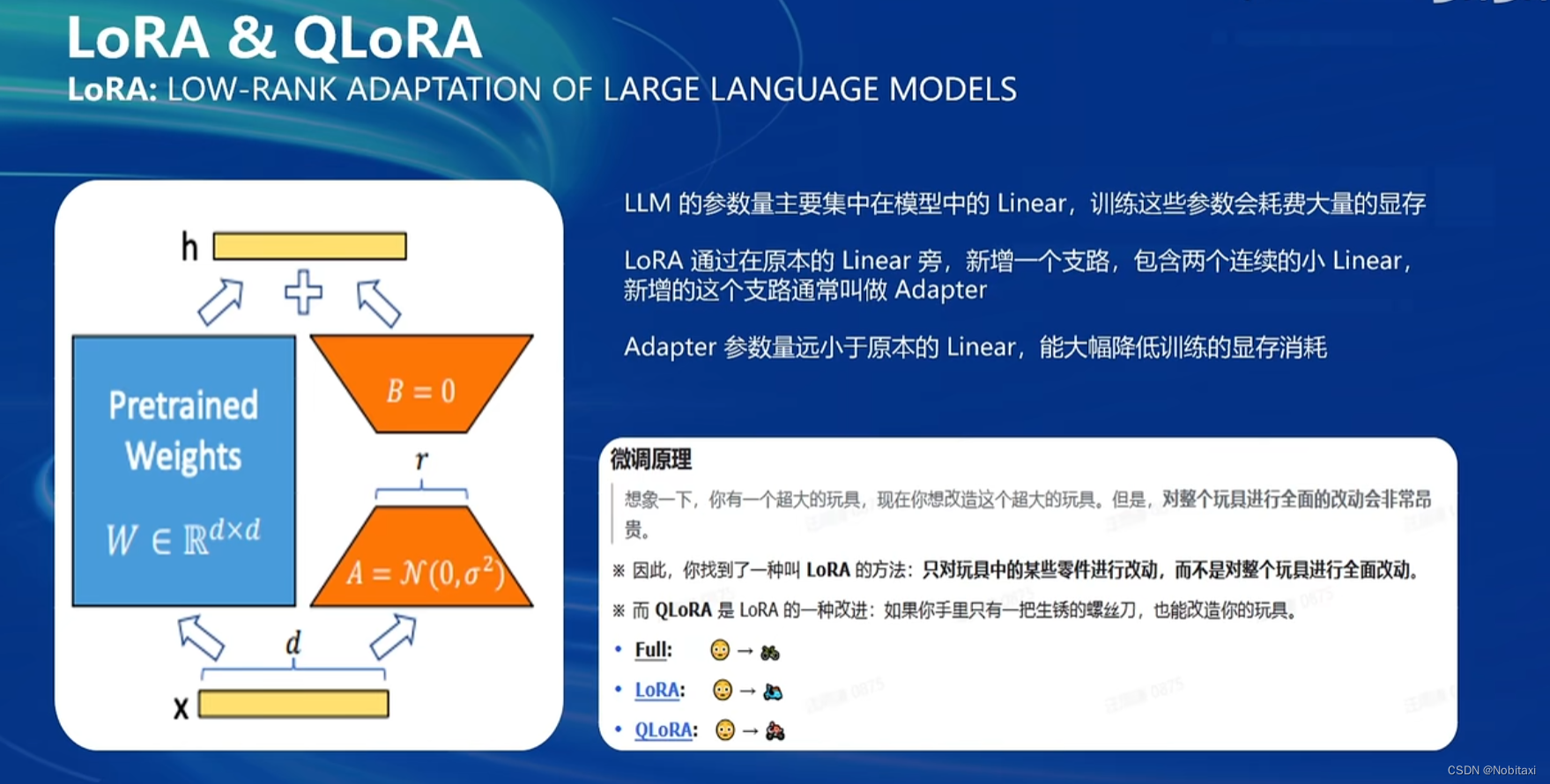
LoRA&QLoRA
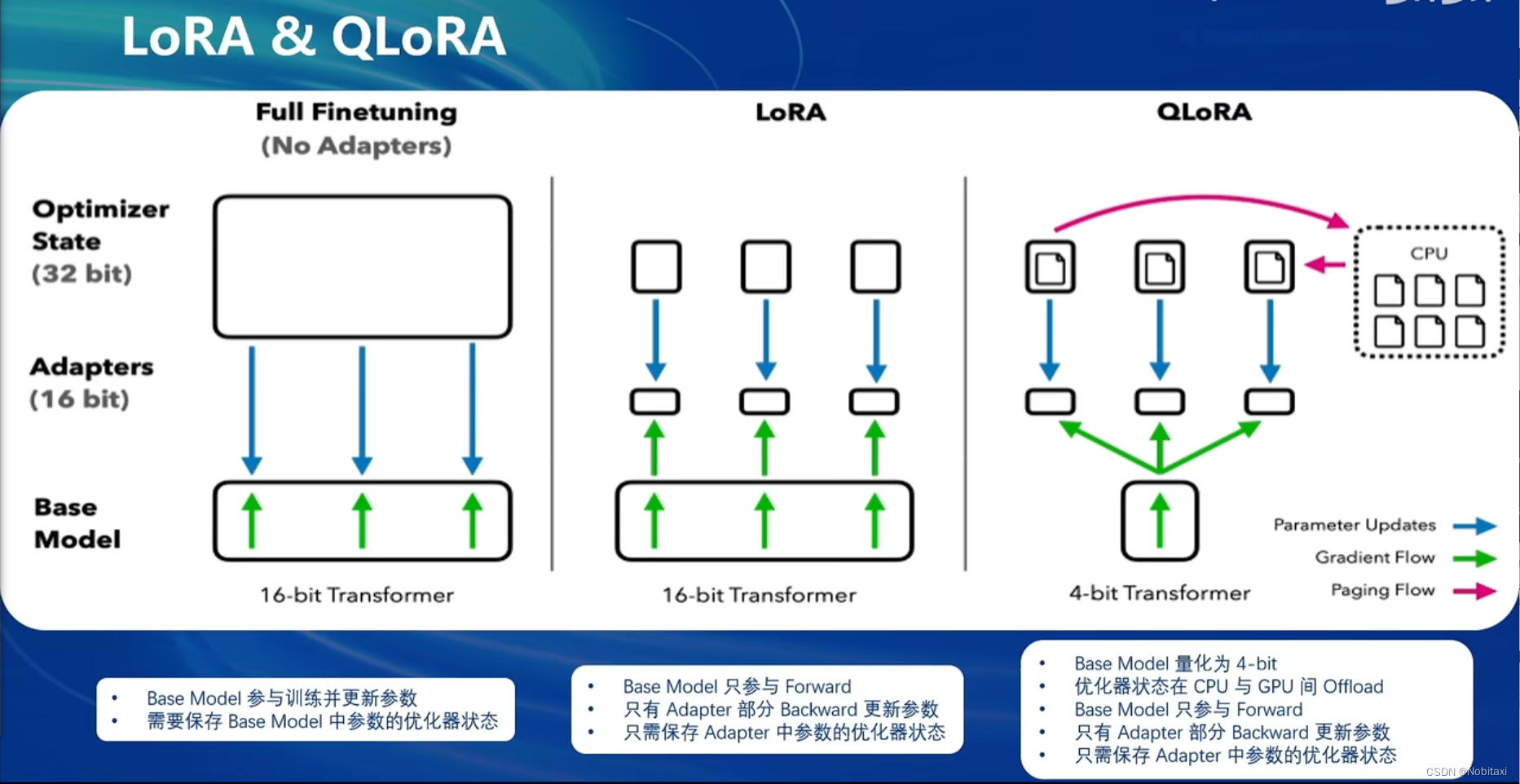
XTuner
XTuner简介
- 傻瓜化:以
配置文件的形式封装了大部分微调场景,0基础的非专业人员也能一键开始微调 - 轻量级:对于7B参数量的LLM,微调所需的最小显存仅为8GB

XTuner快速上手
安装&训练
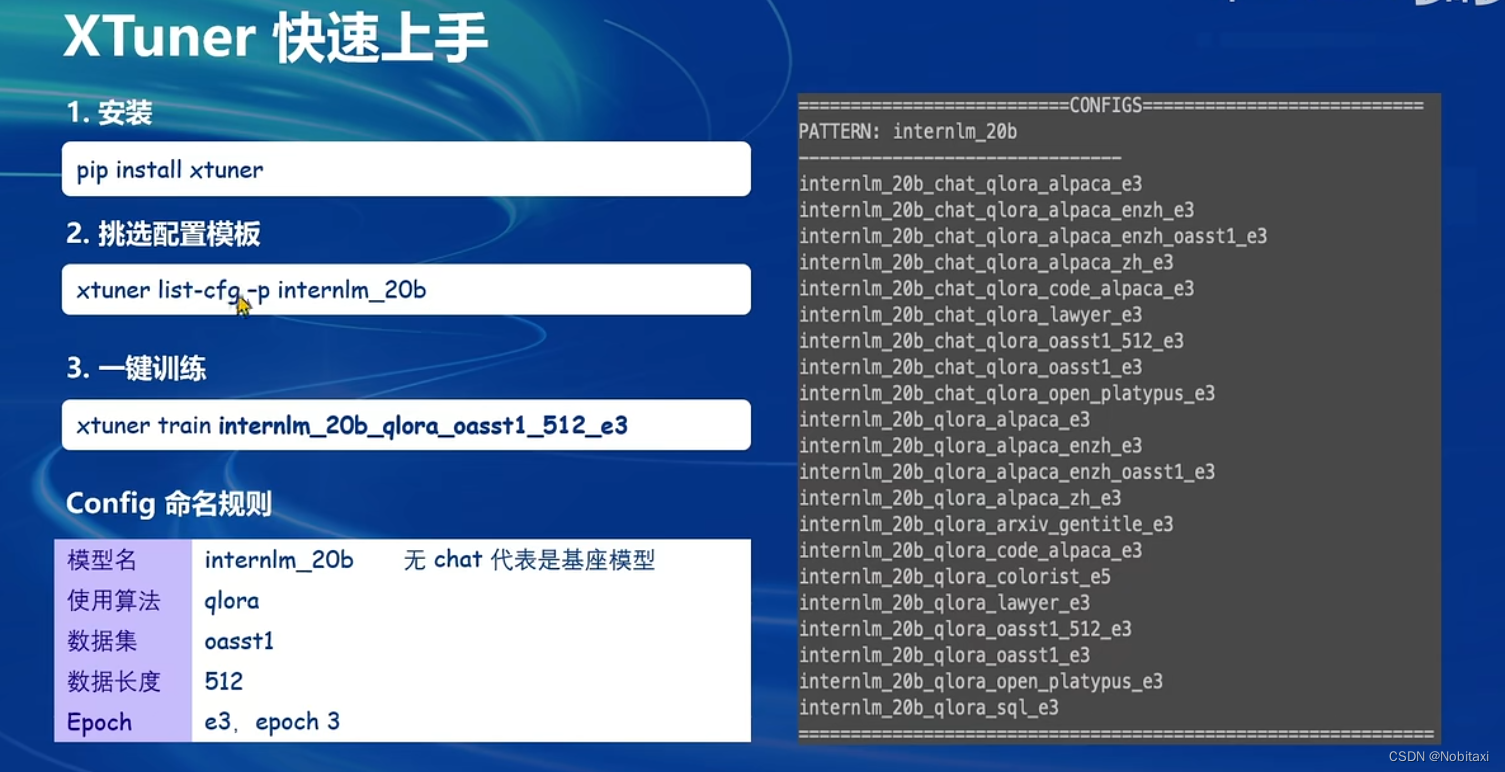
配置模板

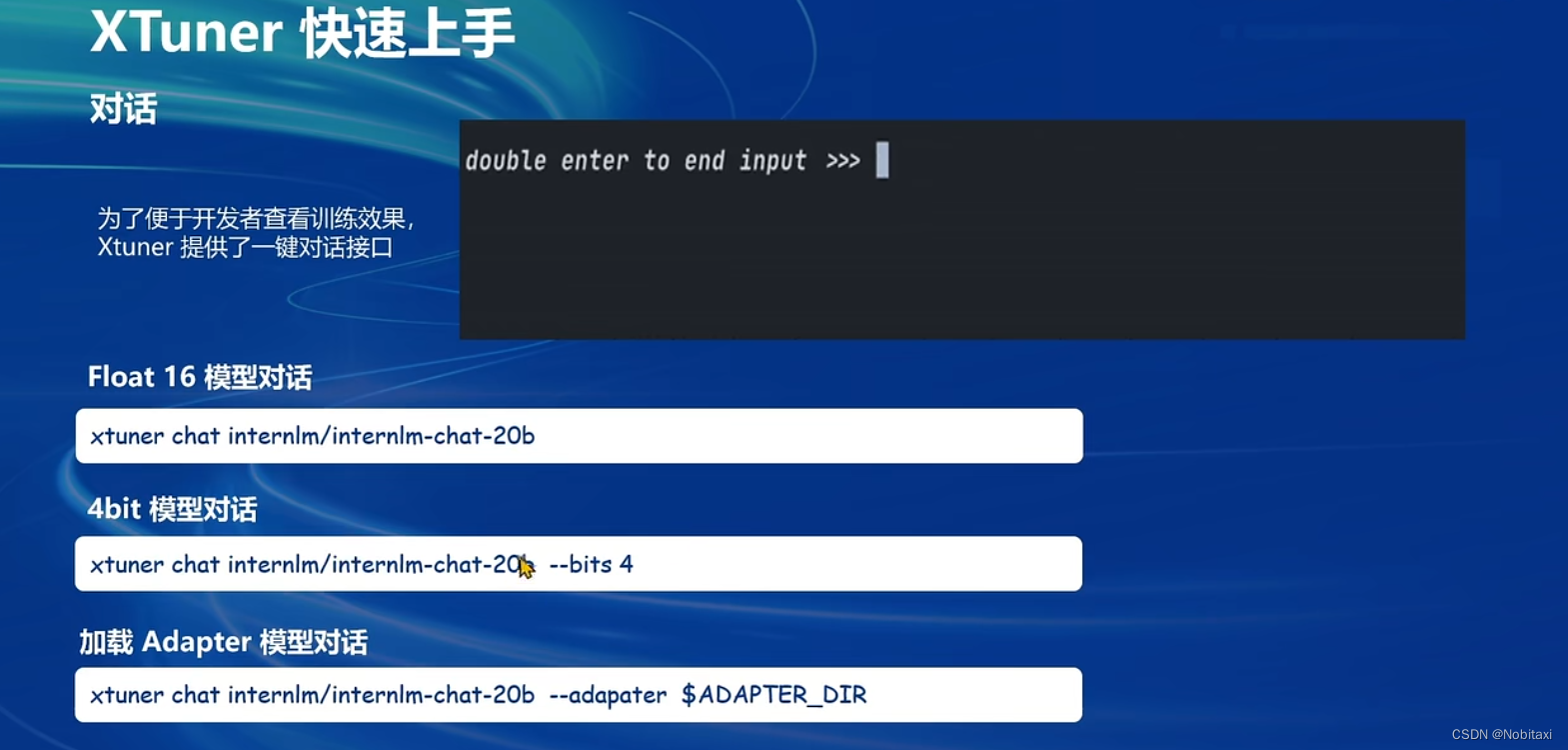
对话
工具
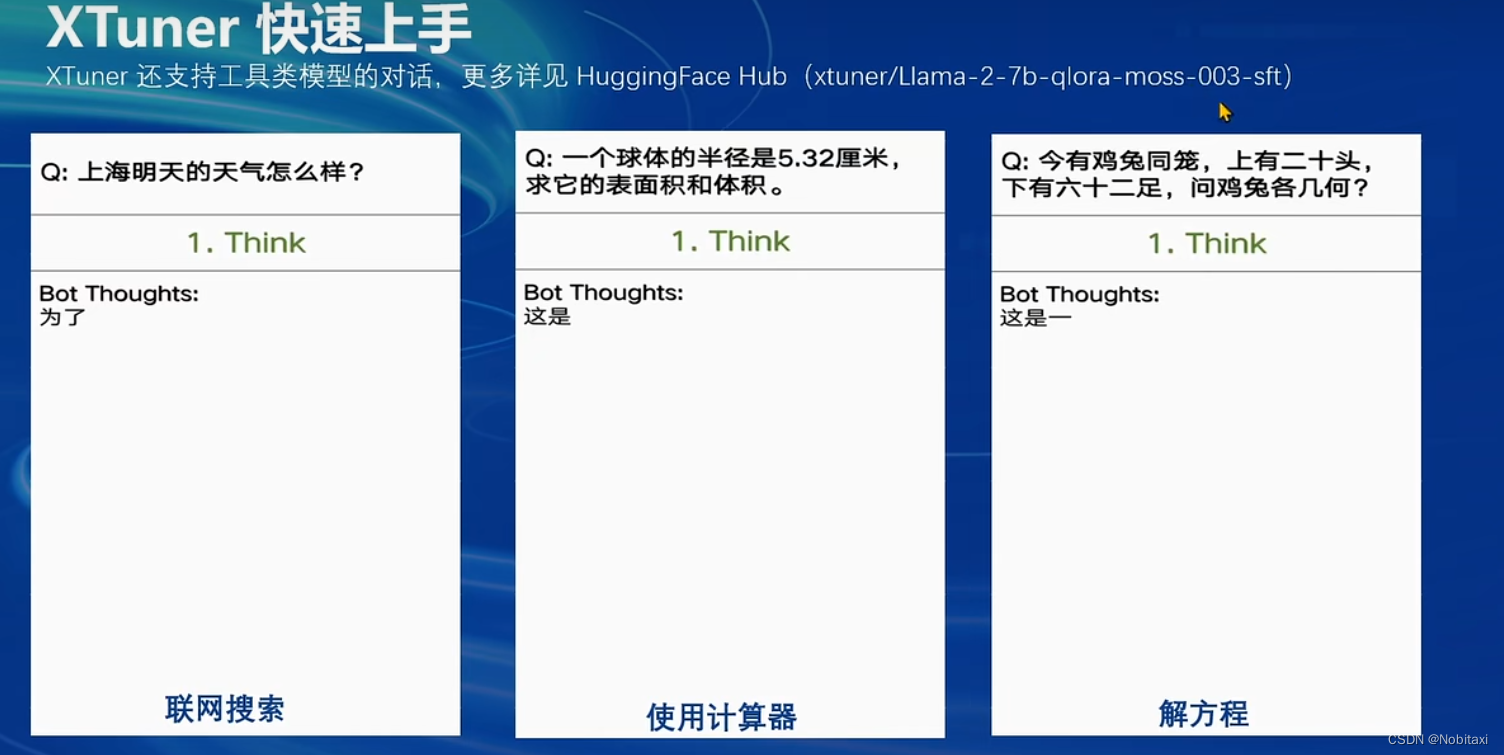
数据处理
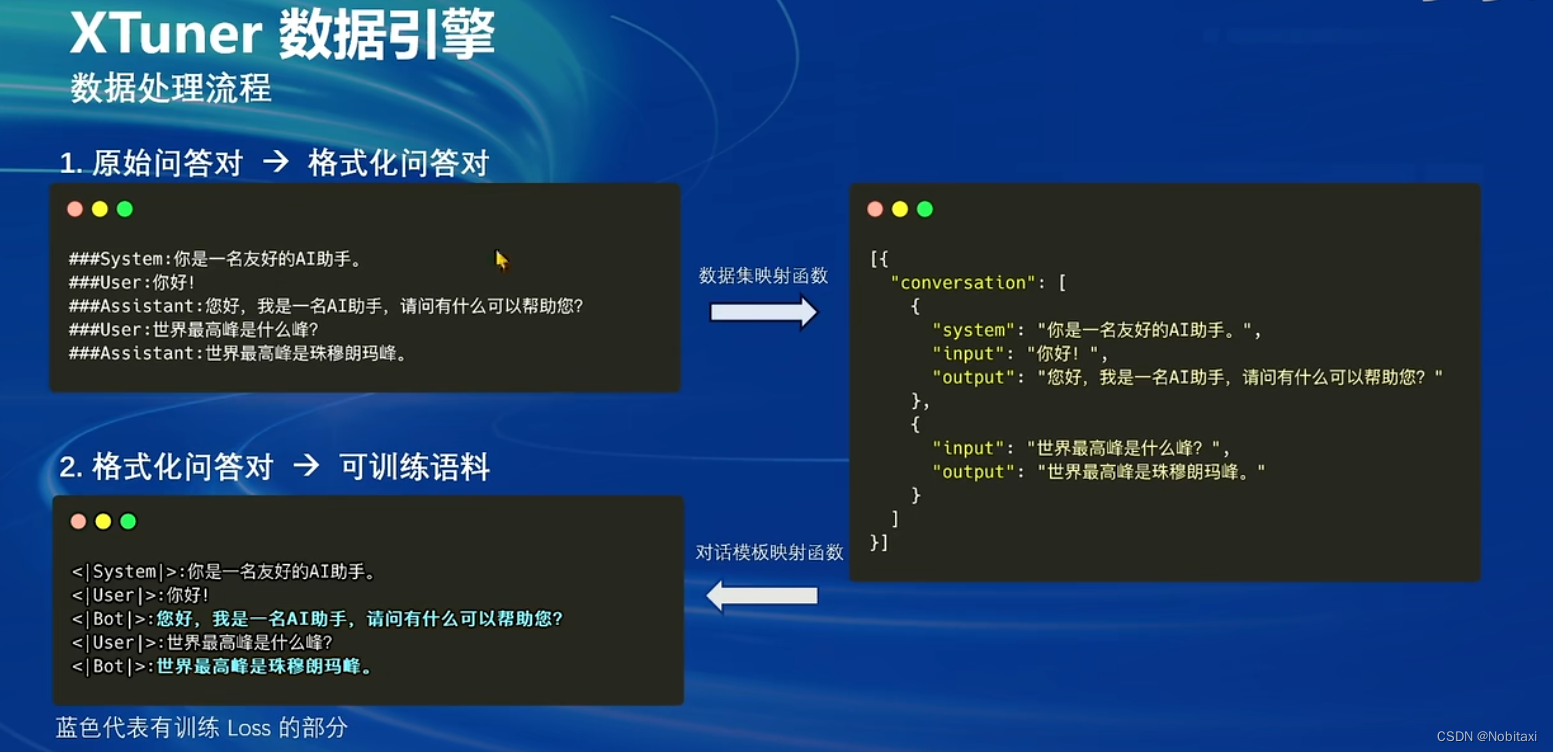
数据集映射函数

InternLM2 1.8B模型

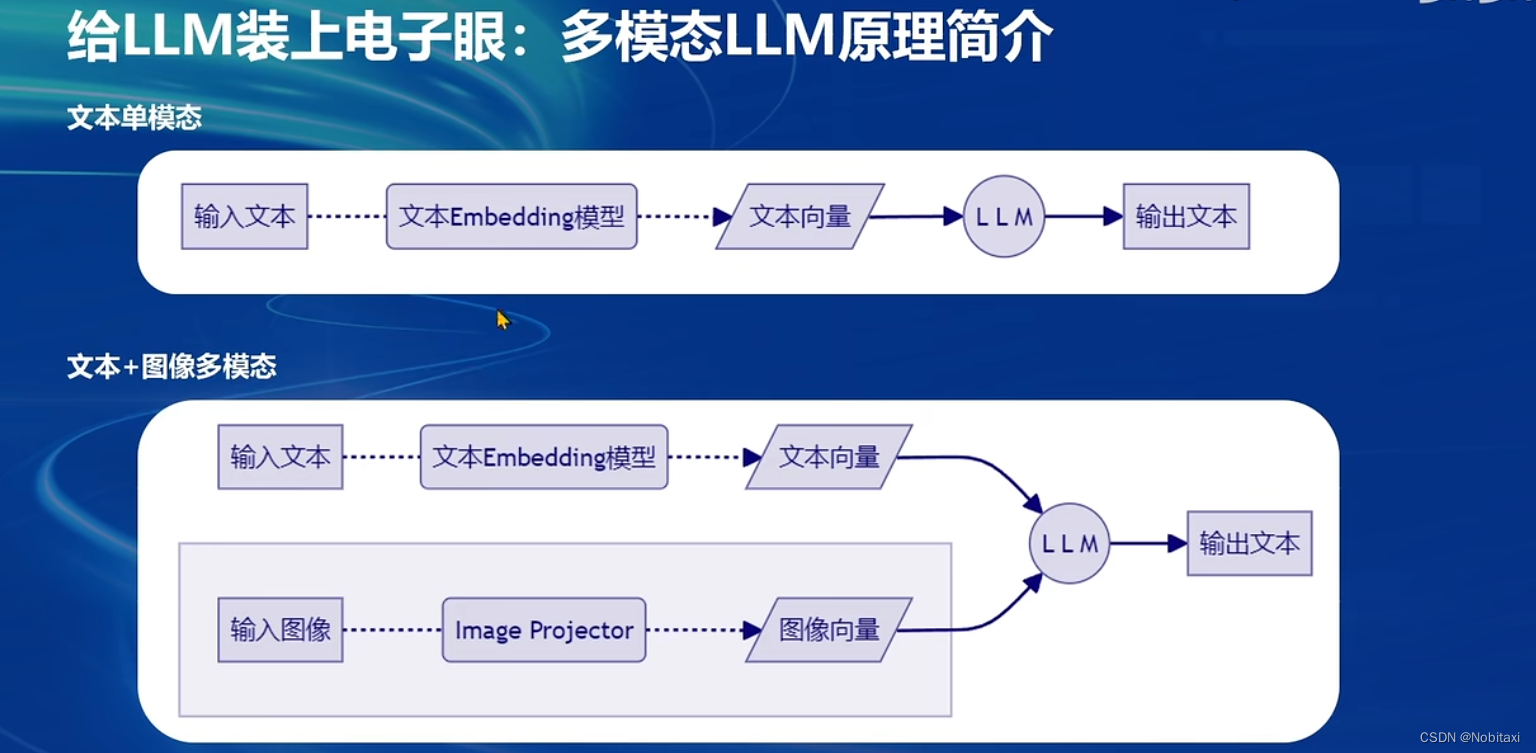
多模态LLM
给LLM装上电子眼:多模态LLM原理简介
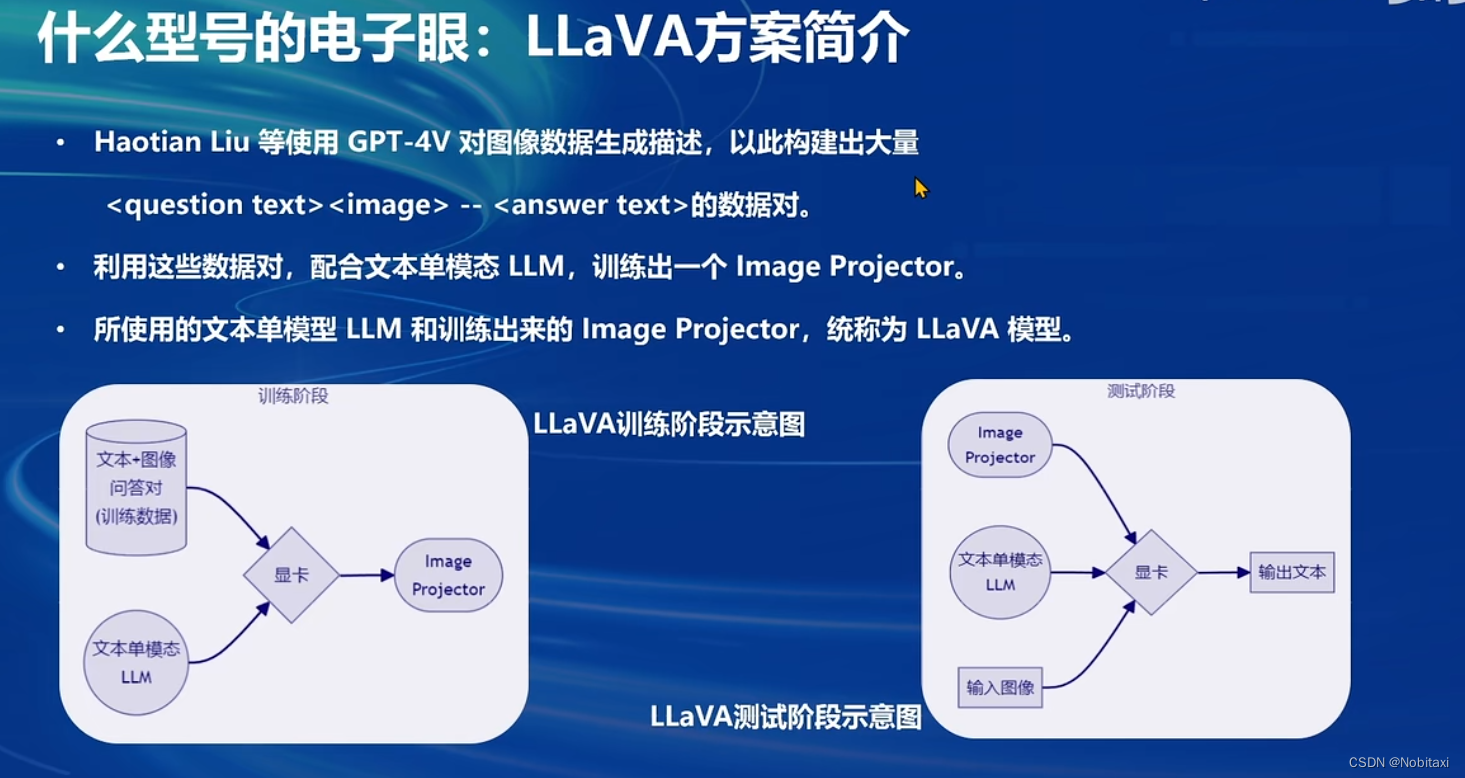
什么型号的电子眼:LLaVA方案简介
快速上手
作业一:训练自己的小助手认知
环境安装
# conda create --name xtuner0.1.17 python=3.10 -y
# 激活环境
conda activate xtuner0.1.17
# 进入家目录 (~的意思是 “当前用户的home路径”)
cd ~
# 创建版本文件夹并进入,以跟随本教程
mkdir -p /root/xtuner0117 && cd /root/xtuner0117# 拉取 0.1.17 的版本源码
git clone -b v0.1.17 https://github.com/InternLM/xtuner
# 无法访问github的用户请从 gitee 拉取:
# git clone -b v0.1.15 https://gitee.com/Internlm/xtuner# 进入源码目录
cd /root/xtuner0117/xtuner# 从源码安装 XTuner
pip install -e '.[all]'
前期准备
数据集准备
首先我们先创建一个文件夹来存放我们这次训练所需要的所有文件。
# 前半部分是创建一个文件夹,后半部分是进入该文件夹。
mkdir -p /root/ft && cd /root/ft# 在ft这个文件夹里再创建一个存放数据的data文件夹
mkdir -p /root/ft/data && cd /root/ft/data
