基准专题

一键部署Phi 3.5 mini+vision!多模态阅读基准数据集MRR-Benchmark上线,含550个问答对
小模型又又又卷起来了!微软开源三连发!一口气发布了 Phi 3.5 针对不同任务的 3 个模型,并在多个基准上超越了其他同类模型。 其中 Phi-3.5-mini-instruct 专为内存或算力受限的设备推出,小参数也能展现出强大的推理能力,代码生成、多语言理解等任务信手拈来。而 Phi-3.5-vision-instruct 则是多模态领域的翘楚,能同时处理文本和视觉信息,图像理解、视频摘要

时序数据库 IoTDB 为什么选择 TPCx-IoT 基准测评?
IoTDB 在 TPCx-IoT 榜单的 What 与 Why 解答! 去年,我们发布了 IoTDB 多项性能表现位居国际数据库性能测试排行榜 benchANT(Time Series: DevOps)第一名的好消息。 刚刚落幕的数据库顶级会议 VLDB 上,我们又收获了一则重磅喜讯:IoTDB 原厂团队基于 Apache IoTDB 开发的企业级产品 TimechoDB 成功打破世界纪录,登

使用 WARP 和 Perf 测试对 MinIO 企业对象存储进行基准测试
AI/ML、高级分析和数据库等现代应用程序需要高性能对象存储。MinIO Enterprise Object Store 将可扩展性和高性能相结合,使每个工作负载(无论要求多么苛刻)触手可及。我们发布的基准测试表明,MinIO Enterprise Object Storage 是市面上最快的对象存储,但它的运行速度只能与您提供的硬件和网络一样快。WARP 和 Perf Test 的结果可

使用ROCm和AMD GPU进行机器学习基准测试:复现我们的MLPerf推理提交
Benchmarking Machine Learning using ROCm and AMD GPUs: Reproducing Our MLPerf Inference Submission — ROCm Blogs 简介 衡量新技术的性能是自古以来的一种实验,常常引人入胜(例如,我们仍然用马力来比较新电动汽车电机的性能)。在迅速发展的机器学习(ML)领域,MLPerf在2018年5月2

深度学习实用方法 - 默认的基准模型篇
序言 在深度学习的广阔领域中,选择合适的基准模型是项目成功的关键一步。深度学习模型的选择不仅取决于问题的复杂性,还深受数据结构、任务类型及领域特性的影响。从简单的统计模型如逻辑回归到复杂的深度学习架构,每一步选择都需精心考量。本文将简要概述深度学习中默认的基准模型,旨在为读者提供一个清晰的起点,以便在面对不同问题时能够迅速定位并选用最合适的模型。 默认的基准模型 确定性能度量和目标后,任何实

了解基准测试(benchmark test)
1.基本概念 基准测试,也称之为性能测试,是一种用于衡量计算机系统,软件应用或硬件组件性能的测试方法。基准测试旨在通过运行一系列标准化的任务场景来测量系统的性能表现,从而帮助评估系统的各种指标,如响应时间、吞吐量、延迟、资源利用率等。 英文概念:"Benchmark (computing), the result of running a computer pro

Depth Anything V2:抖音开源高性能任何单目图像深度估计V2版本,并开放具有精确注释和多样化场景的多功能评估基准
📜文献卡 题目: Depth Anything V2作者: Lihe Yang; Bingyi Kang; Zilong Huang; Zhen Zhao; Xiaogang Xu; Jiashi Feng; Hengshuang ZhaoDOI: 10.48550/arXiv.2406.09414摘要: This work presents Depth Anything V2. With

Apache HTTP server benchmarking tool(ab)-服务器基准测试工具一文上手
这是一个非常简单的工具,用途比较有限,只能针对单个URL进行尽可能快的压力测试。 Windows下如何下载安装(Linux安装十分简单) Apache HTTP server benchmarking tool(ab)下载地址 资源 2.4版本 httpd-2.4.48-o111k-x64-vc15.zip 解压移动至C盘 管理员身份运行CMD,进入bin目录,执行

