本文主要是介绍AI论文速读 | 2024[VLDB]TFB:全面与公正的时间序列预测方法基准测试研究,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
论文标题:TFB: Towards Comprehensive and Fair Benchmarking of Time Series Forecasting Methods
作者:Xiangfei Qiu ; Jilin Hu(胡吉林) ; Lekui Zhou ; Xingjian Wu ; Junyang Du ; Buang Zhang ; Chenjuan Guo(郭晨娟) ; Aoying Zhou(周傲英) ; Christian S. Jensen ; Zhenli Sheng ; Bin Yang(杨彬)
机构:华东师范大学,华为云,奥尔堡大学(AAU)
关键词:时间序列预测, 基准测试, 领域覆盖, 评估策略, 公平比较, 自动化流程.
链接:https://arxiv.org/abs/2403.20150
Cool Paper:https://papers.cool/arxiv/2403.20150
代码:https://github.com/decisionintelligence/TFB
TL; DR:该论文提出了TFB(时间序列预测基准测试),这是一个新颖的自动化基准测试框架,旨在通过包含来自十个不同领域的数据集,并提供一个灵活、可扩展且一致的评估流程,使得对包括统计学习、机器学习和深度学习在内的多种时间序列预测方法进行全面且无偏见的评估成为可能。

这篇应该是ED&B(Experiment, Analysis and Benchmark)Track的论文
🌟【紧跟前沿】“时空探索之旅”与你一起探索时空奥秘!🚀
欢迎大家关注时空探索之旅
摘要
时间序列在经济、交通、健康和能源等不同领域生成,其中未来值的预测具有许多重要的应用。 毫不奇怪,人们提出了许多预测方法。 为了确保进展,必须能够以全面、可靠的方式对这些方法进行实证研究和比较。 为了实现这一目标,本文提出了 TFB,一种时间序列预测 (TSF) 方法的自动化基准。 TFB 通过解决与数据集、比较方法和评估流程相关的缺点来推进最先进的技术,即:1)数据域覆盖范围不足,2)对传统方法的刻板印象偏见,以及 3)不一致且不灵活的流程。 为了实现更好的领域覆盖,包含来自 10 个不同领域的数据集:交通、电力、能源、环境、自然、经济、股票市场、银行、健康和网络。 还提供时间序列特征,以确保所选数据集的全面性。 为了消除对某些方法的偏见,提供了多种方法,包括统计学习、机器学习和深度学习方法,并且还支持多种评估策略和指标,以确保对不同方法进行更全面的评估。 为了支持将不同方法集成到基准测试中并实现公平比较,TFB 具有灵活且可扩展的流程,可以消除偏差。 接下来,使用 TFB 对 8,068 个单变量时间序列的 21 种单变量时间序列预测 (UTSF) 方法和 25 个数据集的14 种多元时间序列预测 (MTSF) 方法进行全面评估。
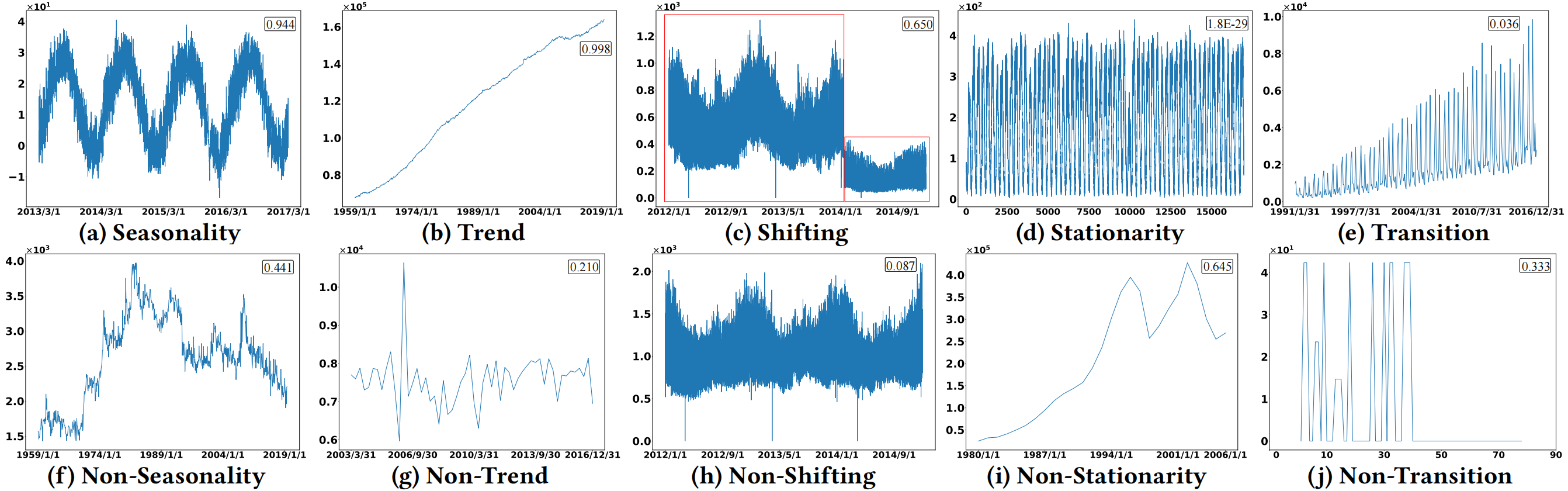
- 季节性(Seasonality):时间序列在特定时间间隔内重复变化的现象。
- 趋势(Trend):时间序列长期变化或模式的总体方向。
- 移动(漂移)(Shifting):时间序列的概率分布随时间变化的现象。
- 平稳性(Stationarity):时间序列的均值和方差对于所有观测值都是恒定的,协方差仅依赖于观测值之间的距离。
- 转换(Transition):时间序列中趋势、周期性或季节性和趋势同时出现的清晰表现。
- 相关性(Correlation):多变量时间序列中不同变量可能共享的共同趋势或模式,表明它们受到相似因素的影响或存在某种潜在关系(后文有体现)。
Q: 这篇论文试图解决什么问题?
A: 这篇论文提出了一个名为TFB(Time Series Forecasting Benchmark)的自动化基准测试,旨在全面和公正地评估时间序列预测(TSF)方法。论文试图解决的问题包括:
- 数据集覆盖不足:现有的时间序列预测方法评估通常只覆盖有限的领域,无法全面反映方法在不同领域的表现。
- 对传统方法的偏见:早期的评估往往忽略了传统方法,如统计学习方法,而只关注基于机器学习和深度学习的方法。
- 评估流程不一致和缺乏灵活性:不同的评估基准使用不同的实验设置,如数据划分、归一化方法选择和超参数设置,这使得跨基准的比较变得困难。
为了解决这些问题,TFB提出了以下解决方案:
- 包含来自10个不同领域的数据集,以提高领域覆盖率。
- 支持多种评估策略和指标,涵盖统计学习、机器学习和深度学习方法。
- 提供灵活且可扩展的评估流程,确保在相同设置下对不同方法进行评估,以提高比较的公平性。
总的来说,TFB旨在为时间序列预测方法提供一个全面、可靠和用户友好的评估平台,以促进新方法的发展和现有方法的改进。
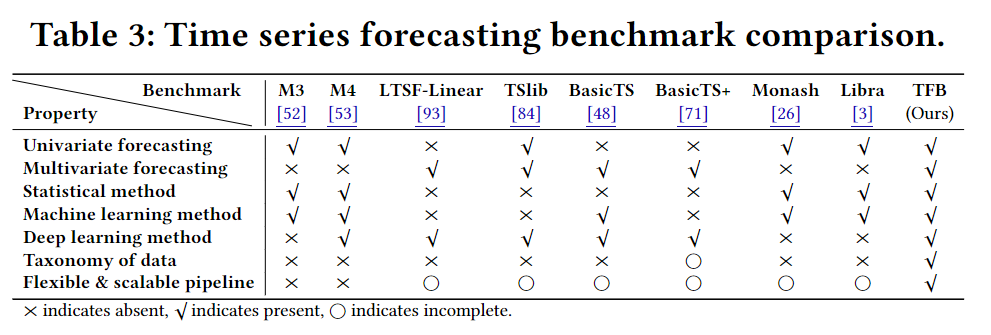
Q: 有哪些相关研究?