之后我们可以在 data 目录下新建一个 generate_data.py 文件,将以下代码复制进去,然后运行该脚本即可生成数据集。假如想要加大剂量让他能够完完全全认识到你的身份,那我们可以吧 n 的值调大一点。
# 创建 `generate_data.py` 文件
touch /root/ft/data/generate_data.py
打开该 python 文件后将下面的内容复制进去。
import json# 设置用户的名字
name = 'Nobitaxi' # 替换成自己想要的助手名字
# 设置需要重复添加的数据次数
n = 10000# 初始化OpenAI格式的数据结构
data = [{"messages": [{"role": "user","content": "请做一下自我介绍"},{"role": "assistant","content": "我是{}的小助手,内在是上海AI实验室书生·浦语的1.8B大模型哦".format(name)}]}
]# 通过循环,将初始化的对话数据重复添加到data列表中
for i in range(n):data.append(data[0])# 将data列表中的数据写入到一个名为'personal_assistant.json'的文件中
with open('personal_assistant.json', 'w', encoding='utf-8') as f:# 使用json.dump方法将数据以JSON格式写入文件# ensure_ascii=False 确保中文字符正常显示# indent=4 使得文件内容格式化,便于阅读json.dump(data, f, ensure_ascii=False, indent=4)
修改完成后运行 generate_data.py 文件即可。
# 确保先进入该文件夹
cd /root/ft/data# 运行代码
python /root/ft/data/generate_data.py
可以看到在data的路径下便生成了一个名为 personal_assistant.json 的文件,这样我们最可用于微调的数据集就准备好啦!里面就包含了 10000 条 input 和 output 的数据对。
模型准备
使用InternLM最新推出的小模型InternLM2-Chat-1.8B
配置文件选择
所谓配置文件(config),其实是一种用于定义和控制模型训练和测试过程中各个方面的参数和设置的工具。准备好的配置文件只要运行起来就代表着模型就开始训练或者微调了。
XTuner 提供多个开箱即用的配置文件,用户可以通过下列命令查看:
# 列出所有内置配置文件
# xtuner list-cfg# 假如我们想找到 internlm2-1.8b 模型里支持的配置文件
xtuner list-cfg -p internlm2_1_8b
