本文主要是介绍VS编译部署libtorch-yolov5推理运行自己训练的权重文件/模型,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
libtorch-yolov5推理运行
- 一、模型文件导出
- 二、项目创建
- 2.1、测试代码下载
- 2.2、文件拷贝
- 2.3、代码优化修改
- 2.4、其它准备工作
- 三、代码运行
- 3.1、参数修改
- 3.2、修改完毕点击运行
前期环境配置(vs+libtorch+opencv)可以参考博主另一篇博文vs配置opencv和libtorch(2.2.2)(cuda12.0),这里主要基于环境配置好之后如何运行yolov5的推理程序,并生成对应的.exe文件。
博主环境软件版本:
- win10
- pytorch 2.2.2
- libtorch 2.2.2
- opencv4.8.0
- -cuda12.0
libtroch版本尽量和pytorch的版本一致,各版本libtorch下载地址。1.10.1版本该连接的博文中没有给出,可以直接修改后面的版本号,例如CPU-Release版本的地址为:
https://download.pytorch.org/libtorch/cpu/libtorch-win-shared-with-deps-1.10.1%2Bcpu.zip
博主查阅了很多博文,有的博文是通过cmake编译运行,博主vs新手,因为VS配置的libtorch和opencv是跟着项目的(在vs界面),博主暂时还没能把终端cmake编译和vs联系起来(配置好的环境容易崩掉),后边有时间再出一版结合cmake编译运行的方案。
所以这篇文章主要就是在vs端直接编译运行libtorch-yolov5程序,并生成对应的.exe文件。
一、模型文件导出
如果已经导出了GPU模型的朋友可以跳过这一步。
这一步是准备后续工作推理需要的模型文件,训练得到的.pt文件不能直接使用,需要转换为torchscript, onnx, coreml, saved_model, pb, tflite, tfjs等格式,博主以torchscript为例。
打开export.py,修改参数【‘–data’】数据集的.yaml文件为自己对应的.yaml文件地址,博主是CCPD.yamll;修改参数【‘–weights’】为自己训练好的权重文件地址,博主是runs/train/exp5/weights/best.pt(最后导出的模型文件也在此目录下);参数【‘–include’】,default参数修改为torchscript。
除了直接修改参数,也可以在终端运行命令行:
python export.py --data data/CCPDMASK.yaml --weights runs/train/exp5/weights/best --include torchscript