A: 这篇论文在“相关工作”部分提到了以下几类相关研究:
-
时间序列预测方法(Time series forecasting:)
-
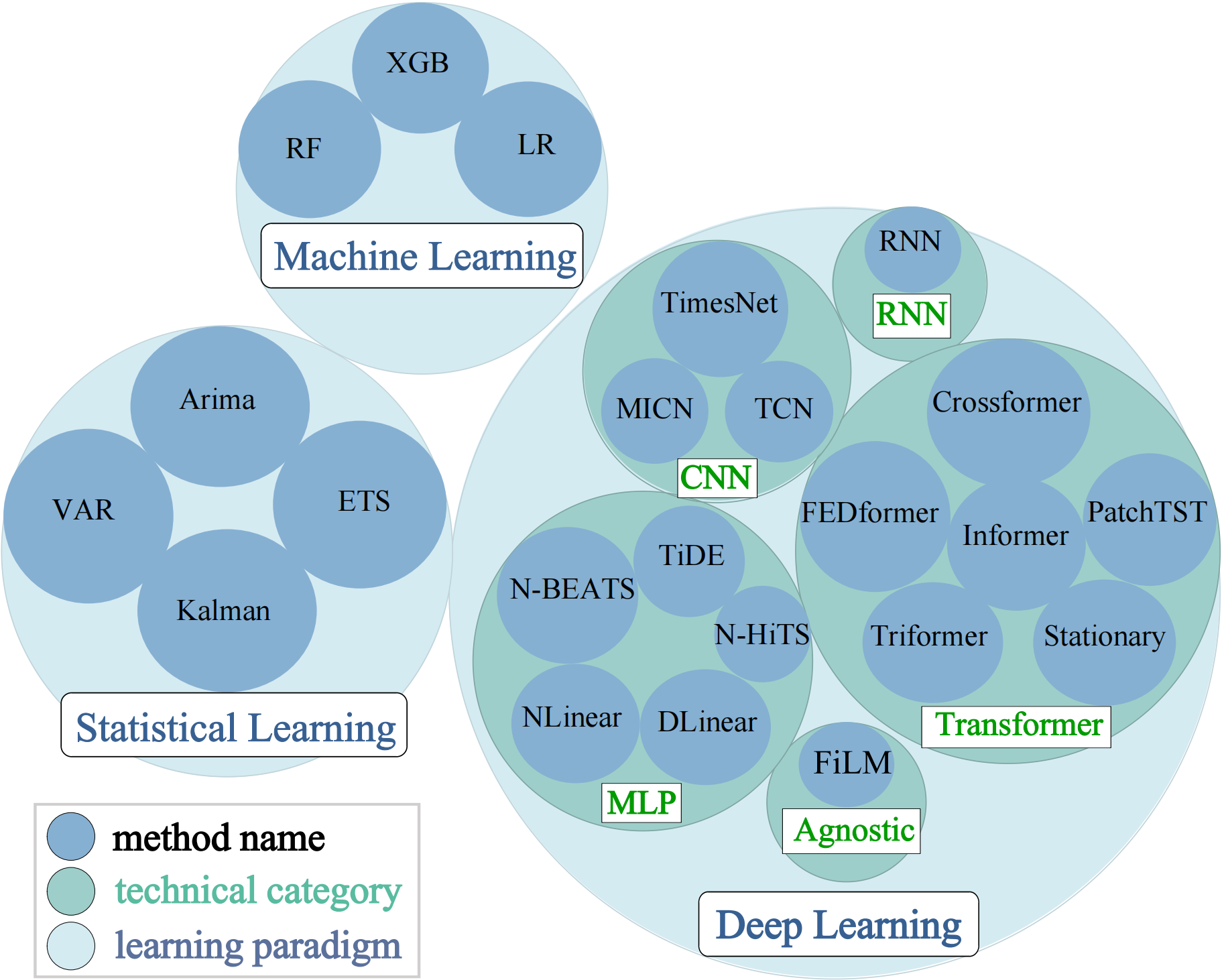
- 统计学习方法:如ARIMA, ETS, Theta, VAR, 和 Kalman Filter (KF) 。
- 机器学习方法:如XGBoost, Gradient Boosting Regression Trees (GBRT), Random Forests 和 LightGBM 。
- 深度学习方法:如TCN , DeepAR , Transformer架构(包括Informer , FEDformer, Autoformer, Triformer, 和 PatchTST)以及基于MLP的模型(如N-HiTS , N-BEATS , NLinear, 和 DLinear )。
-
时间序列预测基准(Benchmarks:)
-
- Libra, BasicTS, BasicTS+ , Monash, M3, M4, LTSF-Linear, 和 TSlib 。
这些相关研究表明,虽然已经有许多方法和基准用于时间序列预测,但它们在方法多样性、数据集覆盖、以及评估流程的一致性和灵活性方面存在不足。TFB旨在通过提供一个全面的、支持多种方法和评估策略的基准来解决这些问题,从而推动时间序列预测领域的发展。
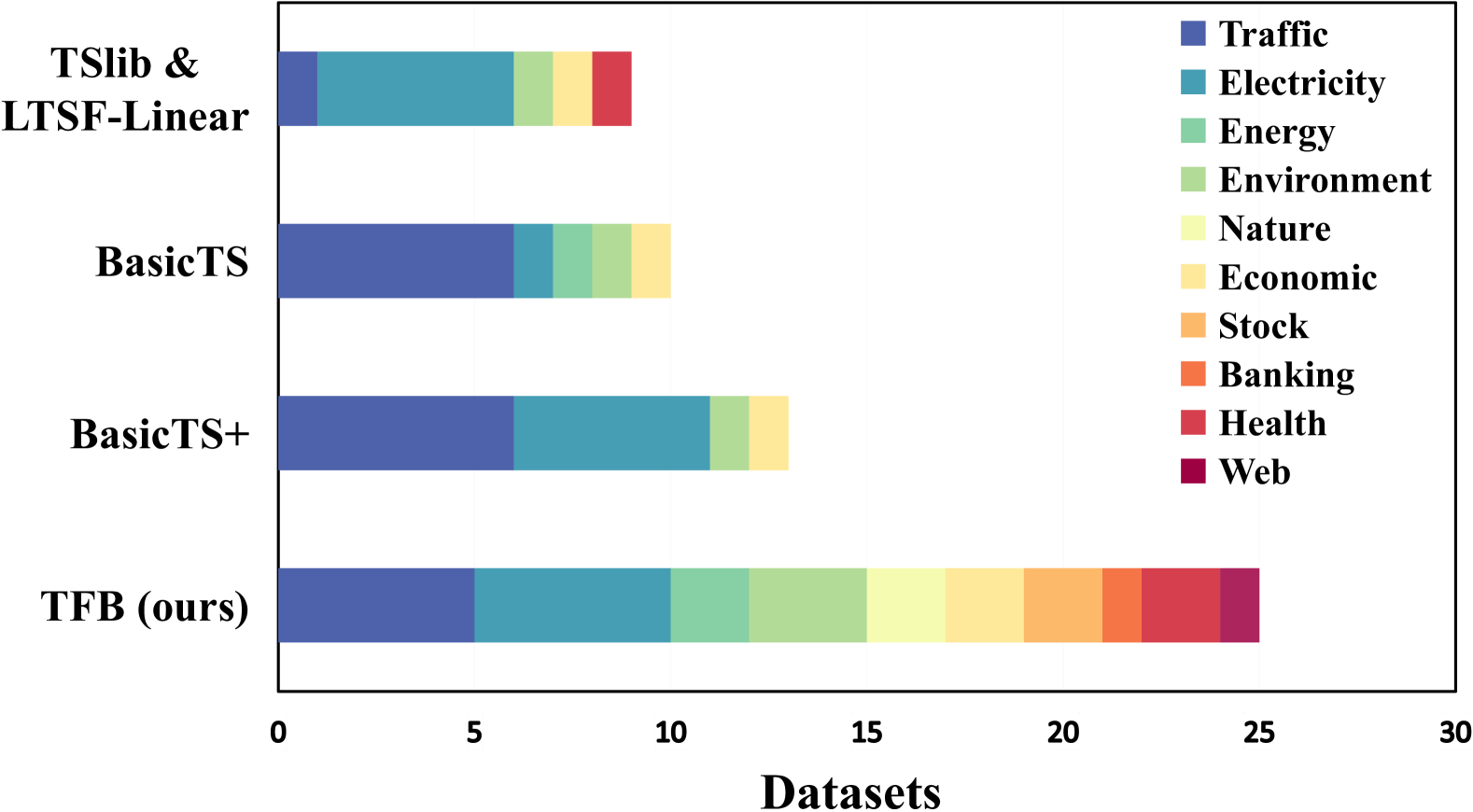
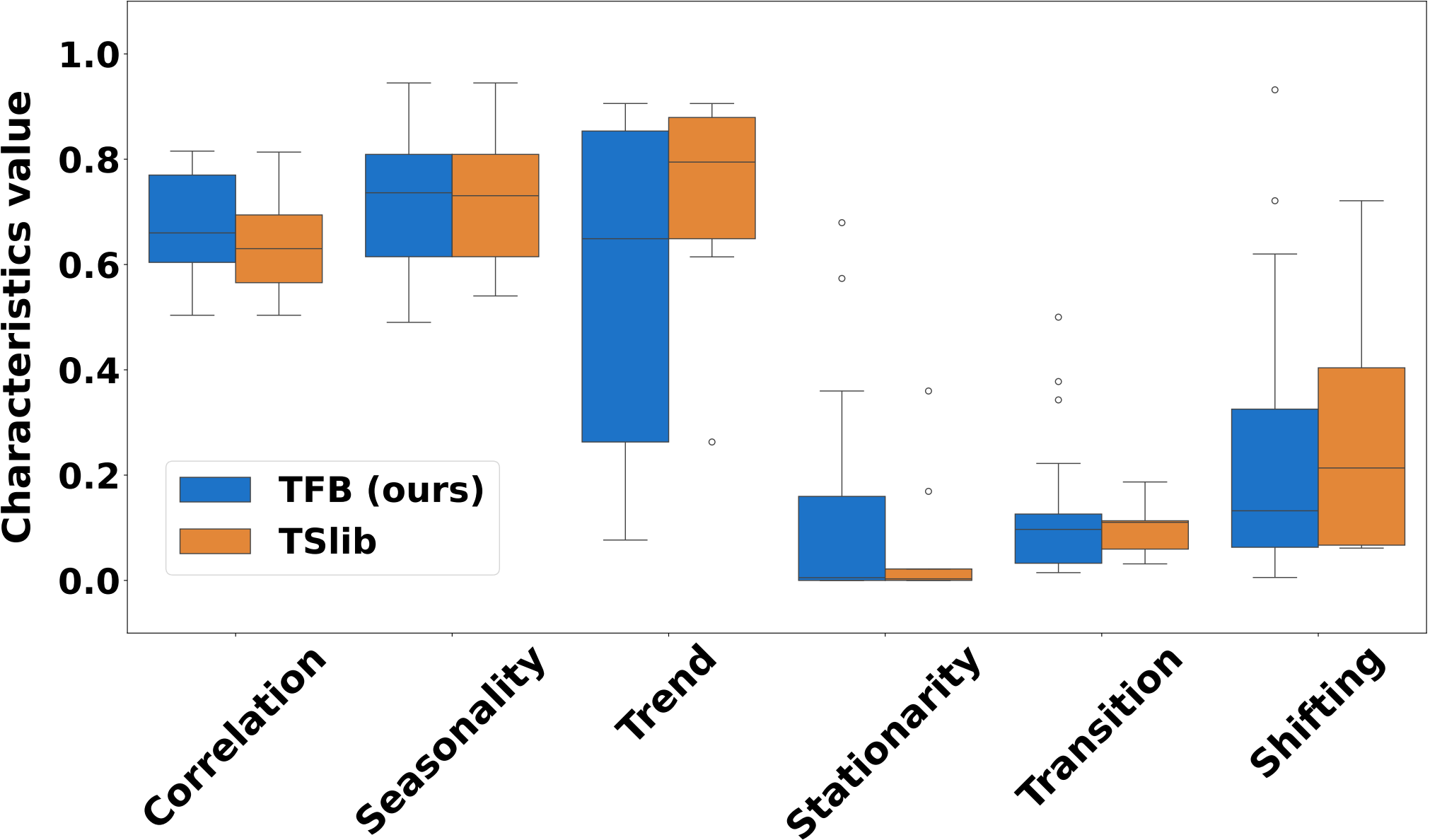
Q: 论文如何解决这个问题?
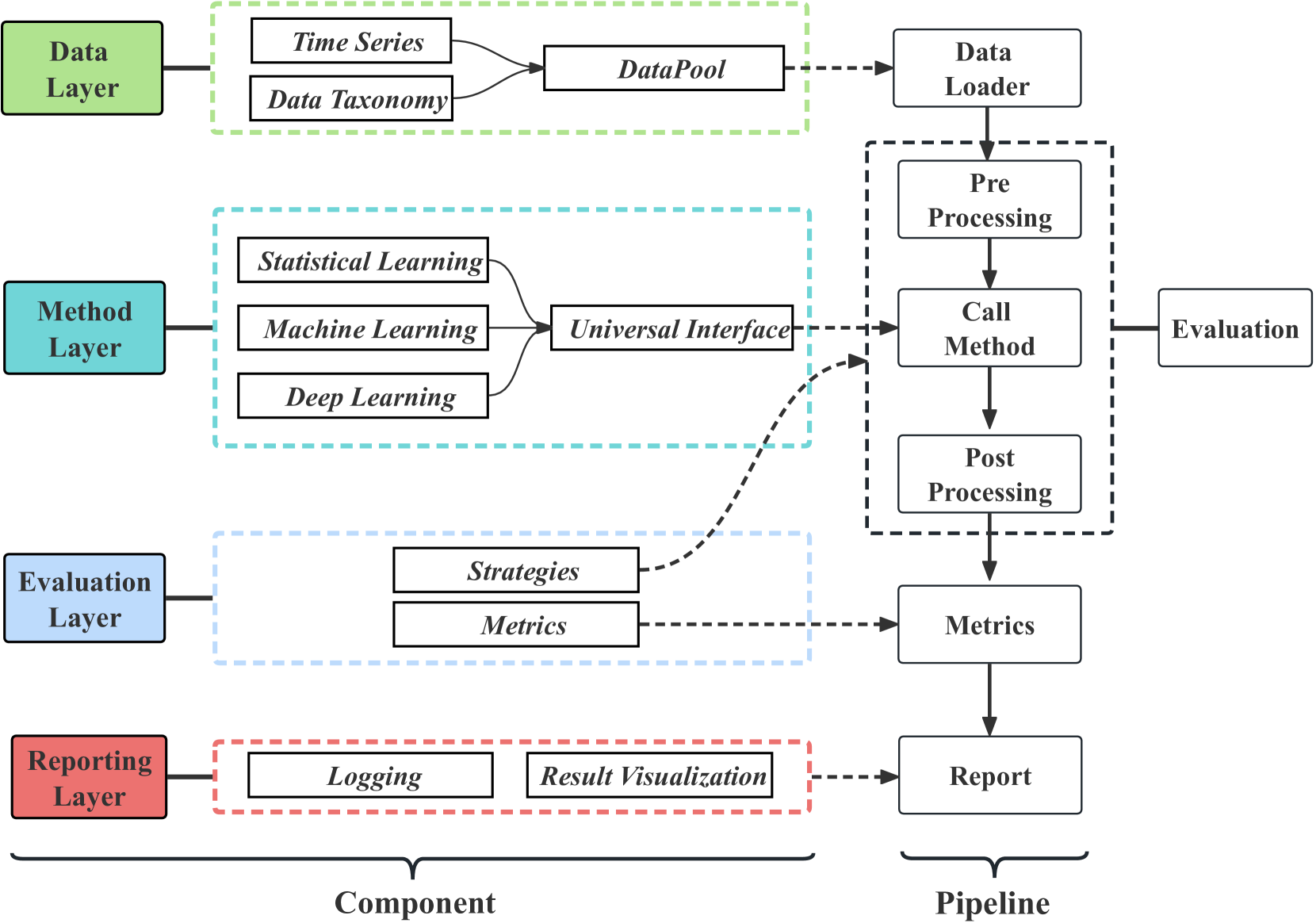