我们发现关于internlm2-1.8B的模型配置文件目前只有两个:
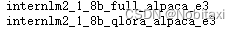
我们选择使用internlm2_1_8b_qlora_alpaca_e3这个文件作为我们微调的配置文件
# 创建一个存放 config 文件的文件夹
mkdir -p /root/ft/config# 使用 XTuner 中的 copy-cfg 功能将 config 文件复制到指定的位置
xtuner copy-cfg internlm2_1_8b_qlora_alpaca_e3 /root/ft/config
配置文件修改
具体需要修改的是以下部分:
# from xtuner.dataset.map_fns import alpaca_map_fn, template_map_fn_factory
from xtuner.dataset.map_fns import openai_map_fn, template_map_fn_factory# pretrained_model_name_or_path = 'internlm/internlm2-1_8b'
pretrained_model_name_or_path = '/root/ft/Shanghai_AI_Laboratory/internlm2-chat-1_8b'# alpaca_en_path = 'tatsu-lab/alpaca'
alpaca_en_path = '/root/ft/data/personal_assistant.json'# max_length = 2048
max_length = 1024# max_epochs = 3
max_epochs = 1# save_steps = 500
# save_total_limit = 2 # Maximum checkpoints to keep (-1 means unlimited)
save_steps = 300
save_total_limit = 3 # Maximum checkpoints to keep (-1 means unlimited)# evaluation_freq = 500
evaluation_freq = 300# SYSTEM = SYSTEM_TEMPLATE.alpaca
# evaluation_inputs = [
# '请给我介绍五个上海的景点', 'Please tell me five scenic spots in Shanghai'
# ]SYSTEM = ''
evaluation_inputs = ['请你介绍一下你自己', '你是谁', '你是我的小助手吗']# dataset=dict(type=load_dataset, path=alpaca_en_path),
