本文主要是介绍经典文献阅读之--A Survey on Generative Diffusion Models(扩散模型最新综述),希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
0. 简介
本文综述了深度生成模型,特别是扩散模型(Diffusion model),如何赋予机器类似人类的想象力。扩散模型在生成逼真样本方面显示出巨大潜力,克服了变分自编码器中的后分布对齐障碍,缓解了生成对抗网络中的对抗性目标不稳定性。
扩散模型包括两个相互连接的过程:一个将数据分布映射到简单先验分布的前向过程和一个相应的反向过程。前向过程类似于具有时变系数的简单布朗运动。神经网络通过使用去噪评分匹配目标来训练估计得分函数。在前向扩散阶段,图像被逐渐引入的噪声污染,直到图像成为完全随机噪声。在反向过程中,利用一系列马尔可夫链在每个时间步逐步去除预测噪声,从而从高斯噪声中恢复数据。

然而,扩散模型与GANs和VAEs相比,其采样过程本质上需要更耗时的迭代过程。这是由于通过利用ODE/SDE或马尔科夫过程将先验分布转化为复杂数据分布的迭代转换过程,这需要反向过程中进行大量的函数评估。
这是由于扩散模型保留数据语义结构的能力。然而,这些模型的计算要求很高,训练需要非常大的内存,这使得大多数研究人员甚至无法尝试这种方法。这是因为所有的马尔可夫状态都需要一直在内存中进行预测,这意味着大型深度网络的多个实例一直在内存中。此外,这些方法的训练时间也变得太高(例如,几天到几个月),因为这些模型往往陷入图像数据中细粒度的、难以察觉的复杂性。然而,需要注意的是,这种细粒度图像生成也是扩散模型的主要优势之一,因此,使用它们是一种矛盾。
为了应对这些挑战,研究人员提出了各种解决方案。例如,提出了先进的ODE/SDE求解器来加速采样过程,同时采用了模型传授策略来实现这一目标。此外,还引入了新型前向过程来增强采样稳定性或促进维度降低。此外,近年来有一系列研究致力于利用扩散模型有效地连接任意分布。为了提供一个系统性的概述,我们将这些进展分为四个主要领域:采样加速、扩散过程设计、似然优化和连接分布。此外,本综述将全面考察扩散模型在不同领域中的各种应用,包括计算机视觉、自然语言处理、医疗保健等。
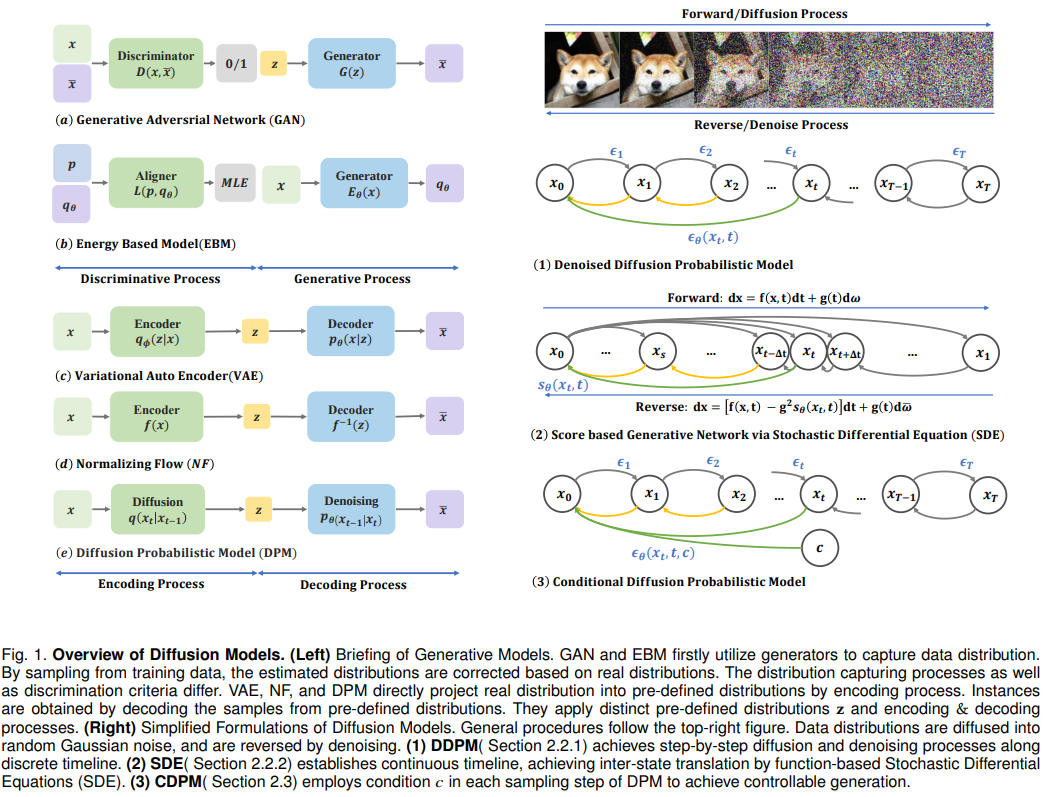
图1. 扩散模型概述。 (左) 生成模型简介。GAN 和 EBM 首先利用生成器捕获数据分布。通过从训练数据中采样,根据真实分布纠正估计的分布。捕获过程及判别标准各异。VAE、NF 和 DPM 通过编码过程直接将真实分布投影到预定义的分布中。实例是通过解码预定义分布中的样本获得的。它们应用不同的预定义分布 z 和编码解码过程。 (右) 扩散模型的简化形式。通用程序遵循右上方图示。数据分布被扩散到随机高斯噪声中,并通过去噪过程被反转。 (1) DDPM沿离散时间线实现逐步扩散和去噪过程。 (2) SDE建立连续时间线,通过基于函数的随机微分方程(SDE)实现状态间的转换。 (3) CDPM在 DPM 的每个采样步骤中使用条件 𝑐 来实现可控的生成。
1. 算法改进
尽管扩散模型在各种数据模态中生成的质量很高,但它们在现实世界的应用仍有待改进。与其他生成模型(如GAN和VAE)不同,它们需要一个缓慢的迭代抽样过程,并且它们的前向过程在高维像素空间中操作。本节重点介绍了四项最近的发展,以增强扩散模型的性能:(1)抽样加速技术(第2节)用于加速标准ODE/SDE模拟;(2)新的前向过程(第3节)用于改进像素空间中的布朗运动;(3)似然优化技术(第4节)用于增强扩散ODE的似然度;(4)桥接分布技术(第5节)利用扩散模型的概念连接两个不同的分布。
2. 抽样加速