.pt
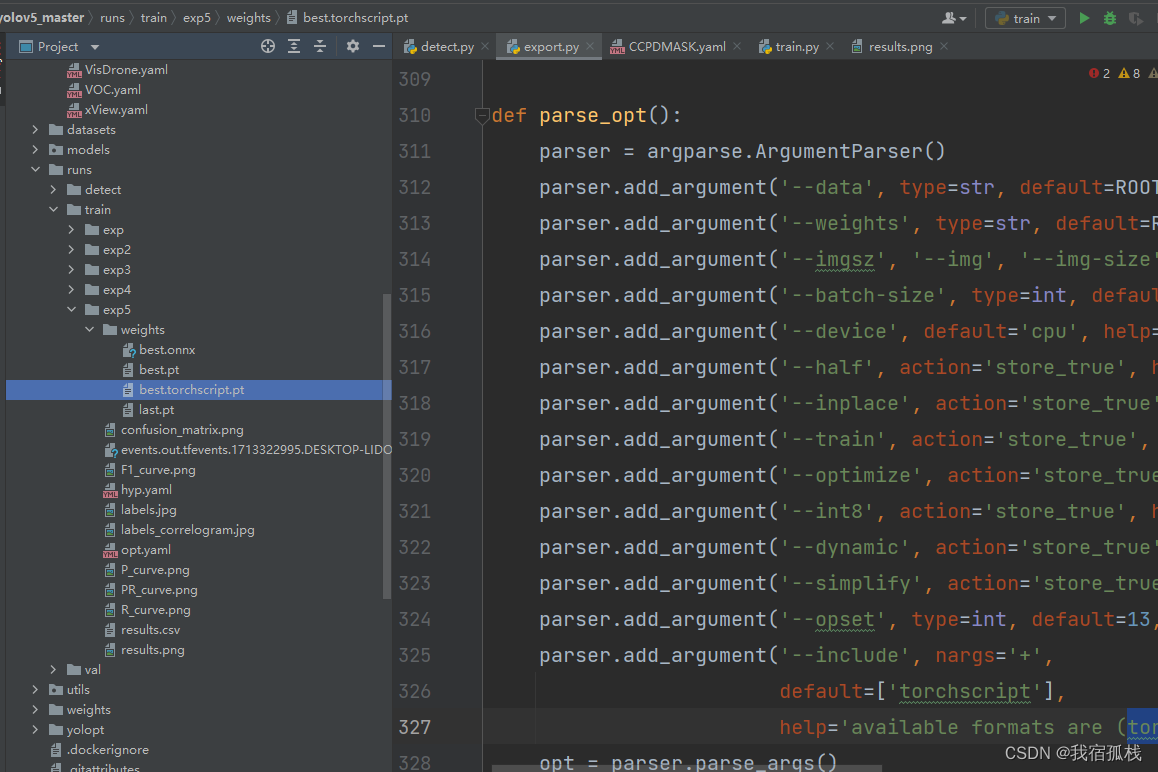
如下图所示,成功导出。

可以在相应的目录下看到该文件:
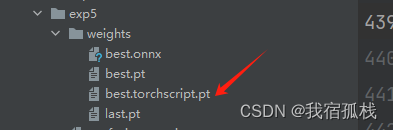
注意这里的导出参数【‘–imgsz’】和训练时的【‘–imgsz’】需保持一致,同理后续推理时的【‘–imgsz’】也保持一致。
export.py更多参数含义有兴趣的可以单独搜索下,这里不做赘述。
二、项目创建
接博文vs配置opencv和libtorch(2.2.2)(cuda12.0),环境已配置完毕,接下来就是项目创建。
2.1、测试代码下载
下载地址:libtorch-yolov5官方源码下载。
这个项目是将yolov5训练好的模型用于推理,并生成.exe文件以及lib文件,用以后续部署的。
- PyInstaller通过spec也可以打包模型恩建,方便不会使用Python脚本的研究人员使用,但不适用于工作中实际任务的深度学习模型部署(速度较低且占用空间)。
下载解压后如图所示:

2.2、文件拷贝
接博文vs配置opencv和libtorch(2.2.2)(cuda12.0)创建的项目Project3,分别在头文件和源文件里边创建【2.1】下载的libtorch-yolov5源码里的各个文件。
这给出两种方法:
- 方法1:将源码中【src】和【include】目录里边的文件拷贝到