A: 为了解决上述提到的问题,论文提出了TFB(Time Series Forecasting Benchmark),一个全面的、自动化的时间序列预测方法评估基准。具体的解决方案包括:
- 数据集的全面覆盖:
- 包含来自10个不同领域的数据集,以提高领域覆盖率。
- 对时间序列数据进行特征化分析,确保所选数据集在不同特征上具有广泛的分布。
- 方法多样性和评估策略的扩展:
- 支持包括统计学习、机器学习和深度学习在内的多种时间序列预测方法。
- 提供多种评估策略和指标,以全面评估不同方法的性能。
- 灵活且可扩展的评估流程:
- 设计了一个统一的评估流程,包括数据层、方法层、评估层和报告层。
- 引入了标准化的数据集处理、划分和归一化步骤。
- 提供了可定制的配置文件,以便用户根据需要调整评估设置。
- 消除偏见和提高评估公平性:
- 通过统一的实验设置和评估策略,确保所有方法在相同的条件下进行评估。
- 避免了对任何特定类别方法的偏见,如传统方法或最新方法。
- 自动化和简化评估过程:
- 提供了一个端到端的自动化评估流程,简化了研究人员对时间序列预测方法的评估过程。
- 通过GitHub上的代码和数据集的公开,促进了社区的验证和使用。
通过这些解决方案,TFB旨在为时间序列预测研究者提供一个可靠、全面和用户友好的评估平台,从而推动该领域的进一步发展。
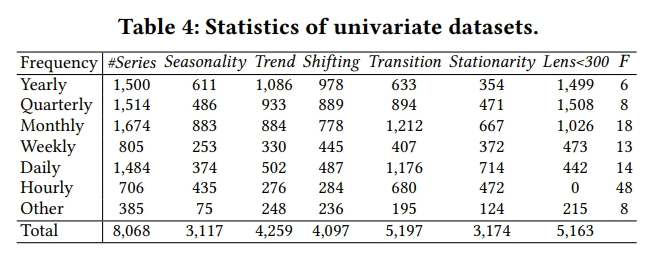

(这个图没有完全看懂,就翻译一下)