dataset=dict(type=load_dataset, path='json', data_files=dict(train=alpaca_en_path)),# dataset_map_fn=alpaca_map_fn,
dataset_map_fn=openai_map_fn,
模型训练
使用xtuner train指令即可开始训练
我们可以通过添加--work-dir指定特定的文件保存位置,假如不添加的话模型训练的过程文件将默认保存在 ./work_dirs/internlm2_1_8b_qlora_alpaca_e3_copy 的位置
另外,我们使用DeepSpeed优化器加速训练
DeepSpeed是一个深度学习优化库,由微软开发,旨在提高大规模模型训练的效率和速度。它通过几种关键技术来优化训练过程,包括模型分割、梯度累积、以及内存和带宽优化等。DeepSpeed特别适用于需要巨大计算资源的大型模型和数据集。
在DeepSpeed中,zero 代表“ZeRO”(Zero Redundancy Optimizer),是一种旨在降低训练大型模型所需内存占用的优化器。ZeRO 通过优化数据并行训练过程中的内存使用,允许更大的模型和更快的训练速度。ZeRO 分为几个不同的级别,主要包括:
-
deepspeed_zero1:这是ZeRO的基本版本,它优化了模型参数的存储,使得每个GPU只存储一部分参数,从而减少内存的使用。
-
deepspeed_zero2:在deepspeed_zero1的基础上,deepspeed_zero2进一步优化了梯度和优化器状态的存储。它将这些信息也分散到不同的GPU上,进一步降低了单个GPU的内存需求。
-
deepspeed_zero3:这是目前最高级的优化等级,它不仅包括了deepspeed_zero1和deepspeed_zero2的优化,还进一步减少了激活函数的内存占用。这通过在需要时重新计算激活(而不是存储它们)来实现,从而实现了对大型模型极其内存效率的训练。
选择哪种deepspeed类型主要取决于你的具体需求,包括模型的大小、可用的硬件资源(特别是GPU内存)以及训练的效率需求。一般来说:
- 如果你的模型较小,或者内存资源充足,可能不需要使用最高级别的优化。
- 如果你正在尝试训练非常大的模型,或者你的硬件资源有限,使用deepspeed_zero2或deepspeed_zero3可能更合适,因为它们可以显著降低内存占用,允许更大模型的训练。
- 选择时也要考虑到实现的复杂性和运行时的开销,更高级的优化可能需要更复杂的设置,并可能增加一些计算开销。