AI大模型落地应用场景:LLM训练性能基准测试
随着 ChatGPT 的现象级走红,引领了AI大模型时代的变革,从而导致 AI 算力日益紧缺。与此同时,中美贸易战以及美国对华进行AI芯片相关的制裁导致 AI 算力的国产化适配势在必行。之前也分享过一些国产 AI 芯片、使用国产 AI 框架 Mindformers 基于昇腾910训练大模型,使用 MindIE 进行大模型服务化等。 训练性能的定义 训练性能在本文指机器(GPU、NPU或其他平台
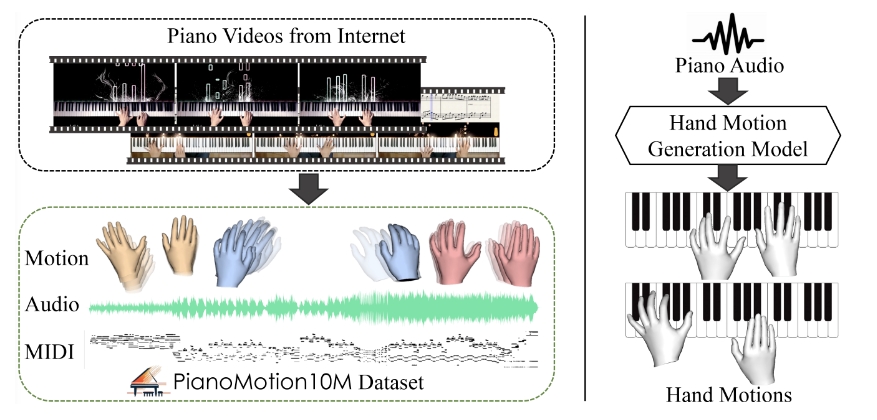
开源的代码语言模型DeepSeek-Coder-V2;Runway推出Gen-3;多层架构整合多个大语言模型;大规模钢琴手部动作数据集和基准
✨ 1: DeepSeek-Coder-V2 开源的多专家代码语言模型,支持338种编程语言。 DeepSeek-Coder-V2 是一个开源的代码语言模型,专为代码生成、代码补全、代码修复以及数学推理等任务而设计。该模型通过在大量高质量的多源语料库上进一步训练,显著提升了其在代码生成和数学推理方面的能力,同时在一般语言任务中的表现也保持在同等水平。DeepSeek-Coder-V2

Rust创建基准测试bench
打开终端(或命令提示符)。 导航到父目录。 将 Rust 编译器切换到 nightly 版本: rustup default nightly 在该目录下运行 cargo init 命令来创建一个新的 Rust 项目,这将在当前目录下创建 Cargo.toml 和 src 目录: cargo init --lib 请注意,我们使用 --lib 选项因为我们将创建一个库项目而不

MultiTrust:首个综合统一的多模态信任度基准(上)
随着我们迈向人工通用智能(AGI)的时代,出现了开创性的大语言模型(LLMs)。凭借它们强大的语言理解和推理能力,已经无缝地将其他模态(例如视觉)整合到LLMs中,以理解不同的输入。由此产生的多模态大型语言模型(MLLMs)在传统视觉任务和更复杂的多模态问题上都表现出了多样化的专业能力。然而,尽管它们表现出色,并且努力与人类偏好保持一致,这些尖端模型在可信度方面仍存在显著缺陷,导致事实上的
redis-benchmark 基准测试
我们可以通过 redis 自带工具 redis-benchmark 来对 redis 服务器进行性能测试。 我们可以通过简单的 redis-benchmark 命令直接对本地部署的 redis 进行性能测试,不用输入任何的参数。默认情况下,redis-benchmark 会向 redis 服务器使用 50 个并发连接发送共 100000 个请求。 如果想指定参数可以参考下面命令: redis
Lettuce和Jedis的基准测试
原文链接:https://www.dubby.cn/detail.html?id=9108 1.准备工作 本地需要安装Redis,使用JMH做基准测试的框架: <dependency><groupId>org.openjdk.jmh</groupId><artifactId>jmh-core</artifactId><version>1.21</version></dependency>

【论文速读】| BIOCODER:一个具有上下文实用知识的生物信息学代码生成基准测试
本次分享论文:BIOCODER: A Benchmark for Bioinformatics Code Generation with Contextual Pragmatic Knowledge 基本信息 原文作者:Xiangru Tang, Bill Qian, Rick Gao, Jiakang Chen, Xinyun Chen, Mark Gerstein 作者单位:耶