尽管扩散模型生成的图像质量很高,但由于其抽样速度较慢,实际应用受到了限制。本节简要介绍了四种先进技术来提高抽样速度:蒸馏、训练进度优化、无需训练的加速以及将扩散模型与更快的生成模型集成。
2.1 知识蒸馏
知识蒸馏是一种从较大模型向较简单模型转移“知识”的技术,正在越来越流行。在扩散模型中,目标是通过对齐和最小化原始样本与生成样本之间的差异,使用更少的步骤或更小的网络生成样本。将其视为跨分布的轨迹优化,蒸馏提供了经济高效和更快的可控生成的最佳映射。
ODE轨迹知识蒸馏从教师模型到学生模型使用ODE形式的蒸馏,通过分布场中的高效路径将先验分布映射到目标分布。首先将这一原理应用于改进扩散模型,通过逐步蒸馏抽样轨迹,在每两个步骤中纠正潜在映射。 TRACT、Denoising Student 和 Consistency Models 扩展了这种效果,通过在时间 𝑇 中直接估计干净数据,将加速率提高到了 64 和 1024。RFCD 通过在训练期间对齐样本特征来增强学生模型的性能。通过最优传输,可以获得最佳轨迹。通过最小化流匹配中的分布间运输成本,ReFlow 和 实现了单步生成。DSNO 提出了一个用于直接时间路径建模的神经运算符。 Consistency Model、SFT-PG 和 MMD-DDM 分别使用 LPIPS、IPA 和 MMD 寻找理想轨迹。SDE轨迹蒸馏难度仍然较大。提出了一些工作(参见第5节)。
2.2 训练进度优化
改进训练进度涉及修改传统的训练设置,如扩散方案和噪声方案,这些设置与抽样无关。最近的研究突出了影响学习模式和模型性能的训练方案中的关键因素。在本小节中,我们将训练增强技术分为两个主要领域:扩散方案学习和噪声尺度设计。
扩散方案学习 扩散模型将数据投影到潜在空间中,如变分自动编码器(VAEs),由于其更高的表现力,它们更复杂。这些模型中的反向解码方法可以分为两种方法:编码程度优化和投影方法。
编码程度优化方法,如 CCDF 和 Franzese et al.,通过将扩散步骤的数量视为变量,最小化证据下界(ELBO)。另一种方法是截断,通过从较少扩散的数据中进行一步采样,平衡生成速度和样本保真度。TDPM 和 ES DDPM 使用 GAN 和 CT 进行截断。投影方法,如 Soft diffusion 和模糊扩散模型,利用线性破坏(如模糊和蒙版)来探索扩散核的多样性。
**噪声尺度设计 **在传统的扩散过程中,每个转换步骤由注入的噪声确定,这相当于在前向和反向轨迹上进行随机行走。设计噪声尺度可以导致合理的生成和快速收敛。与传统的 DDPM 不同,现有的方法在整个过程中将噪声尺度视为可学习参数。
对于前向噪声设计方法,如VDM,将噪声尺度参数化为信噪比,将其与训练损失和模型类型联系起来。FastDPM将噪声设计与ELBO优化联系起来,使用离散时间变量或方差标量。对于反向噪声设计,改进的DDPM通过训练混合损失隐式学习反向噪声尺度,而San Roman等人则使用噪声预测网络在祖先采样之前更新反向噪声尺度。
2.3 无需训练的采样
无需训练的方法旨在利用先进的采样器加速预先训练的扩散模型的采样过程,消除了重新训练模型的需要。本小节将这些方法分为几个方面:扩散ODE和SDE采样器的加速、分析方法和动态规划。
ODE加速证明了DDPM中的随机采样过程具有等价的概率ODE,其定义了从先验到数据分布的确定性采样轨迹。鉴于ODE采样器产生的离散化误差较少,大多数先前关于采样加速的工作都是以ODE为中心的。例如,广泛使用的采样器DDIM可以被视为概率流ODE:
…详情请参照古月居
这篇关于经典文献阅读之--A Survey on Generative Diffusion Models(扩散模型最新综述)的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!