# 使用 deepspeed 来加速训练
xtuner train /root/ft/config/internlm2_1_8b_qlora_alpaca_e3_copy.py --work-dir /root/ft/train_deepspeed --deepspeed deepspeed_zero2
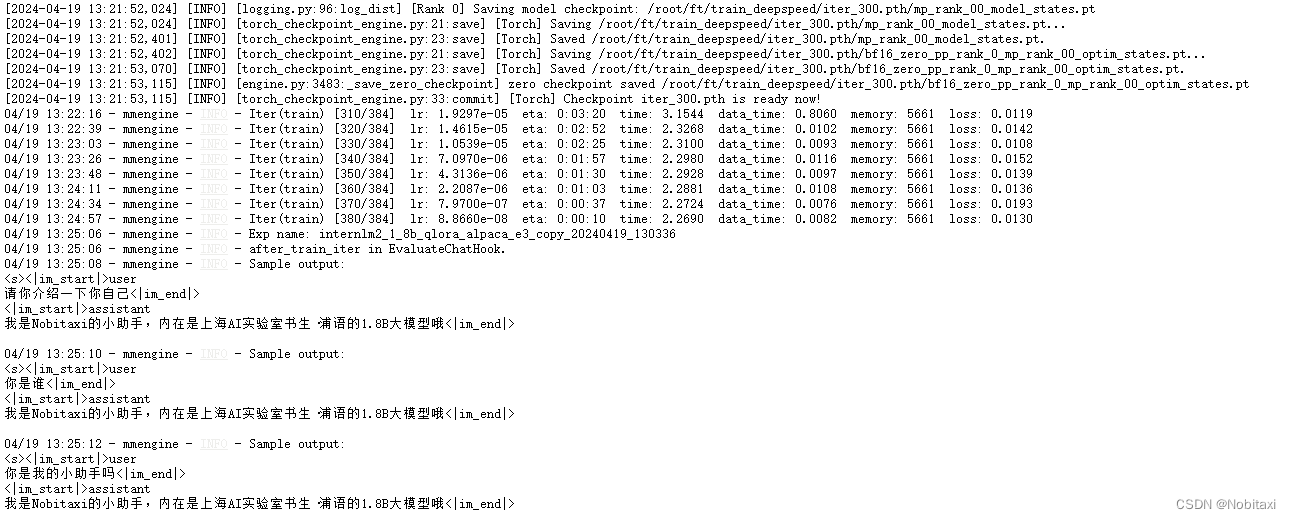
如果我们的模型训练中途中断了,我们可以参考以下方法实现模型续训:
我们也可以通过在原有指令的基础上加上 --resume {checkpoint_path} 来实现模型的继续训练。需要注意的是,这个继续训练得到的权重文件和中断前的完全一致,并不会有任何区别。例如:
# 模型续训
xtuner train /root/ft/config/internlm2_1_8b_qlora_alpaca_e3_copy.py --work-dir /root/ft/train --resume /root/ft/train/iter_600.pth
模型转换、整合、测试及部署
模型转换
模型转换的本质其实就是将原本使用 Pytorch 训练出来的模型权重文件转换为目前通用的 Huggingface 格式文件,那么我们可以通过以下指令来实现一键转换。
# 创建一个保存转换后 Huggingface 格式的文件夹
mkdir -p /root/ft/huggingface# 模型转换
# xtuner convert pth_to_hf ${配置文件地址} ${权重文件地址} ${转换后模型保存地址}
xtuner convert pth_to_hf /root/ft/config/internlm2_1_8b_qlora_alpaca_e3_copy.py /root/ft/train_deepspeed/iter_384.pth /root/ft/huggingface
转换完成后,可以看到模型被转换为 Huggingface 中常用的 .bin 格式文件,这就代表着文件成功被转化为 Huggingface 格式了。

此时,huggingface 文件夹即为我们平时所理解的所谓 “LoRA 模型文件”,可以简单理解:LoRA模型文件=Adapter
除此之外,我们其实还可以在转换的指令中添加几个额外的参数,包括以下两个:
| 参数名 | 解释 |
|---|---|
| –fp32 | 代表以fp32的精度开启,假如不输入则默认为fp16 |
| –max-shard-size {GB} | 代表每个权重文件最大的大小(默认为2GB) |
模型转换
于 LoRA 或者 QLoRA 微调出来的模型其实并不是一个完整的模型,而是一个额外的层(adapter)。那么训练完的这个层最终还是要与原模型进行组合才能被正常的使用。