D:\VCworkspace\Project3\Project3目录下,这个目录即为博主最开始创建的twst.cpp所在的文件目录;在右键【源文件】→【添加】→【现有项】,选择上一步拷贝的.cpp进行添加;头文件同理;添加完成后就可以在VS项目下看到对应的文件啦。(如果只是复制,VS好像并不能直接同步过来) - 方法2:分别点击头文件源文件并新建同名头文件,源文件后,将相应的代码拷贝过来。(如果要修改名字,注意引用时也应该修改,新手的话建议暂时不改)
创建完成后如图所示:
2.3、代码优化修改
这一步如果是运行训练时imgsz为640`且不会更改的模型文件,那可以跳过这不。但后续若更改训练尺寸大小的话,可以优化下源码。
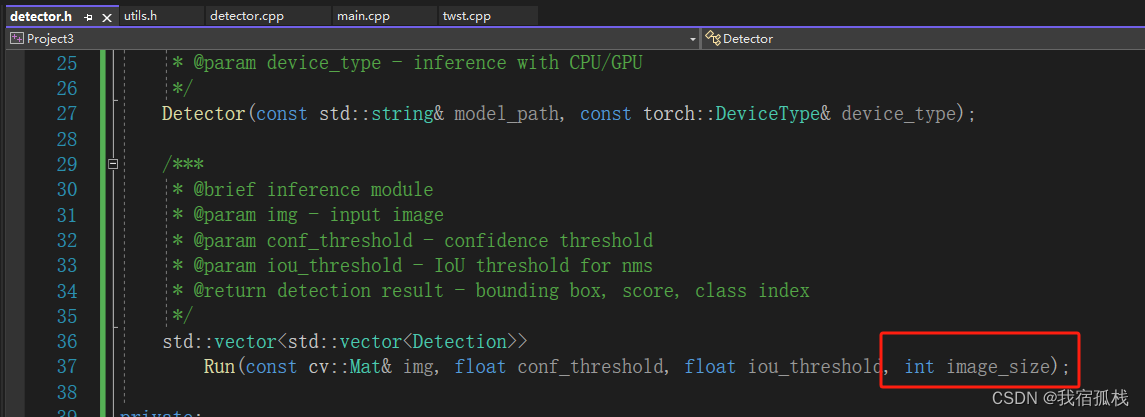
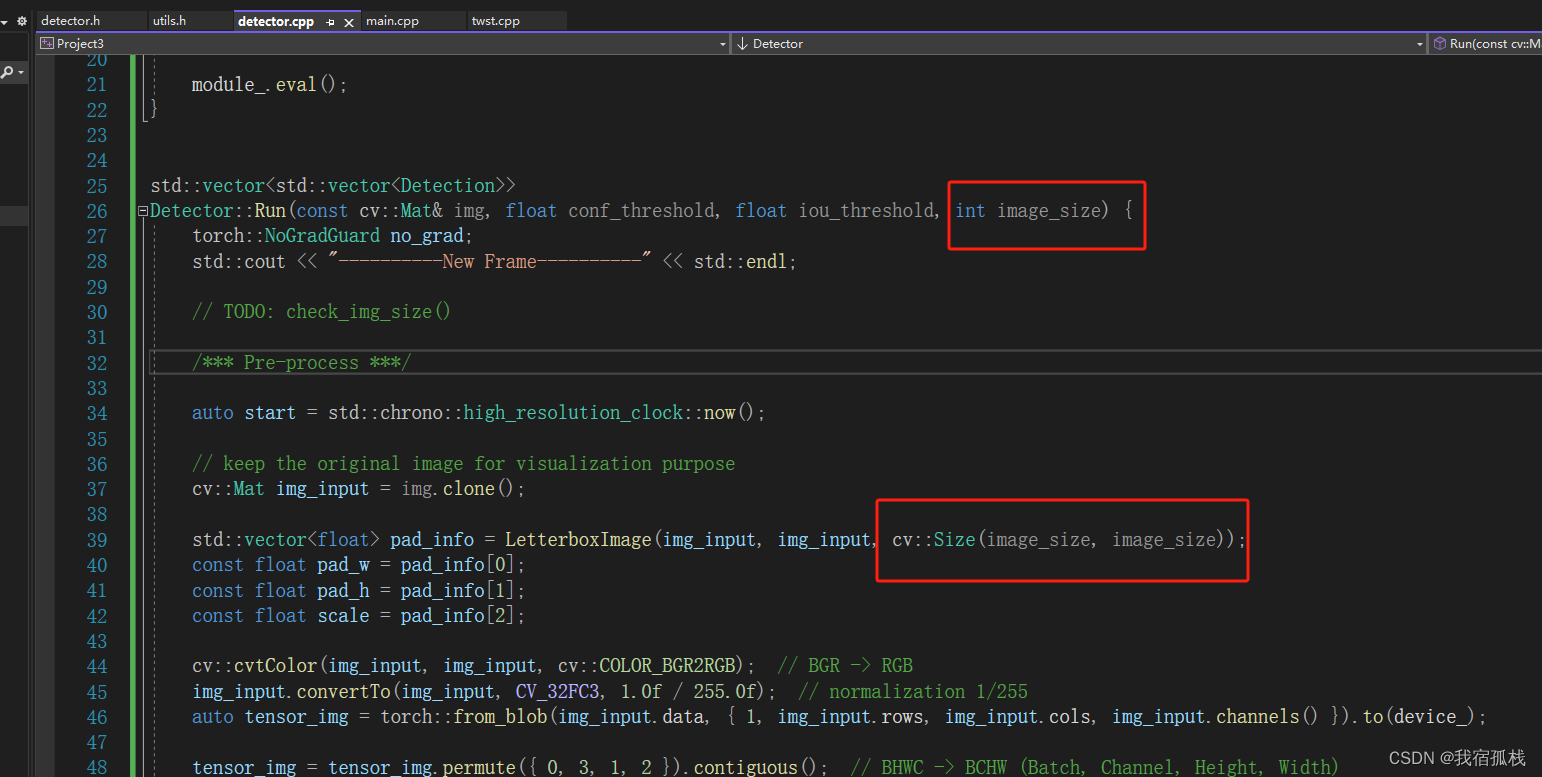
在源码Run()函数中增加一个函数输入,目的是调整推理时,输入网络的图片尺寸大小;在main()函数中增加两个输入,“label”和“imgsz”,别是标签文件所在的路径和输入网络的尺寸大小。
对应修改如下:
【detector.h】
【detector.cpp】
【main.cpp】
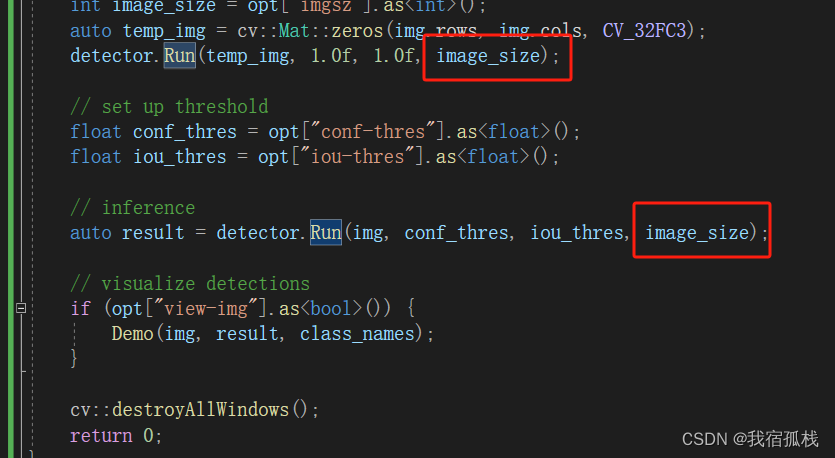

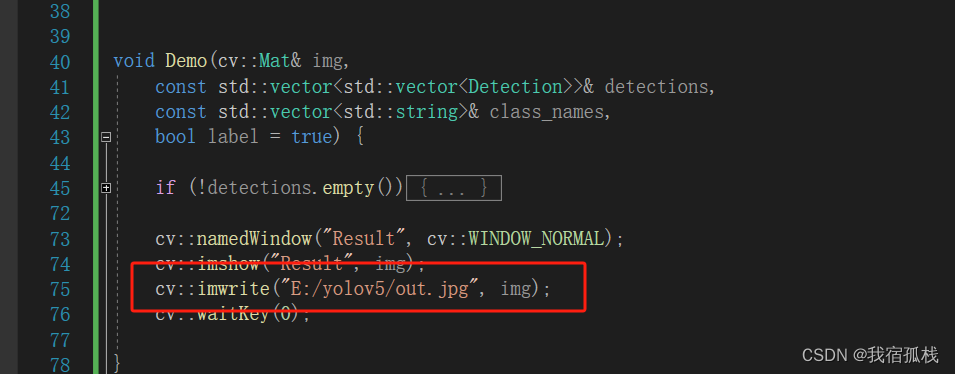
