本文主要是介绍Vision GNN: An Image is Worth Graph of Nodes,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
- 感受野:在卷积神经网络中,感受野(Receptive Field)是指特征图上的某个点能看到的输入图像的区域,即特征图上的点是由输入图像中感受野大小区域的计算得到的。
感受野并非越大越好,反而可能因为过大而过于发散 - 梯度下降(Gradient Descent GD):简单来说就是一种寻找目标函数最小化的方法,它利用梯度信息,通过不断迭代调整参数来寻找合适的目标值。
- 超参数:在机器学习的上下文中,超参数是在开始学习过程之前设置值的参数,而不是通过训练得到的参数数据。通常情况下,需要对超参数进行优化,给学习机选择一组最优超参数,以提高学习的性能和效果。
在机器学习的过程中,
超参= 在开始机器学习之前,就人为设置好的参数。
模型参数=通过训练得到的参数数据。
通常情况下,需要对超参数进行优化,给学习机选择一组最优超参数,以提高学习的性能和效果
- 归一化:数据的标准化(normalization)是将数据按比例缩放,使之落入一个小的特定区间。在某些比较和评价的指标处理中经常会用到,去除数据的单位限制,将其转化为无量纲的纯数值,便于不同单位或量级的指标能够进行比较和加权。其中最典型的就是数据的归一化处理,即将数据统一映射到[0,1]区间上。
目的就是使得预处理的数据被限定在一定的范围内(比如[0,1]或者[-1,1]),从而消除奇异样本数据导致的不良影响。 - 骨干网络:在计算机视觉任务中,骨干网络(Backbone)是对图像进行特征提取的基础网络。它是计算机视觉下游任务(如分类、分割、检测等)的核心组成部分。
一个设计良好的特征提取网络能够显著提升算法的性能表现。
前置(VIT)
- idea:
- 直接把图像分为固定大小的patches
- 通过线性变换得到patch embedding。类似于NLP的words和word embedding
- 由于transformer的输入就是a sequence of token embeddings,则把图像的patch embeddings送入transformer后就能够进行特征提取从而分类
研究背景
- 选题切入点
- CNN和Transformer存在的问题
CNN和Transformer认为图象是网格或者序列结构,不能灵活地捕捉不规则和复杂的物体。
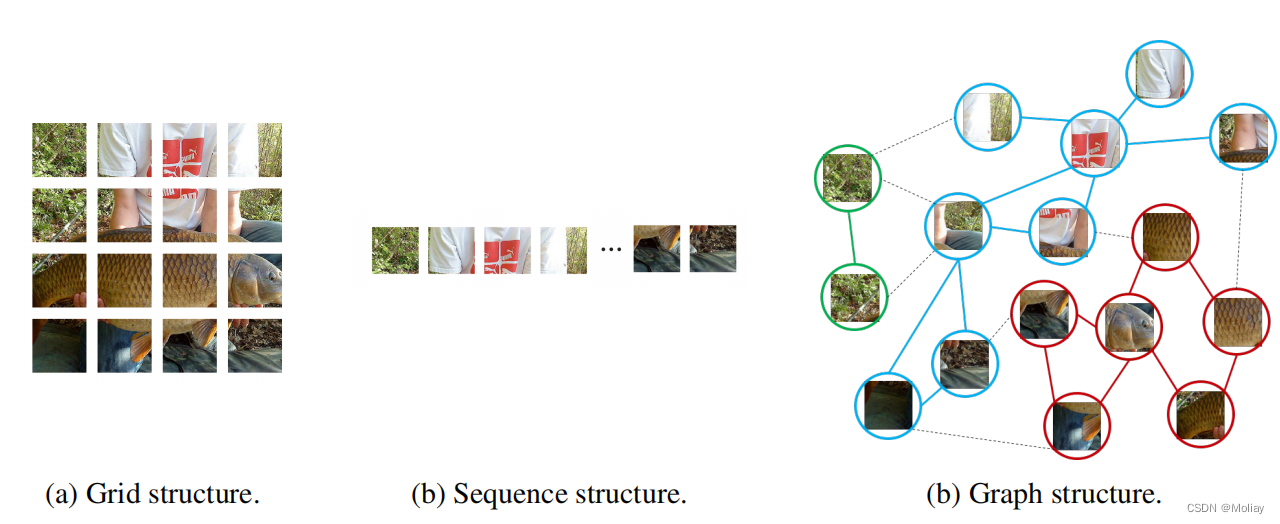
- GNN在CV中的研究现状
- GNN只能用在有天然的图的特殊的视觉任务(如点云数据的分类和分割)
- 对于计算机视觉中的一般应用(如图像分类),缺少一个通用的GNN骨干网络来处理图像
- CNN和Transformer存在的问题
- 用graph的优点:
- graph是一种广义的数据结构,网格和序列可以视为图的特例
- 图比网格或序列更灵活地建模复杂对象,因为图像中的对象通常不是方形的,其形状是不规则的
- 一个对象可以视为部分的组合(例如说一个人可以分为头,上半身,手臂,腿),图结构可以构建这些部分之间的联系
- GNN的先进研究可以转移到解决视觉问题上
用图结构表示图像
方法