单变量时间序列,由于时间序列有不同的长度,首先将时间序列表示为由五个特征指标组成的向量:趋势、季节性、平稳性、漂移和转换。为了便于可视化,采用PCA(主成分分析)降维后的密度分析,观察到 TFB 和 M4 覆盖了最多的单元格,而所有其他基准均小于 TFB。 这强调了TFB数据集在特征分布多样性方面的覆盖范围。 此外,与 M4 相比,TFB的数据集涵盖了更广泛的领域。 此外,注意到 M4 的样本量要大得多,总计 100,000 个,而TFB的数据集仅包含 8,068 个时间序列。
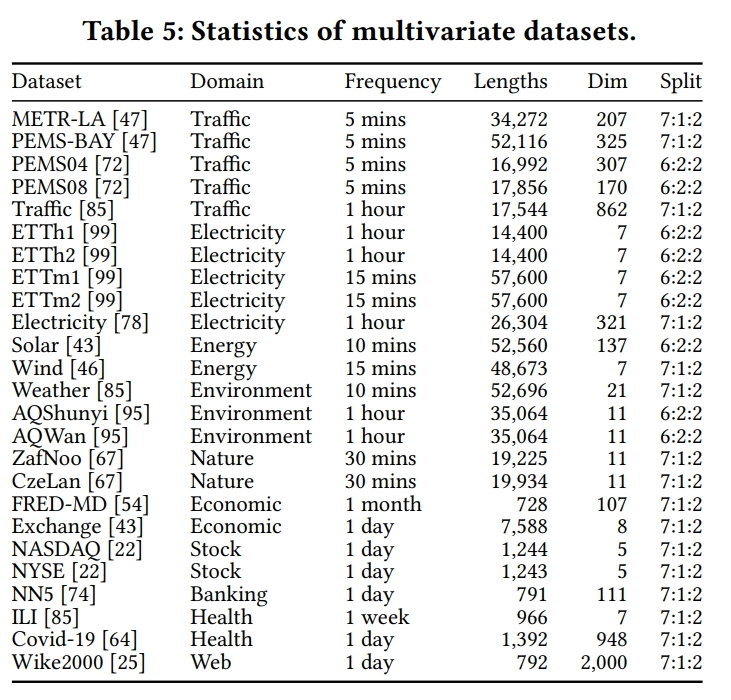
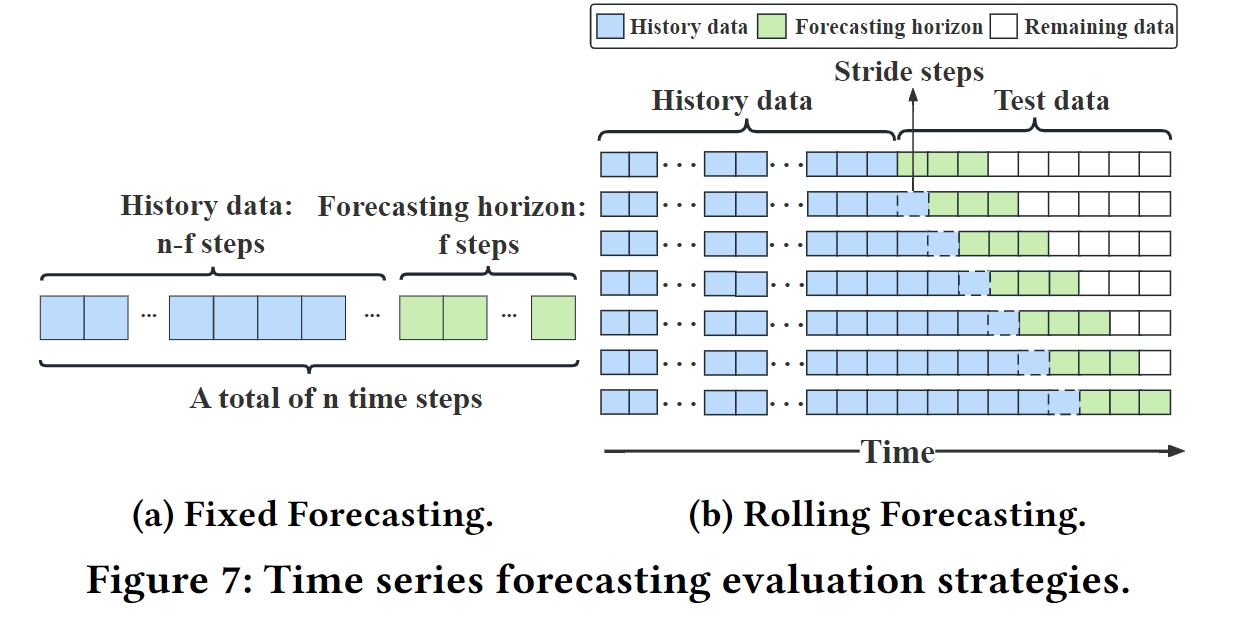
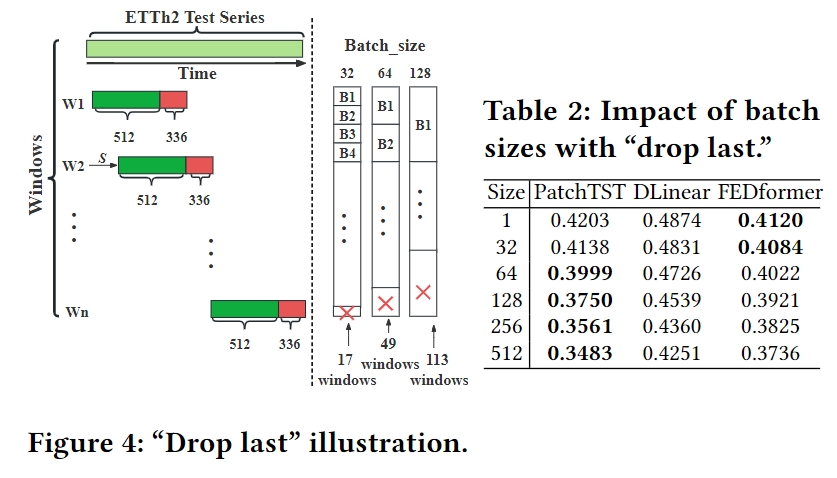
关于“Drop last”的讨论:
“Drop last”是指在时间序列预测的测试阶段中,如果测试数据的最后一个批次(batch)的样本数量少于设定的批次大小(batch size),则通常会选择丢弃这个不完整的批次。这种做法是为了在测试过程中保持数据的一致性和加速计算。
然而,论文指出这种做法可能会导致不公平的比较。因为如果不同的方法在处理最后一个批次时采用不同的策略,比如一些方法丢弃了最后一个批次而另一些方法则没有,这可能会导致评估结果的偏差。
为了解决这个问题,论文提出了一种改进的评估流程,即在测试时不丢弃最后一个批次,而是确保所有方法在相同的策略下进行评估。这可以通过调整批次大小或采用其他方法来实现,以确保所有数据都被公平地考虑在内。
论文中通过实验表明,改变批次大小会影响方法的性能,因此建议在评估时间序列预测方法时,应该采用一致的批次处理策略,避免因“Drop last”操作而导致的潜在偏见。这种设计有助于提高评估的一致性和公平性,从而得到更准确的方法性能比较结果。
Q: 论文做了哪些实验?