demo()函数中可增加一句代码,保存推理后的图片,地址给测试图片的路径地址。
2.4、其它准备工作
为了测试方便,博主新建一个文件用于存放测试相关的文件yolov5。
将【一】中导出的模型文件拷贝到该目录下;测试图片bus.jpg也放置在此目录下;新建一个.names文件。
.names文件创建方法:
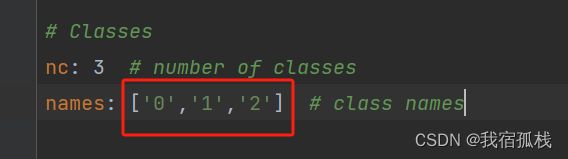
1) 文件夹里右键新建一个文本文件ccpdmask,打开后编辑训练的数据集的类别;

这里的类别名字同训练时的.yaml文件:
2)点击【查看】,勾选【文件扩展名】,将文本文件的后缀名.txt改为.names。如下图所示:

三、代码运行
3.1、参数修改
将箭头所示参数分别修改为【2.4】中对应文件的地址:

这里给生成推理结果图片的地址
3.2、修改完毕点击运行
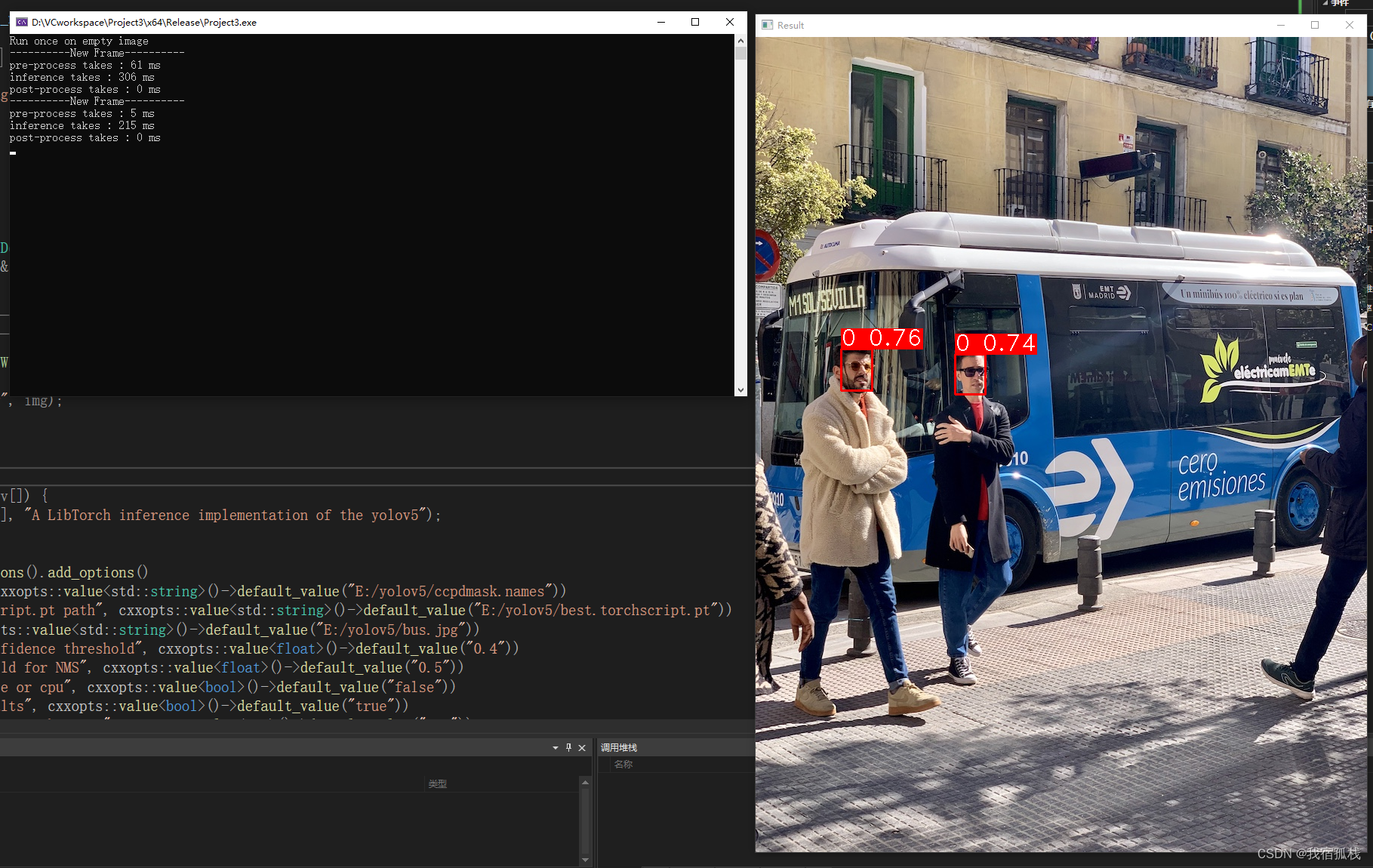
成功运行。
在【3.1】给出的路径下也有推理结果的图片生成。
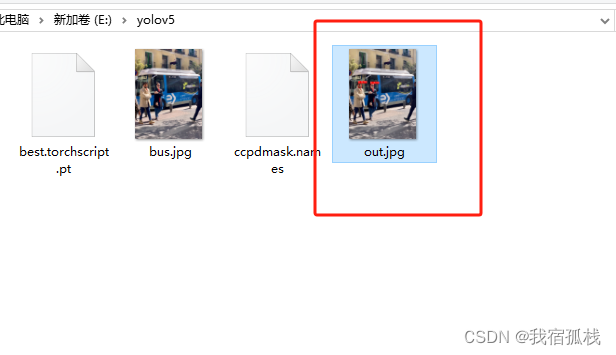
终于拿下啦。
大家有什么问题欢迎私信博主!
这篇关于VS编译部署libtorch-yolov5推理运行自己训练的权重文件/模型的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!