用图结构表示图像
图像预处理主要是将 2D 图像转化为一个图结构。图像首先被均匀切分成若干个图像块,每个图像块通过简单的映射转化为特征向量X={x1,x2,……,xN}。这里每个图像块特征视作一个节点,也就是V={V1,V2,……,VN} ,对于每个节点,找到它的 K 近邻 N(vi),然后在两者之间连接一条边,从而构建出一个完整的图结构:
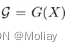
图卷积
图卷积层通过聚集相邻节点的特征,可以在节点之间交换信息。具体而言,图卷积操作如下:
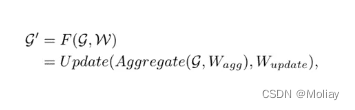
其中 Aggregate 聚合操作通过聚合相邻节点的特征来计算节点的表示,Update 更新操作用来更新聚合后的节点特征。在实际部署时,使用了 max-relative 图卷积:
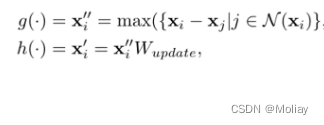
增强节点多样性
直接堆叠图卷积构建视觉图网络的话,由于图像块存在相似性和图卷积的聚合机制,会出现节点过平滑的现象,也就是随着网络的加深,节点特征之间会越来越相似。为了缓解这个问题,ViG 引入前馈神经网络 FFN 模块以及更多线性变换来增强特征变换能力和特征多样性.
在图卷积之前和之后应用一个线性层,将节点特征投影到同一个域中,并增加特征的多样性。在图卷积后插入一个非线性激活函数,以避免多层退化为单层。升级后的模块称为 Grapher 模块:
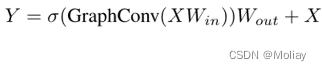
为了进一步提高特征变换能力和缓解过度平滑现象,在每个节点上使用前馈网络(FFN)。FFN 模块是一个简单的多层感知器,具有两个完全连接的层:
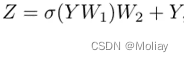
通过 Grapher 模块和 FFN 模块的堆栈构成 ViG 块,ViG 块用作构建网络的基本构建单元。基于图像的图形表示和提出的 ViG 块,可以为视觉任务构建 ViG 网络
ViG 网络架构
通过堆叠 L 个 ViG block,构成作者的 ViG 网络结构。给出了 isotropic 式和金字塔式两种网络架构,如下表所示。

表 1:Isotropic ViG 网络结构参数。
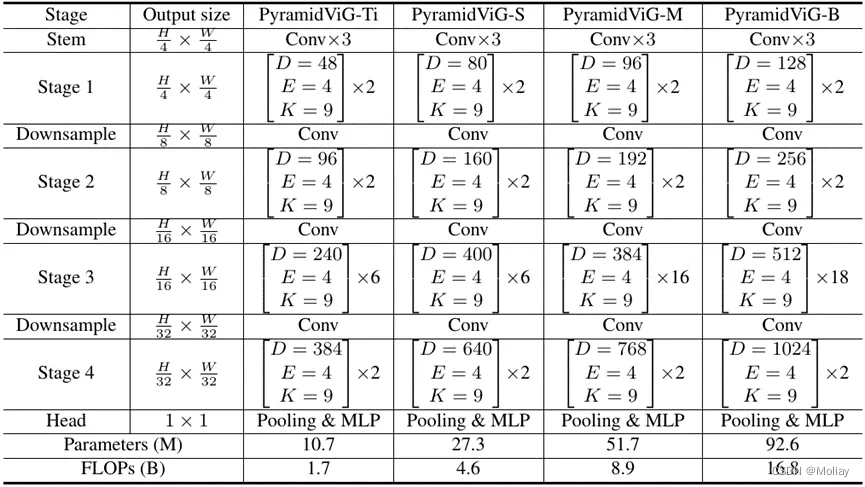
表 2:Pyramid ViG 网络结构参数。
贡献&局限
- 创新点
- 提出了一个用于视觉任务的通用GNN骨干网络,并设计了同向性结构和金字塔结构
- 直接在图像上使用GNN会出现over-smoothing问题并导致性能变差,故提出了FC操作和FFN层来解决这个问题
- 局限性
- 与VIT相同,VIG在少量的数据下表现得性能并不优秀,往往需要通过大量的数据做梯度下降才能取得比较好的效果
- 从image到graph的过程中,本文采用KNN来取K(超参数)个邻居作为邻居结点;对于不同的图像,所需的K值不一定相同。
这篇关于Vision GNN: An Image is Worth Graph of Nodes的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!