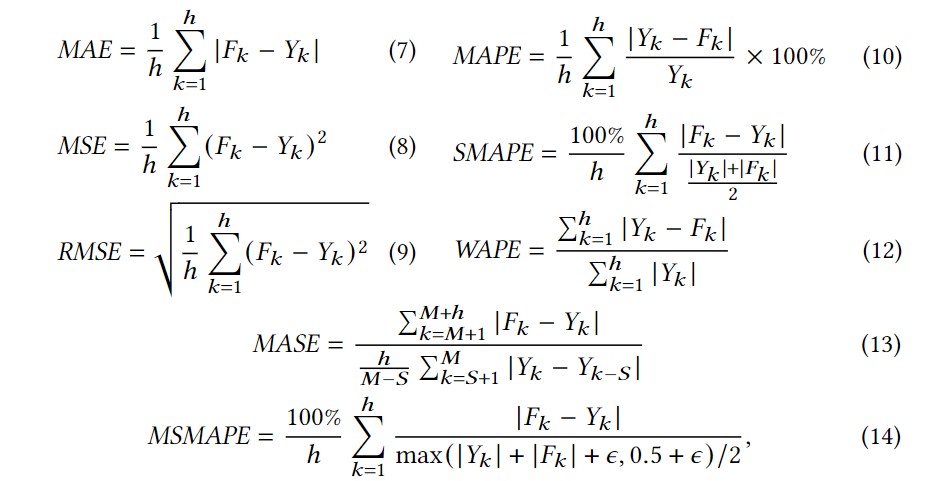
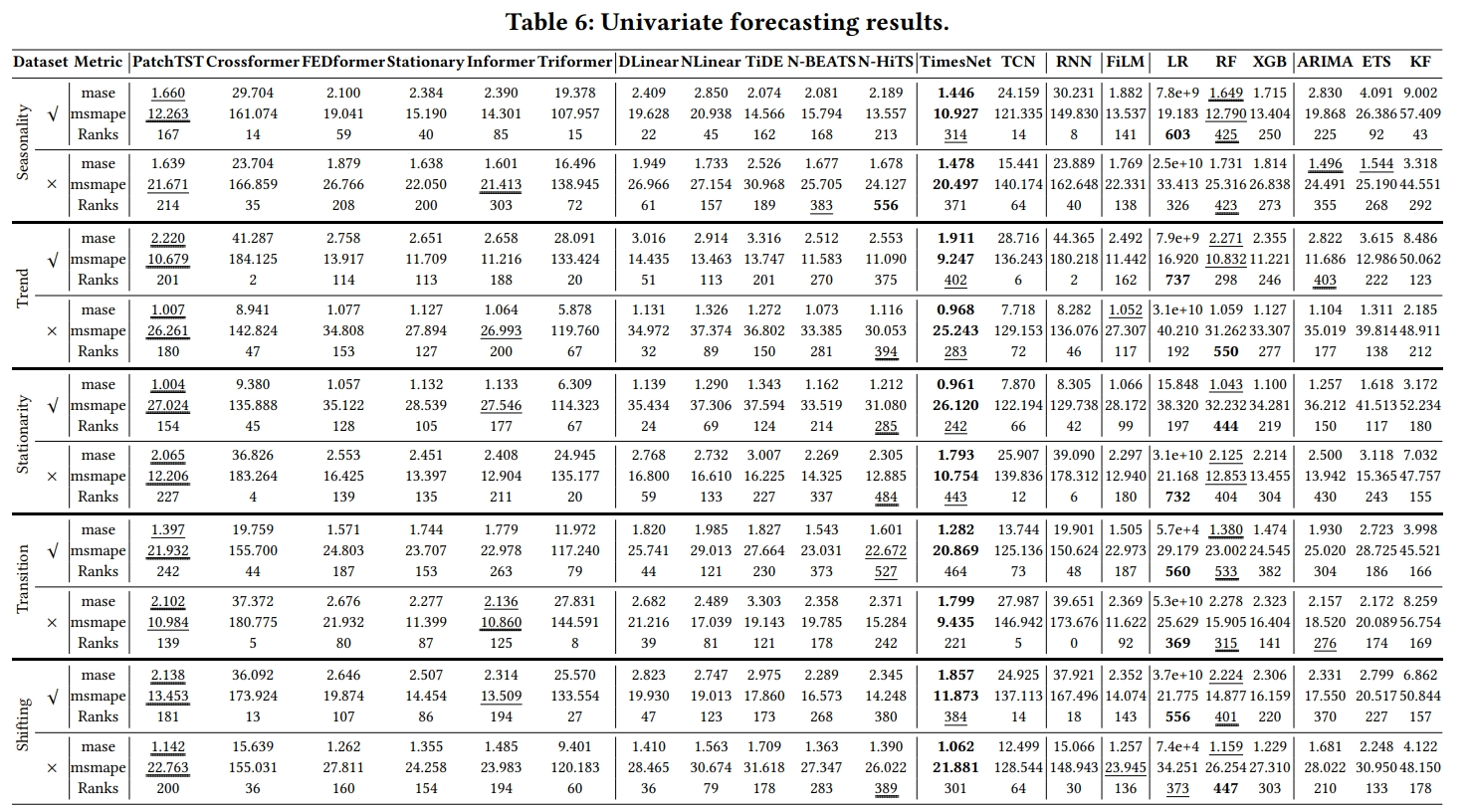
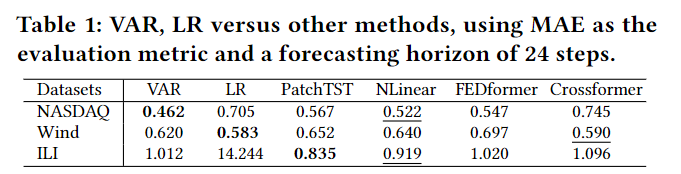
Ranks表示MSMAPE在该数据集上有多少次取得最佳性能
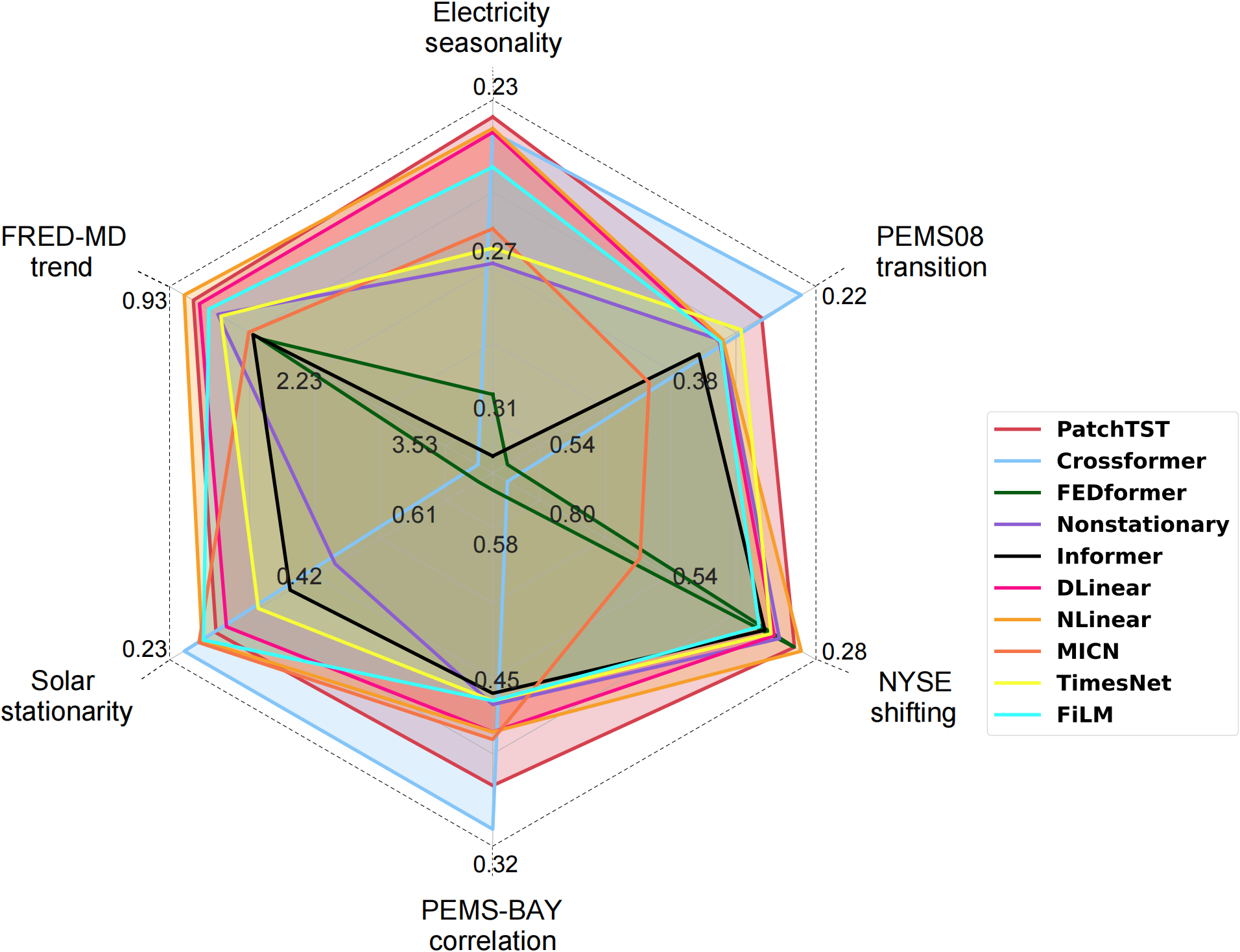
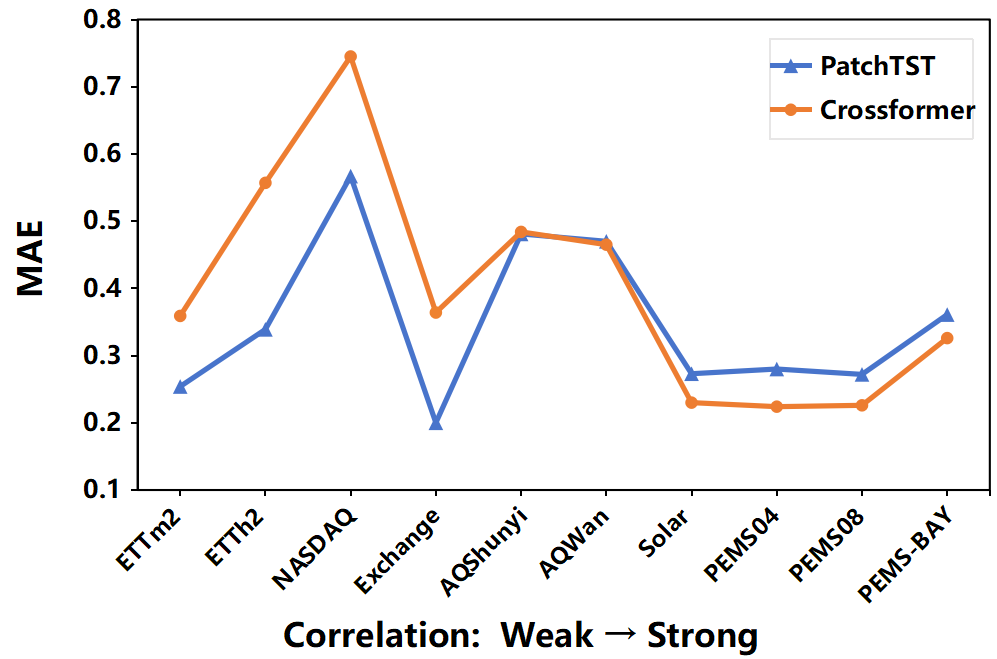
通道独立(CI) VS 通道依赖(CD)
渠道独立性与渠道依赖性。 在多元数据集中,变量有时被称为通道。 为了研究多变量时间序列中通道依赖性的影响,在十个数据集上比较 PatchTST(CI方法) 和 Crossformer(CD方法),依赖性从弱到强。。观察到,随着数据集中相关性的增加,Crossformer 的性能逐渐超过 PatchTST,这表明当相关性很强时最好考虑通道依赖性。但是, 当变量之间相关性不明显时,不考虑通道依赖性的PatchTST更好。
因此深入探索通道依赖性,在设计新方法和改良现有方法是值得思考的问题。
比如之前介绍过的CCM:
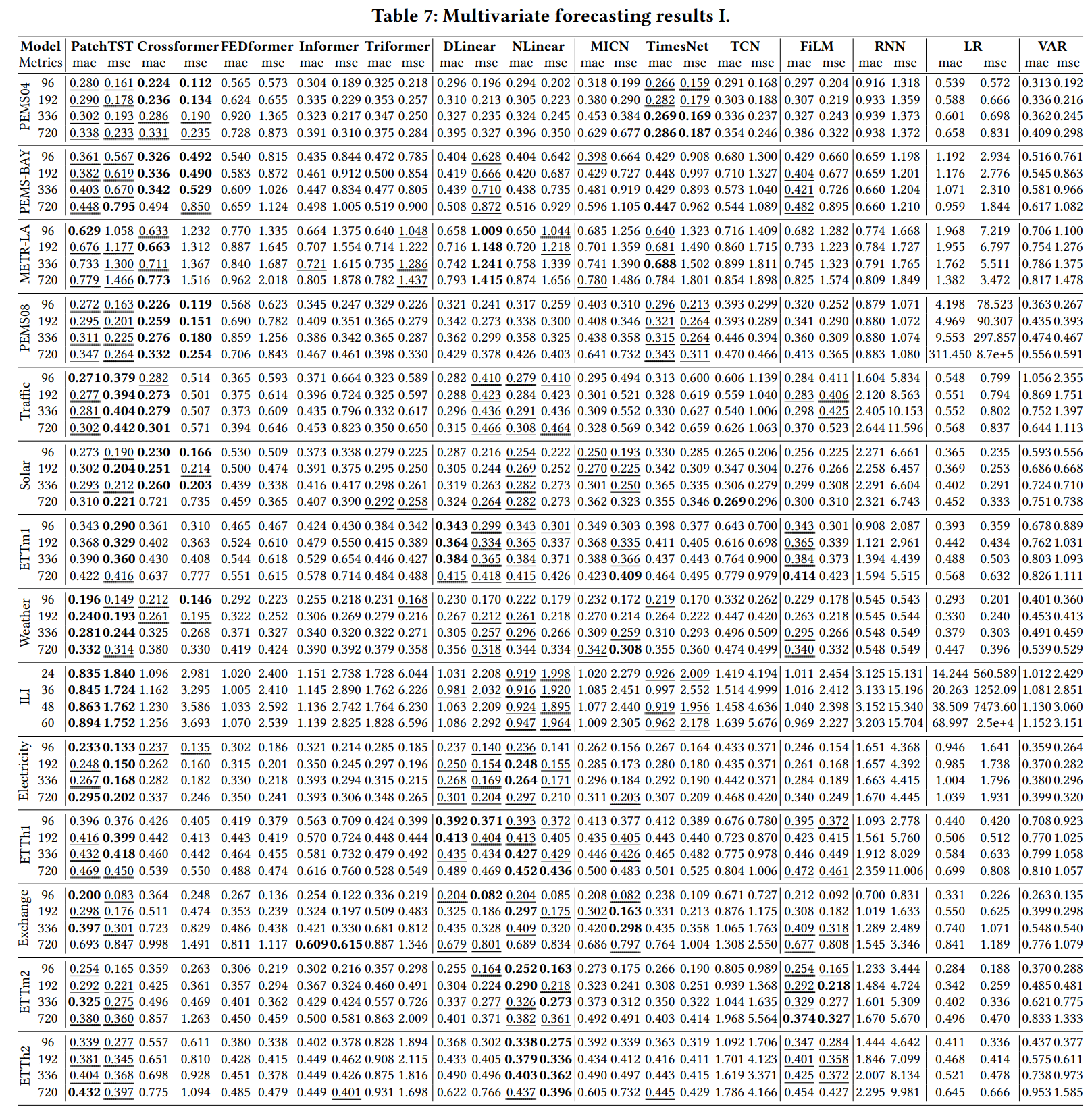
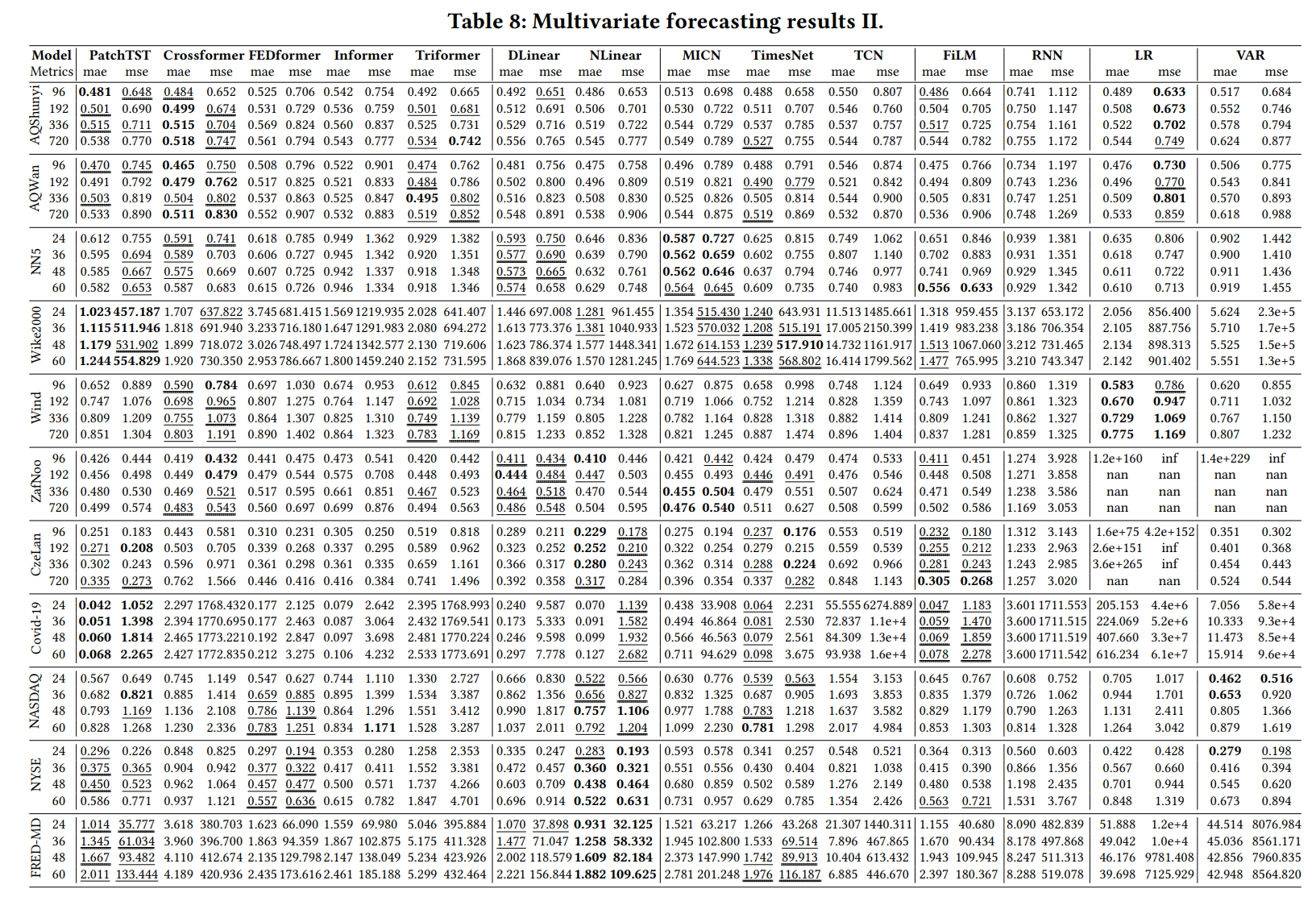
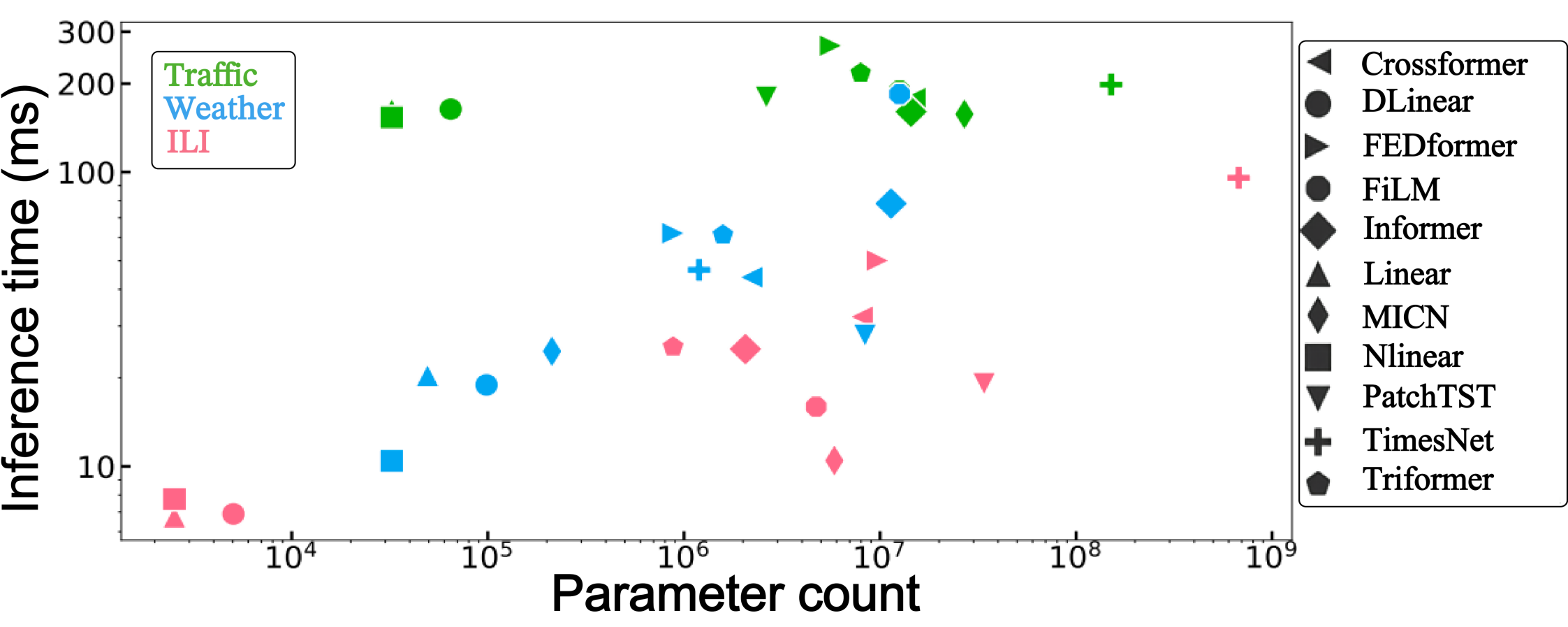