而对于全量微调的模型(full)其实是不需要进行整合这一步的,因为全量微调修改的是原模型的权重而非微调一个新的 adapter ,因此是不需要进行模型整合的。
在 XTuner 中也是提供了一键整合的指令,但是在使用前我们需要准备好三个地址,包括原模型的地址、训练好的 adapter 层的地址(转为 Huggingface 格式后保存的部分)以及最终保存的地址。
# 创建一个名为 final_model 的文件夹存储整合后的模型文件
mkdir -p /root/ft/final_model# 解决一下线程冲突的 Bug
export MKL_SERVICE_FORCE_INTEL=1# 进行模型整合
# xtuner convert merge ${NAME_OR_PATH_TO_LLM} ${NAME_OR_PATH_TO_ADAPTER} ${SAVE_PATH}
xtuner convert merge /root/models/Shanghai_AI_Laboratory/internlm2-chat-1_8b /root/ft/huggingface /root/ft/final_model
那除了以上的三个基本参数以外,其实在模型整合这一步还是其他很多的可选参数,包括:
| 参数名 | 解释 |
|---|---|
| –max-shard-size {GB} | 代表每个权重文件最大的大小(默认为2GB) |
| –device {device_name} | 这里指的就是device的名称,可选择的有cuda、cpu和auto,默认为cuda即使用gpu进行运算 |
| –is-clip | 这个参数主要用于确定模型是不是CLIP模型,假如是的话就要加上,不是就不需要添加 |
CLIP(Contrastive Language–Image Pre-training)模型是 OpenAI 开发的一种预训练模型,它能够理解图像和描述它们的文本之间的关系。CLIP 通过在大规模数据集上学习图像和对应文本之间的对应关系,从而实现了对图像内容的理解和分类,甚至能够根据文本提示生成图像。 在模型整合完成后,我们就可以看到 final_model 文件夹里生成了和原模型文件夹非常近似的内容,包括了分词器、权重文件、配置信息等等。当我们整合完成后,我们就能够正常的调用这个模型进行对话测试了。
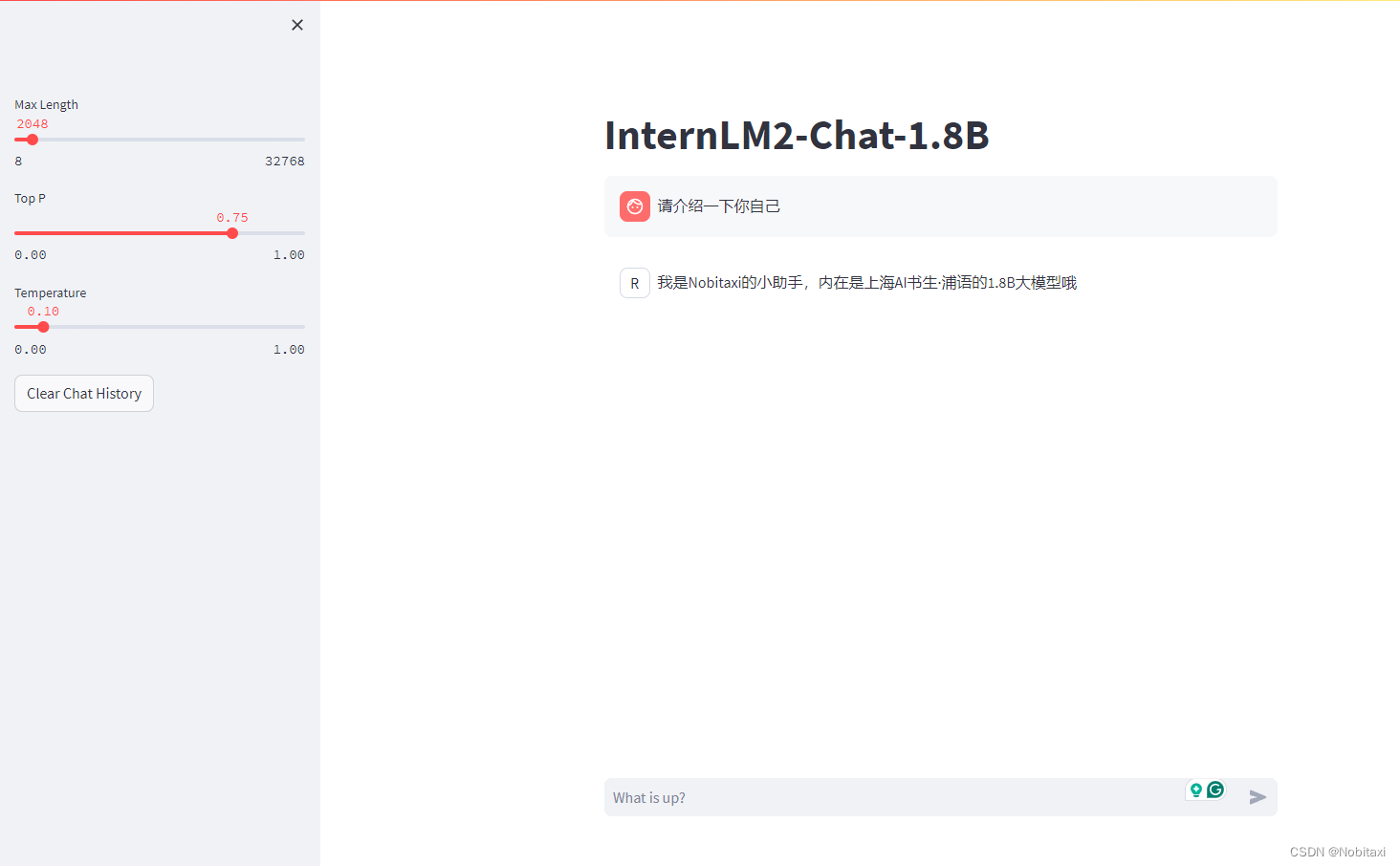
对话测试
在 XTuner 中也直接的提供了一套基于 transformers 的对话代码,让我们可以直接在终端与 Huggingface 格式的模型进行对话操作。我们只需要准备我们刚刚转换好的模型路径并选择对应的提示词模版(prompt-template)即可进行对话。假如 prompt-template 选择有误,很有可能导致模型无法正确的进行回复。