图与矢量 RAG — 基准测试、优化手段和财务分析示例
图与矢量 RAG — 基准测试、优化手段和财务分析示例 Neo4j 和 WhyHow.AI 团队探索了图和矢量搜索系统如何协同工作以改进检索增强生成 (RAG) 系统。使用财务报告 RAG 示例,我们探索了图和矢量搜索之间的响应差异,对两种类型的答案输出进行了基准测试,展示了如何通过图结构优化深度和广度,并探索了为什么将图和矢量搜索结合起来是 RAG 的未来。 图数据库(如 Neo4j)基
15.2 测试-网格测试、基准测试与测试覆盖率
1. 网格测试 函数或方法的输出因收到的输入而异,如果为每个输入专门编写一个测试用例,将导致大量的重复代码。 不妨将输入的各种组合存放在网格之中,只编写一个测试用例即完成对所有输入的测试,比如象下面这样: var greetingTests = []greetingTest{ {"en-US", "George", "Hello George!"}, {"f
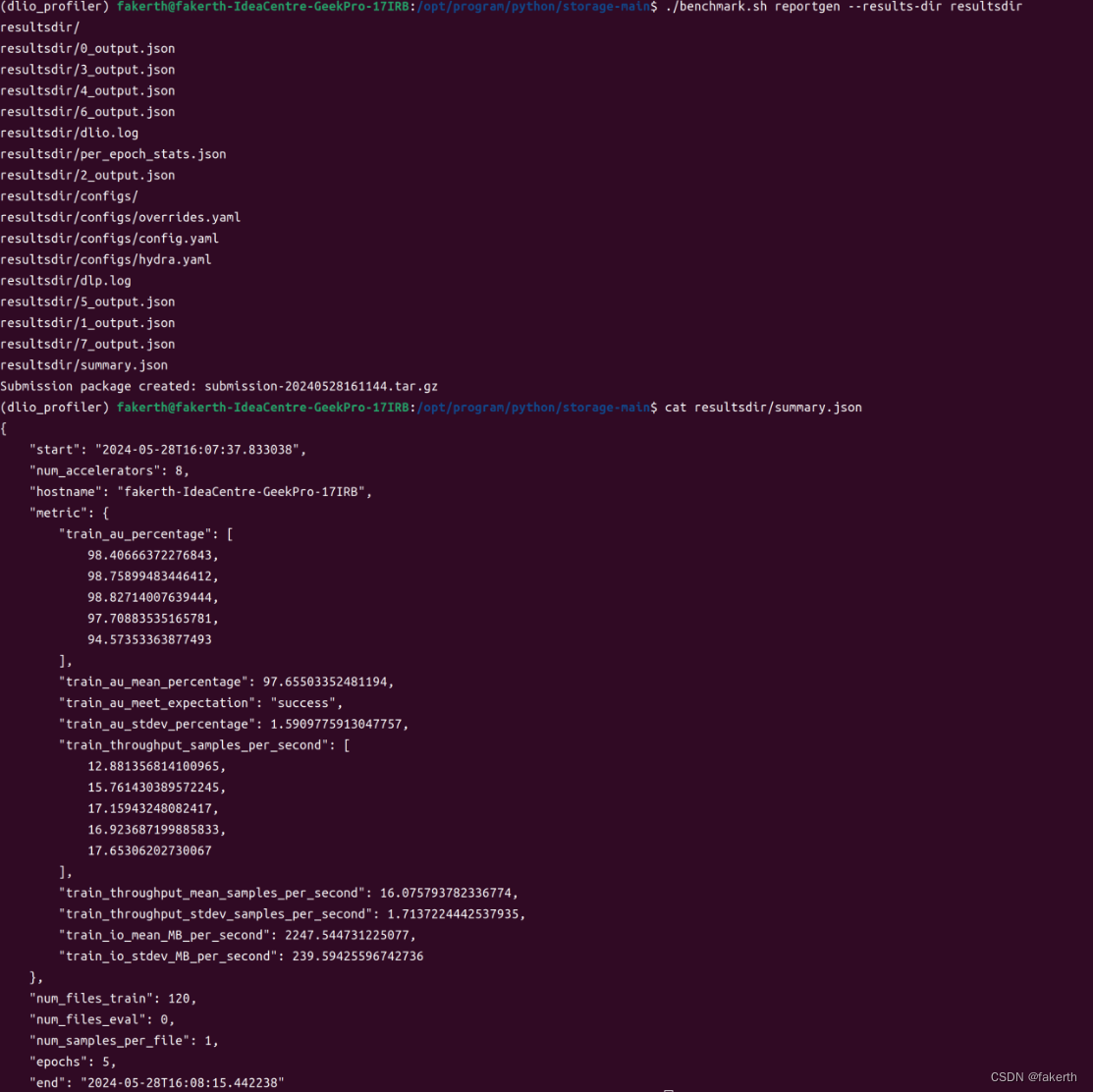
MLPerf storage基准测试
MLPerf 基准测试 什么是 MLPerf?MLPerf™ 基准测试由来自学术界、研究实验室和行业的 AI 领导者联盟 MLCommons 开发,旨在对硬件、软件和服务的训练和推理性能进行无偏评估。它们都在规定的条件下进行。为了保持在行业趋势的前沿,MLPerf 不断发展,定期举行新的测试,并添加代表 AI 技术水平的新工作负载。 Nidia介绍:https://www.nvidia.cn/
LLM 基准测试的深入指南
随着越来越多的 LLM 可用,对于组织和用户来说,快速浏览不断增长的环境并确定哪些模型最适合他们的需求至关重要。实现这一目标的最可靠方法之一是了解基准分数。 考虑到这一点,本指南深入探讨了 LLM 基准的概念、最常见的基准是什么以及它们需要什么,以及仅依赖基准作为模型性能指标的缺点是什么。 什么是 LLM 基准,为什么它们很重要? LLM 基准测试是一种标准化的性能测试,用于评估 AI 语言