A: 论文中进行了以下实验来评估和验证TFB基准测试的有效性和实用性:
- 实验设置:
- 使用了TFB中包含的25个多变量数据集和8,068个单变量时间序列数据集。
- 包含了22种不同的时间序列预测方法,涵盖统计学习、机器学习和深度学习三大类。
- 对每种方法进行了全面的超参数选择,以确保其性能接近或超过原始论文中报告的结果。
- 单变量时间序列预测:
- 对14种单变量时间序列预测方法在8,068个单变量时间序列上进行了评估。
- 使用了MASE(Mean Absolute Scaled Error)和MSMAPE(Mean Symmetric Absolute Percentage Error)等指标来衡量预测性能。
- 分析了不同方法在具有不同特征(如季节性、趋势、平稳性等)的时间序列上的表现。
- 多变量时间序列预测:
- 对14种多变量时间序列预测方法在25个数据集上进行了评估。
- 采用了MAE(Mean Absolute Error)和MSE(Mean Squared Error)等指标,并针对不同的预测范围进行了测试。
- 比较了不同方法在数据集上的表现,并探讨了它们在处理多变量时间序列时的优缺点。
- 方法性能分析:
- 根据实验结果,总结了不同方法在各种数据特征上的表现和排名。
- 讨论了基于Transformer的方法、线性方法以及考虑通道依赖性的方法在不同场景下的性能差异。
- 提供了关于如何选择适合特定数据集和场景的预测方法的见解。