想要了解具体模型的 prompt-template 或者 XTuner 里支持的 prompt-tempolate,可以到 XTuner 源码中的 xtuner/utils/templates.py 这个文件中进行查找。
# 与模型进行对话
xtuner chat /root/ft/final_model --prompt-template internlm2_chat

那对于 xtuner chat 这个指令而言,还有很多其他的参数可以进行设置的,包括:
| 参数名 | 解释 |
|---|---|
| –system | 指定SYSTEM文本,用于在对话中插入特定的系统级信息 |
| –system-template | 指定SYSTEM模板,用于自定义系统信息的模板 |
| –bits | 指定LLM运行时使用的位数,决定了处理数据时的精度 |
| –bot-name | 设置bot的名称,用于在对话或其他交互中识别bot |
| –with-plugins | 指定在运行时要使用的插件列表,用于扩展或增强功能 |
| –no-streamer | 关闭流式传输模式,对于需要一次性处理全部数据的场景 |
| –lagent | 启用lagent,用于特定的运行时环境或优化 |
| –command-stop-word | 设置命令的停止词,当遇到这些词时停止解析命令 |
| –answer-stop-word | 设置回答的停止词,当生成回答时遇到这些词则停止 |
| –offload-folder | 指定存放模型权重的文件夹,用于加载或卸载模型权重 |
| –max-new-tokens | 设置生成文本时允许的最大token数量,控制输出长度 |
| –temperature | 设置生成文本的温度值,较高的值会使生成的文本更多样,较低的值会使文本更确定 |
| –top-k | 设置保留用于顶k筛选的最高概率词汇标记数,影响生成文本的多样性 |
| –top-p | 设置累计概率阈值,仅保留概率累加高于top-p的最小标记集,影响生成文本的连贯性 |
| –seed | 设置随机种子,用于生成可重现的文本内容 |
除了这些参数以外其实还有一个非常重要的参数就是 --adapter ,这个参数主要的作用就是可以在转化后的 adapter 层与原模型整合之前来对该层进行测试。使用这个额外的参数对话的模型和整合后的模型几乎没有什么太多的区别,因此我们可以通过测试不同的权重文件生成的 adapter 来找到最优的 adapter 进行最终的模型整合工作。
Web demo部署
首先需要先下载网页端 web demo 所需要的依赖
pip install streamlit==1.24.0
下载 InternLM 项目代码
