本文主要是介绍Python leetcode 1765 地图中的最高点,力扣练习,多源BFS解法代码实践,广度优先搜索,图搜索经典题目,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
leetcode 1765 地图中的最高点,多源BFS
1.题目描述
给你一个大小为
m x n的整数矩阵isWater,它代表了一个由 陆地 和 水域 单元格组成的地图。
- 如果
isWater[i][j] == 0,格子(i, j)是一个 陆地 格子。- 如果
isWater[i][j] == 1,格子(i, j)是一个 水域 格子。你需要按照如下规则给每个单元格安排高度:
- 每个格子的高度都必须是非负的。
- 如果一个格子是 水域 ,那么它的高度必须为
0。- 任意相邻的格子高度差 至多 为
1。当两个格子在正东、南、西、北方向上相互紧挨着,就称它们为相邻的格子。(也就是说它们有一条公共边)找到一种安排高度的方案,使得矩阵中的最高高度值 最大 。
请你返回一个大小为
m x n的整数矩阵height,其中height[i][j]是格子(i, j)的高度。如果有多种解法,请返回 任意一个 。
示例 1:
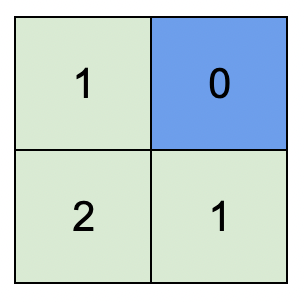
输入:isWater = [[0,1],[0,0]] 输出:[[1,0],[2,1]] 解释:上图展示了给各个格子安排的高度。 蓝色格子是水域格,绿色格子是陆地格。
示例 2:
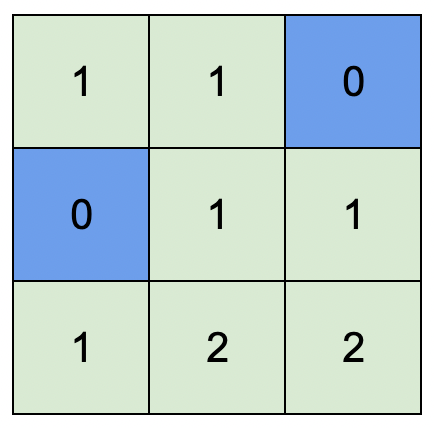
输入:isWater = [[0,0,1],[1,0,0],[0,0,0]] 输出:[[1,1,0],[0,1,1],[1,2,2]] 解释:所有安排方案中,最高可行高度为 2 。 任意安排方案中,只要最高高度为 2 且符合上述规则的,都为可行方案。
提示:
m == isWater.lengthn == isWater[i].length1 <= m, n <= 1000isWater[i][j]要么是0,要么是1。- 至少有 1 个水域格子。
2.题目解析与代码
利用队列进行操作:
首先创建一个矩阵res用于写入结果,利用已知条件填入水域高度,未填入的陆地高度统一用-1表示,与已经写入的陆地区域相互区别;
其次,创建一个队列,所有水域入队;
然后,每个水域出队,写入res周围陆地高度,被写入高度的陆地作为源点继续入队;
知道循环结束,结束标志:不再有新的源点入队,即队列空了。
(注意队列的入队和出队一定不能在一个方向,右进左出,或者反过来)
代码:
class Solution:def highestPeak(self, isWater: List[List[int]]) -> List[List[int]]:m, n = len(isWater), len(isWater[0])res = [[0] * n for _ in range(m)]d = deque()for i in range(m):for j in range(n):if isWater[i][j]:d.append((i, j))res[i][j] = 0 if isWater[i][j] else -1dirs = [(1, 0), (-1, 0), (0, 1), (0, -1)]h = 1while d:size = len(d)for _ in range(size):x, y = d.popleft()for dir in dirs:nx, ny = x + dir[0], y + dir[1]if 0 <= nx < m and 0 <= ny < n and res[nx][ny] == -1:res[nx][ny] = hd.append((nx, ny))h += 1return res
- 时间复杂度:O(m∗n)
- 空间复杂度:O(m∗n)
这篇关于Python leetcode 1765 地图中的最高点,力扣练习,多源BFS解法代码实践,广度优先搜索,图搜索经典题目的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!