- 基准测试的可用性和灵活性:
- 展示了TFB如何简化时间序列预测方法的评估过程,并提供了可复现的实验设置。
- 通过公开代码和数据集,允许社区成员验证实验结果并基于TFB进行进一步的研究。
这些实验不仅验证了TFB作为一个全面和公正的评估工具的有效性,而且为时间序列预测领域的研究人员提供了有价值的见解和建议。通过这些实验,研究人员可以更好地理解和比较不同方法的性能,从而为特定应用场景选择或设计最合适的预测模型。
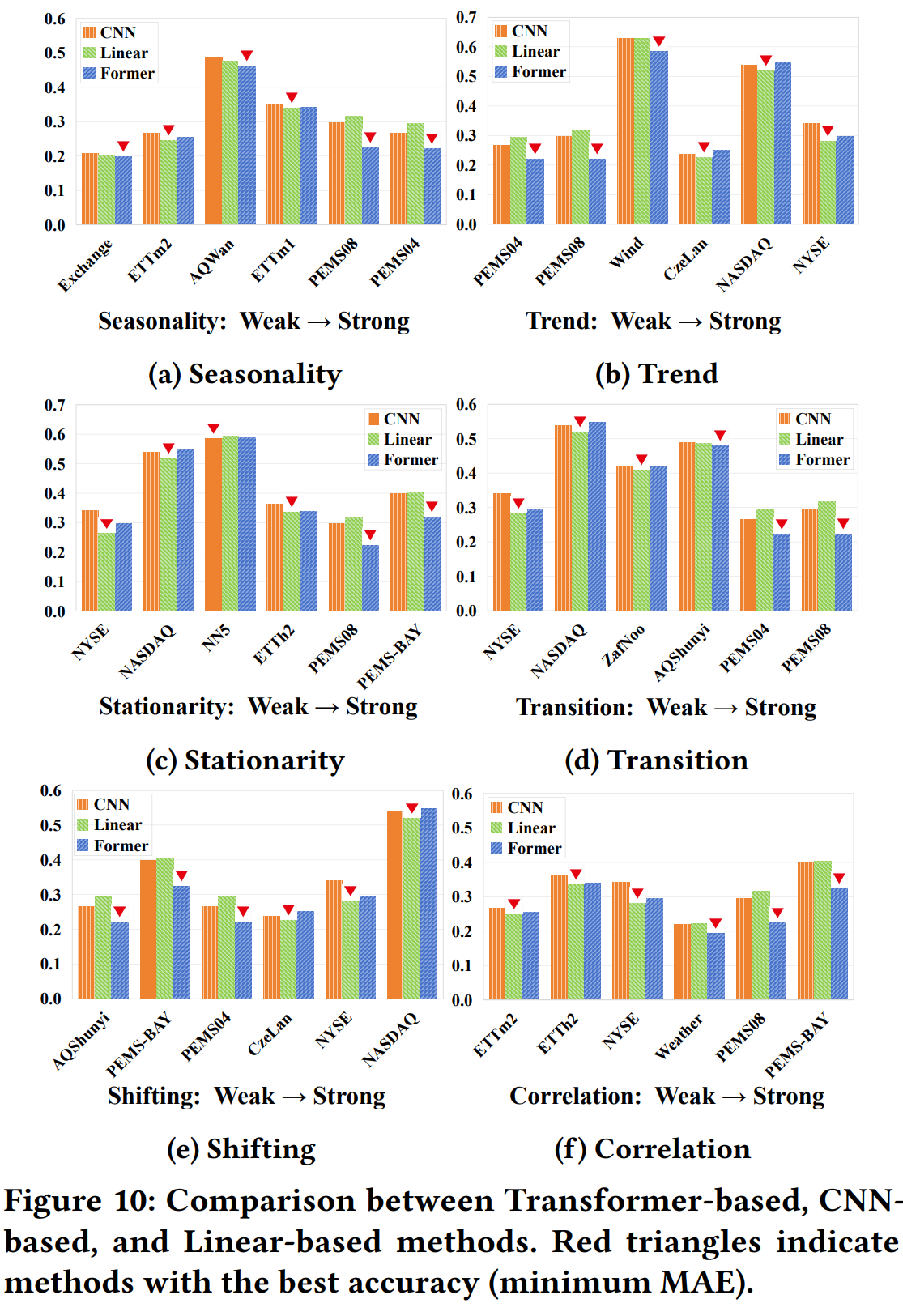
上述两张图,从左到右,所示数据集的时序属性(季节性,趋势性,平稳性,转换,漂移,相关性)逐步增强。
Q: 总结一下论文的主要内容
A: 这篇论文的主要内容可以总结如下:
- 问题陈述:论文识别了现有时间序列预测(TSF)方法评估基准在数据集覆盖、方法多样性和评估流程一致性及灵活性方面存在的不足。
- TFB基准:为了解决上述问题,论文提出了TFB,一个自动化的、全面的和可扩展的时间序列预测方法评估基准。
- 数据集:TFB包含来自10个不同领域的数据集,以确保对各种时间序列特征的全面覆盖,并提供时间序列特征分析以确保数据集的多样性。
- 方法多样性:TFB支持多种时间序列预测方法,包括统计学习、机器学习和深度学习方法,并提供多种评估策略和指标。
- 评估流程:TFB设计了一个灵活的评估流程,包括数据层、方法层、评估层和报告层,以确保不同方法可以在公平和一致的环境中进行比较。