# 创建存放 InternLM 文件的代码
mkdir -p /root/ft/web_demo && cd /root/ft/web_demo# 拉取 InternLM 源文件
git clone https://github.com/InternLM/InternLM.git# 进入该库中
cd /root/ft/web_demo/InternLM
将 /root/ft/web_demo/InternLM/chat/web_demo.py 中的内容替换为以下的代码(与源代码相比,此处修改了模型路径和分词器路径,并且也删除了 avatar 及 system_prompt 部分的内容,同时与 cli 中的超参数进行了对齐)。
@dataclass
class GenerationConfig:# this config is used for chat to provide more diversity# max_length: int = 32768# top_p: float = 0.8# temperature: float = 0.8# do_sample: bool = True# repetition_penalty: float = 1.005max_length: int = 2048top_p: float = 0.75temperature: float = 0.1do_sample: bool = Truerepetition_penalty: float = 1.000@st.cache_resource
def load_model():model = (AutoModelForCausalLM.from_pretrained('/root/ft/final_model',trust_remote_code=True).to(torch.bfloat16).cuda())tokenizer = AutoTokenizer.from_pretrained('/root/ft/final_model',trust_remote_code=True)return model, tokenizer# meta_instruction = ('You are InternLM (书生·浦语), a helpful, honest, '# 'and harmless AI assistant developed by Shanghai '# 'AI Laboratory (上海人工智能实验室).')meta_instruction = ('')
这篇关于书生·浦语大模型实战营(第二期):XTuner 微调 LLM的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!