《异常检测——从经典算法到深度学习》29 EasyTSAD: 用于时间序列异常检测模型的工业级基准
《异常检测——从经典算法到深度学习》 0 概论1 基于隔离森林的异常检测算法 2 基于LOF的异常检测算法3 基于One-Class SVM的异常检测算法4 基于高斯概率密度异常检测算法5 Opprentice——异常检测经典算法最终篇6 基于重构概率的 VAE 异常检测7 基于条件VAE异常检测8 Donut: 基于 VAE 的 Web 应用周期性 KPI 无监督异常检测9 异常检测资料汇总(

斯坦福报告解读3:图解有趣的评估基准(上)
《人工智能指数报告》由斯坦福大学、AI指数指导委员会及业内众多大佬Raymond Perrault、Erik Brynjolfsson 、James Manyika等人员和组织合著,旨在追踪、整理、提炼并可视化与人工智能(AI)相关各类数据,该报告已被大多数媒体及机构公认为最权威、最具信誉人工智能数据与洞察来源之一。 2024年版《人工智能指数报告》是迄今为止最为详尽的一份报告,包含了

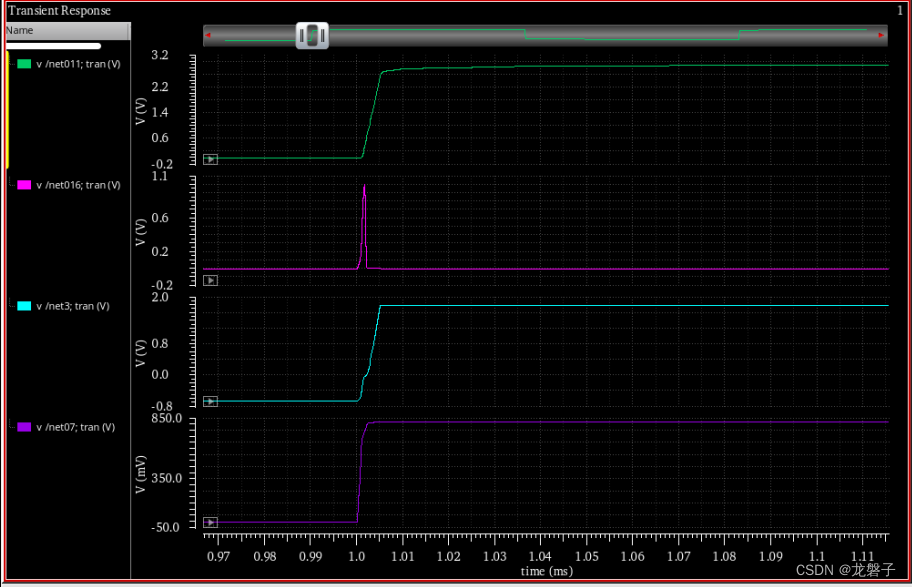
【电子元件】TL431 电压基准
TL431(C23892)是一种常用的可调节精密电压基准和电压调节器。它广泛应用于电源管理、精密参考电压和稳压电路等领域。以下是TL431的一些关键特点和使用方法: 关键特点 可调输出电压:TL431的输出电压可以通过外部电阻网络在2.495V到36V范围内调整。精度高:具有±0.5%的初始精度,提供稳定的参考电压。低温度系数:在宽温度范围内保持稳定的性能。高输入电压范围:适用于高电压

2024年NGFW防火墙安全基准-防火墙安全功效竞争性评估实验室总结报告
Check Point 委托 Miercom 对 Check Point 下一代防火墙 (NGFW) 开展竞争性安全有效性测试, 选择的竞品分别来自 Cisco、Fortinet 和 Palo Alto Networks。对 Zscaler 的测试涉及他们的 SWG(安全网关)。测试内容包括验证防病毒、反恶意软件、入侵防护系统 (IPS)、防僵尸网络、 URL 过滤 (URLF)、沙盒、机器学习及