- 实验:论文使用TFB对多种单变量和多变量时间序列预测方法进行了全面评估,并提供了实验结果和分析。
- 发现:通过实验,论文得出了一些关键发现,包括传统统计方法在某些数据集上的表现优于最新方法,以及不同方法在处理具有不同特征的数据集时的优缺点。
- 贡献:TFB作为一个评估工具,为研究人员提供了一个可靠和用户友好的平台,以设计和评估新的TSF方法,并促进了该领域的进步。
- 代码和数据:为了促进研究的透明度和可复现性,论文提供了TFB的代码和数据集的公开访问链接。
*:通过实验,论文得出了一些关键发现,包括传统统计方法在某些数据集上的表现优于最新方法,以及不同方法在处理具有不同特征的数据集时的优缺点。
8. 贡献:TFB作为一个评估工具,为研究人员提供了一个可靠和用户友好的平台,以设计和评估新的TSF方法,并促进了该领域的进步。
9. 代码和数据:为了促进研究的透明度和可复现性,论文提供了TFB的代码和数据集的公开访问链接。
总体而言,TFB基准旨在提供一个综合性的评估框架,以推动时间序列预测领域的研究和实践。
🌟【紧跟前沿】“时空探索之旅”与你一起探索时空奥秘!🚀
欢迎大家关注时空探索之旅
这篇关于AI论文速读 | 2024[VLDB]TFB:全面与公正的时间序列预测方法基准测试研究的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!






